Mamba
Mamba: Linear Time Sequence Modeling with Selective State Spaces

Foudnation Model은 Transforemr 아키텍처와 core attention module을 기반으로 만들어 졌으며,현재 DL에서 강력하게 응용되고 있다. 많은 subquadratic-time 아키텍처는 long sequance에 대한 Transformer 연산의 비효율성을 다룰때 사용되지만, language과 같이 중요한 모달에서는 attention만큼 좋은 성과를 내지 못한다. 이 논문에서는 모델의 주요 취약점인내용 기반(content based) 추론을 수행할 수 없다는 것을 확인하였고 여러가지를 개선했다. 첫 번쨰로, 단순히 SSM 매개변수를 입력의 함수로 두는 것만으로 개별 양식으로의 취약점을 해결하여 모델이 현재 토큰에 따라 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 잊어버릴 수 있다. 둘 때는, 이러한 변화는 효율적인 convolution을 사용할 수 없음에도 불구하고 반복 모드(recurrent mode)에서 하드웨어 인식 병렬 알고리즘을 설계했다. Selective SSM을 simplified end-to-end neural network 아키텍처를 attention 또는 MLP blocks 없이 통합했다. Mamba는 Transformer보다 5배는 높은 성능으로 추론을 하고, linear scaling과 million-lengh 길이를 다룰 때 성능을 개선했다. 일반적인 sequence model의 백본처럼, Mamba는 SOTA의 성능으로 언어, 오디오, 유전체(genomics) 모달에서 보였다. Language