🔶Intro
지난 졸업 프로젝트를 통해 접한 3D reconstruction 기술에 AI를 접목한 NeRF 기술과 그 후속 연구들에 대해서 동아리 발표를 진행하게 되었다. 발표 자료를 만들기 이전에 먼저 내용을 정리하기 위해서 NeRF 기술과 원본 기술의 한계, 그리고 후속 연구들이 어떻게 NeRF를 발전시켜왔는지에 대해 글을 작성하였다.
(사실 졸업 프로젝트 주제를 3개월 남기고 완전히 갈아엎으면서 나도 멘탈 깨지고 협동 깨지고 최신 기술 사용해보는 걸로 최대한 비벼보려다가 웹 개발 담당자가 깃허브 날리고 코드 안 올리고 로컬 테스트만 해두고 잠수 타서 아쉽고 개빡치는 나머지 나라도 기술 트렌드 한 가닥 잘 잡아보고 싶어서 동아리 발표 논문으로 선정했다.)
NeRF 기술은 ECCV 2020 Oral – Best Paper Honorable Mention으로 선정된 이후로 AI를 활용한 2D에서 3D로의 변환 기술 중 가장 큰 관심을 받은 기술 중 하나이다.
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (링크: https://arxiv.org/abs/2003.08934)
☝NeRF가 뭔데?
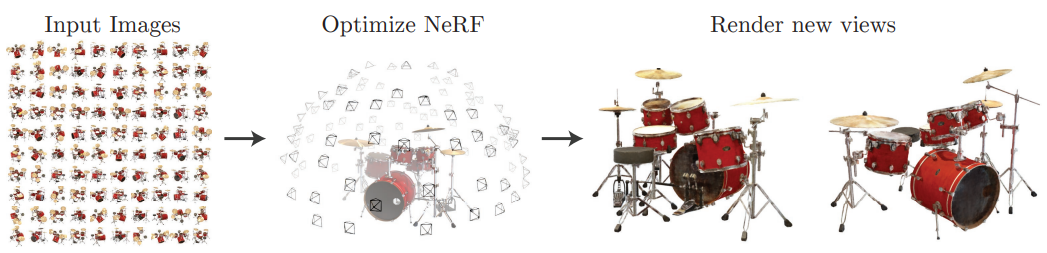 NeRF를 간단히 설명하자면, "input images를 통해 Neural Radial Field 상에서 바라보는 물체의 3D point를 최적화(optimization)하여 input에 없는 새로운 view에서의 물체 형태를 출력하는 기술"이다.
NeRF를 간단히 설명하자면, "input images를 통해 Neural Radial Field 상에서 바라보는 물체의 3D point를 최적화(optimization)하여 input에 없는 새로운 view에서의 물체 형태를 출력하는 기술"이다.
여기서 AI 기술의 역할은 Radial Field에 3차원 voxel이 갖는 색상과 물체 밀도를 예측하여 찍어주는 것이고, AI가 이를 학습하여 출력하기 위해 사용되는 데이터를 input images로부터 추출하는 기술이 따로 있다.
쉽게 말해, AI 기술의 앞뒤로 input images에서 데이터를 추출하고, AI의 output 데이터가 3D object로 구성되도록 연산하는 함수가 붙어있다는 것이다. 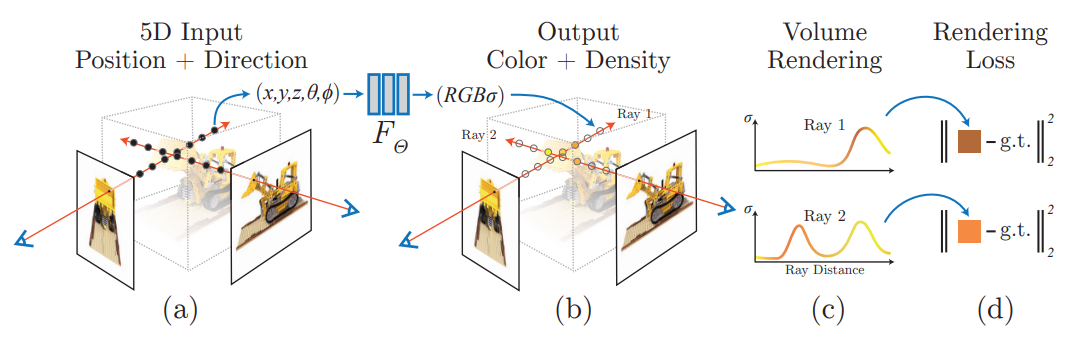 이 그림의 순서를 따르는 알고리즘이라고 생각하면 된다. (중간에 쪼마낳게 붙어있는 FΘ가 FC layer이다...
