톺아보다 : 틈이 있는 곳마다 모조리 더듬어 뒤지면서 찾다(순우리말).
이 글이 저의 Velog 첫 글이랍니다! 무슨 내용으로 글을 올려볼까 생각하다가, 최근에 공부하게 된 U-Net에 대해 정리해서 올려보려 합니다. 학부 인턴생으로 딥러닝을 제대로 공부한지, 2021.08.14 기준으로 한달이 채 되지 않았다는 점을 미리 알려드립니다(틀린 내용이 있을 수 있다는 밑밥이라는..). 그렇기 때문에 틀린 내용이 있어도 너그러이 봐주시면 고맙겠습니다!
일단 먼저 제가 참고한 링크를 맨 아래에 적어놓겠습니다. 링크 덕분에 정말 많은 도움 받았습니다. 작성자분들께 고맙다는 말씀드립니다. 또한, 이 글의 모든 사진은 U-Net 논문의 사진을 공부 내용에 맞게 재창작 했으며 인용문 또한 동일한 논문에서 발췌하였다는 것을 알려드립니다.
U-Net architecture
U-Net은 본래 Biomedical 분야를 위해 만들어진 FCN 기반의 모델입니다. 논문의 제목은 아래와 같습니다.
U-Net : Convolutional Networks for Biomedical Image Segmentation
위의 제목을 보면 알 수 있듯이 논문의 저자는 U-Net을 Biomedical 분야에 적용하기 위해 만든 것을 알 수 있습니다. 그 결과로 ISBI cell tracking challenge 2015라는 biomedical 분야의 대회에서 우승할 수 있었습니다. 또한, U-Net은 End-to-End 방식의 Fully-Convolutional Network(=FCN)를 기반으로 한 모델입니다.
본격적으로 U-Net의 구조를 알아보기에 앞서 간략한 이미지를 먼저 보여드리겠습니다.
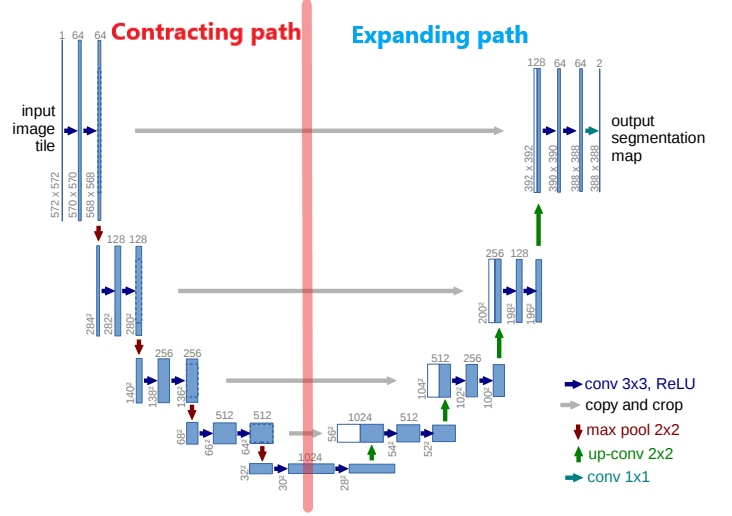
위의 사진에서 다른 내용은 다 제쳐두고 이거 하나만 기억하시면 됩니다. 빨간색 선을 기준으로 왼쪽은 Contracting Path, 오른쪽은 Expanding Path 입니다.
Contracting path를 한글로 번역해보면 "수축 경로" 정도의 의미가 되겠습니다. 반대로 Expanding path는 "확장 경로"라고 보시면 됩니다.
단어의 의미에서 알 수 있듯이 기존에 있던 이미지를 수축해주는 단계가 Contracting Path, 수축된 이미지를 확장해주는 단계가 Expanding Path입니다.
이러한 기본개념을 기억하시고 글을 읽으시면 더 원활한 이해가 될 것이라 생각합니다.
1. Introduction
이제 본격적으로 U-Net에 대해 설명드리겠습니다.
Sliding window setup
U-Net의 저자는 기존에 있던 sliding window 방식에 대해 언급하였습니다. Sliding window에 관한 자세한 설명은 링크를 참고해주시기 바랍니다. Sliding window 방식은 이전의 방법보다 두가지 측면에서 더 좋은 성과를 보여주었습니다.
