[AI] Informer_Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Informer
Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Transformer 기반 long sequence time-sereies forecsting 논문이다.
- Probesparse self-attention mechanism
- self-attenstion mechaism
- Generative style decoder
Intro
시계열 예측을 위한 디벌닝 모델의 종류는 RNN-based, CNN-based, Attention-based 모델이 있다. RNN은 시계열 데이터를 학습하는 대표적인 모델이다.
시계열 예측문제는 short-sequence와 long-sequence 예측 문제가 있다. 예측 길이가 48을 넘어가는 순간부터 MS가 급진적으로 증가하고, 초당 예측길이(predictios/sec)인 inference speed가 가파르게 낮아지고 있다. 즉, Sequence의 길이가 늘어날 수록 추론 속도가 매우 느려진다.
LSTF(long sequence time-series forecasting (LSTF))는 long sequence(input/target)에 대해 prediction capacity를 향상시키는 것이 목표이다. 이를 위해 (1) long-range alignment ability와 (2) efficient operations on long sequence input/output 이다.
LSTF관점에서 Transofrmer의 장점 및 한계점을 확인할 수 있다. Transformer구조는 (a) 에 조건에 대해 어느정도 타 네트워크대비 우수한 성능을 보이며, 이 모델은 Recurrent 나 Convolution구조 없이 Attention mechanism만을 사용하 하며, RNN 대비 long-range dependency를 잘 포착한다. 하지만, self-attention mechanism은 (b) 조건을 만족하지 못하며. 를 가진 input/output에 대해서 연산(computation) 메모리 사용(memory consumptuion)이 불가피하다.
LSTF 수행을 위한 Transformer 활용 방안
- long-range dependecy 장점 유지
- self-attention mechanism의 연산/메모리/속도 측면 효율성 개선
- prediction capacity 향상
Self-attention complexity problem
Self-attention은 Transformer에서 중요한 역할을 하지만, complexity와 structual prior 문제가 있다.
- Complexity : Complexity( 는 문장(T)가 길어지면, Bottleneck 이 발생한다.(D: input dimension)
- Structual Prior: Input에 대해 어떠한 Structual Bias도 없다는 의미이다. (장점이자 단점)
이를 해결하기 위해 Attention Mechanism은 계속 발전해왔다.
- Sparse Attetion
- Linearized Attention
- Prototype and Memory Compression
- Low-rnak Self-Attention
- Attention with Prior
- Improved Multi-Head Mechanism
Sparse Attention의 sparsity
Vanila Trnasformer Attention Matrix는 사실상 Sparse하다고 볼 수 있다. 이는 희소행렬의 값이 대부분 0인 경우이다. 메모리도 비효울적으로 사용된다. 그래서 Attention은 훈련 뒤에 볼 대상만 보게 되고, structual bias를 애초에 부여하여 Q-K 쌍의 개수를 제한하자는 말이 나왔다.

Sparse Attention 논문들의 공통점은, Coumputational cost와 Long-range Dependency에 대해 언급하고 있다.
- Computational Cost : 문장이 길어질수록 Attention 비용이 크기때문에,input Length에 대해 qudaratic 하게 증가하는 대신 linear하게 증가하도록 만드는 것이 목적이다.
- Long Range Dependecy : 긴 문장에는 cost 문제로 Transformer를 적용하기 힘들기 때문에, Global Attention을 통해 이를 해소하고자한다.
Sparse Attention 효과
비용 / Dependency를 감소시키면 512 token보다 더 긴 문장을 input으로 활요할 수 있다 Input 문장을 길게 만들면, Downstream Task에 사용되는 단서가 많아진다. Downstream Task로 QA & 문서 요약이 많이 사용되기 때문에, 시계열 예측의 관점에서는 더 긴 sequence를 받아 이를 예측할 수 있다.
