이번 포스팅에서는 지난 시간에 공부한 U-Net 톺아보기에 대한 실습을 해보려고 합니다. 사실 실습이라기 보다는 링크의 내용을 분석해보는 것에 불과합니다. 실습에 관련된 대부분의 내용(소스코드 포함)은 아래의 사이트를 바탕으로 작성했음을 미리 알려드립니다. 또한, 데이터셋도 아래 링크에서 다운받으실 수 있습니다.
[Semantic Segmentation in Self-driving Cars]
[Source Code]
[Dataset]
기존의 코드에서 제가 따로 추가하거나 수정한 소스코드는, 아래의 깃허브에서 다운받으실 수 있습니다.
Github : U-Net(Semantic Segmentation.ipynb) 파일
Cityscape Dataset
어떤 데이터를 바탕으로 학습을 하는지를 확인해보기 위해, 데이터셋 중 한 개의 이미지만을 확인해봅니다.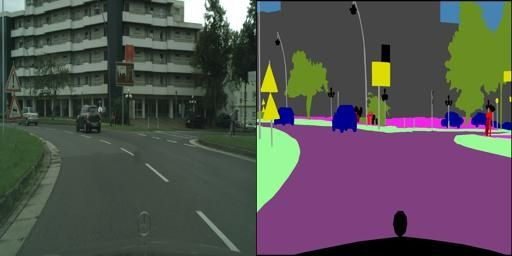
이미지를 확인해보면 256(세로, 행) x 512(가로, 열)의 픽셀로 구성되어 있는 것을 확인할 수 있습니다. 위의 사진에서 왼쪽의 이미지는 실제 이미지(original image)를, 오른쪽 이미지는 labeled 이미지를 나타냅니다. Cityscape Dataset은 2975개의 training 이미지 파일과 500개의 validation 이미지 파일로 이루어져 있습니다. 해당 데이터셋에 대한 자세한 설명은 다운받은 사이트에서 확인할 수 있습니다.
Step 1. 모델 설계
1.1 라이브러리 불러오기
import os
from PIL import Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from tqdm.notebook import tqdm모델 설계하는데 필요한 라이브러리를 불러옵니다.
PIL 라이브러리
1.2 GPU 설정하기
# GPU 사용이 가능할 경우, GPU를 사용할 수 있게 함.
device = "cuda:0" if torch.cuda.is_available() else "cpu"
device = torch.device(device)
print(device)1.3 파일 시스템
# 자신의 폴더 경로에 맞게 재지정해주세요.
root_path = '~/archive/ityscapes_data/'
data_dir = root_path
# data_dir의 경로(문자열)와 train(문자열)을 결합해서 train_dir(train 폴더의 경로)에 저장합니다.
train_dir = os.path.join(data_dir, "train")
# data_dir의 경로(문자열)와 val(문자열)을 결합해서 val_dir(val 폴더의 경로)에 저장합니다.
val_dir = os.path.join(data_dir, "val")
# train_dir 경로에 있는 모든 파일을 리스트의 형태로 불러와서 train_fns에 저장합니다.
train_fns = os.listdir(train_dir)
# val_dir 경로에 있는 모든 파일을 리스트의 형태로 불러와서 val_fns에 저장합니다.
val_fns = os.listdir(val_dir)
print(len(train_fns), len(val_fns))위의 결과를 출력해보면 아래와 같은 결과를 얻을 수 있습니다.
2975 500즉, train_fns의 길이는 2975이며 val_fns의 길이는 500입니다. 이는 데이터셋인 Cityscape Dataset의 학습(train) 및 검증(validation) 데이터와 일치하는 것을 확인할 수 있습니다.
1.4 샘플 이미지 검색
경로를 지정했으므로 이제 이 경로를 사용하여 샘플 이미지를 불러오도록 하겠습니다. 이 과정은 생략해도 되지만 불러오는 과정이 원활하게 동작하는지 확인하기 위해 실습해보도록 하겠습니다.
