VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
논문 리뷰
Transformer model은 CNN의 영역이었던 Image deep learning에서 큰 두각을 드러내며 그 성능을 입증한 바 있다. 이 논문은 그런 Transformer model에 multi-modal data를 넣어 representation vector를 추출하고 contrastive learning을 통해 여러 downstream task에서 좋은 성능을 보였다.
Intro
이론적 배경
Vision Transformer
https://www.thedatahunt.com/en-insight/vision-transformer
https://kmhana.tistory.com/27
위 링크 내용을 참고했다. 자연어 처리에서 주로 사용되던 Transformer 구조가 이제는 image deep learning에도 쓰이기 시작했다. Self-attention을 활용해 더 높은 성능을 구현하고자 했지만 기존의 CNN 구조에는 이것이 잘 이식되지 않았다. 그래서 자연어 처리 분야에서 Transformer 구조와 self-attention을 통해 우수한 성능을 낸 것에 착안하여 image task에서도 self-attention이 잘 적용되도록 하였다.
Self-Supervised Learning
supervised learning이란 training dataset에 input과 Ground truth를 붙여 labeling하여 정답을 알려주면서 학습을 시키는 것을 말한다. 그러나 Self-Supervised Learning(자기 지도 학습)은 실상 unsupervised learning에 가깝다. unlabelled dataset으로부터 좋은 data representation을 얻고자 하는 학습 방식으로 representation learning의 일종이다.
이는 큰 카테고리로 보면 Self-prediction과 Contrastive learning으로 나눌 수 있다. Self-prediction은 data sample 내에서 한 부분을 통해 다른 부분을 예측하는 task를 수행하는 부분이고, Constrative learning은 batch 내의 data sample들 사이의 관계를 예측하는 task를 말한다.
Video-Audio-Text Transformer (VATT)
Approach
Tokenization & Positional Encoding
Vision modality는 frame 별로 RGB 3개의 채널로 구성되어있고 Audio는 waveform으로 되어있으며 text는 character로 구성되어 있다. 서로 다른 형식으로 되어 있는 데이터들이 Transformer encoder에 들어가기 위해서는 각각의 data들을 tokenization 해야 한다.
Vision: T H W 차원의 전체 video clip을 잘게 쪼갠 patch sequence로 partitioning한다. 각각의 voxel에 대해 linear projection을 적용하여 d차원의 vector representation을 만든다. 여기에 position encoding을 적용하기 위해 dimention-specific embedding을 정의해서 계산한다.
Audio: waveform으로 들어오는 이 데이터는 1차원의 input으로 길이 T를 갖는다. 이를 또 잘게 쪼갠 segment로 partitioning하고 각각의 patch는 t길이의 waveform이 된다. 각각의 patch에 대해서 linear projection을 하고... 등등 Vision data를 마지막 처리한 것과 같은 과정을 연산한다.
Text: training dataset에 대해 v차원의 단어 dictionary를 정의한다. input text sequence를 v차원의 one-hot vector로 mapping하고 이를 d차원으로 mapping하는 embedding layer를 거쳐 연산한다.
위 과정을 모두 진행하고 나면 input으로 들어온 3종류의 data에 대해서 data representation이 모두 통일된 상태로 다음 단계에 전달된다.
DropToken
Transformer model에 모든 token을 넣으면 그것대로 task를 수행하면서 너무 많은 연산을 하게 되기 때문에 복잡도가 커진다. 이를 낮추기 위해서 Droptoken 방식을 적용한다. Video나 Audio에 대해서 받게 되는 token sequence는 그 크기가 매우 크기 때문에 이를 sampling을 통해 일부만 받아 input으로 활용하는 것이다. 이를 통해 input의 크기에 비례하여 계산 복잡도가 올라가는 Transformer의 computation complexity를 효과적으로 줄였다.
Transformer Architecture
VATT에서 사용하는 transformer 구조는 NLP task에서 주로 사용하는 구조와 거의 유사한 구조를 사용한다.
