TACOTRON2 : Natural TTS Synthesis By Conditioning WAVENET On Mel Spectrogram Predictions
논문 리뷰
Text-to-Speech 기술에 WaveNet, Tacotron 등이 접목되면서 전보다 더 고품질의 음성을 합성할 수 있게 되었다. 여러 미디어 채널에서는 TTS를 이용해서 재밌는 합성된 음성을 활용하고 있고 앞으로도 TTS를 사용하는 사람들은 늘어갈 전망으로 보인다.
Tacotron2는 Google에서 Tacotron1 기술의 한계점을 뛰어넘기 위해 개발한 것으로 Tacotron1과 비교해서 기술 설명을 이해하면 좋을 것이다.
Intro
이론적 배경
WaveNet
https://joungheekim.github.io/2020/09/17/paper-review/
https://music-audio-ai.tistory.com/2
위 링크들을 참조했다.
Tacotron2에서는 WaveNet을 변형한 Vocoder를 사용한다. (Vocoder: Text-to-Mel spectrogram model이 만들어낸 spectrogram을 실제 음성의 Waveform으로 바꾸어주는 모델)
WaveNet은 Google의 DeepMind사에서 공개한 End to End 음성 생성 모델이다. 이는 30개의 Residual Block을 쌓은 구조를 갖고 있으며, Input으로 정수 array를 받아 Residual Blocks를 거쳐 나온 값을 Skip Connection을 통해 합쳐 최종 Output을 내는 구조이다.
원래 NN의 구조를 음성 데이터에 적용하는 것은 쉬운 일이 아니지만(audio data는 sample의 수가 너무 많음.), 그럼에도 NN이 image나 text에서 우수한 성능을 내던 것을 감안하여 이를 audio에도 적용하고자 PixelCNN의 방식을 수정하여 사용한 것이 특징이다.
이 논문 자체만으로도 Audio deep learning model에서는 중요한 역할을 하는 만큼 이 논문은 나중에 자세하게 다뤄볼 예정이다.
mel-spectogram
https://walkaroundthedevelop.tistory.com/129
https://judy-son.tistory.com/6
위 링크를 참조했다.
위의 WaveNet에 대해서 설명할 때 언급했듯이 audio data는 sample의 수가 너무 많아 그대로 deep learning model에 사용하기 어렵다는 단점이 있다. 그래서 이를 완화하고자 사용하는 방식 중 하나가 mel-spectrogram인데, 이는 소리의 파형을 인간이 들을 수 있는 가청 주파수 범위인 Mel-scale로 down scaling한 후 그 파형을 그림으로 그린 것이다.
이를 이용해서 sample의 수를 줄여 데이터를 압축하는 효과를 가져올 수 있다.
short-time Fourier transform (STFT)
전자전기공학 전공 수업을 부전공하면서 지겹게도 들어온 것이 Fourier transform이다... 그 중에서도 STFT는 전체 데이터가 아닌 데이터를 일정 구간으로 나눠 짧은 구간마다 각각 Fourier transform을 수행하는 것을 말한다.
Fourier transform은 time domain의 data를 frequency domain의 data로 변환하여 data의 주파수 성분 분포를 보기 위해 사용하는 연산법이다. STFT는 그런 주파수 성분의 관찰 목적에 있어서 특정 원하는 시간대의 주파수 성분을 관찰하기 위해서 시간대 별로 각각 연산을 하는 것이다.
Ablation study
특이한 용어이고 맥락 상 어떠한 성능 평가 지표처럼 보여 이게 무엇인지 따로 찾아보았다. 쉽게 말하자면 논문에서 제시하는 기술이 그 task를 수행함에 있어서 기여하는 정도를 평가하는 것이다.
여기서 Ablation이란 "제거"라는 뜻인데 task를 수행하는 전체 system에서 성능을 평가하고자 하는 특정 부분을 삭제하고 성능 평가를 하여 비교함으로써 그 특정 부분의 기여도가 어느 정도인지 확인하는 연구 기법이라 생각하면 된다.
