BERT model은 영어 corpus로 학습되어 있는 언어 모델이다. 그렇기 때문에 한국어 BERT 모델이 따로 개발되어서 나오기도 했는데 이 논문에서는 Multilingual BERT(M-BERT) 즉, 여러 언어에 대해 일반화된 언어 모델이 얼마나 일반화를 잘 수행하고 있는지를 조사했다.
우선 논문에 따르면, M-BERT는 104개 언어의 단일 언어 위키 백과 corpus를 이용해 pre-training한 model을 사용한다. 이 모델은 BERT와 사용한 데이터셋의 차이를 빼면 학습 과정이 거의 유사하며 구조도 12 layer의 transformer로 구성되어 있다는 점에서 비슷하다.
논문에서 수행한 실험 데이터에 따르면, M-BERT는 서로 다른 언어 사이의 일반화를 꽤 우수하게 수행하고 있으며 어떻게 이러한 전이를 수행할 수 있는지 확인하기 위해 다양한 가설을 검증했다.
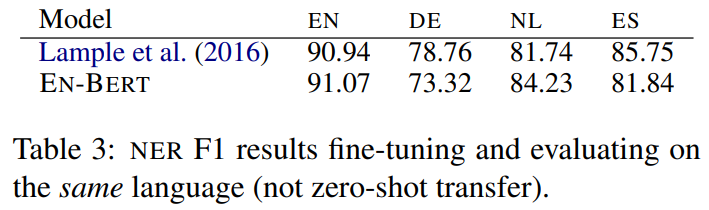
 네덜란드어, 스페인어, 영어, 독일어가 포함된 CoNLL-2002 및 2003 데이터셋과 16개 언어가 포함된 사내 데이터셋으로 Name Entity Recognition (NER) 테스트를 했을 때의 결과 지표이다.
네덜란드어, 스페인어, 영어, 독일어가 포함된 CoNLL-2002 및 2003 데이터셋과 16개 언어가 포함된 사내 데이터셋으로 Name Entity Recognition (NER) 테스트를 했을 때의 결과 지표이다.
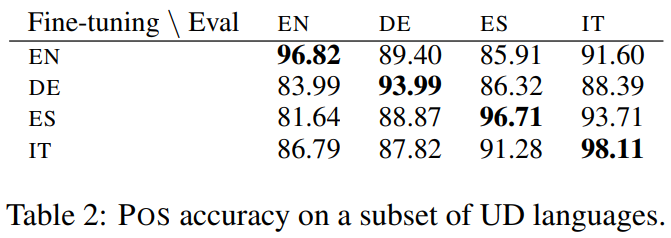 Part of Speech tagging 실험의 결과이다. 41개 언어에 대한 유니버셜 디펜던시(UD) 데이터를 활용해서 POS 실험을 수행했고, M-BERT는 모든 쌍에 대해서 80% 이상의 정확도를 달성하고 있다.
Part of Speech tagging 실험의 결과이다. 41개 언어에 대한 유니버셜 디펜던시(UD) 데이터를 활용해서 POS 실험을 수행했고, M-BERT는 모든 쌍에 대해서 80% 이상의 정확도를 달성하고 있다.
 Zero Shot NER test를 수행했을 때, En-BERT는 중첩되는 단어 조각들에 직접적으로 의존하는 반면, M-BERT는 단어 중첩과 거의 무관한 수준의 성능을 보이고 있다.
Zero Shot NER test를 수행했을 때, En-BERT는 중첩되는 단어 조각들에 직접적으로 의존하는 반면, M-BERT는 단어 중첩과 거의 무관한 수준의 성능을 보이고 있다.

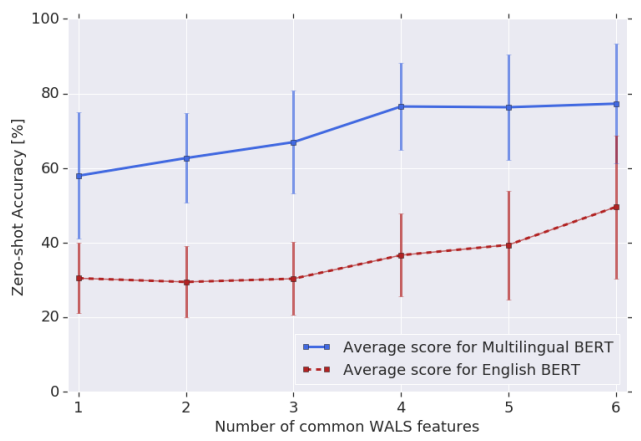 공통된 typological feature 의 개수가 많을수록 transferabiltiy 향상되는 결과를 볼 수 있다.
공통된 typological feature 의 개수가 많을수록 transferabiltiy 향상되는 결과를 볼 수 있다.
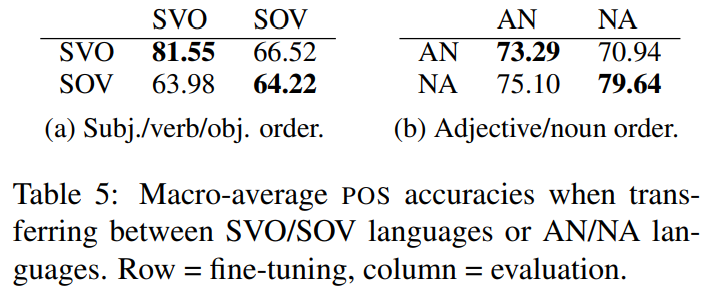 여러 typological features 중에서 SOV order 와 AN order의 영향을 비교했을 때 전자가 더 영향이 크다.
여러 typological features 중에서 SOV order 와 AN order의 영향을 비교했을 때 전자가 더 영향이 크다.
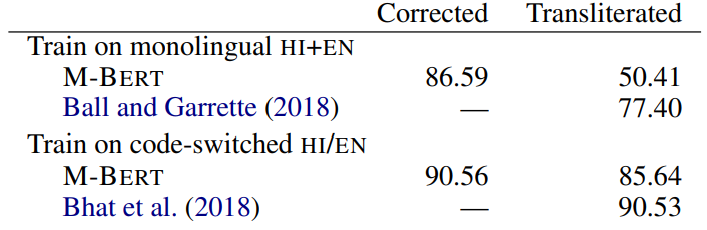
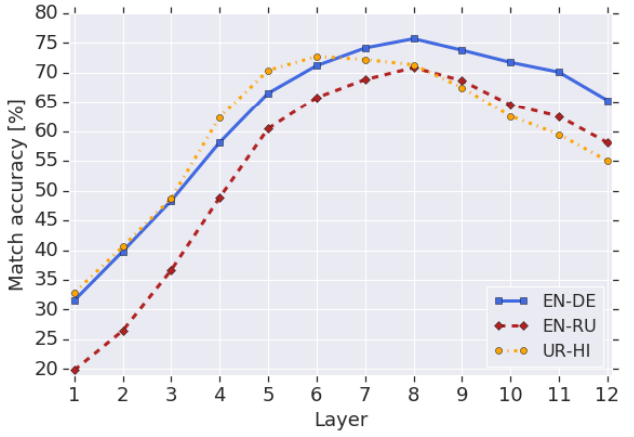 중간 layer에서 linguistic information을 공유하고 이는 언어에 관계없이 비슷하게 나타난다.
중간 layer에서 linguistic information을 공유하고 이는 언어에 관계없이 비슷하게 나타난다.
