LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
1 Introduction
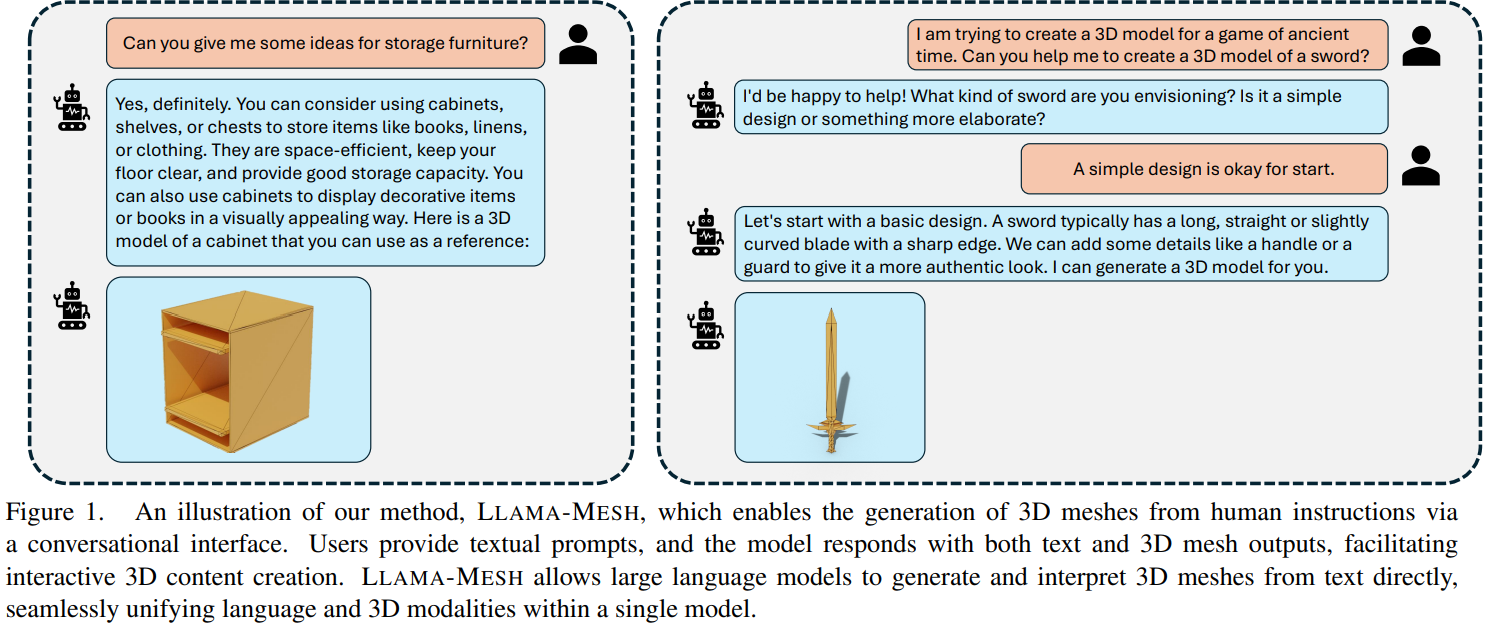
LLaMA-MESH는 텍스트와 3D mesh를 통합된 형식으로 합치며, 이는 3D mesh를 vertex coordinateface deifinition로 정의를 통해 가능하다. 제안된 모델은 text와 3D의 서로 연관된 데이터로 학습되었다. 그래서, 이 모델은 텍스트와 3D mesh를 생성하는 것이 모두 가능하다.
