NumPy
파이썬을 주로 사용한다면, 아니 주로 사용하지 않더라도 Python 하면 NumPy 라이브러리를 한번쯤 들어보았을 것이다. import를 사용하여 라이브러리를 다운받고, 주로 별칭(as)을 사용하여 np라고 작성한다.
import numpy as npNumPy가 뭔데?
NumPy를 길게 말하면 Numerical Python라 한다. pythondptj 수치계산을 위한 핵심 라이브러리로, ndarray(N-dimensional array) 자료 구조를 지원한다.
여기서 우리가 주목해야할 것은 ndarray이다.
ndarray는 기본적으로 다양한 수학 함수를 지원하며, 주로 배열끼리의 연산을 할 때 자주 사용한다. python은 느리다는 공공연한 사실이 있지만 이 라이브러리는 c언어를 배경으로 만들어져 상당히 빠른 속도를 자랑한다. ndarray로 만든 배열은 차원을 동일시 하는 '브로드캐스팅'기능과 다타원의 배열을 지원한다.
ndarray 생성
ndarray 생성하는 방법은 어렵지 않다.
np.array(리스트 or 튜플)ndarray또한 하나의 배열이라 할 수 있기 때문에 꼭 시퀀스 자료형을 넣어줘야한다.
list1 = [1,2,3,4,5]
arr1 = np.array(list1)
arr1
#결과 : array([1, 2, 3, 4, 5])
arr2 = np.array([1,2,3,4,5])
arr2
#결과 : array([1, 2, 3, 4, 5])
list2 = [[1,2,3],[4,5,6]]
arr3 = np.array(list2)
print(list2)
print(arr3)
#결과 : [[1, 2, 3], [4, 5, 6]]
#[[1 2 3]
# [4 5 6]]
#array([[1, 2, 3],
# [4, 5, 6]])2차원 ndarray의 경우 차원을 인식하여 행과 열에 맞게 출력이된다.
앞서 설명했듯, 브로드 캐스팅은 차원소를 동일시 판단하는 기능이다.
list1 = [1,2,3]
list2 = [4,5,6]
#리스트의 경우 문자열을 연결하듯이, 하나의 리스트로 이어붙임
print(list1 + list2)
#결과 : [1, 2, 3, 4, 5, 6]
#ndarray의 경우 차원을 인식해서 각각의 요소들의 연산을 수행
arr1 = np.array(list1)
arr2 = np.array(list2)
print(arr1+arr2)
#결과 : [5 7 9]
#2차원과 1차원을 더했더니, 각각의 요소들을 찾아서 연산을 수행
arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.array([7,8,9])
print(arr3+arr4)
#결과 : [[ 8 10 12]
# [11 13 15]]
# 1차원과 0차원(요소하나) 를 곱했더니, 각각의 요소들을 찾아서 연산을 수행
arr5 = np.array([1,1,1])
print(arr5 * 5)
#결과 : [5 5 5]결국 리스트 내부에 직접적으로 편하게 연산할 수 있는 것이 브로드 캐스팅이라 할 수 있다.
ndarray 확인하기
ndarray를 확인하기 위해서는 여러가지 속성(키워드)를 사용하면 된다. 여기서 주의할 점은 함수가 아니기 때문에 소괄호'()'를 사용해서는 안된다.
array의 모양(크기) 확인하기 : .shape
print(arr3.shape)
print(arr4.shape)
결과 : (2, 3) #2열 3행
: (3,) #1차원이기 때문에 3개라는 뜻array의 차원 확인하기 : .ndim
print(arr3.ndim)
print(arr4.ndim)
결과 : 2
: 1arrayl의 전체 요소 개수 확인하기 : .size
#len() > 배열의 첫 번째 차원의 '길이'를 반환
#size > 각각의 오소들의 개수를 반환
arr3.size
결과 : 6arr1 = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
print(arr1)
print(f"배열의 모양(크기) : {arr1.shape}")
print(f"배열의 차원 : {arr1.ndim}")
print(f"배열의 요소개수 : {arr1.size}")
결과
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
shape(모양) : (2, 2, 2)
ndim(차원수) : 3
size(요소 전체 개수) : 8
dtype(데이터 타입) : int32ndarray dtype 및 shape변경
ndarray는 생성시 요소의 데이터 타입을 직접 지정해서 생성할 수 있다.
