2022년 구글에서 발표한 PaLM(Pathways Language Model) 모델에 Multi-modal 특성을 더한 PaLM-E이 2023년 3월에 발표되었다. 대화형 AI에 자주 쓰인 초대형 언어 AI모델들은 아직 로봇에까지 적용되기에는 무리가 있다. 로봇은 상황에 맞는 동작을 수행하기 위해서 언어 뿐만 아니라 다양한 data의 자극에 반응해야 한다. 이에 기존에 발표했던 초대형 언어 모델인 PaLM에 image deep learning을 접목한 multi-modal AI model인 PaLM-E에 대해 알아보고자 한다.
Intro
이론적 배경
PaLM 모델
https://velog.io/@tobigs-nlp/PaLM-Scaling-Language-Modeling-with-Pathways-1
https://coding-moomin.tistory.com/38
https://coding-moomin.notion.site/PaLM-Scaling-Language-Modeling-with-Pathways-1f078d7e77284728ae7a31a4ca9dbefd
위 두 링크의 내용을 참고하여 작성하였다.
GPT-3로 촉발된 대규모 언어 모델 시장의 붐은 여러 대규모 언어 모델들과 후속 연구들로 NLP 연구에 큰 유행을 불러오고 있다. 대규모 언어 모델 연구들이 갖는 특징은 아래와 같다.
1. 점점 커지는 모델의 크기 (depth & width)
2. 더 정제되고 더 많은 학습 데이터
3. model capacity의 증가
PaLM도 위의 특징을 모두 갖추고 있다. 다만, 기존의 모델들이 model fine tuning을 위해서 꽤 많은 양의 task-specific training examples를 필요로 하고 요구하는 task에 맞춰 model의 parameter를 update 해야한 다는 점이 한계였다. PaLM은 Scaling the size, 즉 모델의 크기를 키움으로써 한계를 극복하고자 하였다.
총 540-billion의 parameter를 사용하였으며 780 billion tokens of high quality text를 사용했으며, 여기에 Pathways라는 방법을 이용했다.
Pathways는 매우 큰 사이즈의 모델을 2대의 TPU v4 Pods를 이용해 학습의 효율성을 올리는 방식인데 구체적인 것은 링크를 참고하면 좋다.
ViT-22B
ViT는 Vision Transformer로 image classification task에 Transformer를 적용시킨 것이다. 이 모델에 대한 연구는 Attention에 온전히 의존하는 구조가 CNN에 필적하는 image 인식 능력이 있음을 보였으며, 표준 ImageNet dataset보다 더 큰 크기의 dataset에서 image recongnition performance를 실험 했을 때 기존의 ResNets 기반의 CNN보다 더 좋은 성능을 내는 것 또한 확인되었다.
이에 관한 후속 연구 중에서 가장 최신의, 그리고 가장 발전된 형태의 ViT-22B를 PaLM에 결합해서 만든 multi-modal model이 PaLM-E이다.
Multi-modal
robotic model은 인간이 인지하는 감각에 가까운 실제 세계를 반영하여 최선의 행동을 하도록 설계해야 한다. 기존의 모델들이 하나의 data type만 학습하여 실제 세계를 인지하는 것에 한계가 있었다면, 여러 data type을 학습하도록 만든 것이 Multi-modal 기술이며 이는 robotic model에서 중요한 역할을 하고 있다.
Google에서 발표한 PaLM-E도 그런 multi-modal 기술이 응용된 것이다. 이 기술은 강력한 LLM인 PaLM을 robotic agent로부터 얻은 센서 데이터를 보완함으로써 구체화(Embodied)한 것이 특징이다.
PaLM-E의 핵심적인 학술적 기여
https://cartinoe5930.tistory.com/entry/PaLM-E-An-Embodied-Multimodal-Language-Model-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
위의 링크에서 발췌하길,
1. embodied 데이터를 multimodal LLM의 학습에 혼합해 범용적 모델, 전이 학습, 다중 구현 의사 결정 에이전트를 교육할 수 있음.
2. 현재 SOTA visual-language model은 zero-shot 추론 문제를 잘 다루지 못 함. 하지만, 유능한 범용 visual-language model을 훈련하는 것이 가능함.