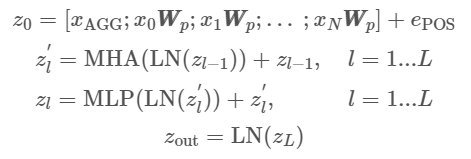
Projection
Model의 학습을 위해서 같은 공간으로 data를 projection하는 과정이 필요하다. 학습 과정에 있어서 data간의 유사성을 비교하려면 cosine 유사도를 비교할 수 있어야 하는데 이를 위해서 모두 같은 공간에 projection 되어 있어야 하는 것이다. 그리고 그 같은 공간에서의 Contrastive learning을 사용하여 학습이 진행된다.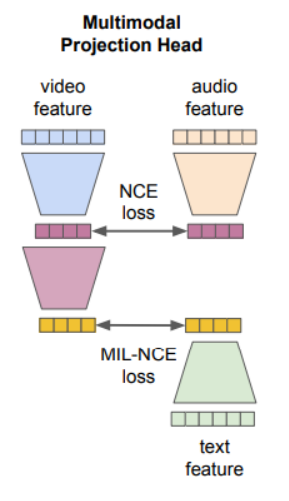
Multi-modal Contrastive Learning
이 논문에서는 학습할 때 (video-audio), (video-text) 쌍으로 학습을 진행하는데 여기서 Contrastive learning을 수행하면서 Self-Supervised learning 방법을 사용한다.
