2017년에 출간된 논문으로, 광범위한 NLP task에 대해서 어떤 구조의 모델을 선택하는 것이 좋을지에 대한 가이드라인을 제공하고자 작성된 논문이다.
제목에서는 CNN과 RNN을 비교한다고 되어있으나 구체적으로는 RNN의 세부 종류인 GRU, LSTM을 성능 비교 실험에 사용하고 있다.
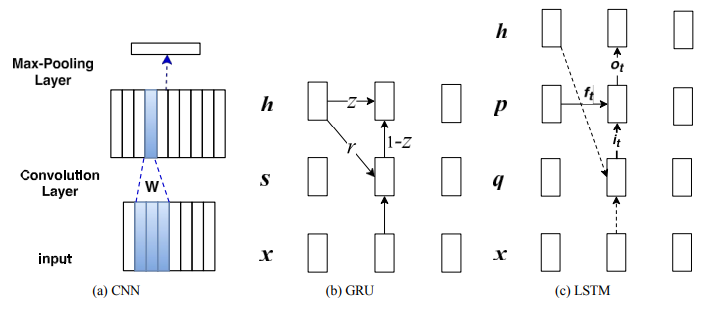
사실상 이미 자주 접해본 모델들을 다루고 있기 때문에 각 모델에 대한 설명은 생략하고 실험 결과에 대해서만 간단히 요약하고자 한다.
Experiments
Tasks
- Sentiment Classification (SentiC) on Stanford Sentiment Treebank(SST): SST dataset을 이용해서 영화에 대한 긍정/부정 감성을 분류하는 task
- Relation Classification (RC) on SemEval2010 task 8: 메뉴얼에 따라 labeling된 문장들이 있는 dataset을 이용해서 문장 시퀀스 s에 따라 명사 쌍 e1과 e2 사이의 관계를 알아내는 task
- Textual Entailment (TE) on Stanford Natural Language Inference (SNLI): labeling된 전제-가설 쌍을 포함하는 dataset을 이용해 unlabeled 쌍에 대한 답을 맞춰가는 task
- Answer Selection (AS) on WikiQA: open domain의 QnA 쌍 dataset을 이용해 질문에 대한 맞는 답변을 찾는 task
- Question Relation Match (QRM) on WebQSP: 각 질문에 대해서 구문 분석을 통해 Topic entity를 생성하고, Topic entity와 연결되는 모든 relations/relation chain을 선택하고, labeling된 구문 분석에서 relations/relation chain만 긍정으로, 나머지는 부정으로 설정하는 task
- Path Query Answering (PQA) on the path query dataset released by Guu et al: KB path data가 포함된 dataset에 대해서 head entity와 relation sequence를 통해 tail entity를 예측하도록 인코딩하는 task
- Part of Speech Tagging on WSJ: 품사 tagging task
위의 7가지 작업들을 4가지로 분류하여 실험을 진행했다.
(1) TextC: SentiC, RC
(2) SemMatch: TE, AS, QRM
(3) SeqOrder: PQA
(4) ContextDeP: POS tagging
Results
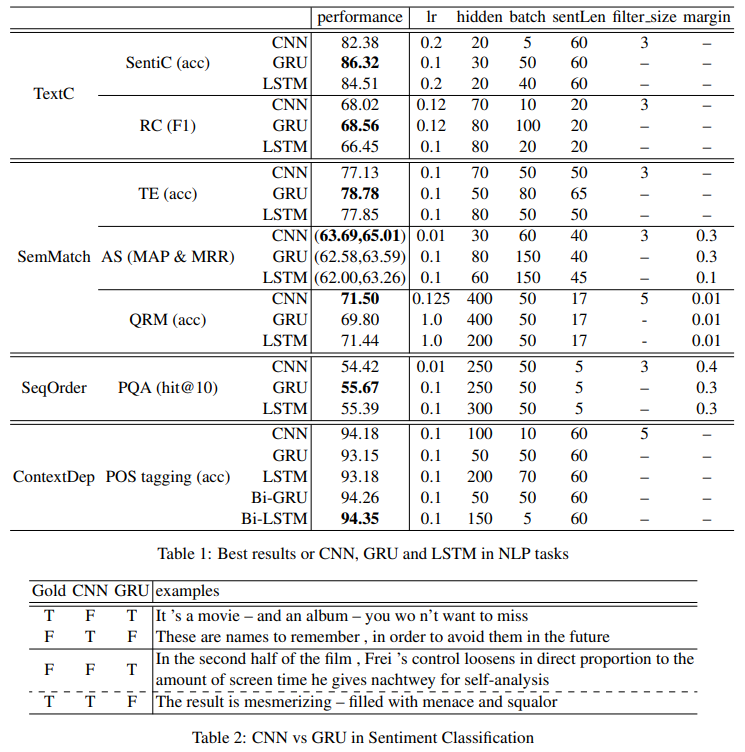
(1)~(4) task에 대해서 각 모델 CNN, GRU, LSTM의 성능을 비교하고 있다.