2 Related work
Enabling LLMs to be Multi-Modal
- Multimodal interactions
- Unify a new visual tokenizer
3D Object Generation
- DreamFusion, Magic3D, ProlificDreamer, & many other methods user score-distillation from diffusion model
- Feed-Forward methods including LRM. CRM, Instant Mesh, & meshods wihtout test-time optimization
Auto-Regressive Mesh Generation
- PolyGen, MeshGPT, MeshXL : instead descrte 3D object, use an auto-regressive transformer
- MeshAnything, PivotMEsh, EdgeRunner : Cloud
3 Method
3.1 3D Representation
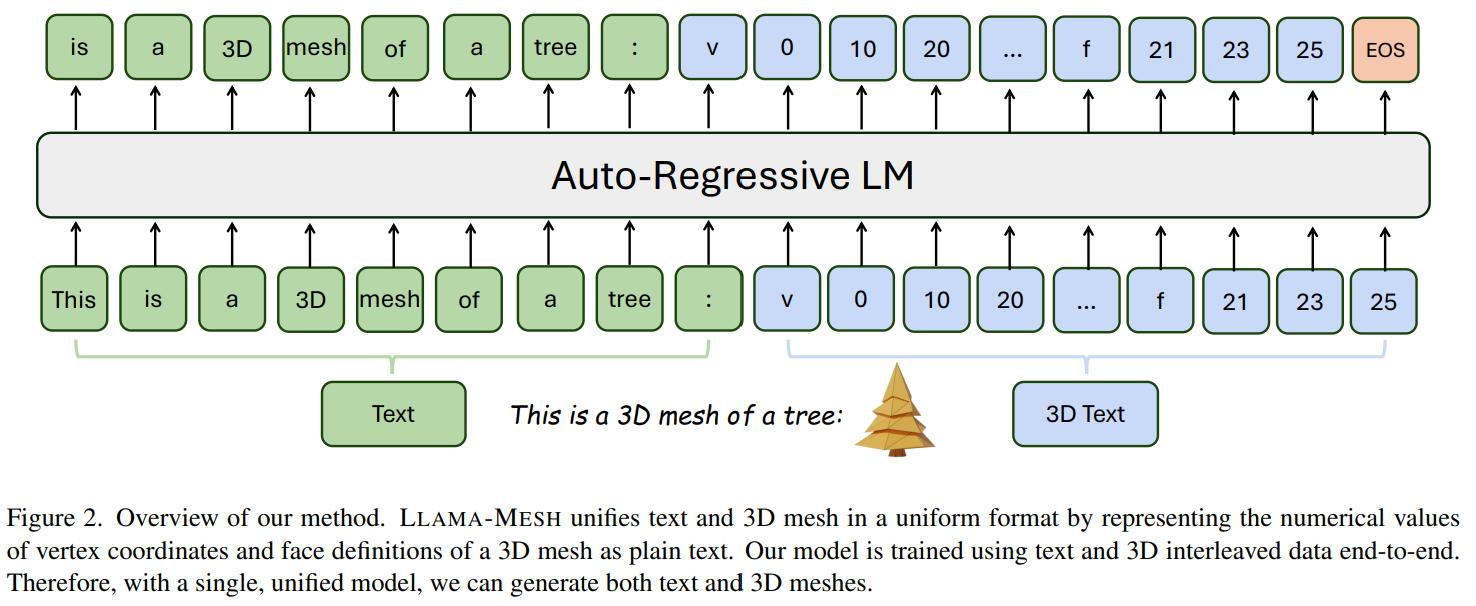
the key challenge is tokenizing the new modality so that the LLM can process it effectively, OBJ file format.
