1번
미션 자료를 보고 ERD를 설계한 후 제 1,2,3 정규화를 통해 제 1,2,3 정규형을 만들고 각각 중복된 데이터가 어떻게 변화하였고 어떠한 이점이 있었는 지 작성하기
정규화 개념을 먼저 짚고 넘어가자면,
- 제1정규형 : 각 속성이 원자값을 보장해야 한다.
- 제2정규형: 부분 함수 종속이 제거되어야 한다.
- 제3정규형: 이행 함수 종속이 제거되어야 한다.
정규화를 거쳤던 테이블을 보면서, 설계 이전에 제 1,2,3 정규화를 어떻게 진행했었는지 보려고 한다.
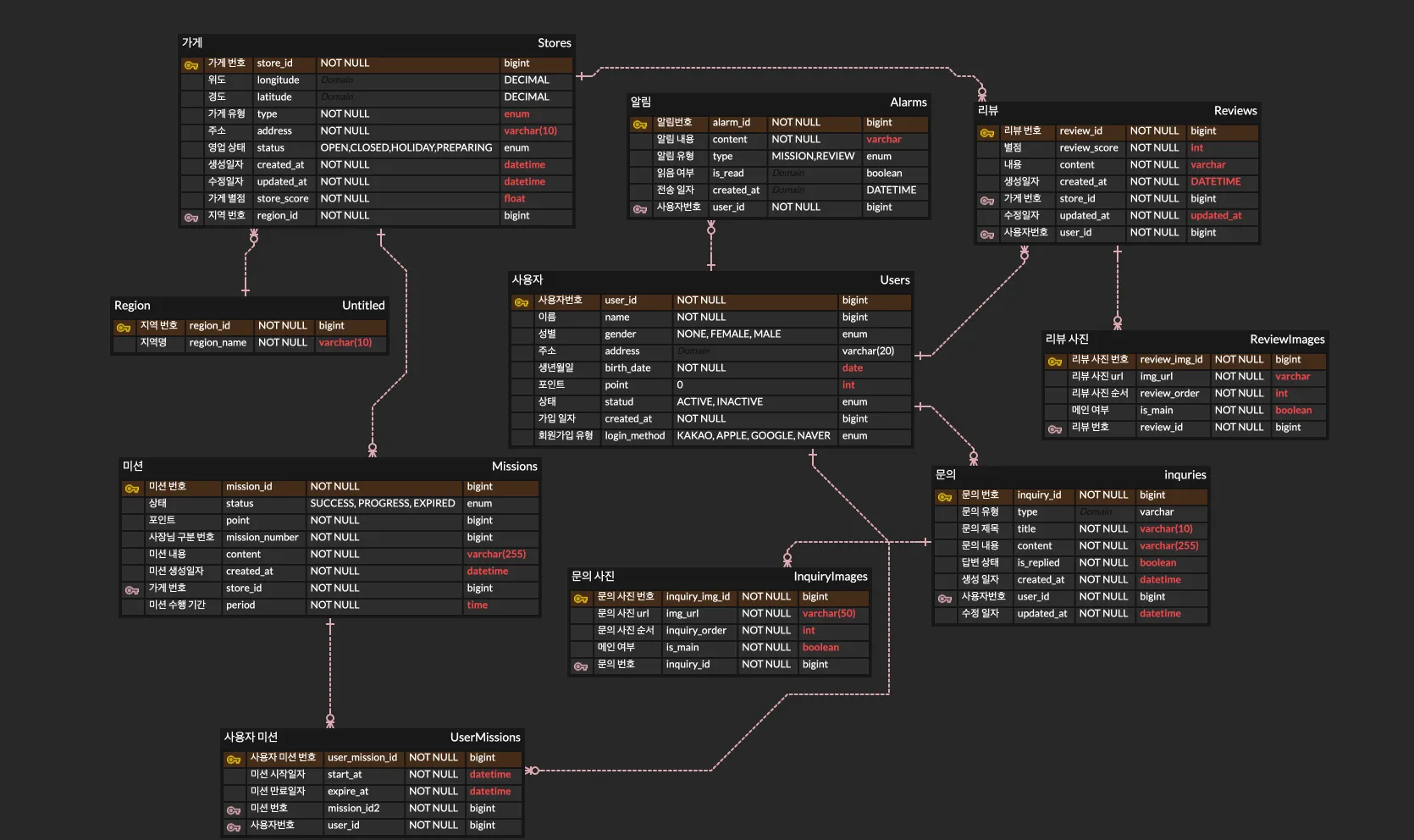
가게, 지역
지역별로 가게가 있을 수 있다. 이에 따르면 다음과 같은 함수 종속성이 있음을 알 수 있다.