3. neural scene representation과 entity-labeling multimodal token 같은 새로운 architecture을 제안하였음.
4. PaLM-E는 visual과 language과 같이 다방면에 대해서 질적으로 유망한 모습을 보여줌.
5. 모델의 크기를 늘리는 것이 적은 catastophic fogetting과 함께 multimodal fine-tuning을 가능하게 함.
PaLM-E
모델 구조
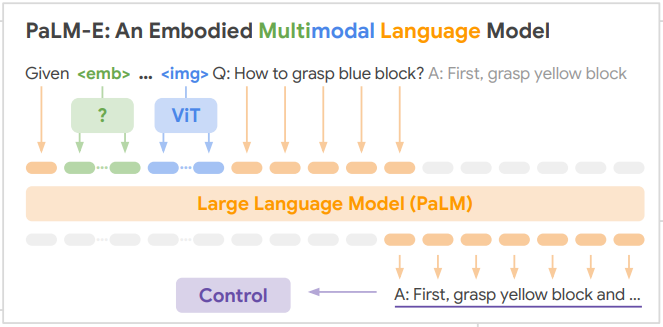
위 사진은 PaLM-E model의 구조도이다. 어떻게 PaLM-E가 서로 다른 data type을 이해하고 multi modal language modeling을 통해 task를 해결하는지 그리고 있다.
PaLM-E의 핵심 아이디어는 text와 image 입력을 NLP에서의 token embedding처럼 같은 차원의 representation으로 변환하는 enconder를 학습시키는 것이다. text input과 image input이 같은 차원을 갖고 있기 때문에 동일하게 LM으로 처리될 수 있다.
논문에서는 PaLM와 ViT-22B 모두 pre-trained model을 이용해 초기화했고 학습 과정에 있어서 parameter update가 있을 수 있다고 설명했다.
성능 테스트
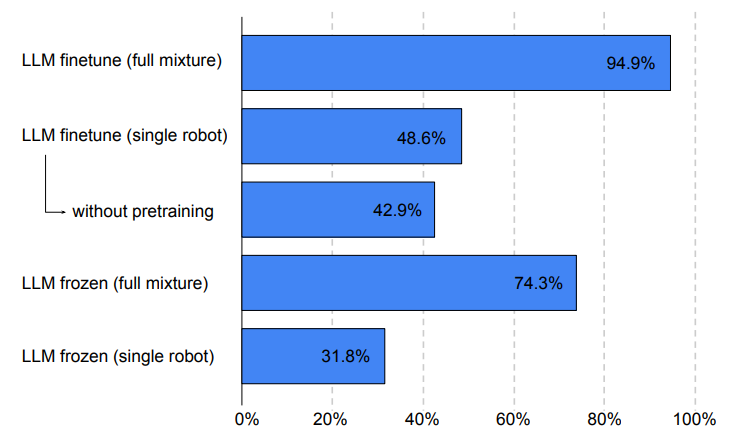
scratch로 학습한 다른 개별 model들의 robot performance와 PaLM + ViT를 결합한 model의 robot performance를 비교한 그래프이다.
PaLM-E는 text와 image를 한 번에 학습하여 처리함으로써 다방면으로 우수한 성능을 낼 수 있는 model 개발의 가능성을 보였다. 그래프를 보면, 각각의 task에 대해서 학습을 수행한 model에 비해서 PaLM-E가 robotics, vision, language task의 거대 dataset을 학습한 것이 오히려 높은 성능으로 동시에 task들을 수행할 수 있다는 것을 알 수 있다.
특히 vision-language dataset이 robot task의 성능을 크게 향상시키고 있었다.
그외 PaLM-E의 성능
https://blog.research.google/2023/03/palm-e-embodied-multimodal-language.html
위 링크로 들어가보면 실제 PaLM-E가 들어간 robot이 어떻게 행동하고 대답하는지 볼 수 있다. image 내에서 object detection을 수행하는 것이든, 상황에 따라 지시하는 내용을 수행하는 것이든 모두 우수한 성능을 보이고 있음이 확인되었다.