First, this network can localize.
Secondly, the training data in terms of patches is much larger than the number of training images.
즉, localize를 할 수 있으며 training data의 patch가 training image 보다 훨씬 많다는 장점을 가졌습니다. 이러한 장점에도 불구하고 두가지의 단점(=Two drawbacks of sliding-window)이 존재합니다.
- 매우 느리다(=quite slow)는 것입니다. Sliding-window 방식의 경우 아래의 사진처럼, 검증이 완료된 patch에 대해 중복(=redundancy)해서 다음 patch를 검증하기 때문입니다.

- 해결방법
아래의 사진처럼 검증이 완료된 patch에 대해서는, 검증을 수행하지 않고 다음 patch로 넘어가게 됩니다. 이 덕분에 기존의 Sliding window 방식보다 더 빠른 속도로 patch를 검증할 수 있게 됩니다.

-
Localization의 정확도와 Context의 사용 간에 "trade-off" 가 발생합니다.
Context란, 번역하면 "문맥, 전후 사정, 맥락" 등으로 이해할 수 있습니다. 우리가 글을 읽을 때 단어 하나 하나의 의미를 통해 글의 전체 맥락을 파악하듯이, 이미지 처리에서도 마찬가지입니다. 패치를 이용하여 이미지의 일부분을 보고, 전체 이미지의 맥락을 파악하게 됩니다.
-
Larger patches의 경우, 더 많은 양의 max-pooling layer를 필요로 하는데 이는 곧 localization의 정확도를 떨어뜨리게 됩니다.
⇒ patch size가 커지면 더 넓은 범위의 이미지를 한 번에 인식할 수 있어 context 파악에 큰 효과가 있습니다. 하지만 넓은 범위를 인식하게 되므로 localization의 정확도에서는 성능이 떨어지게 됩니다.
-
반대로, small patches는 little context만을 관찰하게 됩니다.
⇒ 너무 작은 patch size로 인하여 좁은 범위의 이미지만을 관찰하게 됩니다. 이는 곧, context를 파악하는데 어려움을 겪게 됩니다.
-
-
해결방법
논문의 reference 4, 11번 논문에서 확인할 수 있듯이, 여러 layer의 output을 동시에 검증하게 되면 localization과 context 문제를 해결할 수 있게 됩니다.⇒ Contracting path에서 이미지의 context를 파악합니다. Expanding path에서는 feature map을 upsampling한 후에 Contracting path의 context와 결합하여 localization의 정확도를 높이게 됩니다.
∴ context (Contracting path) + upsampling (Expanding path) ⇒ accuracy of localization ↑ (combine)
2. U-Net architecture
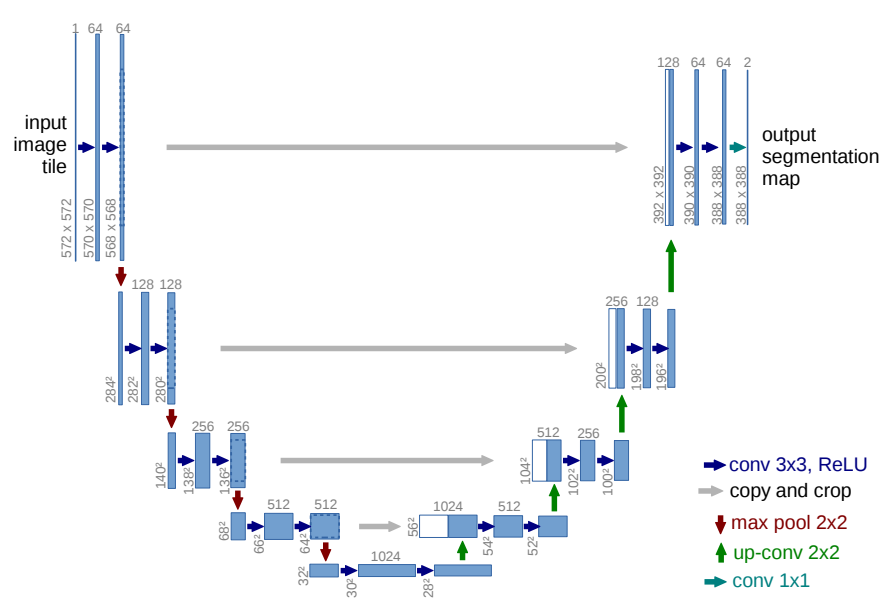
위의 사진은 논문에서 가져왔습니다. 위의 사진에 대한 설명은 아래와 같습니다.