가게번호 -> 지역번호 -> 지역명
지역 번호는 지역명을 결정하지만, 가게 테이블의 기본키가 아니므로 지역명이 지역번호에 종속되는 것은 이행 함수 종속이 될 수 있다. 지역명을 가게 테이블에서 분리를 해줘야 한다는 것이다. 이 경우 가게와 지역 테이블로 분리를 해주면 이행 종속이 제거된다. 가게 테이블에서 지역 테이블을 참조하고, 지역 테이블에서 지역번호와 지역명을 가지고 있으면 된다.
다음과 같이 설계하면 제3정규형을 만족한다.
가게 (stores)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| store_id | bigint | PK, NOT NULL | 가게 번호 |
| longitude | DECIMAL | NOT NULL | 위도 |
| latitude | DECIMAL | NOT NULL | 경도 |
| type | enum | NOT NULL | 가게 유형 |
| address | varchar(10) | NOT NULL | 주소 |
| status | enum | NOT NULL | 영업 상태 (OPEN, CLOSED 등) |
| created_at | datetime | NOT NULL | 생성일자 |
| updated_at | datetime | NOT NULL | 수정일자 |
| store_score | float | NOT NULL | 가게 평점 |
| region_id | bigint | NOT NULL, FK | 지역 번호 |
지역 (regions)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| region_id | bigint | PK, NOT NULL | 지역 번호 |
| region_name | varchar(10) | NOT NULL | 지역명 |
사진
리뷰, 문의 글에는 사진을 여러 장 업로드할 수가 있다. 사진에는 순서가 있고, 사진을 업로드할 시 생성되는 URL이 있다.
리뷰에 사진이 여러 장 올 수 있으므로, 이미지 URL이라는 속성에 여러 값이 오게 되는데, 이렇게 되면 제1정규형을 만족할 수 없다. 속성은 원자값이 되어야 하기 때문이다. 그러므로 리뷰 사진, 리뷰 테이블로 분리해야 한다. 리뷰 사진에서는 리뷰 번호를 외래키로 참조함으로써, 어떤 리뷰의 사진인지를 알 수 있도록 한다. 문의 테이블도 동일하게 설계해 주면 된다.
리뷰 (reviews)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| review_img_id | bigint | PK, NOT NULL | 리뷰 이미지 ID |
| img_url | varchar | NOT NULL | 이미지 URL |
| review_order | int | NOT NULL | 리뷰 사진 순서 |
| is_main | boolean | NOT NULL | 메인 여부 |
| review_id | bigint | NOT NULL, FK | 리뷰 ID |
리뷰 사진 (review_images)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| review_img_id | bigint | PK, NOT NULL | 리뷰 이미지 ID |
| img_url | varchar | NOT NULL | 이미지 URL |
| review_order | int | NOT NULL | 리뷰 사진 순서 |
| is_main | boolean | NOT NULL | 메인 여부 |
| review_id | bigint | NOT NULL, FK | 리뷰 ID |
리뷰 - 사용자
리뷰를 작성한 사용자가 있을 것이기 때문에 다음과 같이 종속성을 나타낼 수 있다.
리뷰 번호 -> 사용자 번호 -> 사용자 이름
이 경우에도 리뷰 테이블에서 사용자 번호가 기본키가 아니지만, 사용자 이름을 결정할 수 있으므로 이행 함수 종속이 된다. 그러므로 리뷰 테이블과 사용자 테이블을 분리해야 한다.
