Large Language Model의 성공에 따른 후속 연구들이 줄창 이어지면서 흥미로운 연구 결과들이 우수수 쏟아지고 있다. 그 중에서도 눈에 띄는 것 중 하나는 prompt engineering에 관한 것이다. 이전에 읽어본 뉴스 기사 중에서 LLM 서비스 사업의 성장이 만들어낸 새로운 고액 연봉 직군으로 promt engineer라는 것이 있다는 내용이 있었는데 이번에 리뷰할 논문은 LLM은 인간 수준의 prompt engineer와 맞먹는다는 내용을 담고 있었다.
이렇게 또 SW 기술이 사람을 대체하는가 싶어 논문을 읽어보았다.
(참고한 링크들
https://disquiet.io/@luckydaun/makerlog/7866
https://velog.io/@halinee/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-LARGE-LANGUAGE-MODELS-ARE-HUMAN-LEVELPROMPT-ENGINEERS
http://cloudinsight.net/ai/%EA%B1%B0%EB%8C%80-%EB%AA%A8%EB%8D%B8%EC%9D%98-%EB%B0%9C%EC%A0%84%EA%B3%BC-zero-shot%EC%9D%98-%EC%9D%98%EB%AF%B8/
https://www.promptingguide.ai/kr
https://www.t4eh0.com/prompt-engineering/
https://skyjwoo.tistory.com/entry/ChatGPT-%ED%94%84%EB%A1%AC%ED%94%84%ED%8A%B8-%EC%97%94%EC%A7%80%EB%8B%88%EC%96%B4%EB%A7%81%EC%9D%B4%EB%9E%80
https://www.thedatahunt.com/trend-insight/what-is-prompt
)
Intro
이론적 배경
prompt engineering이란
prompt: 어떤 작업을 수행하는 것을 돕기 위해 전달하는 메세지
prompt engineering: 쉽게 말하면 LLM이 더 나은 결과물을 낼 수 있도록 instruction을 넣어주는 역할, LLM이 작업 수행을 더 원활하게 하도록 돕기 위해서 더 나은 프롬프트 메세지의 구성을 만드는 과정
LLM의 목적은 특정 한 가지의 task에 맞춰지는 것이 아니라 가능한 모든 task에 대해서 두루두루 좋은 성능을 내는 것이다. 그렇기 때문에 어떤 작업 수행에 대한 요구가 들어왔을 때 LLM이 무엇을 수행하길 바라는 것인지 정확하게 알려주는 것 또한 중요한 과정이 된다. 이를 위해서 원하는 task에 대해 fine tuning을 하는 방법도 있겠지만 GPT 기반의 모델들이 성행하면서 fine tuning은 좋은 해결책이 되지 못 했다. prompt engineering은 실제 인간 사이의 대화와 달리 그 속의 맥락과 의도를 파악하기 어려운 LLM에게 <과제>와 <원하는 의도>, <작업물의 수준> 등을 함께 전달하여 더 정확한 수행 결과를 얻는 작업으로 보통은 인간이 직접 text input box에 메세지를 작성하는 등의 방식으로 작업해왔다. 그러나 인간은 여전히 LLM이 어떻게 자연어를 처리하는지 알지 못 하기 때문에 인간의 방식으로 prompt engineering을 하는 것은 한계가 있지 않냐는 의견이 있었다. 이에 관해 LLM이 스스로를 prompt engineering하는 방식을 제시한 것이 이 논문이다.
Zero shot, Few shot
shot 앞에 붙은 것은 LLM이 얼마나 그 task에 관해 배웠는지를 두고 붙인 말이다. 그래서 zero shot은 아예 배운 적이 없는 task를 수행하도록 하는 것을 말하고, few shot은 약간의 data를 학습한 상태에서 그에 관한 작업을 수행하는 것을 말한다. Zero shot을 하는 이유는 LLM이 더 다양한 task를 수행할 수 있으면서 semantic information을 습득하여 general output을 만들도록 하기 위함이다.
Automatic Prompt Engineering
이 논문의 요지는 LLM이 스스로를 prompt engineering하여 더 나은 output을 만들도록 했을 때 그 성능이 인간이 직접 prompt engineering을 하는 것보다 좋다는 것이다. 그래서 LLM이 직접 prompt에 후보 instruction들을 추가해서 zero shot 수행 결과물을 보고 점수를 매기면서 더 나은 instruction을 선정하는 식으로 prompt engineering을 하는 알고리즘을 제시하고 있다.