# train_dir(문자열)와 train_fns[0](문자열)의 경로를 결합하여 sample_image_fp(샘플 이미지의 경로)에 저장합니다.
sample_image_fp = os.path.join(train_dir, train_fns[0])
# PIL 라이브러리의 Image 모듈을 사용하여, sample_image_fp를 불러옵니다.
# RGB 형태로 변환하여 sample_image에 저장하는 것으로 이해했는데, ".convert("RGB")" 코드는 없어도 될 것 같습니다.
# Image.open() 함수 자체가 RGB의 형태로 불러오는 것으로 이해했습니다. 확실하지 않습니다...
sample_image = Image.open(sample_image_fp).convert("RGB")
plt.imshow(sample_image)
plt.show()위의 소스코드를 실행하면 아래의 이미지가 출력됩니다.
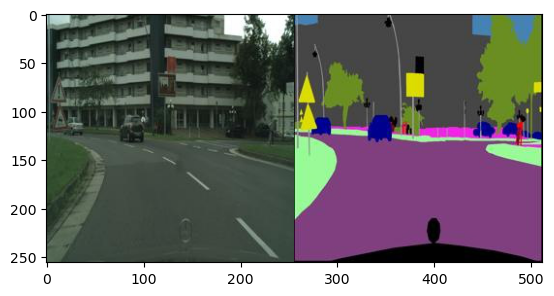
1.5 Output Label 정의하기
num_items = 1000
# 0~255 사이의 숫자를 3*num_items번 랜덤하게 뽑기
color_array = np.random.choice(range(256), 3*num_items).reshape(-1, 3)
print(color_array.shape)출력결과
(1000, 3)num_classes = 10
# K-means clustering 알고리즘을 사용하여 label_model에 저장합니다.
label_model = KMeans(n_clusters = num_classes)
label_model.fit(color_array)# 이전에 샘플이미지에서 볼 수 있듯이, original image와 labeled image가 연결되어 있는데 이를 분리해줍니다.
def split_image(image) :
image = np.array(image)
# 이미지의 크기가 256 x 512 였는데 이를 original image와 labeled image로 분리하기 위해 리스트로 슬라이싱 합니다.
# 그리고 분리된 이미지를 각각 cityscape(= original image)와 label(= labeled image)에 저장합니다.
cityscape, label = image[:, :256, :], image[:, 256:, :]
return cityscape, label# 바로 이전 코드에서 정의한 split_image() 함수를 이용하여 sample_image를 분리한 후, cityscape과 label에 각각 저장합니다.
cityscape, label = split_image(sample_image)
label_class = label_model.predict(label.reshape(-1, 3)).reshape(256, 256)
fig, axes = plt.subplots(1, 3, figsize = (15, 5))
axes[0].imshow(cityscape)
axes[1].imshow(label)
axes[2].imshow(label_class)
plt.show()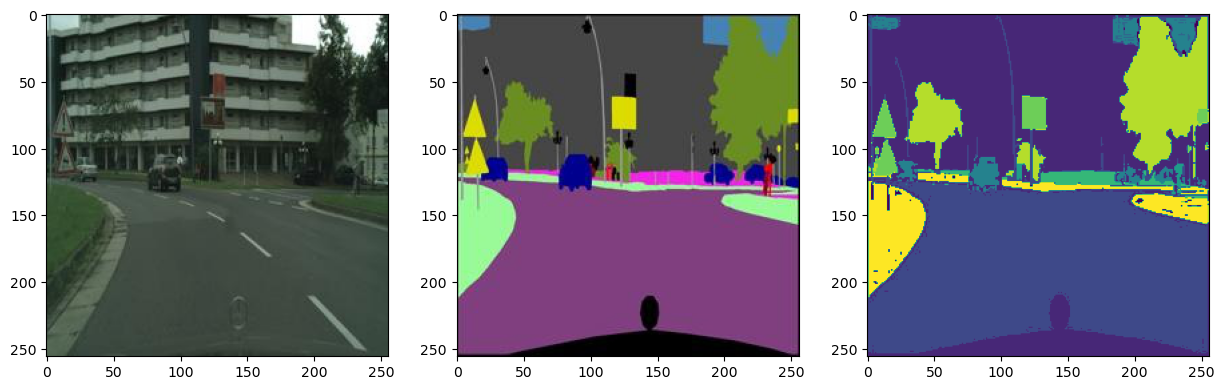
label_model.predict( )
plt.subplots( )
1.5.1 label_model.predict( ) 궁금한 것
# label_class = label_model.predict(label.reshape(-1, 3)).reshape(256, 256) 코드를 아래의 코드로 바꿔봄.
label_class = label_model.predict(label.reshape(-1, 1)).reshape(256, 256)KMeans의 predict 메소드의 경우 3개의 feature를 입력으로 받으므로 reshape(-1, 3)을 해주어야 정상적으로 동작함.