1. 분리하지 않고 저장한다면 사용자 이름 데이터가 중복 저장될 수 있기 때문이다.
| 리뷰 번호 | 사용자 번호 | 사용자 이름 | 내용 |
|---|---|---|---|
| 1 | 4 | 김수정 | 맛있어요 |
| 2 | 4 | 김수정 | 또 왔어요 |
| 3 | 44 | 김영희 | 별로예요 |
김수정이라는 이름이 여러 번 저장되므로 비효율적이다. 사용자 수가 많아질수록 중복된 데이터가 많아질 수밖에 없기 때문이다.
2. 사용자 이름이 변경될 경우에도 리뷰 테이블에서 해당 사용자가 작성한 리뷰 데이터를 모두 수정해야 하기 때문에, 사용자 이름을 사용자 테이블에서 따로 관리하는 방법이 바람직하다.
위의 테이블에서 김수정이라는 이름을 이수정으로 변경하고 싶다면, 사용자 번호가 4인 리뷰를 모두 수정해야 한다. 사용자 테이블에서만 사용자 이름을 저장하도록 한다면, 리뷰 입장에서는 사용자 번호만 가지고 있으므로 수정이 발생하더라도 리뷰 테이블에서는 따로 수정할 필요가 없다.
사용자를 다음과 같이 설계했다.
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| user_id | BIGINT | PK, AUTO_INCREMENT | 사용자 고유 ID |
| name | VARCHAR(50) | NOT NULL | 사용자 이름 |
| VARCHAR(100) | UNIQUE, NOT NULL | 사용자 이메일 | |
| phone_num | VARCHAR(20) | UNIQUE, NULLABLE | 전화번호 |
| is_phone_authorized | BOOLEAN | DEFAULT FALSE | 전화번호 인증 여부 |
| point | INT | DEFAULT 0 | 포인트 |
| created_at | DATETIME | DEFAULT NOW() | 가입 일시 |
| updated_at | DATETIME | 자동 갱신 트리거 등 | 수정 일시 |
이렇게 정규화 과정을 거쳤고, 다음과 같이 ERD를 설계했다.
미션 (missions)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| mission_id | bigint | PK, NOT NULL | 미션 번호 |
| point | bigint | NOT NULL | 포인트 |
| mission_number | bigint | NOT NULL | 사장님 구분 번호 |
| content | varchar(255) | NOT NULL | 미션 내용 |
| created_at | datetime | NOT NULL | 생성일자 |
| store_id | bigint | - | 가게 번호 |
| period | time | NOT NULL | 수행 기간 |
| status | enum | NOT NULL | 상태 (AVAILABLE 등) |
사용자 미션 (user_missions)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| user_mission_id | bigint | PK, NOT NULL | 사용자 미션 번호 |
| start_at | datetime | NOT NULL | 미션 시작 일자 |
| mission_id | bigint | NOT NULL, FK | 미션 ID |
| user_id | bigint | NOT NULL, FK | 사용자 ID |
| status | enum | NOT NULL | 상태 (SUCCESS 등) |
알림 (alarms)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| alarm_id | bigint | PK, NOT NULL | 알림 ID |
| content | varchar | NOT NULL | 알림 내용 |
| type | enum | NOT NULL | 알림 유형 |
| is_read | boolean | - | 읽음 여부 |
| created_at | DATETIME | NOT NULL | 생성 시간 |
| user_id | bigint | NOT NULL, FK | 사용자 ID |
리뷰 (reviews)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| review_id | bigint | PK, NOT NULL | 리뷰 ID |
| review_score | int | NOT NULL | 평점 |