Informer
기존의 Transforemr 모델의 연산, 메모리, 구조적 측면을 향상시키면서 효율성과 높은 예측성을 유지하고자하는 방법을 찾기 위해 고안외었다. Transformer의 한계점은
- The quadratic computation of self-attention
* Vanilla trnasofrmer의 self-attention에서 각 layer별 dot-product연산의 시간 복잡도와 메모리 사용량이 - The memory bottleneck in stacking layrs for long inputs
J개 stack된 encoder/decoer layer를 고려하면, 총 메모리 사용량은$O(J\cdot L2^)를 따르게 되고, 이는 long sequence input에 따른 모델의 scalability의 한계점으로 작용한다.scalability(확장성)은 데이터 크기가 증가하더라도 모델이 잘작동할 수 있는 능력
- The speed plunge in predicting long outputs
Vanilla Transformer의 dynamic decoding방식이 inference 단계에서 sptep-by-step decoding을 수행하더라도 이는 RNN 기반 모델만큼 느린 속도를 보인다.
Dynamic Decoding
RNN과 같이 autogressive한 step-by-step의 decoding 방식이다. 앞의 토큰의 값을 받아 n 번 반복한다.
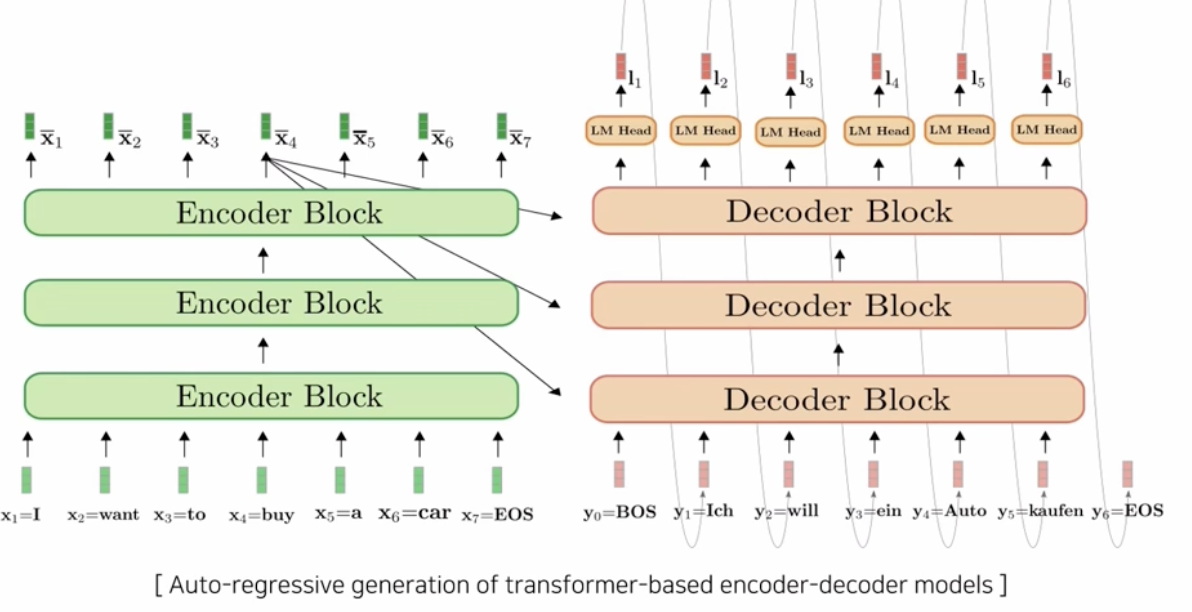
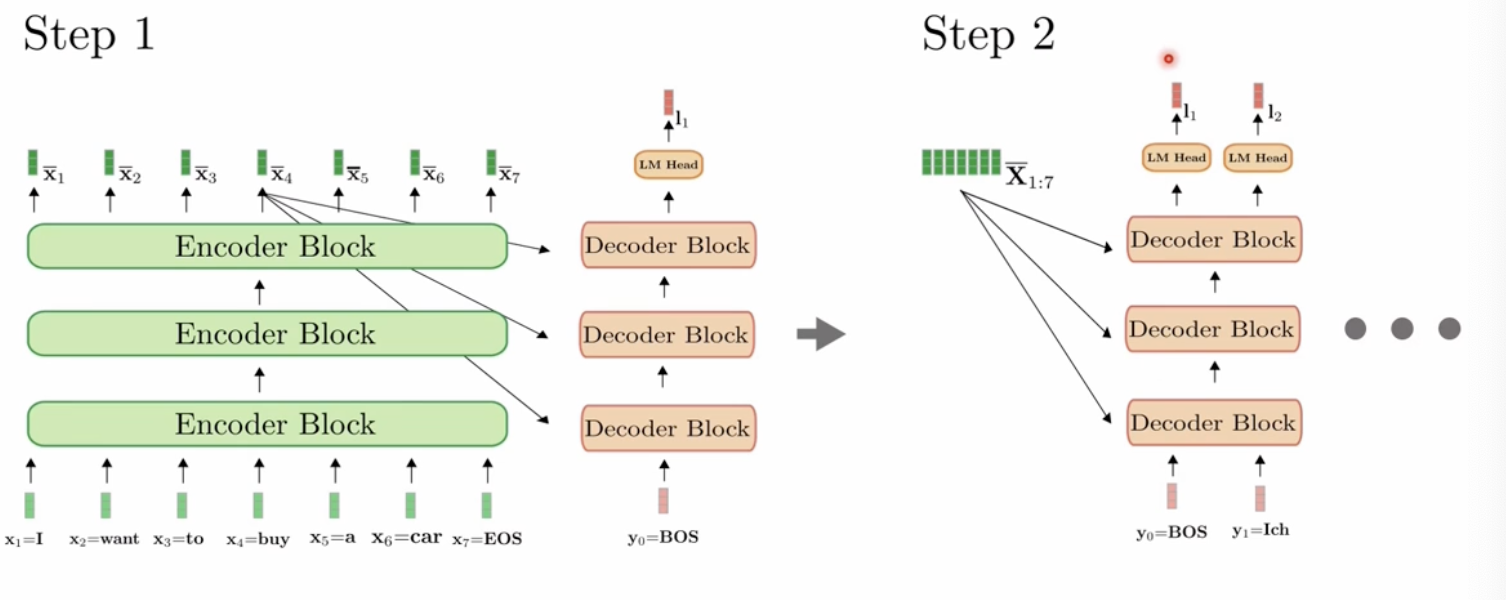
대부분의 논문은 Self-attention의 효율성을 개선하기 위해서 heuristic 방법론, LSH, Linformer 방식을 사용하였다. 하지만, 이러한 연구들에서는 연산효율성과, 현실적으로 긴 input길이에 대한 stacking layer 구조가 발생시키는 memory bottleneck, step-by-step decoindg 방식의 느린 inference 속도를 개선하지 못하였다.
이에, Informer는 transformer 모델을 기반으로, ProbSparse self-attention mechanism을 제안하고 Self-attention distilling operation과 하나의 forward step만을 사용하여 generative style decoder를 만드는 것을 제안하였다.