ValueError: X has 1 features, but KMeans is expecting 3 features as input.print(label.shape)
print(label.reshape(-1, 3).shape)
print(label_model.predict(label.reshape(-1, 3)).shape
print(label_class.shape)위의 출력 결과는 각각 아래와 같습니다.
(256, 256, 3)
(65536, 3)
(65536,)
(256, 256)1.6 데이터셋 정의하기
class CityscapeDataset(Dataset):
def __init__(self, image_dir, label_model):
self.image_dir = image_dir
self.image_fns = os.listdir(image_dir)
self.label_model = label_model
def __len__(self) :
return len(self.image_fns)
def __getitem__(self, index) :
image_fn = self.image_fns[index]
image_fp = os.path.join(self.image_dir, image_fn)
image = Image.open(image_fp)
image = np.array(image)
cityscape, label = self.split_image(image)
label_class = self.label_model.predict(label.reshape(-1, 3)).reshape(256, 256)
label_class = torch.Tensor(label_class).long()
cityscape = self.transform(cityscape)
return cityscape, label_class
def split_image(self, image) :
image = np.array(image)
cityscape, label = image[ : , :256, : ], image[ : , 256: , : ]
return cityscape, label
def transform(self, image) :
transform_ops = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = (0.485, 0.56, 0.406), std = (0.229, 0.224, 0.225))
])
return transform_ops(image) dataset = CityscapeDataset(train_dir, label_model)
print(len(dataset))
cityscape, label_class = dataset[0]
print(cityscape.shape)
print(label_class.shape)# 출력 결과
2975
torch.Size([3, 256, 256])
torch.Size([256, 256])위의 출력 결과를 통해, 학습 데이터가 2975개 있다는 것을 다시 한번 확인할 수 있습니다. 또한, cityscape과 label_class의 shape도 알 수 있습니다. cityscape의 경우 transforms.ToTensor()를 통과하여 [3, 256, 256]의 텐서 형태를 가지게 되는 것을 확인할 수 있습니다.
1.7 U-Net 모델 정의하기
이전 포스팅에서 다룬 U-Net 모델을 사용하여 Sementic Segmentation을 진행하겠습니다. 아래의 사진을 바탕으로 U-Net 모델을 만듭니다.
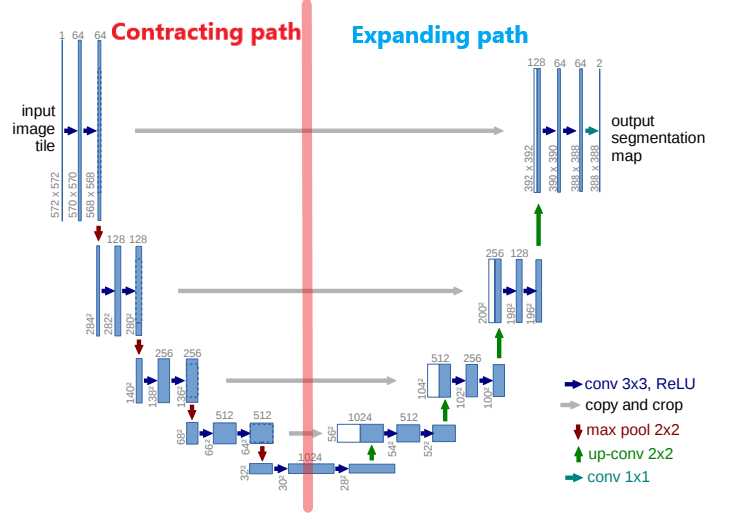
class UNet(nn.Module):
def __init__(self, num_classes):
super(UNet, self).__init__()
self.num_classes = num_classes
self.contracting_11 = self.conv_block(in_channels=3, out_channels=64)
self.contracting_12 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_21 = self.conv_block(in_channels=64, out_channels=128)
self.contracting_22 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_31 = self.conv_block(in_channels=128, out_channels=256)
self.contracting_32 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_41 = self.conv_block(in_channels=256, out_channels=512)
self.contracting_42 = nn.MaxPool2d(kernel_size=2, stride=2)
self.middle = self.conv_block(in_channels=512, out_channels=1024)
self.expansive_11 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_12 = self.conv_block(in_channels=1024, out_channels=512)
self.expansive_21 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_22 = self.conv_block(in_channels=512, out_channels=256)