- Definition
- v : vertex
- f : face
- Meaning
- v x y z
- f v1 v2 v3
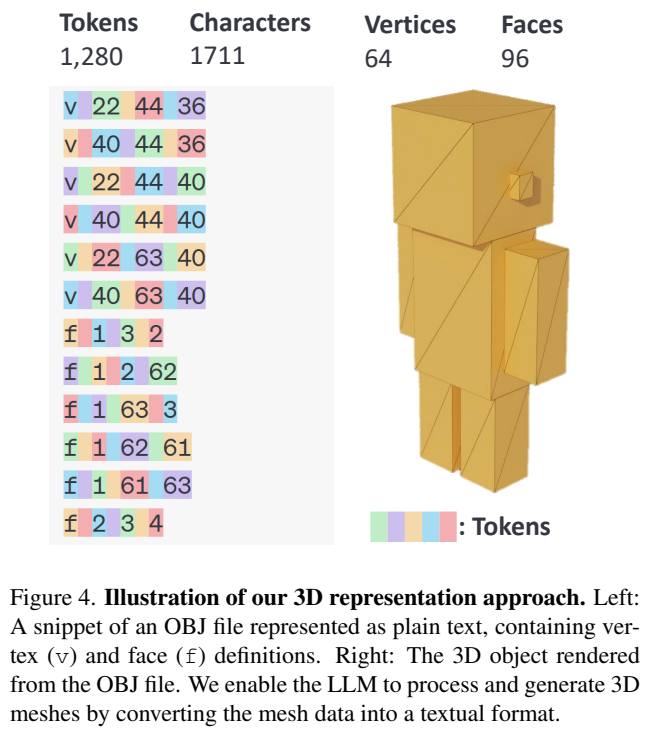
Orignially, 3D mesh coordinates are typically consists of floating-point numbers. However, floating-point numbers for vertex coordinates directly leads to long tokes sequences, exceeding most LLM’s context length limitations and increasing the computational cost.
To deal with these problems, Proposed model quantize the vertex coordinates into a fixed number of bins(64 per axis in their case). They scale the mesh to the range [0, 64] & quantize the coordinates to the nearest integer. However, it significantly decreases the to ken count, making it feasible for LLMs to handle longer sequences without sacrificing geometric fidelity.

3.2 Pretrained Models
It uses LLaMA 3.1-8B-Instruct
(a) strong tools for modeling arbitrary sequences and
(b) may have encountered similar data during pre-training.
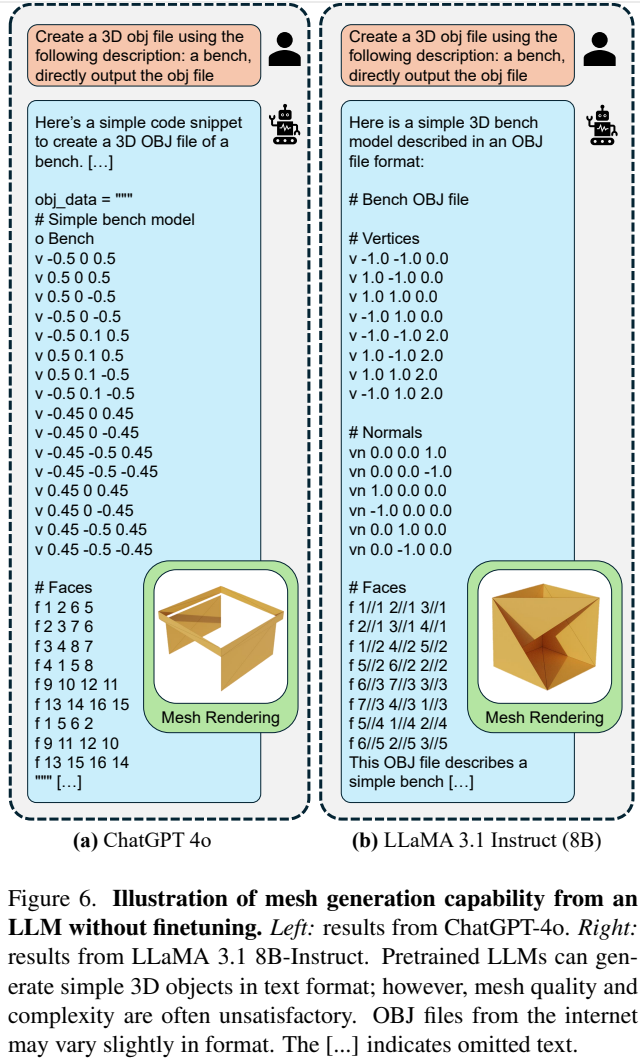
3.3 3D-task Finetuning
They use 3D meshes from Objectverse*, a comprehesive 3D dataset for general objects.