- Blue box : multi-channel feature map
- White box : 복사된(=copied) feature map
- Top of the box : 채널의 수 표기
- The arrow : different operation
- Lower left edge of the box : X-Y size
U-Net의 특징에 대해 설명해보겠습니다.
2.1 No Fully Connected Layer ⇒ 연산속도 ↑
우선, U-Net의 경우 Fully connected layer가 아닌 Fully convolutional layer를 기반으로 하기 때문에, FC layer가 있는 네트워크보다 상대적으로 연산속도가 빠릅니다.
2.2 Overlap-tile strategy
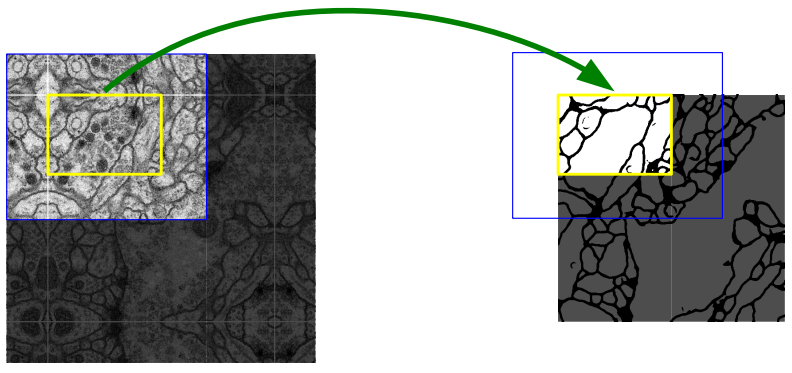
Overlap-tile strategy for seamless segmentation of arbitrary large images
Overlap-tile strategy에 관한 설명은 링크를 참고하시면 되겠습니다.
저자는 U-Net에 padding을 추가하지 않았습니다. 이로 인해 Input size가 Output size보다 더 크게 되는데, 위의 사진처럼 파란색 박스로 된 Input 이미지에 대해 노란색 박스로 된 Output 이미지의 결과를 얻게 됩니다.
2.3 Missing input data
위에서 설명했듯이, padding을 하지 않으므로 데이터 손실이 발생하게 됩니다.
- 해결방법
저자는 이에 대한 해결방법으로 "Mirroring extrapolation"이라는 방법을 사용하였습니다.
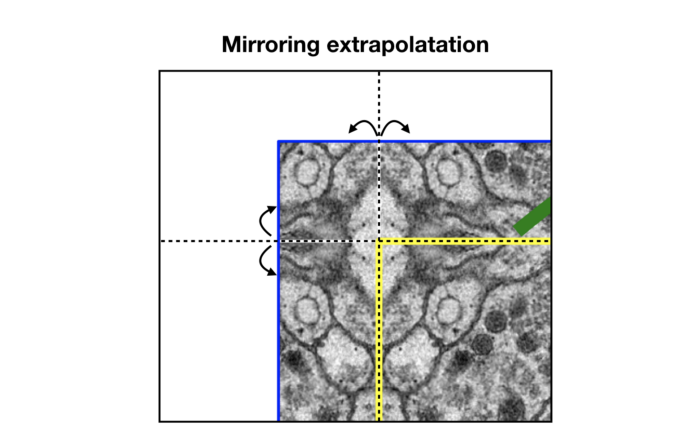
위의 사진을 보면 알 수 있듯이, 점선을 기준으로 mirroring 하는 것을 의미합니다. 즉, 거울에 반사되는 것처럼, 점선을 기준으로 반사 및 복제 되는 것을 의미합니다. 이 덕분에 손실된 이미지 데이터를 채울 수 있게 됩니다.