self.expansive_31 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_32 = self.conv_block(in_channels=256, out_channels=128)
self.expansive_41 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_42 = self.conv_block(in_channels=128, out_channels=64)
self.output = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=3, stride=1, padding=1)
def conv_block(self, in_channels, out_channels):
block = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(num_features=out_channels),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(num_features=out_channels))
return block
def forward(self, X):
contracting_11_out = self.contracting_11(X) # [-1, 64, 256, 256]
contracting_12_out = self.contracting_12(contracting_11_out) # [-1, 64, 128, 128]
contracting_21_out = self.contracting_21(contracting_12_out) # [-1, 128, 128, 128]
contracting_22_out = self.contracting_22(contracting_21_out) # [-1, 128, 64, 64]
contracting_31_out = self.contracting_31(contracting_22_out) # [-1, 256, 64, 64]
contracting_32_out = self.contracting_32(contracting_31_out) # [-1, 256, 32, 32]
contracting_41_out = self.contracting_41(contracting_32_out) # [-1, 512, 32, 32]
contracting_42_out = self.contracting_42(contracting_41_out) # [-1, 512, 16, 16]
middle_out = self.middle(contracting_42_out) # [-1, 1024, 16, 16]
expansive_11_out = self.expansive_11(middle_out) # [-1, 512, 32, 32]
expansive_12_out = self.expansive_12(torch.cat((expansive_11_out, contracting_41_out), dim=1)) # [-1, 1024, 32, 32] -> [-1, 512, 32, 32]
expansive_21_out = self.expansive_21(expansive_12_out) # [-1, 256, 64, 64]
expansive_22_out = self.expansive_22(torch.cat((expansive_21_out, contracting_31_out), dim=1)) # [-1, 512, 64, 64] -> [-1, 256, 64, 64]
expansive_31_out = self.expansive_31(expansive_22_out) # [-1, 128, 128, 128]
expansive_32_out = self.expansive_32(torch.cat((expansive_31_out, contracting_21_out), dim=1)) # [-1, 256, 128, 128] -> [-1, 128, 128, 128]
expansive_41_out = self.expansive_41(expansive_32_out) # [-1, 64, 256, 256]
expansive_42_out = self.expansive_42(torch.cat((expansive_41_out, contracting_11_out), dim=1)) # [-1, 128, 256, 256] -> [-1, 64, 256, 256]
output_out = self.output(expansive_42_out) # [-1, num_classes, 256, 256]
return output_outsuper(UNet, self).init()
nn.Module
model = UNet(num_classes=num_classes)data_loader = DataLoader(dataset, batch_size = 4)
print(len(dataset), len(data_loader))
X, Y = iter(data_loader).next()
print(X.shape)
print(Y.shape)# 출력결과
2975 744
torch.Size([4, 3, 256, 256])
torch.Size([4, 256, 256])Y_pred = model(X)
print(Y_pred.shape)torch.Size([4, 10, 256, 256])원래 U-Net 논문에는 no padding이지만 링크의 저자는 padding을 추가해주었습니다. 또한 논문에서는 1x1 convolution이 마지막 레이어에 존재하지만 이 포스팅에서는 존재하지 않습니다. 추측하건대 논문의 이미지 크기와, 우리가 인식하려는 이미지의 크기가 다르기 때문에 약간의 변형을 해준 것 같습니다.
