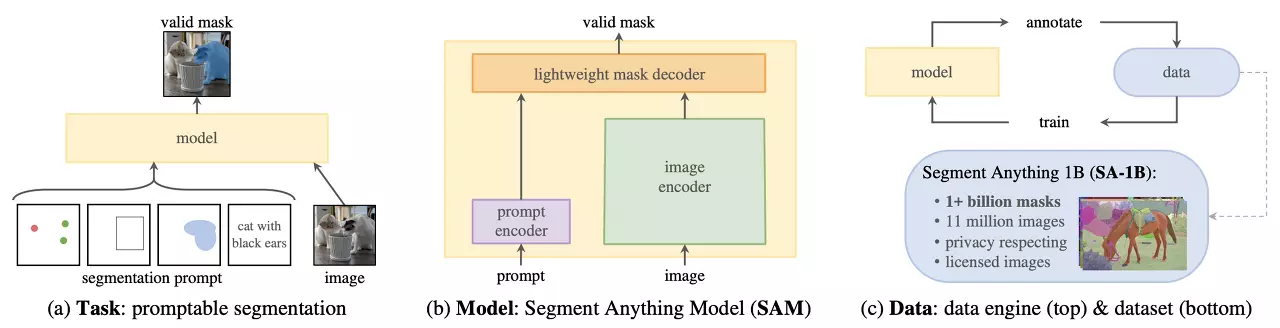
기존의 Segmentation task를 수행하는 AI model들은 model이 이미 학습한 물체의 테두리를 감지하는 방식의 학습 방법을 사용해왔는데, 이 논문은 Segmentation task에 대해서 zero shot 방식을 통해 배우지 않은 물체의 테두리도 인식할 수 있는 Foundation model을 다룬다는 특징이 있다.
이 논문에서는 정말 무엇이든 segmentation하기 위한 Generalized model을 만들기 위해서 task, model, data 세 가지 요소를 중점적으로 다뤘다.
- Zero-shot 일반화를 가능하게 하는 task
- 이 model의 구조
- 이 task와 model에 필요한 data
위의 세 가지 요소들을 포괄적으로 해결하는 모델을 만들 때, "무엇이든"이라는 포인트를 prompt의 방식으로 접근한다. 사용자가 segmentation을 하고자 하는 것을 prompt에 넣으면 AI model이 이를 수행하는 방식이다. 여기서 prompt로 받는 것은 point, box, text이다.
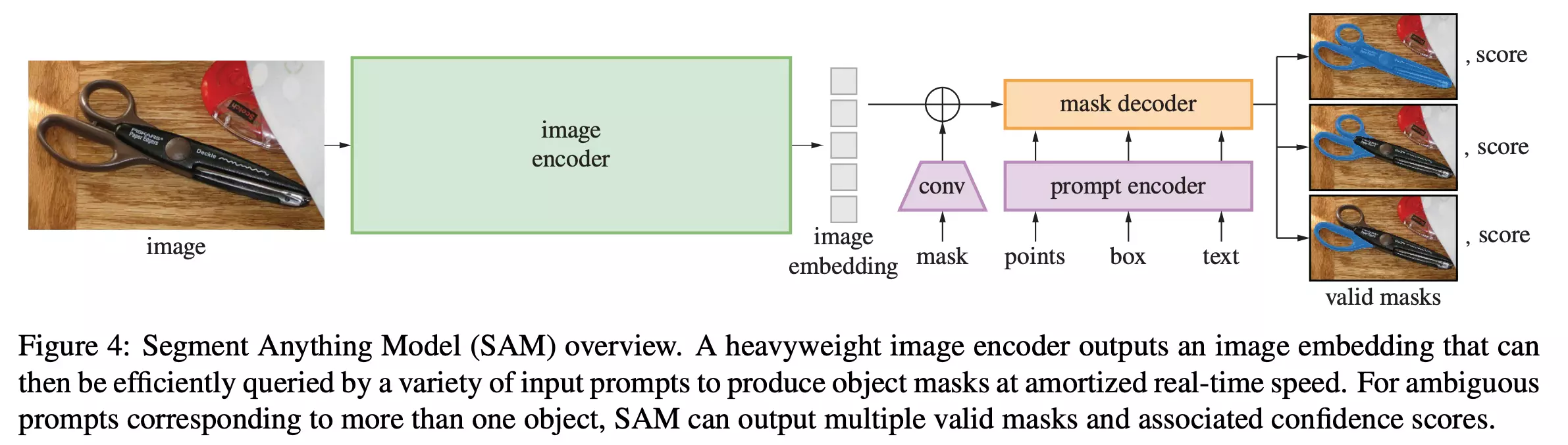
Segmentation Anything model의 전체 구조는 위와 같다. 주요 요소로는 Powerful Image Encoder, Prompt Encoder, Mask Decoder가 있다.



눈 앞에 치킨 무와 파닭 치킨과 자몽 주스가 있을 때 지었던 닉네임