이 그림의 순서를 따르는 알고리즘이라고 생각하면 된다. (중간에 쪼마낳게 붙어있는 FΘ가 FC layer이다... 하찮다.)
NeRF 기술의 핵심 포인트를 꼽자면, (1) MLP를 사용한 학습, (2) Volume Rendering 이렇게 2가지이다. 사실상 (1)은 아이디어의 한 축인 정도고 layer의 구조도 굉장히 단순하기 때문에 실상 기술의 더 많은 지분을 갖고 있는 것은 (2)이다.
🔴[NeRF] MLP를 사용한 학습
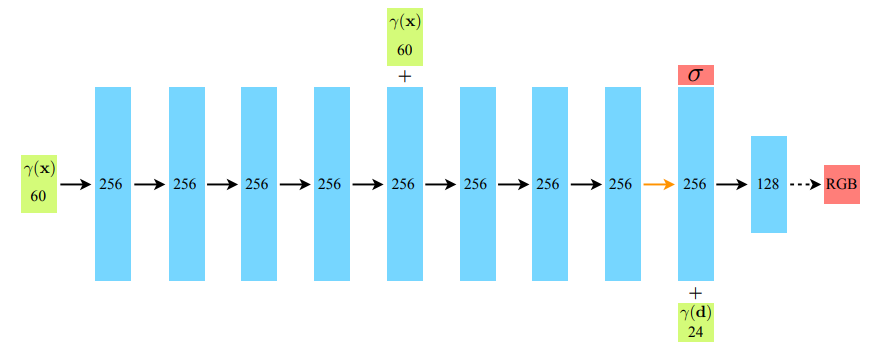 NeRF에서는 위와 같은 단순한 구조의 Mulit-layer Perceptrons를 사용하고 있다.
NeRF에서는 위와 같은 단순한 구조의 Mulit-layer Perceptrons를 사용하고 있다.
모델 구조는...
- input: input images에서 추출한 voxel (x, y, z, θ, ϕ) (θ, ϕ은 카메라 view point's direction)
- architecture:
8 Fully-connected ReLU layers, each with 256 channels (include skip connection (concat input to the 5th layer's activation)
+) additional layer for checking whichever output volume density value is negative or possitive
+) 위의 구조에 따라 출력된 output은 256차원 특징 벡터 상태에서 input viewing direction의 position encoding과 concat되고 128 channel의 FC ReLU 추가 layer에서 최종 처리됨.
- output: Radial Field 상에서의 voxel값 마다 갖는 물체의 3D 표면의 RGB와 density 예측 값
이렇게 된다.
실상 skip connection을 이용해서 gradient vanishing을 방지하던지.. 아니면 spatial info를 살리던지 하고(concat을 쓴 이유: input channel과 FC layer channel 값이 달라서? summation을 쓰는 case와 뭐가 다른지는 따로 찾아봐야 할 것 같다.), 마지막에 최종 output으로의 변환을 거치는 것을 제외하면 이 부분은 기술적으로 설명할 것이 많지 않다.
🟠Neural Radiance Field represnetation + Volume Rendering
이 부분이 진짜... 수식도 어렵고 설명할 것이 많다. 여기가 핵심이다. 설명을 위해 앞에서 썼던 그림을 다시 가져왔다. 그리고 아래 그림도 같이 참고하면 좋다. (정말 단순화한 그림이기 때문에 참고용으로만...)  이 그림에서 파란색 부분이 지금 다뤄볼 부분이다. 이 두 부분은 실상 선형 대수라던지, Neural Network라던지 그런 곳에서 쓰는 연산보다는 실질적으로 미적분 연산을 위주로 사용하고 있기 때문에 따로 빼서 설명하는 것이 나을 것 같아 꺼내 왔다. 그리고 연산 방식이나 목적도 encoding / decoding 수준의 관계이기도 하다.
이 그림에서 파란색 부분이 지금 다뤄볼 부분이다. 이 두 부분은 실상 선형 대수라던지, Neural Network라던지 그런 곳에서 쓰는 연산보다는 실질적으로 미적분 연산을 위주로 사용하고 있기 때문에 따로 빼서 설명하는 것이 나을 것 같아 꺼내 왔다. 그리고 연산 방식이나 목적도 encoding / decoding 수준의 관계이기도 하다.
위 그림에서 Radiance Field Scene Representation 부분을 먼저 살펴보자.