1.7.1 U-Net 모델 코드 수정
논문에서 마지막 레이어에 1x1 convolution을 추가하였기 때문에, 궁금하여 이전의 소스코드에서 1x1 conv. layer를 추가해보았습니다. 수정한 코드는 아래와 같습니다.
class UNet(nn.Module):
def __init__(self, num_classes):
super(UNet, self).__init__()
self.num_classes = num_classes
self.contracting_11 = self.conv_block(in_channels=3, out_channels=64)
self.contracting_12 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_21 = self.conv_block(in_channels=64, out_channels=128)
self.contracting_22 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_31 = self.conv_block(in_channels=128, out_channels=256)
self.contracting_32 = nn.MaxPool2d(kernel_size=2, stride=2)
self.contracting_41 = self.conv_block(in_channels=256, out_channels=512)
self.contracting_42 = nn.MaxPool2d(kernel_size=2, stride=2)
self.middle = self.conv_block(in_channels=512, out_channels=1024)
self.expansive_11 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_12 = self.conv_block(in_channels=1024, out_channels=512)
self.expansive_21 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_22 = self.conv_block(in_channels=512, out_channels=256)
self.expansive_31 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_32 = self.conv_block(in_channels=256, out_channels=128)
self.expansive_41 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1, output_padding=1)
self.expansive_42 = self.conv_block(in_channels=128, out_channels=64)
self.output = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
# 1x1 convolution layer 추가
self.output1 = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=1, stride=1, padding=1)
def conv_block(self, in_channels, out_channels):
block = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(num_features=out_channels),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(num_features=out_channels))
return block
def forward(self, X):
contracting_11_out = self.contracting_11(X) # [-1, 64, 256, 256]
contracting_12_out = self.contracting_12(contracting_11_out) # [-1, 64, 128, 128]
contracting_21_out = self.contracting_21(contracting_12_out) # [-1, 128, 128, 128]
contracting_22_out = self.contracting_22(contracting_21_out) # [-1, 128, 64, 64]
contracting_31_out = self.contracting_31(contracting_22_out) # [-1, 256, 64, 64]
contracting_32_out = self.contracting_32(contracting_31_out) # [-1, 256, 32, 32]
contracting_41_out = self.contracting_41(contracting_32_out) # [-1, 512, 32, 32]
contracting_42_out = self.contracting_42(contracting_41_out) # [-1, 512, 16, 16]
middle_out = self.middle(contracting_42_out) # [-1, 1024, 16, 16]
expansive_11_out = self.expansive_11(middle_out) # [-1, 512, 32, 32]
expansive_12_out = self.expansive_12(torch.cat((expansive_11_out, contracting_41_out), dim=1)) # [-1, 1024, 32, 32] -> [-1, 512, 32, 32]
expansive_21_out = self.expansive_21(expansive_12_out) # [-1, 256, 64, 64]
expansive_22_out = self.expansive_22(torch.cat((expansive_21_out, contracting_31_out), dim=1)) # [-1, 512, 64, 64] -> [-1, 256, 64, 64]
expansive_31_out = self.expansive_31(expansive_22_out) # [-1, 128, 128, 128]
expansive_32_out = self.expansive_32(torch.cat((expansive_31_out, contracting_21_out), dim=1)) # [-1, 256, 128, 128] -> [-1, 128, 128, 128]
expansive_41_out = self.expansive_41(expansive_32_out) # [-1, 64, 256, 256]
expansive_42_out = self.expansive_42(torch.cat((expansive_41_out, contracting_11_out), dim=1)) # [-1, 128, 256, 256] -> [-1, 64, 256, 256]
output_out = self.output(expansive_42_out) # [-1, 64, 256, 256] -> [-1, 64, 256, 256]
output_out1 = self.output(output_out) # [-1, num_classes, 256, 256]
return output_out1Step 2. 모델 학습
batch_size = 4
epochs = 10
lr = 0.01
dataset = CityscapeDataset(train_dir, label_model)
data_loader = DataLoader(dataset, batch_size = batch_size)
model = UNet(num_classes = num_classes).to(device)
# 손실함수 정의
criterion = nn.CrossEntropyLoss()
# Optimizer 정의
optimizer = optim.Adam(model.parameters(), lr = lr)
step_losses = []
epoch_losses = []
for epoch in tqdm(range(epochs)) :
epoch_loss = 0
for X, Y in tqdm(data_loader, total = len(data_loader), leave = False) :
X, Y = X.to(device), Y.to(device)
optimizer.zero_grad()
Y_pred = model(X)
loss = criterion(Y_pred, Y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
step_losses.append(loss.item())
epoch_losses.append(epoch_loss/len(data_loader))학습을 통해 얻은 손실함수를 확인해보겠습니다.