기존의 pre-text task에서 발전되어 나온 학습 방법으로 중심이 되는 data을 기준으로 positive, negative를 추출하고 positive는 anchor에 가깝게, negative는 anchor에서 멀게 하도록 만들면서 학습이 진행된다.
Experiments
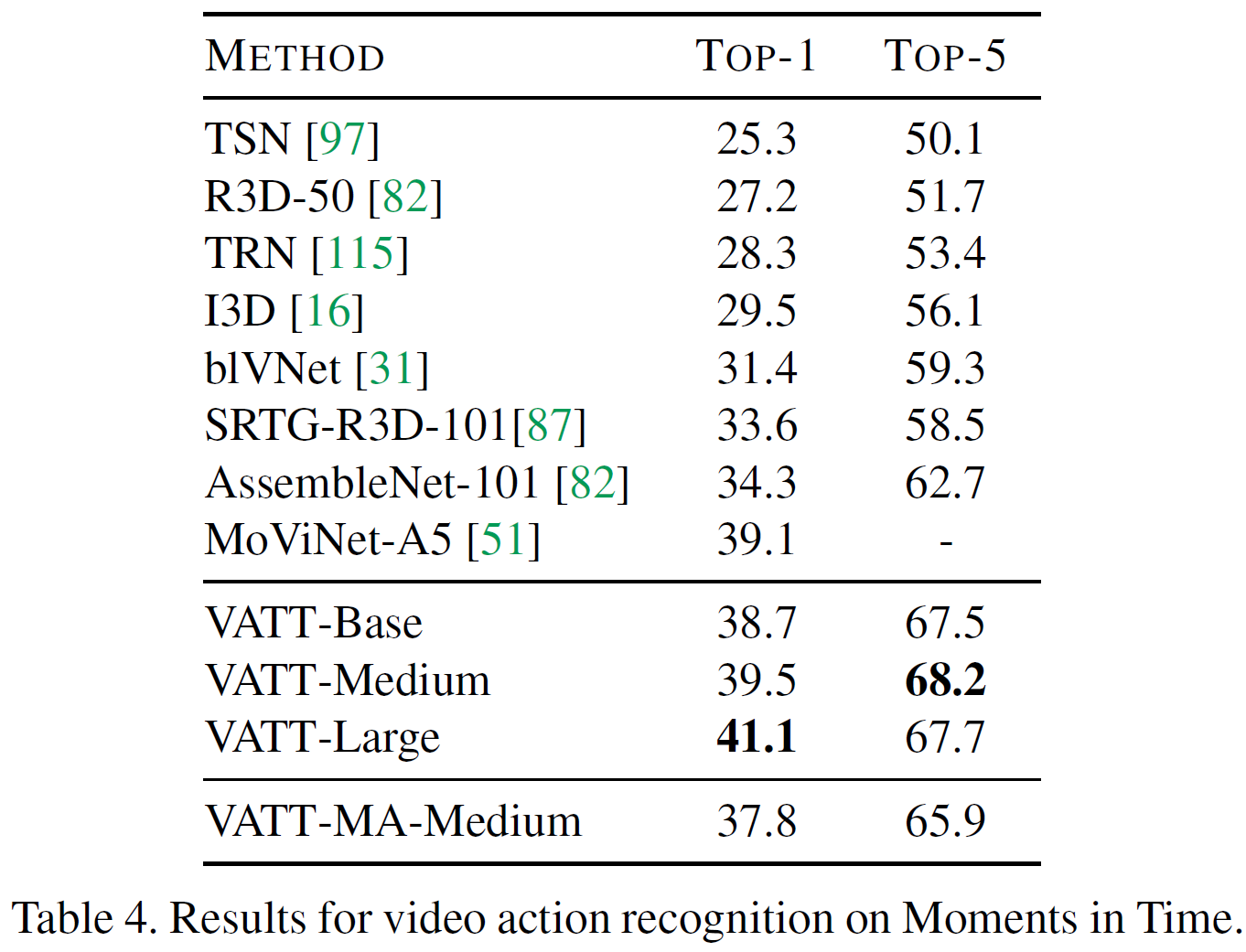
Fine-tuning for video action recognition
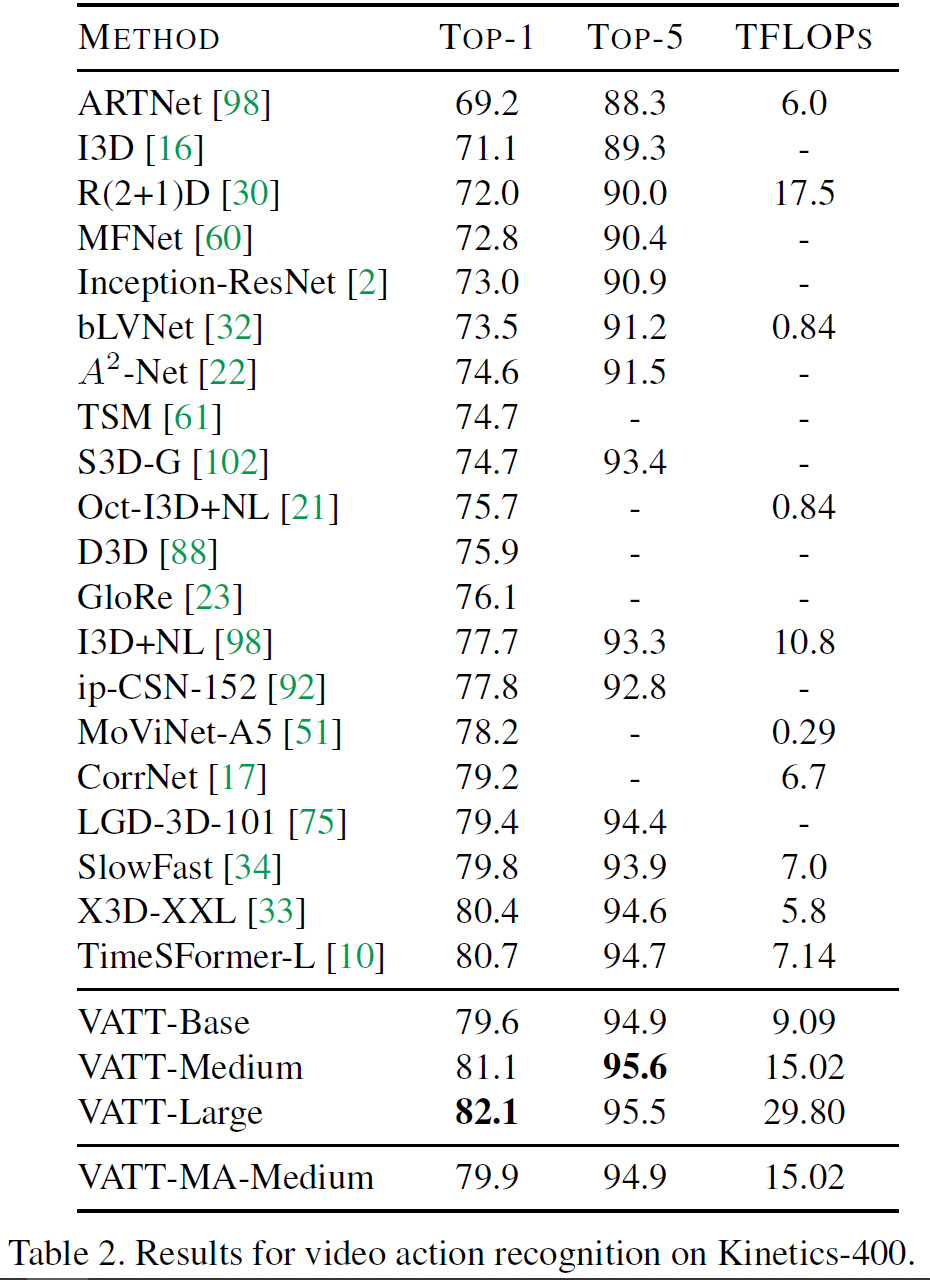
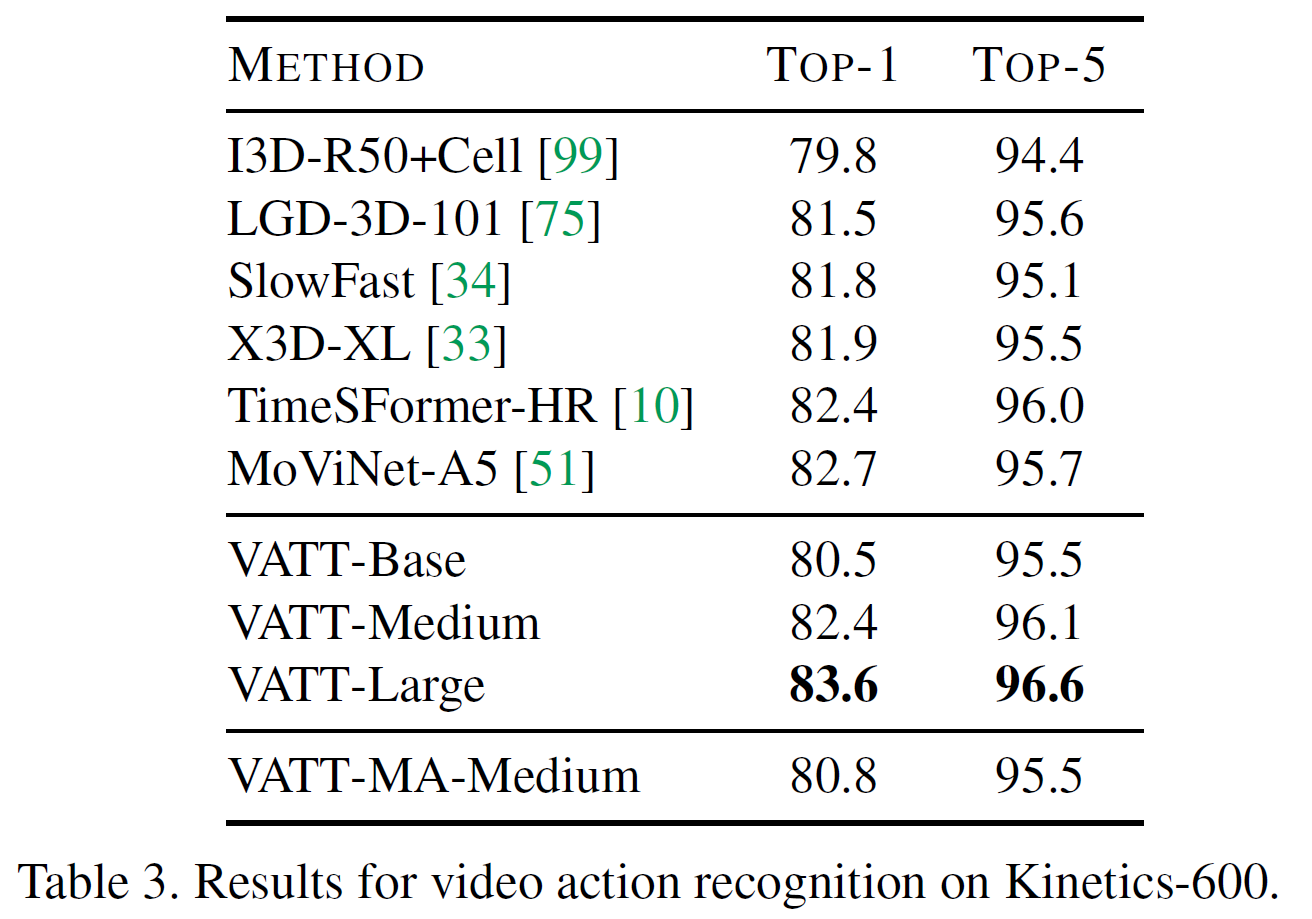