modeling에서 Mamba 3B model은 같은 크기의 Transformer의 성능을 뛰어넘고, 사전학습 및 다운스트림 평가에서 Transformer와 크기가 두배 일치한다.(?)
- subquadratic : time complexity <
- subquadratic model : linear attention, gated convolution, recurrent model, strctured space models(SSMs)
- quadratic : : time complexity >=
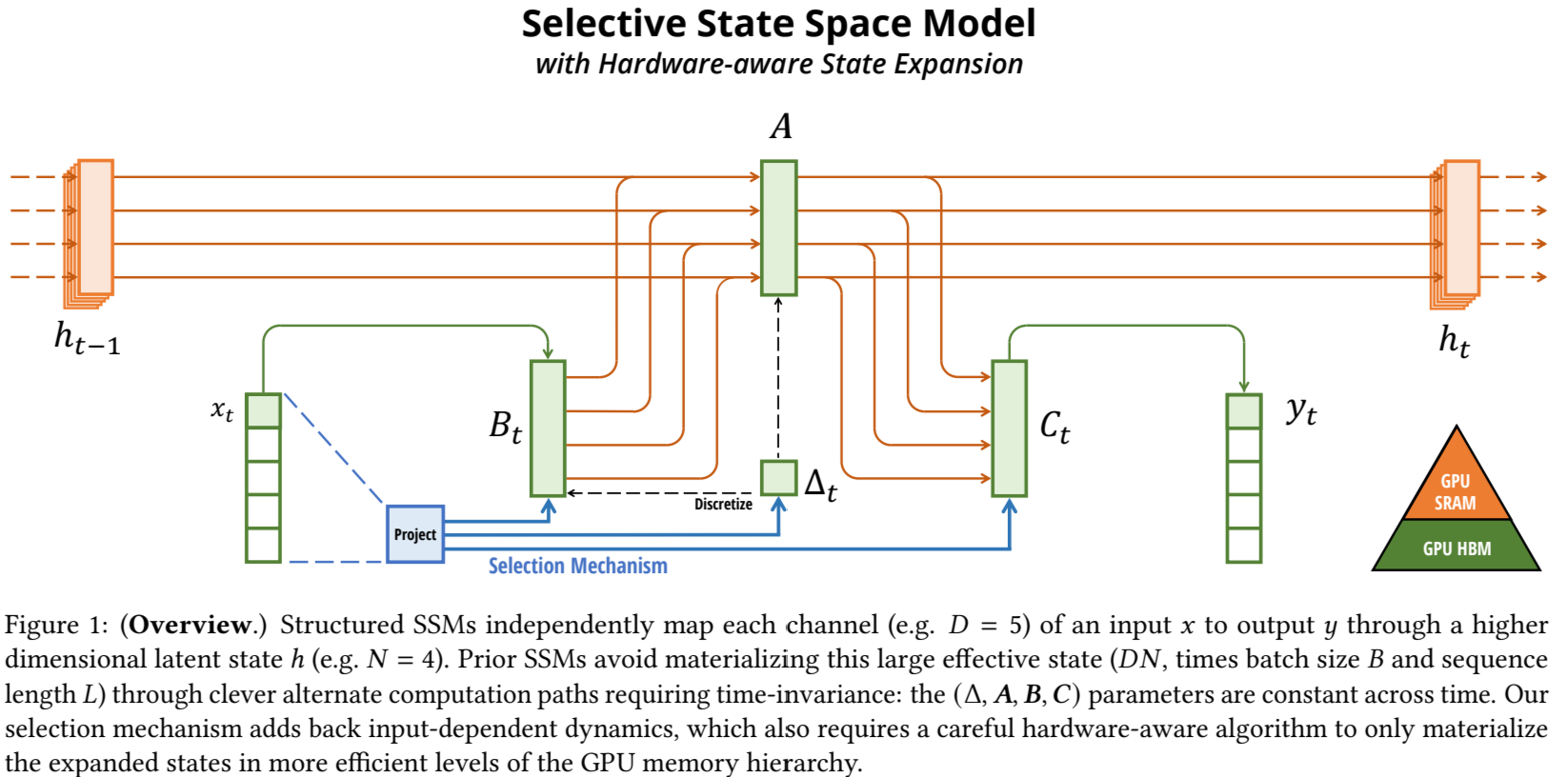
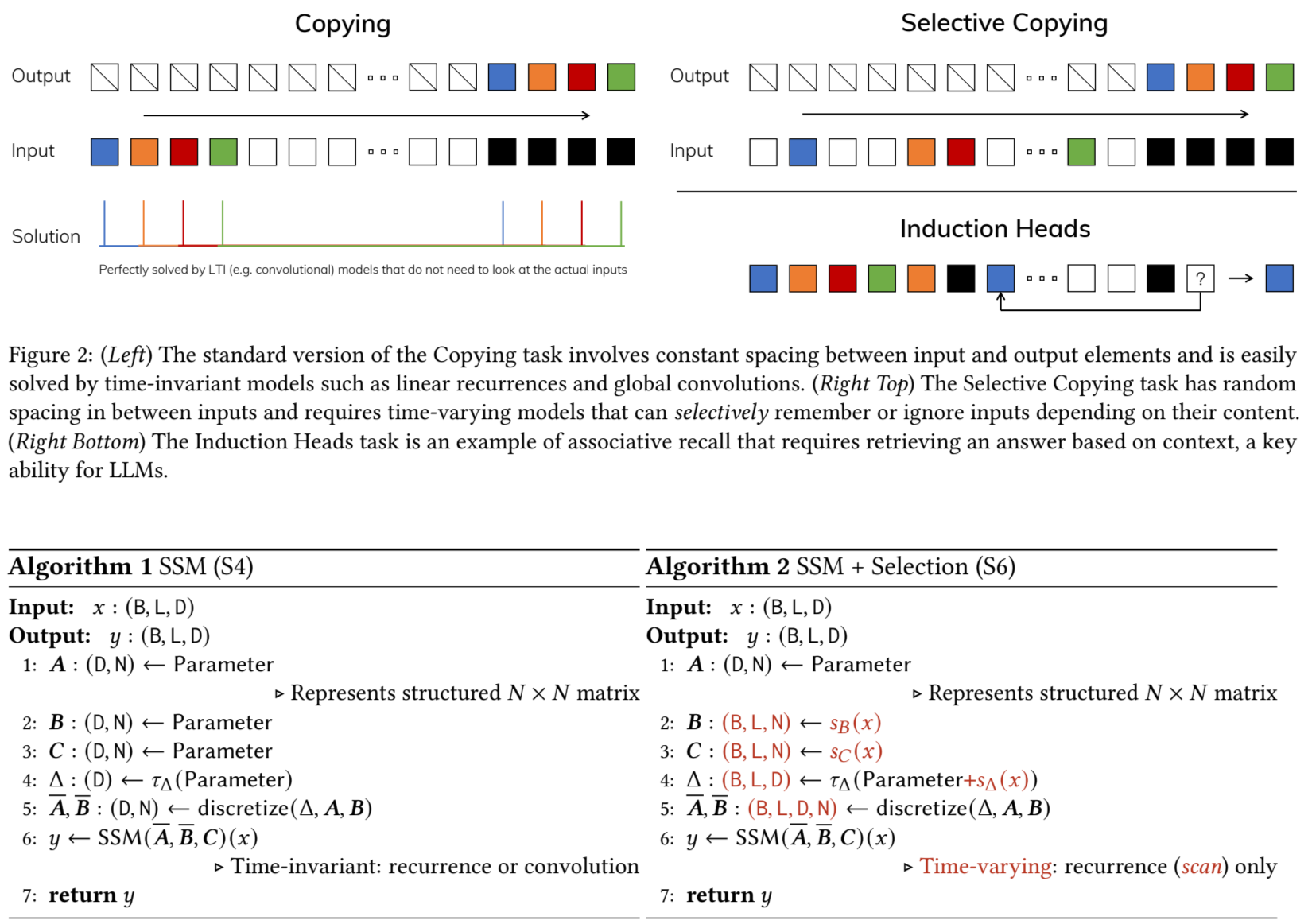
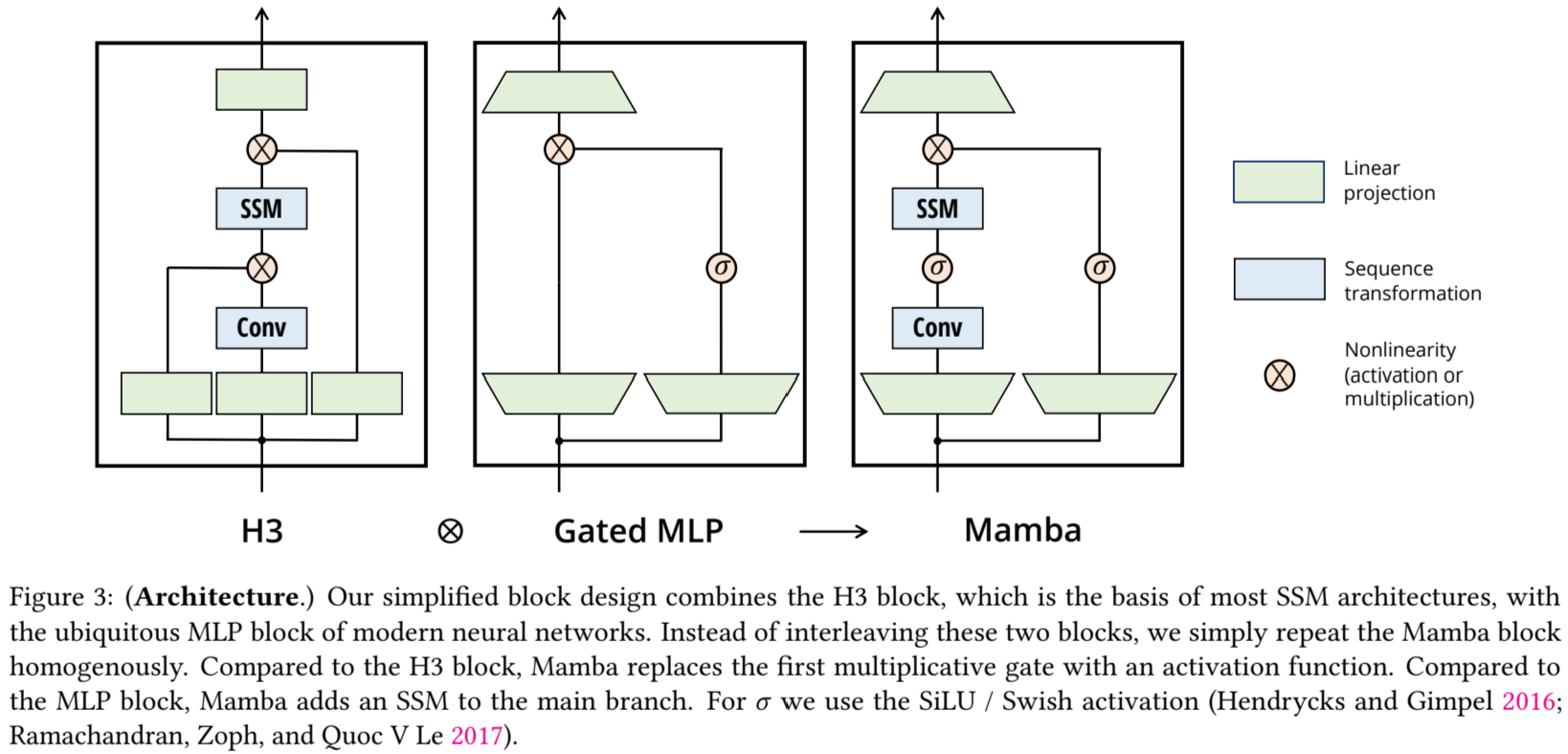
LTI(liner time invariant)