2.4 Contracting path vs Expanding path
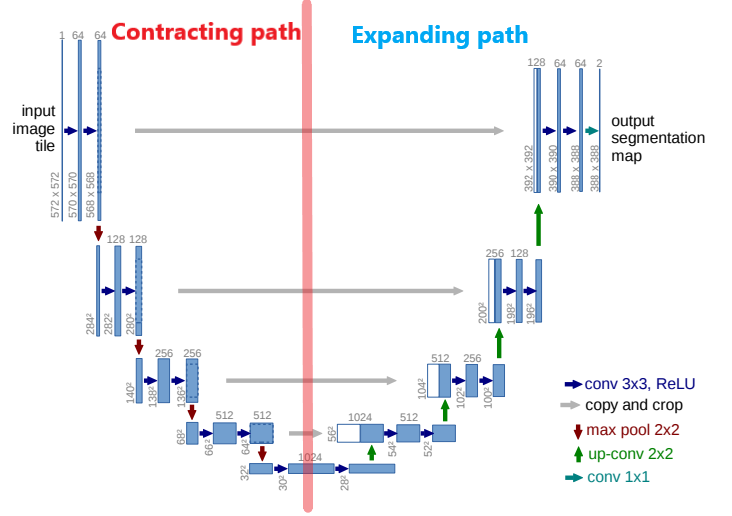
-
위의 사진에서, Contracting path의 풀링 바로 전 단계의 feature map을 copy한 것을 확인할 수 있습니다. Copy한 것을 Expanding path의 feature map에 concatenate(연결) 한 결과가, 흰색 박스(white box)입니다.
이 때, 손실된 데이터가 있으므로 Contracting path의 feature map의 크기가 Expanding path의 feature map 크기보다 크게 됩니다. 따라서 이미지의 크기를 맞춰주기 위해, 가운데 부분을 적당한 크기로 crop을 해주어서 연결합니다.
-
Expanding path의 Upsampling 단계 이후에, Copy & Crop & Concatenate + Paste 을 단계마다 반복해서 수행합니다. 이로 인해 2장의 feature map이 겹쳐진 상태로 다음 단계인 Convolution을 거치게 됩니다.
-
Channel 수를 조정하기 위해서 1 x 1 Convolution 연산을 마지막 layer에서 수행하게 됩니다. 즉,
64개의 channel ⇒ 2개의 channel
Data augmentation에 대한 내용도 있으나, 생략하도록 하겠습니다.
3. Experiments
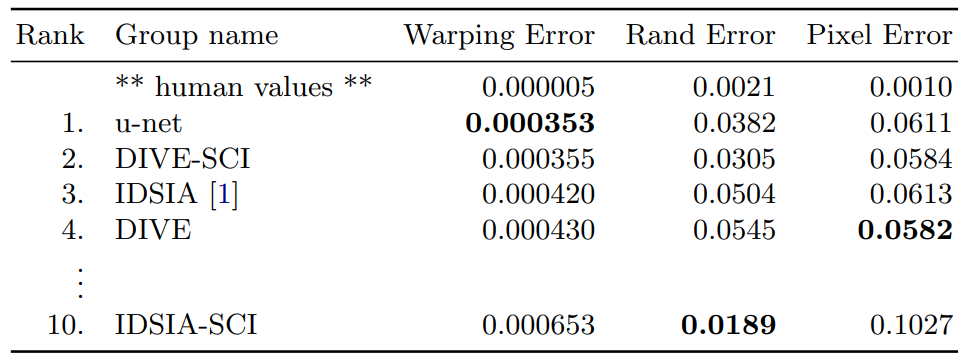
Ranking on the EM segmentation challenge [14] (march 6th, 2015), sorted
by warping error
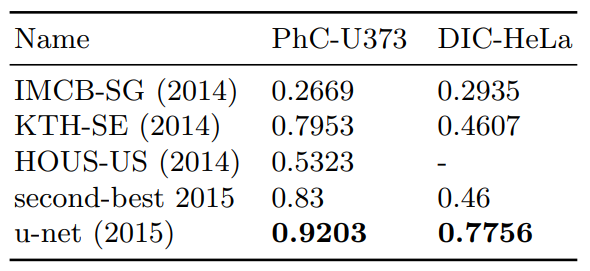
Segmentation results (IOU) on the ISBI cell tracking challenge 2015
이러한 구조를 바탕으로 결과적으로, 대회에서 이전의 네트워크보다 훨씬 더 좋은 성능을 내 우승을 했습니다.
참고자료