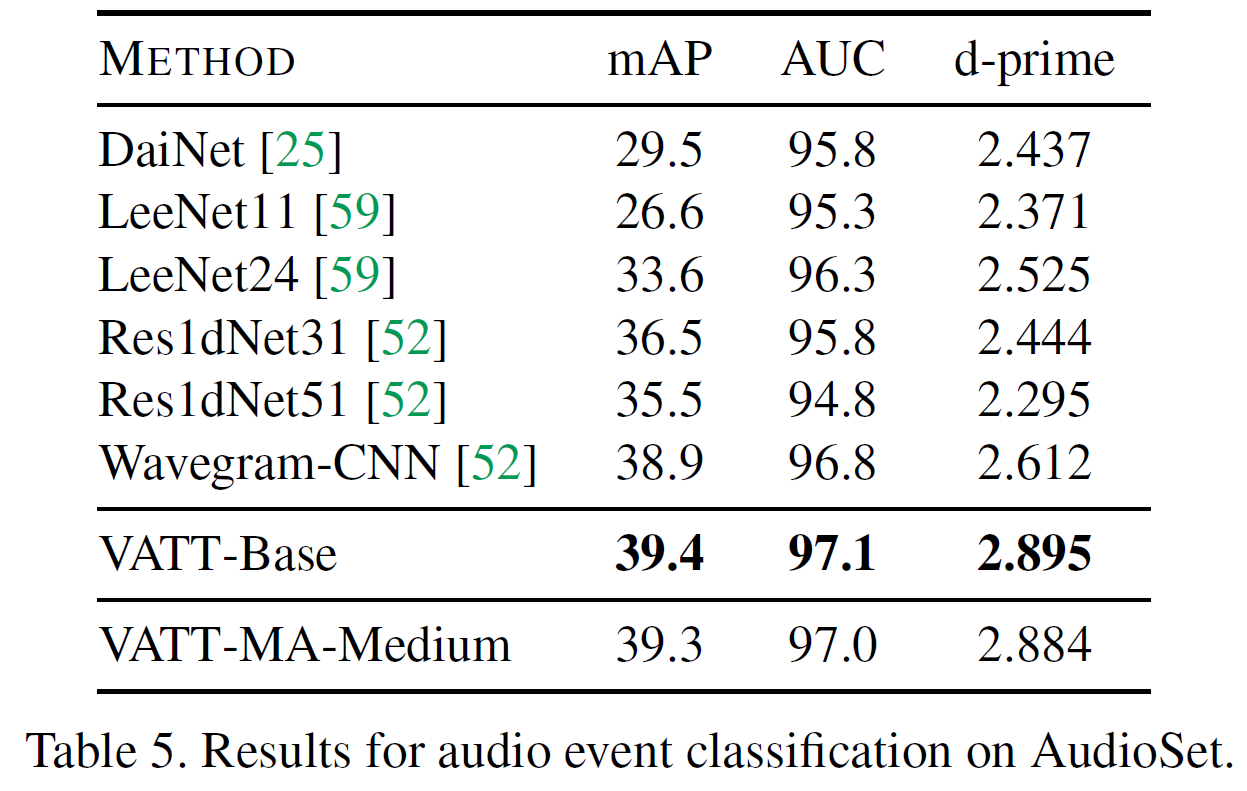
Fine-tuning for audio event classification
Fine-tuning for image classification

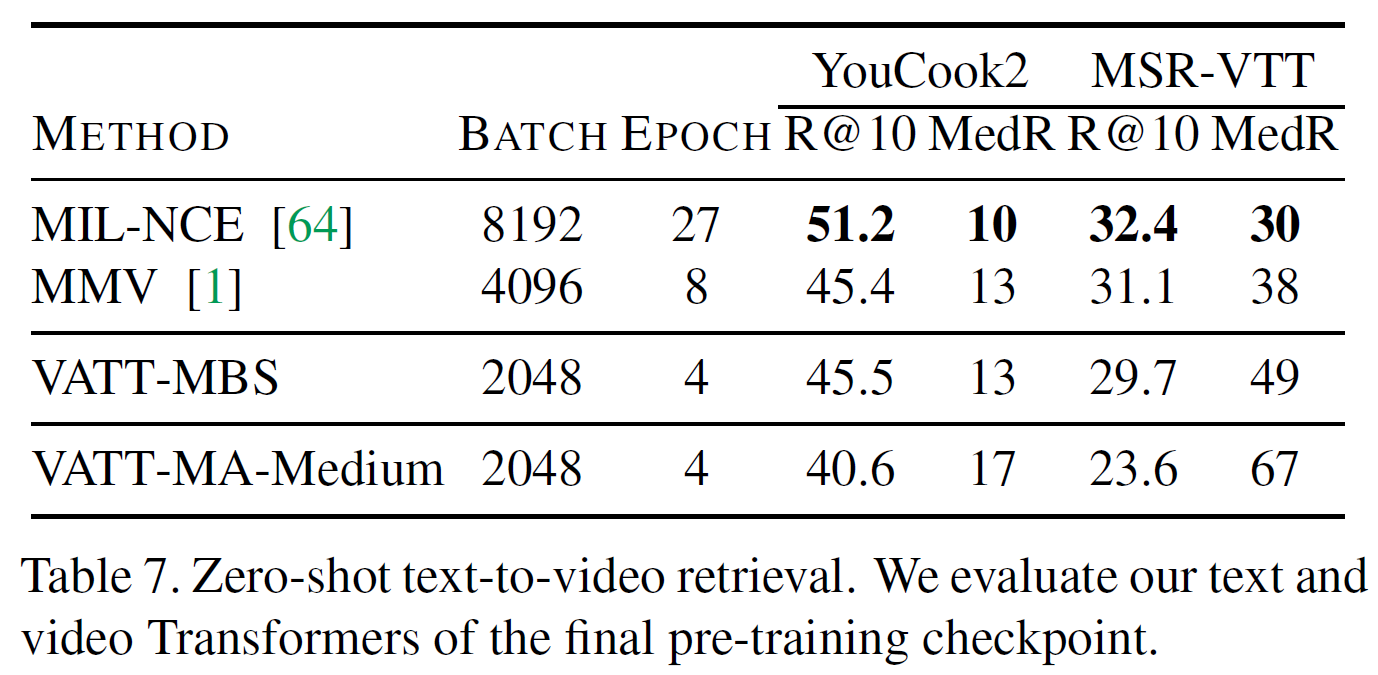