print(len(epoch_losses))
print(epoch_losses)출력 결과
10
[1.2644546631202902, 0.8764938149721392, 0.7952614437828782, 0.7531729845270034, 0.7165372273934785, 0.6903373579023987, 0.6792501089393451, 0.6337115100474768, 0.6319557054629249, 0.6149069263890226]학습을 통해 손실함수가 감소한 것을 확인할 수 있습니다.
이제 학습의 결과(training losses)를 그래프를 통해 확인해보겠습니다.
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].plot(step_losses)
axes[1].plot(epoch_losses)
plt.show()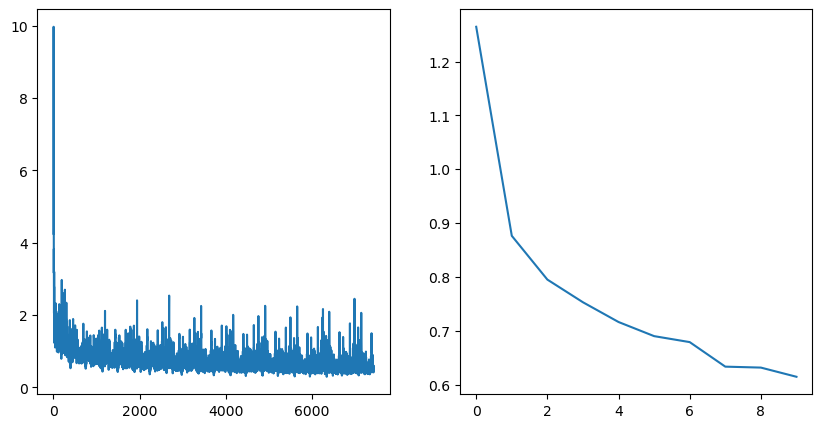
왼쪽이 step_losses, 오른쪽이 epoch_losses의 결과 그래프입니다.
모델 저장
이제 학습시킨 모델을 저장합니다.
model_name = "UNet.pth"
torch.save(model.state_dict(), root_path + model_name)Step 3. 모델 평가하기
model_path = root_path + model_name
model_ = UNet(num_classes = num_classes).to(device)
model_.load_state_dict(torch.load(model_path))
model_.load_state_dict( ) - 1
model_load_state_dict( ) - 2
pickle 모듈
역직렬화
test_batch_size = 8
dataset = CityscapeDataset(val_dir, label_model)
data_loader = DataLoader(dataset, batch_size = test_batch_size)
X,Y = next(iter(data_loader))
X,Y = X.to(device), Y.to(device)
Y_pred = model_(X)
print(Y_pred.shape)
Y_pred = torch.argmax(Y_pred, dim=1)
print(Y_pred.shape)# 출력결과 => test_batch_size에 따라 8은 변할 수 있음
torch.Size([8, 64, 256, 256])