list3 =[[1.7, 4.2, 3.6],[4.1,2.9,5.8]]
temp1 = np.array(list3)
#실수형을 정수형으로 데이터 타입 형 변환
temp2 = np.array(list3, dtype = np.int64)temp1에는 실수형의 데이터가 저장되어있지만
temp2에는 생성할 때 dtype을 np.int64로 지정해주었기 때문에 소숫점이 사라진 정수형태로 생성된다.
(옛날에는 int32로 많이 했지만 현재는 하드웨어의 발전으로 인해 더 큰 수로 할 수 있다는 사실!)
그렇다면 만들어진 array의 타입을 바꿀 수 있을까?
김종국 : 당연하지!
array명.astype(변경데이터타입)으로 작성하면 된다.
temp1.astype(np.int64)근데 이렇게만 하면 temp1이 저절로 바뀌느냐?
아니다. 다시 변수에 넣어줘서 갱신을 해야한다.
temp1 = temp1.astype(np.int64)모양 바꿔주기는 .reshape(행,열) 이 함수를 사용하면 되는데 이 함수도 다시 갱신을 해줘야만 실제로 적용이 된다.
temp1 = temp1.reshape(3,2)특정한 값으로 ndarray 생성하기
이 내용은 따로 설명할 내용이 없으니 바로 코드로 보여주겠다.
#모든 값을 0으로 초기화
#np.zeros((행, 열)) > 2차원 이상의 array인경우 튜플로 감싸주어야 함!
arr_zeros = np.zeros((5,2))
#모든 값을 1로 초기화
arr_ones = np.ones((5,2))
#모든 값을 원하는 값으로 초기화
#np.full((행,열), 원하는 값)
arr_full = np.full((5,2), 5)
#랜덤값으로 배열 생성하기(int 형)
#np.random.randint(시작값, 끝값, size=(행, 열))
#random 라이브러리의 randint는 끝 값을 포함 했었음
#np 에서 제공하는 randint는 끝 값을 포함하지 않음
arr_randint = np.random.randint(1,11,(5,6))
#ndarray로 범위 만들기
#np.arange(시작값, 끝값, 증감량) 끝값 포함 x
arr2 = np.arange(1,51) #array 생성(1차원)
arr2.reshape(5,10) #5행 10열로 만들기랜덤값도 가끔 사용하는 편이니 숙지하도록 하자!
np.random.randint(시작값, 끝값, (행,열))
ndarray또한 신텍스 데이터로 이루어져있기 때문에 인덱싱과 슬라이싱이 가능하다.
#1차원 array 생성 후 인덱싱
arr_1 = np.arange(10) #시작값 생략 가능
print(arr_1)
arr_1[7]
결과 : 7값을 수정하는 것 또한 list와 차이가 있다.
#리스트 값 수정
list1[3:8]=[10]
print(list1)#범위가 하나의 요소로 변환
결과 : 0,1,2,10
#array값 수정
arr_1[3:8]= 10
print(arr_1)#각 요소들에 값을 하나하나 수정
결과 : 0 1 2 10 10 10 10 10 8 9그렇담 2차원 ndarray의 인덱싱과 슬라이싱은?
인덱싱 : array명[행, 열]
슬라이싱 : array명[행의 시작값 : 행의 끝값, 열의 시작값 : 열의 끝값]
일반적인 인덱싱 : arr[3][3]
튜플 인덱싱 : arr[3,3]
- 이 둘의 차이점으로 일반 인덱싱은 두번의 연산을 수행하고, 튜플 인덱싱은 인덱싱을 한번에 연산한다는 차이가 있다.
- 성능적인 측면에서 튜플인덱싱을 사용하는 것이 유리하기 때문에 튜플 인덱싱을 자주 이용하자!