❗Neural Radiance Field Scence Representation
논문에서 제시하는 Neural radiacne field scence은 Input으로 들어온 image 내에서 (x, y, z)에서의 Viewing point를 (θ, ϕ)로 표현하여 이 두 정보를 합친 5 dimension으로 이루어져 있다.
❗❗Volume Rendering
🟡NeRF 기술 근황과 후속 연구
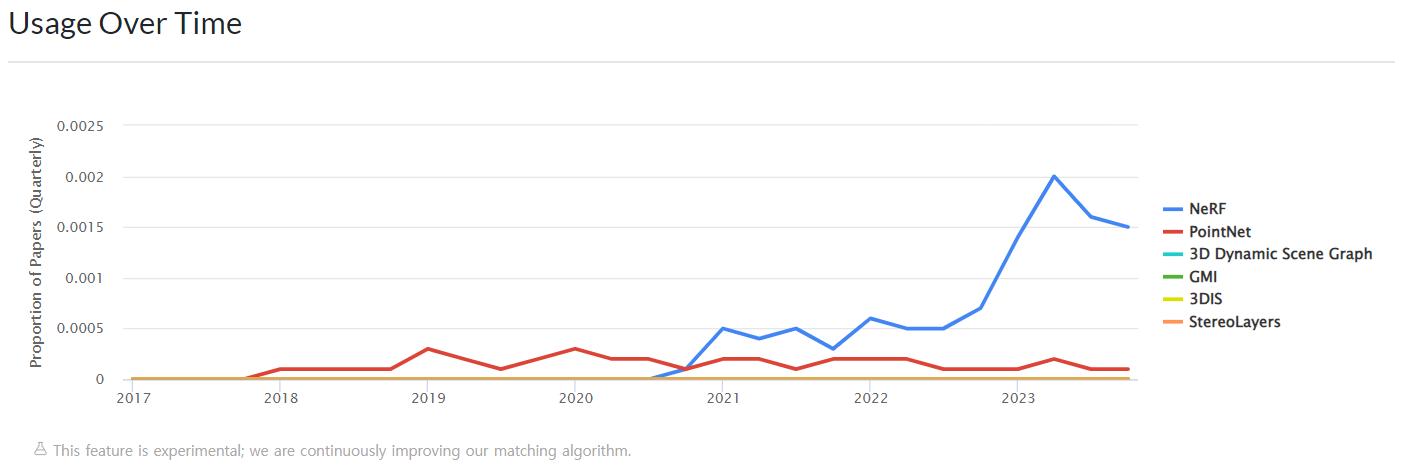 위 이미지는 https://paperswithcode.com/method/nerf 에서 가져온 것인데, 2020년 처음 기술이 나온 후에 꾸준히 높은 관심을 받아오고 있는 것을 확인할 수 있다.
위 이미지는 https://paperswithcode.com/method/nerf 에서 가져온 것인데, 2020년 처음 기술이 나온 후에 꾸준히 높은 관심을 받아오고 있는 것을 확인할 수 있다.
사용성에 관해서 큰 관심을 받고 있을 뿐만 아니라 그래픽 작업에 대해 완전히 새로운 트렌드를 가져올 수도 있는 기술인 만큼 NeRF가 갖는 한계를 극복하기 위한 여러 후속 연구들이 나오기도 했다.
NeRF의 한계는 다음과 같다.
1. 너무 느린 학습 속도 - 학습에만 1일이 꼬박 걸린다.
2. 너무 많이 필요한 학습 데이터량 - input images가 최소 50장 이상 필요
3. 1 알고리즘: 1 3D 모델 - AI model 하나가 하나의 물체만 만들 수 있다.
4. 움직이는 물체 학습 불가 - 물체가 움직이면 인식을 못 한다.
5. 촬영 환경의 조건의 제한성 - 같은 환경에서 촬영된 물체만 AI가 학습 가능하다.
6. 여러 카메라 변수를 추가적으로 요구한다. - LLFF나 colmap과 같은 library를 활용한 카메라 변수 추출 작업을 추가로 요구한다.
위와 같은 한계들을 극복하기 위해서 여러 후속 연구가 나왔다. (이 만큼 다양한 후속 연구가 나오는 것도 참 쉽지 않다.)