APE의 구조
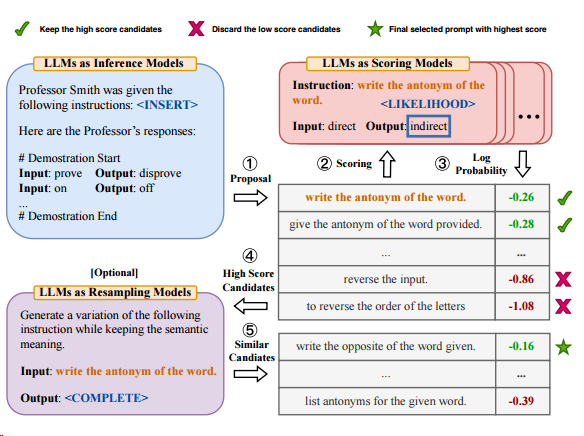 1. LLMs as Inference Model이 들어오는 prompt에 대해서 후보 instructions을 생성한다.
1. LLMs as Inference Model이 들어오는 prompt에 대해서 후보 instructions을 생성한다.
2. score function Model이 후보 instructions을 평가하여 점수를 매기고 log probability를 계산했을 때 높은 점수로 랭킹된 instructions를 골라낸다.
3. LLMs as Resampling Model이 들어오는 후보 instructions에 대해서 괜찮은 instruction이 없을 경우를 대비하여 다시 sampling을 수행한다.
위와 같은 과정에 따라 APE는 prompt engineer LLM이 LLM에게 instruction을 전달하면서 prompt engineering 작업을 효과적으로 수행한다.
LLMs as Inference Model
(내용 추가 예정)
LLMs as Scoring Model
(내용 추가 예정)
LLMs as Resampling Model
(내용 추가 예정)
Results
Interquartile mean across 24 tasks

충분한 data가 있을 때 Instruct GPT-APE는 사람이 수행하는 것을 뛰어넘는 성능을 보일 수 있었다.
Zero Shot test
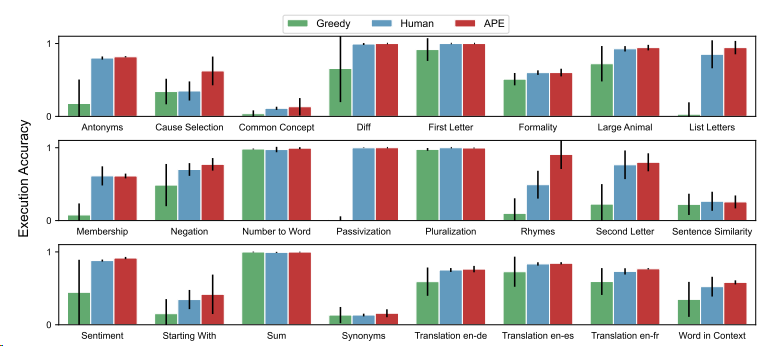 Zero Shot은 LLM이 더 나은 general output을 내도록 하기 위한 중요한 작업 중 하나이다. 이를 APE도 실현할 수 있는지 확인했을 때 사람의 수준 혹은 그보다 우수한 수준에서 이를 실현하는 것을 확인할 수 있다.
Zero Shot은 LLM이 더 나은 general output을 내도록 하기 위한 중요한 작업 중 하나이다. 이를 APE도 실현할 수 있는지 확인했을 때 사람의 수준 혹은 그보다 우수한 수준에서 이를 실현하는 것을 확인할 수 있다.