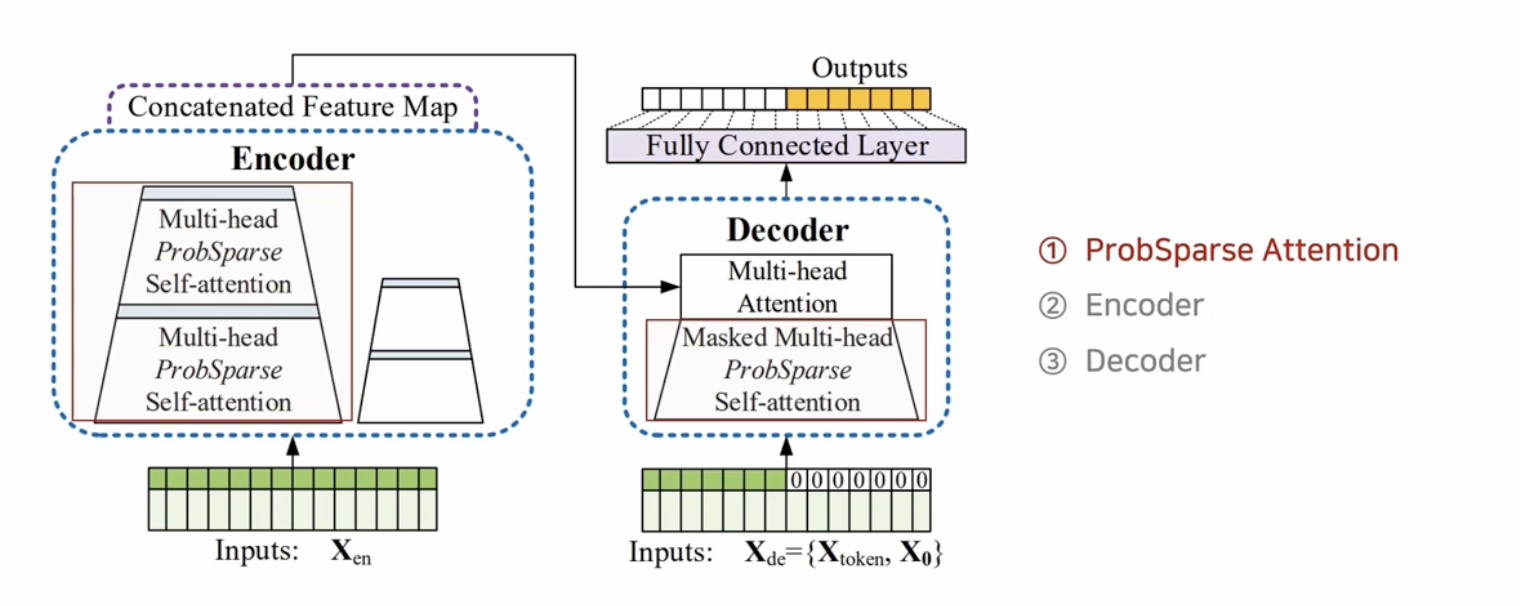
Probe Sparse
attention mechnism를 효율적으로 계산하기 위해 ProbSpares self-attention을 제안하여 연산 효율성 향상시킨다.
이 메커니즘은 유의미한 dot-product pair를 구분해내기 위해 query와 key 간의 유사도를 그 지표로서 활용하고, key sampling과 max operator를 적용하여 시퀀스의 길이를 1/2로 경량화해 연산 효율성을 높였다.
Multi-head 관점에서 보면, 각 head 별로 각기 다른 query-key 쌍을 생성하기 때문에 랜덤 샘플링으로 인한 정보 손실을 방지할 수 있.
Self-attention distilling
중요한 Feature representation 생성 및 stacking layer로 공간 복잡도 해소한다.
전체 self-attention을 사용하지 않고 1D conv와 Max-pooling을 사용하여 시퀀스 길이를 1/2로 줄여 연산 효율을 높인다.
Generative style decoder
하나의 forward step으로 long time-series 시퀀스를 예측 가능하도록 하여 Informer 속도 개선한다. 이를 통해 step-by-step inference 과정에서 발생할 수 있는 cumulative error를 방지한다.
ProbSpares self-attention 이란, sparsity 측정 지표를 바탕으로 유의미한 query들(Top-u)만을 사용하여 복잡도가 Long/L 배 감소시켜 attention을 계산하는 방법론
cumulative error는, 이전 시점의 잘못된 output이 미래 시점에도 계속해서 누적되어 영향을 미치게 되는 것
Reference