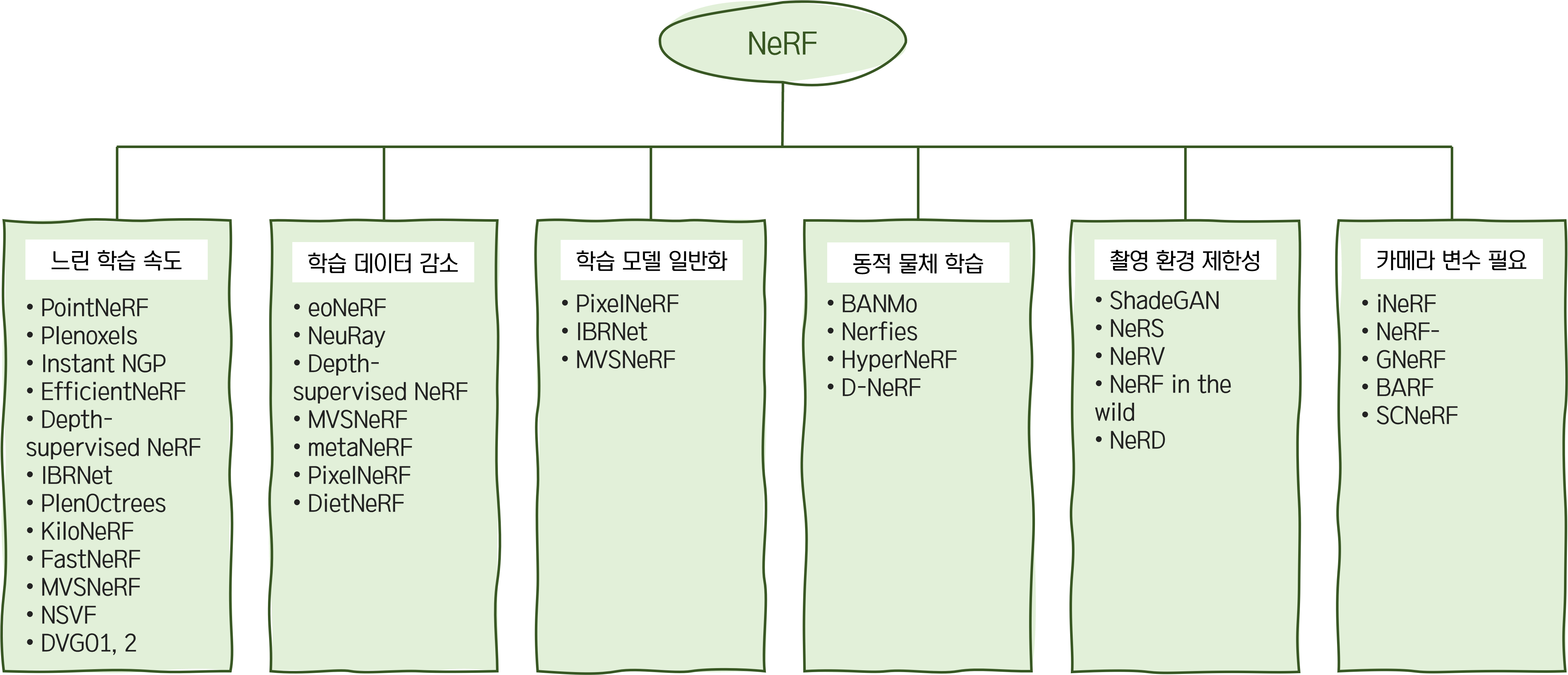 이렇게 후속 연구들을 정리해보았다. (내용 출처: https://modulabs.co.kr/blog/nerf-followup/) 하나의 기술이 이 정도로 추가 후속 연구가 많았다는 점에서 이 기술이 CV domain에서 마르지 않는 샘같은 역할인 듯 싶다.
이렇게 후속 연구들을 정리해보았다. (내용 출처: https://modulabs.co.kr/blog/nerf-followup/) 하나의 기술이 이 정도로 추가 후속 연구가 많았다는 점에서 이 기술이 CV domain에서 마르지 않는 샘같은 역할인 듯 싶다.
✌Best paper 후속 연구 Instant NGP
위의 기술들 중에서도 2022년도에 SIGGRAPH2022 Best Paper로 선정된 Instant NGP 기술은 NeRF의 후속 연구들 중에서도 유의미하게 큰 성과를 이뤘다고 할 수 있을 만큼 굉장한 성과를 거두었다.
https://youtu.be/DJ2hcC1orc4
위 링크에 들어가면 NVDIA에서 직접 공개한 Instant NGP 알고리즘의 성능을 체감해볼 수 있다. 거의 실시간으로 NeRF 기술이 구현되고 있는 것을 확인할 수 있으며, 현재 NVDIA에서 제공하는 github 코드를 NVDIA GPU가 설치된 컴퓨터에 설치하면 GUI를 통해 Instant NGP를 이용한 3D modeling을 직접 수행해볼 수 있다. (슬프게도 나는 Intel GPU가 달린... 똥컴이라 못 써봤다.)