torch.Size([8, 256, 256])inverse_transform = transforms.Compose([
transforms.Normalize((-0.485/0.229, -0.456/0.224, -0.406/0.225), (1/0.229, 1/0.224, 1/0.225))
])fig, axes = plt.subplots(test_batch_size, 3, figsize=(3*5, test_batch_size*5))
iou_scores = []
for i in range(test_batch_size):
landscape = inverse_transform(X[i]).permute(1, 2, 0).cpu().detach().numpy()
label_class = Y[i].cpu().detach().numpy()
label_class_predicted = Y_pred[i].cpu().detach().numpy()
# IOU score
intersection = np.logical_and(label_class, label_class_predicted)
union = np.logical_or(label_class, label_class_predicted)
iou_score = np.sum(intersection) / np.sum(union)
iou_scores.append(iou_score)
axes[i, 0].imshow(landscape)
axes[i, 0].set_title("Landscape")
axes[i, 1].imshow(label_class)
axes[i, 1].set_title("Label Class")
axes[i, 2].imshow(label_class_predicted)
axes[i, 2].set_title("Label Class - Predicted")
plt.show()pytorch의 permute( ) - 1
pytorch의 permute( ) - 2
# 출력결과
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).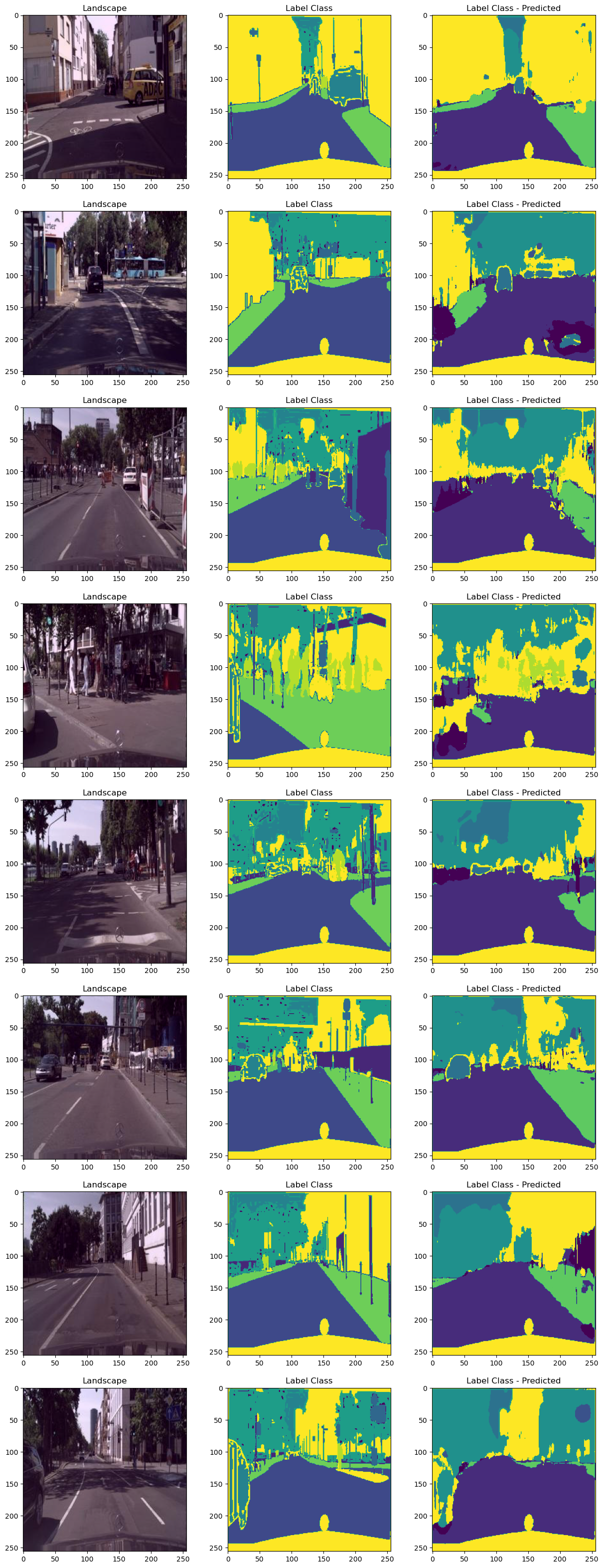
test_batch_size = 8로 설정하여 8개의 이미지에 대한 결과가 출력되었습니다.
3.1.1 궁금한 것
# dim = 1 -> dim = 0으로 변경해봄
Y_pred = torch.argmax(Y_pred, dim=0)위와 같이 이전의 코드를 변경하면 아래와 같은 이미지를 얻을 수 있습니다.