TextC: GRU는 SentiC에서 가장 우수한 성능을 보였고, RC에서는 CNN과 유사했다.
SemMatch: AS와 QRM에서는 CNN이 가장 우수했으나, TE에서는 그렇지 않았다.
SeqOrder: GRU와 LSTM이 CNN보다 성능이 좋았다.
ContextDep: CNN은 단방향 RNN보다는 성능이 좋지만 양방향 RNN보다 성능이 좋지 않았다.
이러한 결과에 대해서 CNN은 local한 위치 불변의 특징을 추출하는데 강점이 있다는 것을 고려하면 TextC에 강점이 있어야 하는데 그렇지 않았다는 점에서 정성 평가를 진행한 것이 위 그림의 아래 표이다. 표의 내용을 간단히 요약하면, 부정 표현이 그대로 드러난 경우에 대해서 CNN은 local feature extraction이라는 특성 하에 부정이라 판단하지만 장기적인 맥락 상 그 부정 표현이 결과적으로 긍정으로 쓰였을 때 GRU가 그것을 긍정이라 판단하여 더 좋은 성능을 보였던 것이다.
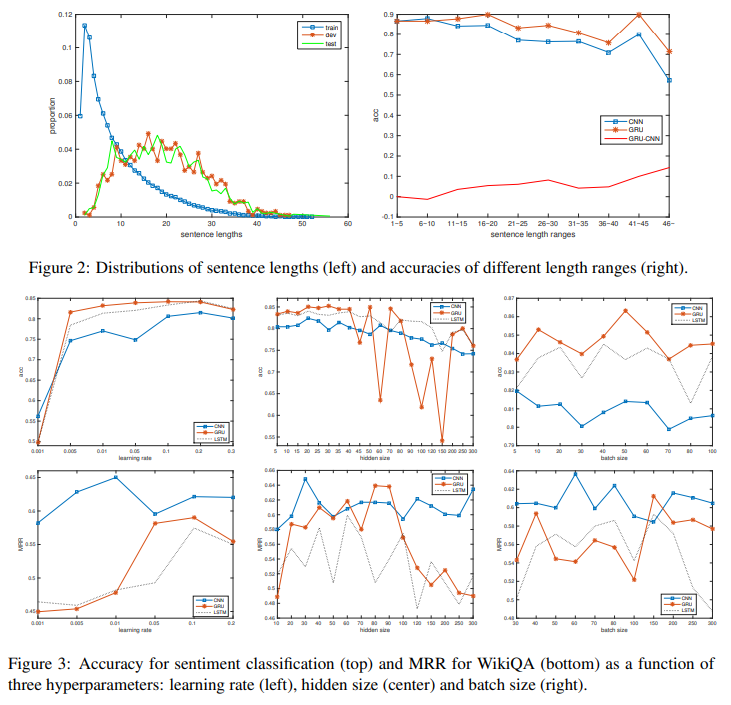
문장의 길이에 따라서 정확도를 비교했을 때 더 긴 문장에 대해서 GRU가 CNN보다 더 좋은 성능을 내고 있음을 맨 위의 그래프를 통해 알 수 있다.
아래의 그래프는 hyper-parameter에 대한 CNN과 GRU, LSTM의 민감도를 비교하여 어떤 모델이 더 안정적인 성능을 제공하는지 확인한 것이다.
모든 모델이 학습 속도 변화에 대해서는 비교적 평탄한 성능을 보이고 있는 반면, hidden layer와 batch size에 대해서는 민감하게 변화하는 것을 볼 수 있다.
SentiC task에서 CNN의 민감성은 GRU나 LSTM에 비해 낮고 AS task에 대해서는 더 높다.