| content | varchar | NOT NULL | 리뷰 내용 |
| created_at | DATETIME | NOT NULL | 작성 시간 |
| updated_at | updated_at | - | 수정 시간 |
| store_id | bigint | NOT NULL, FK | 가게 ID |
| user_id | bigint | NOT NULL, FK | 사용자 ID |
문의 (inquiries)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| inquiry_id | bigint | PK, NOT NULL | 문의 ID |
| type | varchar | - | 문의 유형 |
| title | varchar(10) | NOT NULL | 문의 제목 |
| content | varchar(255) | NOT NULL | 문의 내용 |
| is_replied | boolean | - | 답변 여부 |
| created_at | datetime | - | 생성 시간 |
| updated_at | datetime | - | 수정 시간 |
| user_id | bigint | NOT NULL, FK | 사용자 ID |
문의 사진 (inquiry_images)
| 컬럼명 | 타입 | 제약조건 | 설명 |
|---|---|---|---|
| inquiry_img_id | bigint | PK, NOT NULL | 문의 사진 ID |
| img_url | varchar(50) | NOT NULL | 이미지 URL |
| inquiry_order | int | NOT NULL | 문의 이미지 순서 |
| is_main | boolean | NOT NULL | 메인 여부 |
| inquiry_id | bigint | NOT NULL, FK | 문의 ID |

2번
가게마다 미션이 있고, 사용자는 미션에 도전할 수 있다. 한 사람이 “미션 도전!” 버튼을 빠르게 여러 번 눌렀을 때 여러 가지 이유(비동기 로직 등)로 요청이 지연되어 완전히 처리하기 전 두 번 요청이 들어갈 수 있다. 이를 해결할 수 있는 방법을 생각해보기
사용자는 하나의 미션에 한번만 참여할 수가 있는데, 미션 도전 버튼을 여러 번 누르게 되면, 하나의 사용자에 대해서 여러 개의 '사용자 미션' 이라는 레코드가 여러 개가 생길 수 있다는 것이다. 이를 해결할 수 있는 방법에 대해 알아볼 것이다.
1. 유일키(Unique Key) 제약조건 지정하기
- 값 중복을 허용하지 않는다. 각 행을 고유하기 식별하는 데에 사용되기 때문이다.
- NULL값을 허용한다. 중복된 값은 될 수 없지만 NULL이 될 수는 있다.
- 기본키와 달리 여러 개의 유니크키가 존재할 수 있다.
사용자 미션에는 사용자번호, 미션번호라는 속성이 존재한다. 이 두 속성이 중복되지 않도록 하기 위해 유니크 제약조건을 다음과 같이 설정하면 된다.
UNIQUE (user_id, mission_id)이렇게 하면 INSERT문 실행 시에 중복된 값이 존재하는지 확인하므로, 중복된 값이 들어가는 것을 방지할 수 있다.
2. 유니크 인덱스(Unique index) 사용하기
인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
데이터가 매우 많을 경우, 원하는 데이터를 찾으려면 시간이 많이 걸린다. 데이터와 데이터의 위치를 포함한 자료구조인 인덱스를 생성하면 원하는 데이터를 빠르게 조회할 수 있다.
일반적으로 B+Tree 구조와 해시테이블 등의 자료구조로 구현할 수 있다. 인덱스는 두 가지 종류로 나눌 수 있는데,
- 클러스터 인덱스 : 기본키를 통해 인덱스를 설정한다.
- 보조 인덱스 : 유일키를 통해 인덱스를 설정한다.
보조 인덱스를 사용해서 중복 값을 방지하도록 하면 된다. 새로운 값을 insert할 때 인덱스 구조에 존재하는 값인지 검사한다. 자료구조로 만들어져 있으므로 검색 속도가 빠르다. 다음과 같이 유니크 인덱스를 생성할 수 있다.
CREATE UNIQUE INDEX idx_user_mission
ON user_missions (user_id, mission_id);차이점 ?
유니크 제약조건은 말 그대로 중복 데이터를 방지하기 위한, 무결성을 위한 제약조건이고, 유니크 인덱스는 조회 성능도 고려한 것이라고 할 수 있다. 정리해보자면 다음과 같다.