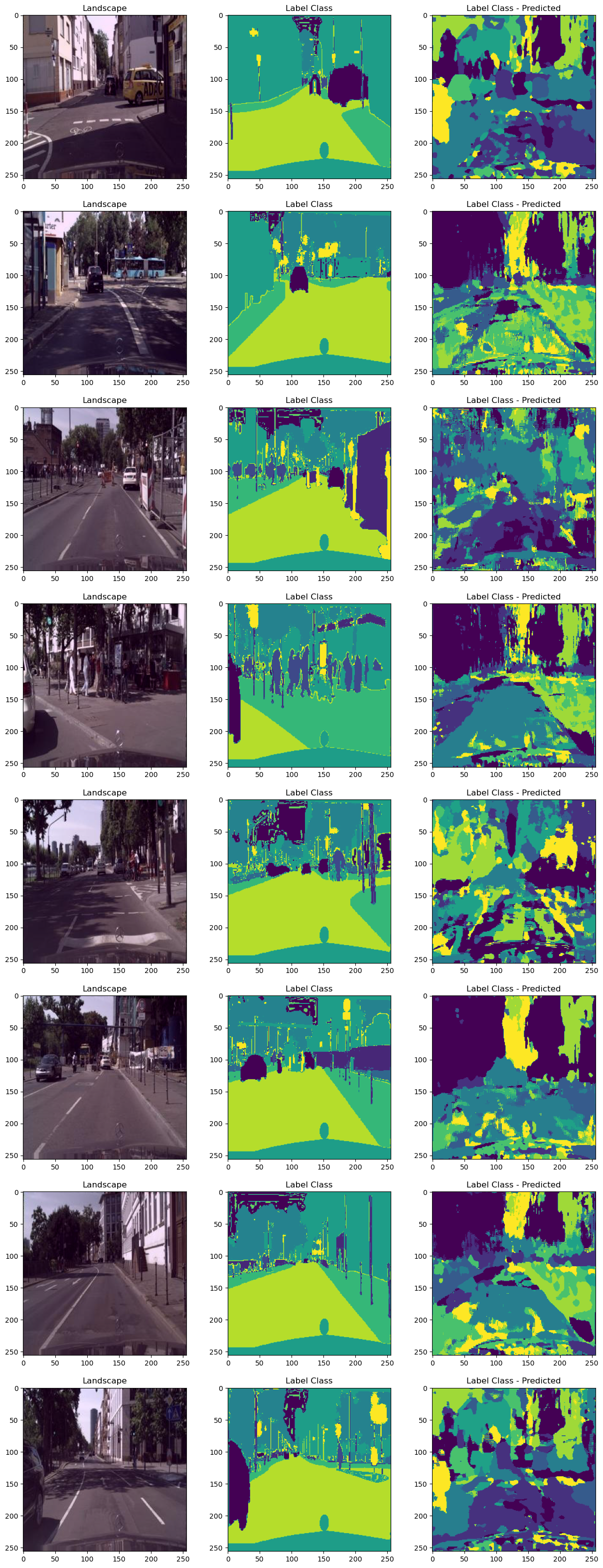
dim = 0과 dim = 1의 차이로 인해 정확도는 71.9%로 떨어졌다. 아직 이러한 결과가 발생하는 원인에 대해서 파악하지 못했습니다. 어째서 dim = 1로 주었는지 조금 더 생각해봐야겠습니다.
Step 4. IOU Score
지금까지 학습시킨 모델에 대하여, 정확도를 산출해보겠습니다. 흔히 알려진 평가지표인, IOU를 기준으로 정확도를 계산하겠습니다.
print(sum(iou_scores) / len(iou_scores))# 출력결과
0.9954032897949219우리가 학습시킨 모델의 IOU는 99.5%가 넘는 정확도를 보여줍니다!
+ 추가
batch_size와 test_batch_size 등에 따라 정확도가 달라지는 것을 확인하였습니다. 때문에 이 포스팅의 내용처럼 99프로가 나오지 않을 수 있습니다. 하지만 대부분 90프로 이상의 성능을 보여줍니다.
마지막으로, 긴 글 읽어주셔서 고맙다는 말씀드리며 딥러닝을 공부한지 얼마되지 않아 틀린 것이 있더라도 너그러이 이해해주시기 바랍니다~! 수정해야할 사항은 언제든지 댓글로 알려주세요!

안녕하세요 블로그 글 잘 읽었습니다!
dim = {0:batch, 1:channel, 2:y, 3:x} 이기 때문에 1에서 0으로 바꾸셨을 때,
배치사이즈에 맞추어 object를 판별하여 약간 지저분한 이미지의 아웃풋이 나온것 같습니다.
잘읽었습니다!