Zero-shot text-to-video retrieval
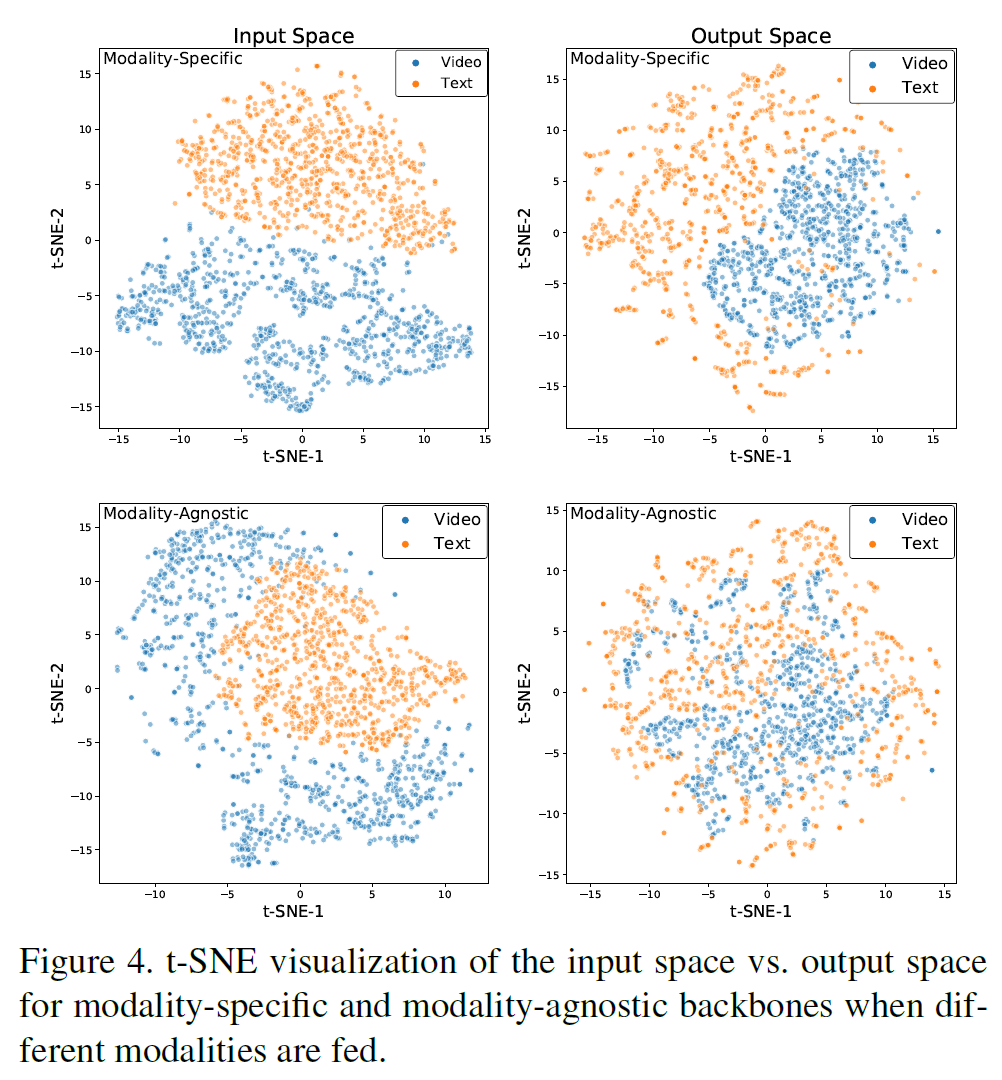
Feature visualization

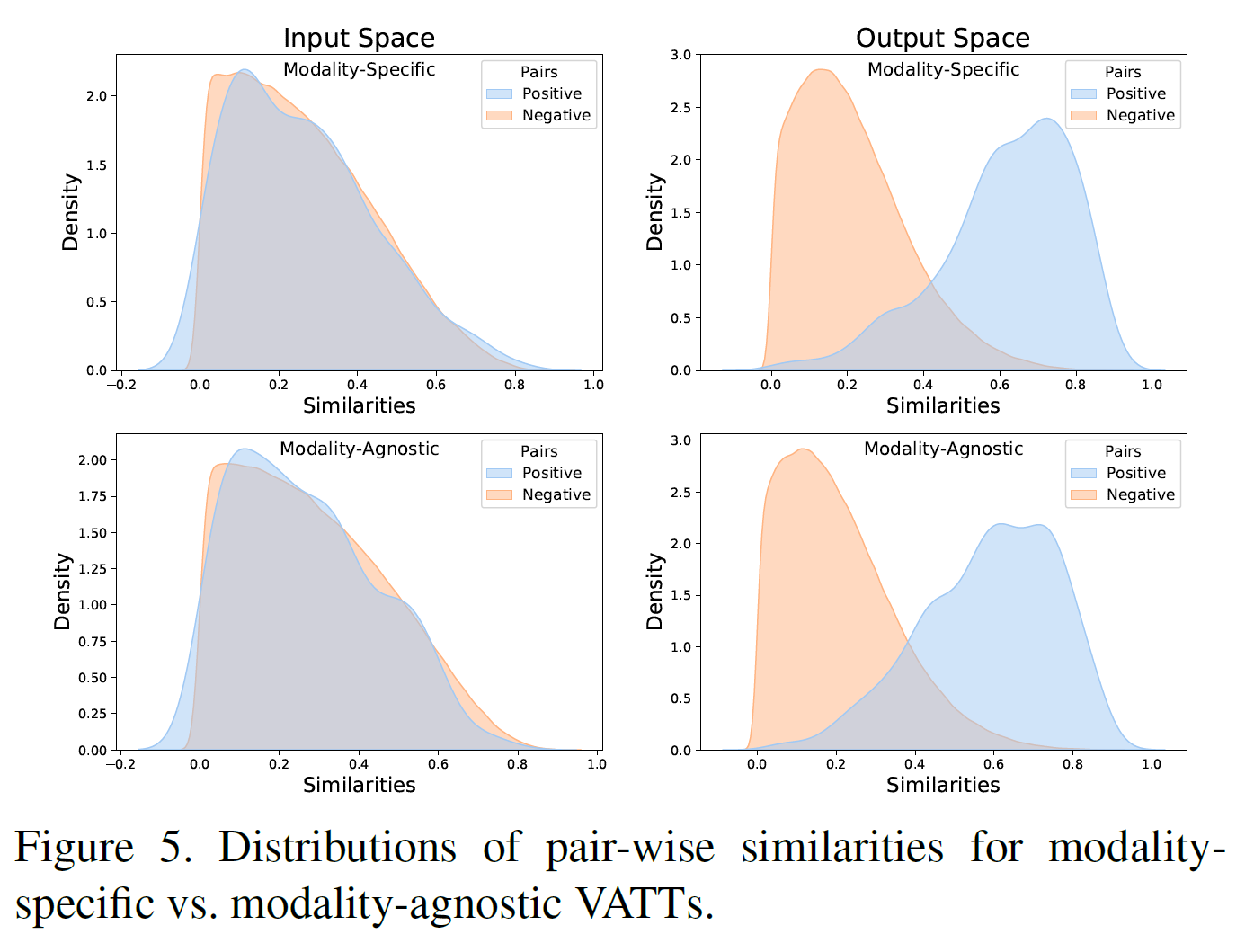
Conclusions
(작성 중)