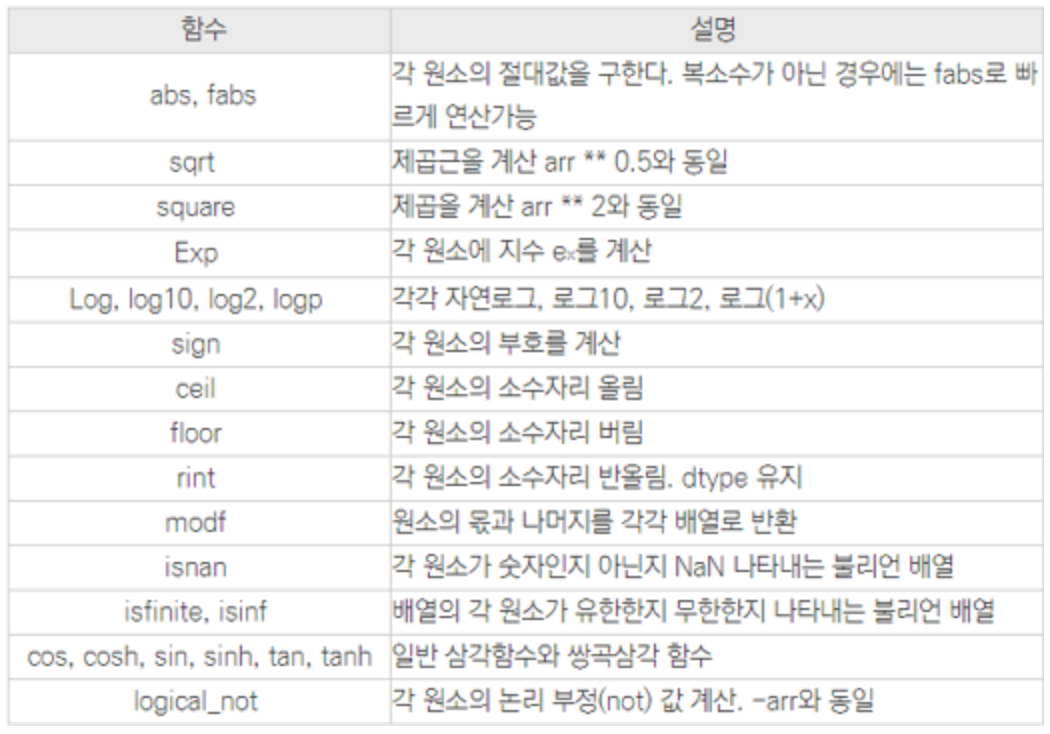
ndarray연산함수
ndarray의 연산함수는 짱 많다
#2행 5열인 랜덤 array 생성
arr = np.random.randint(1,10, size=(2,5))
#python 기본 내장 함수
print(sum(arr))
#numpy sum
print(arr.sum())
print(np.sum(arr))
#mean() : 평균
print(arr.mean())
print(np.mean(arr))
#sqrt() : 제곱근(루트)
print(arr.sqrt()) # 이건 안됨
print(np.sqrt(arr)) # 이건 됨이외에도 아주 많은 함수를 가지고 있다.
- 서로 다른 배열간에 사용하는 함수

Boolean 인덱싱
고급 인덱싱이라고도 불리며, 배열 안에서 조건을 충족하는 true인 값들만 추출하는 인덱싱 방법이다. 간단히 설명하자면 필터링!
1. array를 생성한다.
score = np.array([80,75,55,96,30])
2. mask 를 생성한다.
mask = score>=80
print(mask)
결과 : array([ True, False, False, True, False])
3. 생성된 mask를 배열 인덱싱에 넣어준다
score[mask]
print(score[mask])
결과 : array([80, 96])Boolean인덱싱은 상당히 많이 사용되고 중요하기 때문에 꼭 잊지 말고 숙지해야한다.
만약 결과값들을 csv 파일로 저장하고싶다면?
np.savetxt("파일명.csv", user, delimiter=',', fmt='%.3f')