Tacotron1
원본 논문은 Tacotron이다. 후에 좀더 보완된 논문으로 Tacotron2가 나왔기 때문에 구분을 위해서 Tacotron1이라고 했다.
이 논문은 2017년에 Google에서 발표한 TTS 모델이다. 특징은 텍스트를 입력으로 받아서 raw spectrogram을 바로 생성할 수 있다는 것과 <text, audio> 쌍을 이용해서 End to End로 바로바로 학습이 가능하다는 것이다.
 이 자체로도 중요도가 꽤 높은 논문이어서 아예 새로 논문 리뷰를 할 법도 하다.. 일단 중요한 건 이 Tacotron1은 Output layer, attention module, loss function, Griffin-Lim-based waveform synthesizer에 대해서 개선 가능성이 있었다는 것이다.
이 자체로도 중요도가 꽤 높은 논문이어서 아예 새로 논문 리뷰를 할 법도 하다.. 일단 중요한 건 이 Tacotron1은 Output layer, attention module, loss function, Griffin-Lim-based waveform synthesizer에 대해서 개선 가능성이 있었다는 것이다.
Tacotron2
Architecture
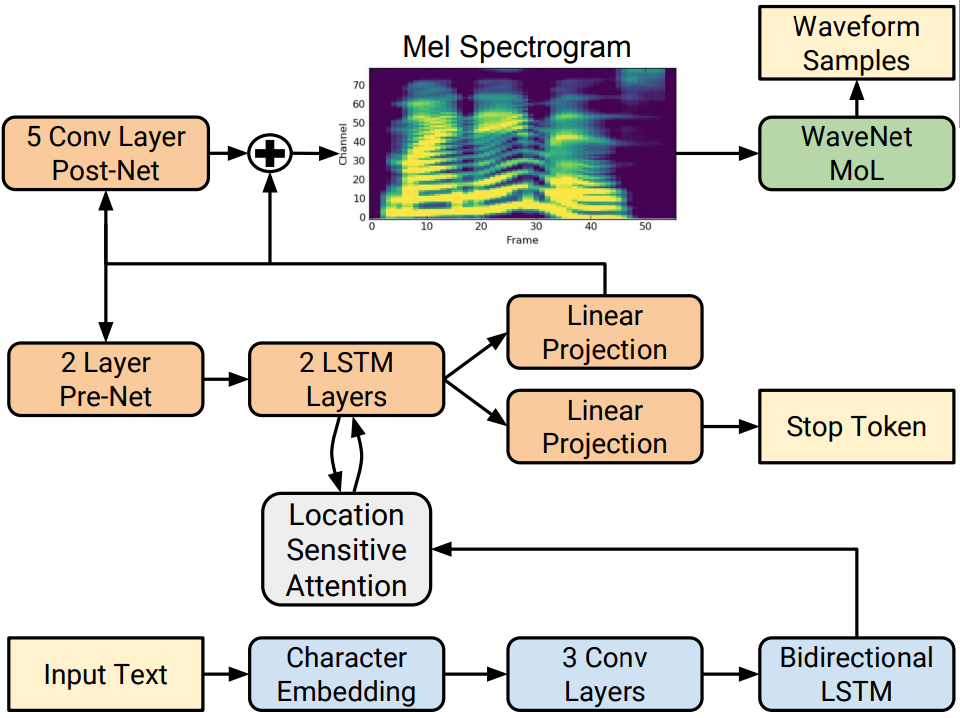
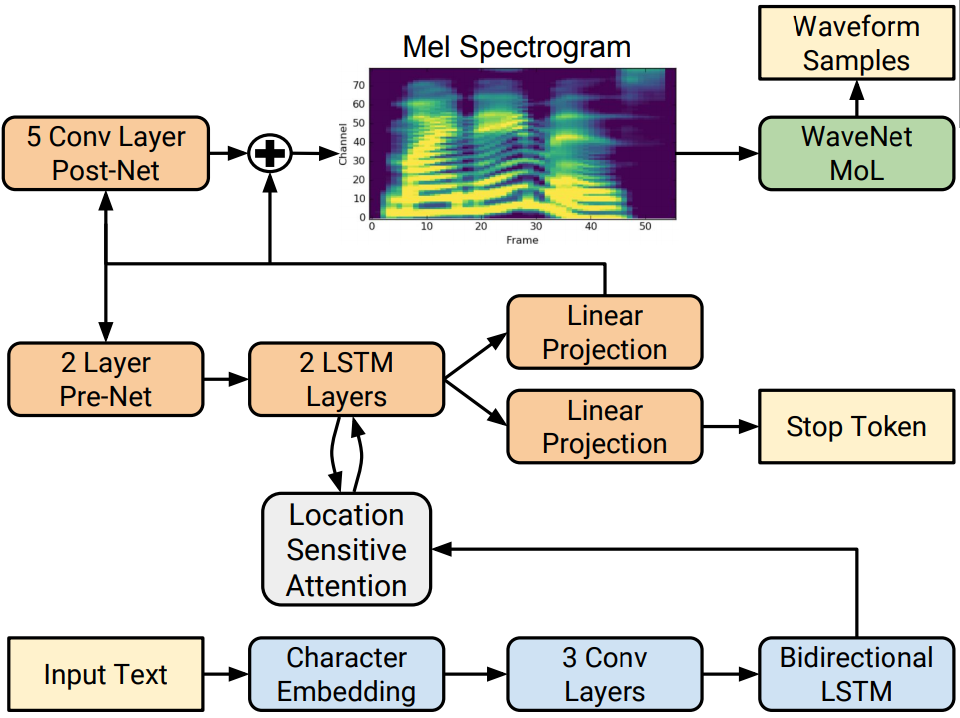 위 그림은 Tacotron2의 전체적인 구조에 대해서 간단히 그린 그림이다.
위 그림은 Tacotron2의 전체적인 구조에 대해서 간단히 그린 그림이다.
이 모델은 supervised learning model로 input과 output이 한 쌍으로 묶인 training dataset이 필요하다. 이 dataset을 위해 데이터를 전처리 해야하는데 여기서 model의 Input = text, Output = Mel-spectrogram인 점을 생각해야 한다. 어차피 실제 Voice로의 변환은 WaveNet이 해줄거니까 Tacotron2 model은 WaveNet의 input이 되는 mel-scpectrogram을 생성하는 것까지가 제 역할이다.
그래서 text input은 character로 만들고, 음성은 mel-spectrogramd로 바꾸는 전처리 과정이 필요하다. 여기서 STFT와 Mel-scaling, Log-transform이 사용된다. 구간별 주파수 정보를 추출하여 이를 가청 주파수 범위로 범위 조정을 한 다음 amplitude domain에서 log scaling을 취하면 mel-spectrogram이 만들어진다.
Encoder
 이 부분은 Text input을 Attention module에 전달하기 위해 feature extraction을 수행하는 부분이라 생각하면 된다.
이 부분은 Text input을 Attention module에 전달하기 위해 feature extraction을 수행하는 부분이라 생각하면 된다.