유니크 제약조건
- 데이터 무결성 보장
- CREATE, ALTER TABLE 문에서 사용
- 내부적으로 유니크 인덱스 자동 생성
유니크 인덱스
- 데이터 중복 방지, 조회 성능 향상
- CREATE UNIQUE INDEX 문에서 생성
- 중복 체크 + 검색 최적화 고려
예를 들어 사용자가 새로운 미션을 도전한다고 할 때, 해당 사용자가 해당 미션을 이미 수행했는지, 또는 이미 도전을 한 상태인지를 확인하려면 user_id , mission_id 의 조합으로 자주 검색해야 한다.
이 경우에는 성능까지 고려한다면 유니크 인덱스가 더 적합할 수 있다.
3. 분산 락
여러 스레드나 프로세스가 동시에 데이터에 접근하려고 할 때 동시성 문제가 발생한다. 이를 해결하기 위해서 공유 자원에 대해서 락을 요청하고, 락을 획득한 프로세스만 자원에 접근 가능하도록 하는 것을 분산 락이라고 한다. 작업이 완료되면 락을 해제하고 다른 프로세스도 접근이 가능하다. 이렇게 하면 데이터를 공유하더라도 원자성이 보장되기 때문에 데이터에 결함이 생기는 것을 방지할 수 있다.
즉 미션 도전 버튼을 여러 번 클릭하면 발생하는 중복 처리 문제도 방지할 수 있다.
일반적으로 Zookeeper, mysql, redis를 사용하여 구현이 가능하다.
- Zookeeper : 분산 서버 관리 시스템이다. 분산 락만을 위해 사용하기에는 추가적인 인프라 구성이 필요하기 때문에 사용하기 적절하다고 보기에는 어렵다.
- MySQL : 트랜잭션과 레코드 락 활용이 가능하나, 동시성이 낮다.
- Redis : 성능이 빠르고 사용이 간편해서 분산 락 용도로 많이 사용된다.
spring에서는 Redis + Redisson 기반 구현이 가능하다.
- 락 획득 시도
- 중복 처리
- 사용자 미션 데이터 삽입
- 인터럽트 오류 처리
- 락 해제
private final RedissionClient redissonClient;
private static final String LOCK_PREFIX = "lock:mission";
public void challengeMisson(Long userId,Long missionId) {
// 고유 락 생성
String lockKey = LOCK_PREFIX + userID + ":" + missionId;
RLock lock = redissonClient.getLock(lockKey);
boolean isLocked = false;
try {
// 락 획득 시도
isLocked = lock.tryLock(3,5,TimeUnit.SECONDS);
if(!isLocked) {
throw new IllegalStateException("락 획득 실패");
}
// 중복 처리 및 데이터 삽입 로직
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("인터럽트 발생",e);
} finally {
if (isLocked && lock.isHeldByCurrentThread()) { // 현재 스레드가 락을 가지고 있는지 확인
lock.unlock(); // 락 해제
}
tryLock(): 락 획득을 시도한다. 유지시간 5초, 대기시간 3초로 설정하였으며 락 유지 및 대기시간이 길어지면 로드 시간이 느려지기 때문에, 너무 길게 설정하지 않는 것이 좋다.isHeldByCurrentThread(): 락은 반드시 현재 스레드가 가지고 있을 때에만 해제해야 하기 때문에, 현재 스레드가 락을 가지고 있는지 확인한다.unlock(): 락을 해제한다.
4. Transaction 처리
Spring에서는 Service 구현 시에 @Transactional 어노테이션을 사용하면 된다.
해당 메서드에서 중복 확인 및 삽입하는 로직을 묶어서 설계하고, 하나의 트랜잭션으로 처리하면 중간에 다른 요청이 들어오더라도 트랜잭션이 격리된다. 이 방법과 DB 락을 병행하면 더 안전하게 처리할 수 있다.
느낀 점
데이터베이스 설계를 1차로 하고, 개발 중에 정규화 작업을 동시해 하는 경우가 많았는데, 설계 과정에서 정규화를 조금 더 꼼꼼하게 하게 되어 개발 시에 수정이 적을 것 같아 편할 것 같다.