- (1) a rule-based approach
- (2) LLM-based augmentation.
a rule-based approach
- a simple pattern :
- for mesh understanding:
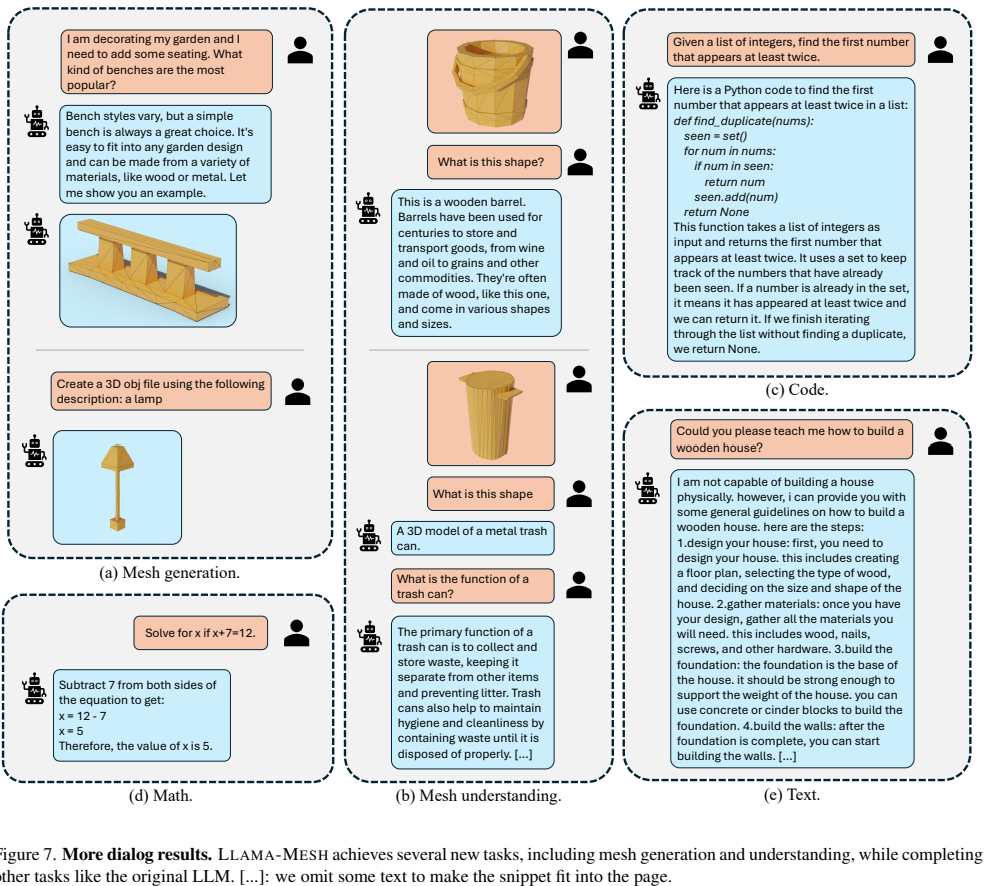
“(user) {obj} What is this? (assistant) {caption}.” - for mesh generation:
“(user) Create a 3D model of {caption}. (assistant) {obj}.” - For each 3D object, They randomly select a pattern and replace placeholders with the mesh definition and caption
- for mesh understanding:
- more sophisticated conversations:
- complex text-3D dialogues : They write sample dialogues in a text-3D interleaved format and use in-context learning to prompt the pretrained LLM to generate dialogues for each 3D object based on its textual description
- combination of rule-based and LLM augmentation methods: They randomly choose from the rule-based approach and LLM- based augmentation for each mesh to construct the dialog. Figure 8 shows examples of our training data.
To preserve the LLM’s language capabilities, we use UltraChat*, a general conversational dataset. Our final dataset is a mix of mesh generation, mesh understanding, and general conversation data, using the ratio in Table
Results

Reference