Attention module
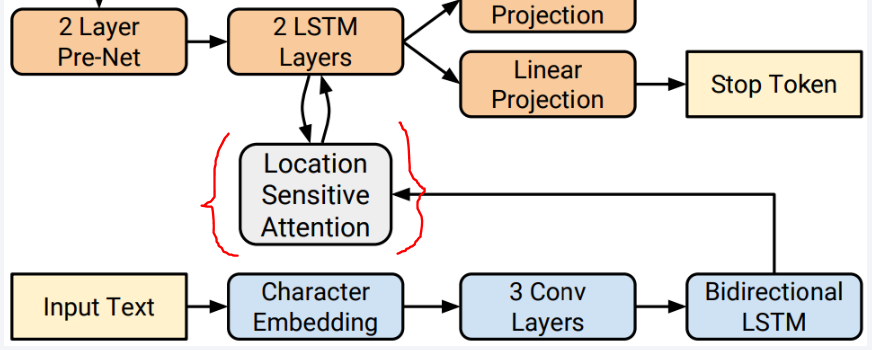 Encoder로 들어온 Text input 정보를 Decoder에서 사용할 정보로 정리하는 역할을 하는 부분이다. Decoder에 정보를 전달하기 위해 Encoder의 feature vector 중 가져올 정보만 추출해서 alignment한다. 여기서는 Location Sentitive Attention을 사용하는데, 다음 시점(t)의 attention alignment를 구할 때 이전 시점(t-1)에서 생성된 attention alignment를 추가로 고려하는 방식이다.
Encoder로 들어온 Text input 정보를 Decoder에서 사용할 정보로 정리하는 역할을 하는 부분이다. Decoder에 정보를 전달하기 위해 Encoder의 feature vector 중 가져올 정보만 추출해서 alignment한다. 여기서는 Location Sentitive Attention을 사용하는데, 다음 시점(t)의 attention alignment를 구할 때 이전 시점(t-1)에서 생성된 attention alignment를 추가로 고려하는 방식이다.
Decoder
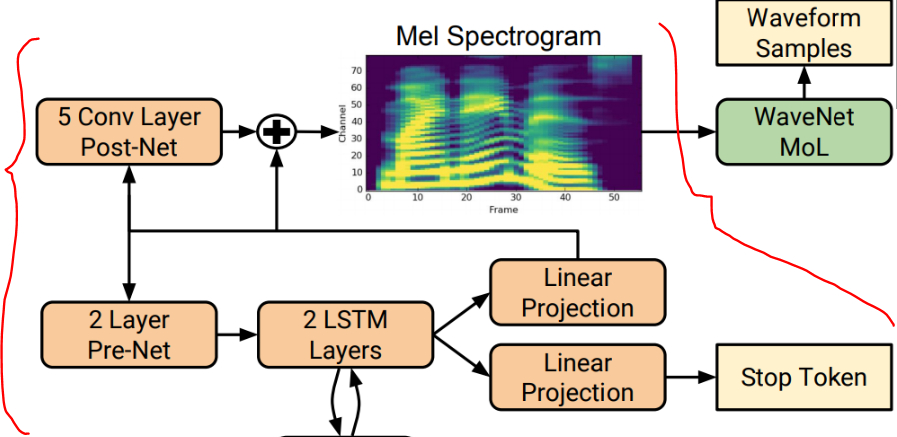 Decoder는 Attention 거쳐 들어온 Text input의 내용을 학습한 대로 mel-spectrogram으로 변환하는 역할을 한다. 이는 pre-net과 LSTM으로 구성되어 있다. pre-net은 2개의 FC layer와 ReLU로 구성되어 있는데 이는 bottle-neck 구간으로써의 역할을 하여 중요 정보만 남기는 거름망 역할을 한다. 그 다음에 배치된 LSTM은 Attention layer의 정보와 pre-net으로부터 전달 받은 정보를 이용해 (t) 시점의 정보를 생성한다.
Decoder는 Attention 거쳐 들어온 Text input의 내용을 학습한 대로 mel-spectrogram으로 변환하는 역할을 한다. 이는 pre-net과 LSTM으로 구성되어 있다. pre-net은 2개의 FC layer와 ReLU로 구성되어 있는데 이는 bottle-neck 구간으로써의 역할을 하여 중요 정보만 남기는 거름망 역할을 한다. 그 다음에 배치된 LSTM은 Attention layer의 정보와 pre-net으로부터 전달 받은 정보를 이용해 (t) 시점의 정보를 생성한다.
Experiments
위와 같이 만들어진 Tacotron2 model의 성능은 다음과 같이 평가되었다.