그외 여러가지 평가 사항
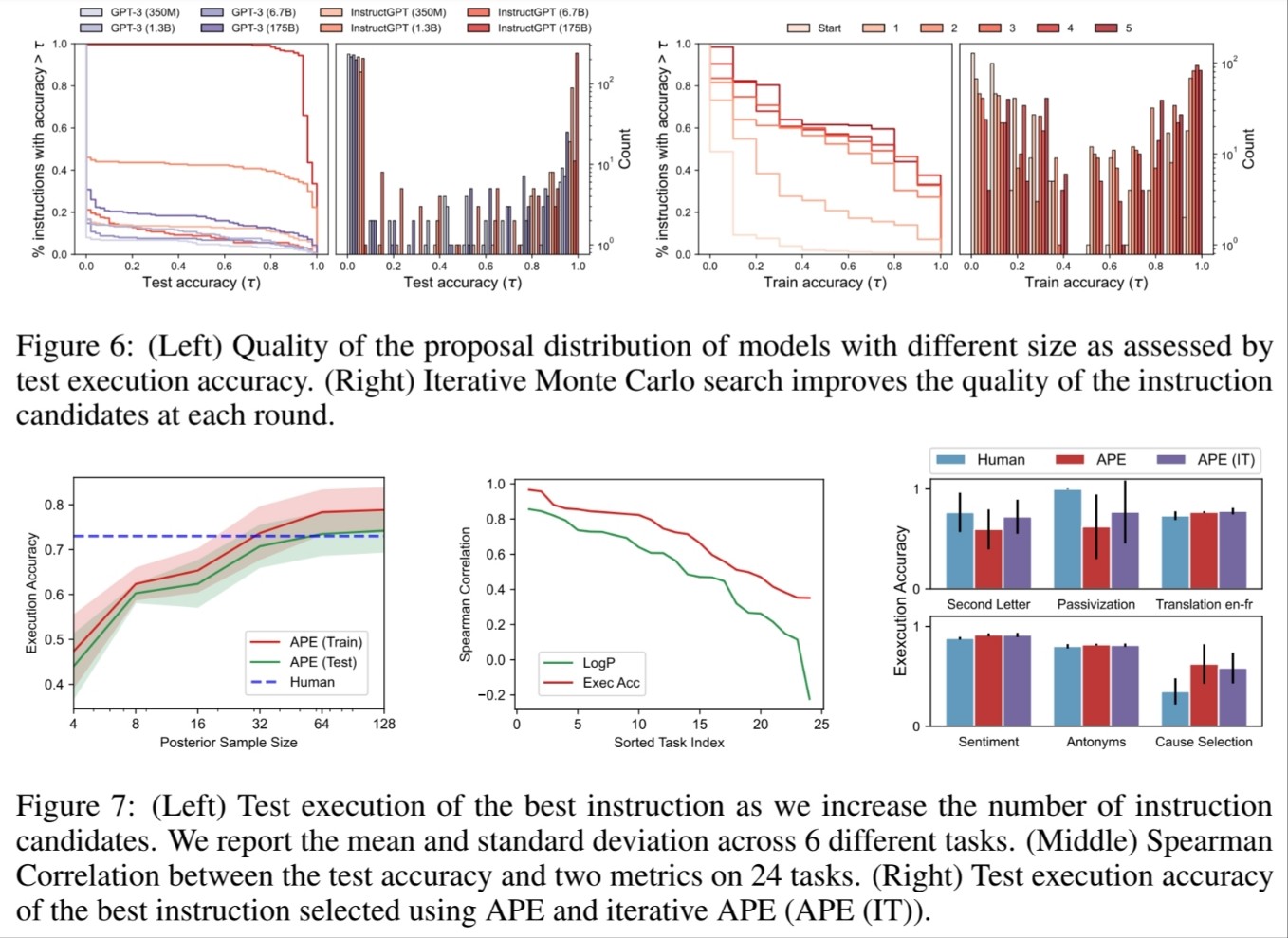
1.
Conclusions
PE에서도 AI가 사람을 이겼나?
결과적으로는 맞지만, 사실 애초부터 AI가 어떻게 학습하는지 모르는 인간보다는 LLM 자신이 직접 스스로를 이해하는 것이 옳은 것이었을지도 모른다. ChatGPT가 등장한 이래로 "잘 질문하기"가 GPT를 사용하는 방법이라고 소개하는 콘텐츠가 우후죽순 나왔지만 어떤 질문이 좋은 질문이라는 것을 판단하기는 어려웠다. 그렇기 때문에 PE는 처음부터 사람이 할 일이 아니라 LLM이 스스로 해결해 가야하는 부분이라고 보는 것이 맞을지도 모른다. 거꾸로 생각해서 LLM이 사람보다도 잘 할 수 있는 task를 찾아낸 논문이라고 생각해도 될 것 같다.