MOS 평가란 Mean-Opinion-Score라 하여 피실험자가 1~5점까지 각각의 음성을 듣고 평가하는 실험을 통해 TTS의 성능을 측정했다.
Evaluation
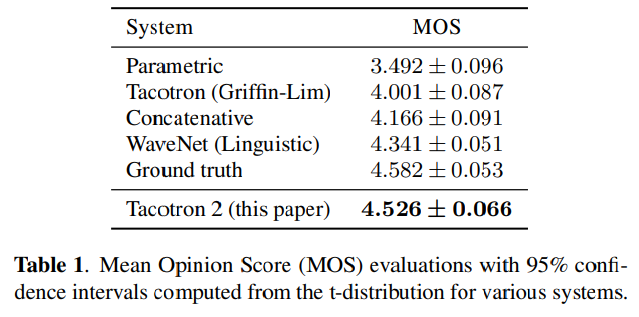 이 표를 보면 Tacotron2가 Ground Truth에 가장 가까운 점수를 받은 것을 알 수 있다.
이 표를 보면 Tacotron2가 Ground Truth에 가장 가까운 점수를 받은 것을 알 수 있다.
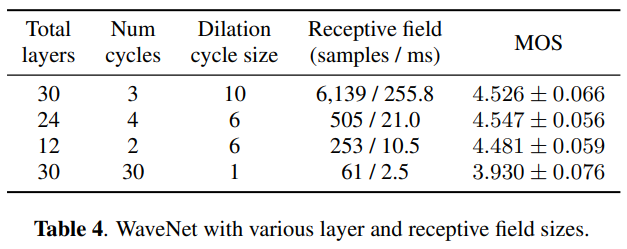
Ablation studies
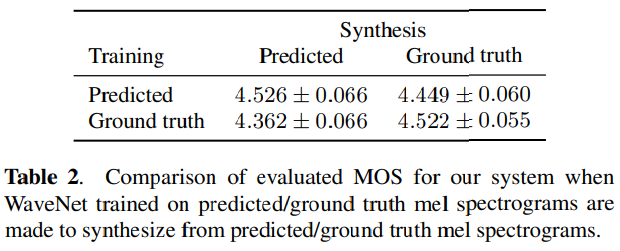
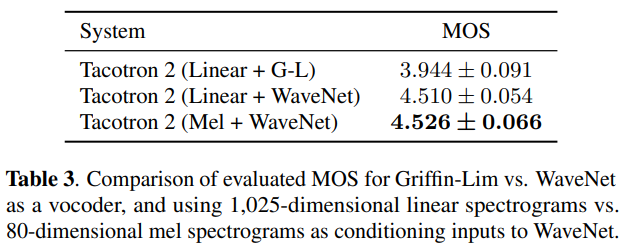
이 연구를 이용해서 각각의 요소의 중요도를 평가했는데 결과는 아래와 같다.
Conclusion
Tacotron1에서 부터도 음성 데이터를 다뤄본 경험이 적은 개발자가 쉽게 TTS를 개발해볼 수 있게 되었다는 점에서 큰 장점이 있었는데 그런 장점은 살리고 좀더 좋은 성능을 만들어낸 것 같다. Tacotron1에서는 CBHG 구조가 중요한 역할을 한다고 했으나 그 구조를 사용하지 않고도 더 높은 성능을 냈다는 점에서 후속 연구를 통한 성능 보완의 중요성을 알 수 있었다. 또한 Tacotron1, 2는 최종 음성을 만들어내는데 있어서 mel-spectrogram을 voice로 바꾸는 WaveNet을 사용했는데 그래서 실질적으로 음성 자체를 생성하는 것의 성능은 WaveNet이 담당했다고 볼 수 있다. 다만 text를 WaveNet에 얼마나 좋은 feature vector로 전달했느냐가 핵심인 듯 하다. WaveNet은 음성을 생성하는데 걸리는 시간이 꽤 오래 걸리는 편이기 때문에 실시간성에 대해서는 여전히 한계가 있다.
