Introduction
Diffusion model은 이미지 합성과 해상도 품질을 올리는 분야에서 좋은 성능을 보였지만, 데이터의 감지할 수 없는 세부 정보를 모델링 하는데 과도한 자원을 소비하는 경향이 있습니다.
DDPM의 재가중된 목적 함수는 초기 노이즈 제거 단계에서 적게 샘플링하여 자원 소비를 줄이고자 하지만 해당 모델을 학습시키고 평가 하려면 RGB 이미지의 고차원 공간에서 반복적 기울기 계신이 필요하여 계산에 소요가 많습니다. 이러한 이유로 커다란 컴퓨팅 리소스가 필요하며, 동일한 모델 아키텍처를 여러 단계를 순차적으로 실행하여 시간과 메모리 또한 많이 사용합니다. 이것을
해결하는 것이 Diffusion model의 최종 목표입니다.
Rate-Distortion Trade-Off 그래프
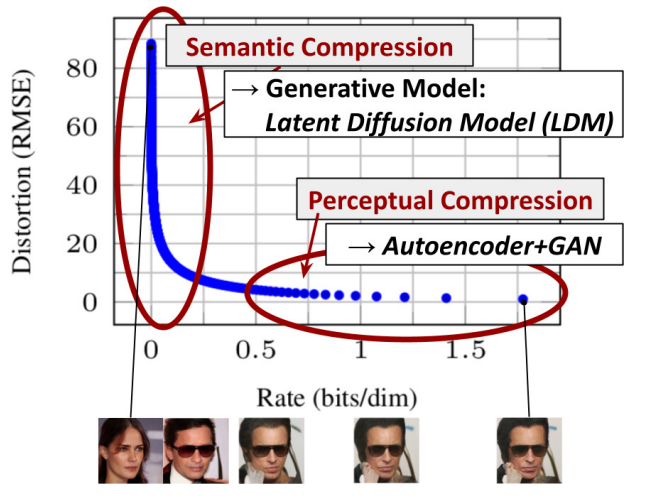
-
*Perceptual compression(지각 기반 압축) - high-frequency detail를 제거하지만 의미(semantic)는 학습 하지 않는 단계
-
*Semantic compression(의미 압축) - 실제 생성 모델이 데이터의 의미론적(semantic)구성 및 개념적(conceptual)구성을 학습하는 단계
-> Perceptual하게 동등하지만 계산적으로 더 적합한 space를 찾는 것을 목표로 고해상도 이미지 합성을 위한 diffusion model을 학습
Perceptual compression
Perceptual Compression은 인간의 지각적 특징을 활용하여 데이터를 압축하는 기법, 인간의 눈이나 귀가 잘 감지하지 못하는 정보를 줄이거나 제거함으로써 압축 효율을 높임
- 비디오 압축에서 고주파 영역의 세부사항을 제거
- 오디오 압축에서 사람이 들을 수 없는 고주파 대역 제거(MP3 형식)
- JPEG 이미지 압축에서 눈에 덜 띄는 색상 정보 축소
Semantic compression
데이터의 저차원 표현을 줄이는 대신, 데이터의 의미나 고수준 정보를 유지하면서 불필요한 세부 정보를 제거하는 압축 기법
- 이미지 데이터에서 구체적인 픽셀 값 대신 "사람", "나무"와 같은 객체 정보를 중심으로 데이터를 표현하는 방식
- e.g. 자연어 처리에서 단어의 의미적 유사성을 이용해 단어 벡터 크기를 줄이는 방식(Word2Vec, GPT 모델 등)
학습과정
데이터 Space와 Perceptual하게 동일한 저차원 representational space(표현공간)로 보내는 autoencoder를 학습, 해당 과정에서 학습된 잠재 공간에서 diffusion model을 학습시키므로 이전 모델과 달리 과도한 space 압축에 의존할 필요가 없어집니다.
또한 감소된 복잡성으로 인해 네트워크를 한 번만 통과하여 latent space에서 효율적인 이미지가 생성되고 이 모델을 LDM(Latent Diffusion Models)라고 합니다.
장점
- 범용 autoencoding 단계를 한 번만 학습하면 되어 diffusion model 학습에 재사용하거나 완전히 다른 task를 탐색 가능
- image-to-image 및 text-to image task를 위한 여러 diffusion model을 효율적 탐색
- e.g. 트랜스포머를 diffusion model의 UNet backbone에 연결하여 임의의 유형의 토큰으로 조건을 주는 아키텍처 설계
representational space (표현공간)
데이터를 추상적으로 표현하는 공간을 의미합니다. 이는 주로 데이터의 복잡한 특성을 저차원에서 간결하게 표현하거나 분석하기 위해 사용
- 원 데이터를 저차원 공간으로 매핑: 이미지의 모든 픽셀 데이터를 고차원의 공간에서 특정 패턴(e.g.고양이, 개 등)을 나타내는 저차원 공간으로 변환
- 터 특징을 보존: 원래 데이터의 중요한 특징(특성 벡터)을 유지하면서 불필요한 정보를 줄임
autoencoder
인공 신경망을 활용해 데이터를 효율적으로 압축(인코딩)하고 다시 원래 형태로 복원(디코딩)하는 신경망 아키텍처
- 구성 요소:
- Encoder (인코더): 입력 데이터를 저차원의 잠재 공간(latent space) 또는 표현 공간으로 압축
- Latent Space: 데이터를 간결하게 표현한 저차원 벡터가 위치한 공간
- Decoder (디코더): 압축된 벡터를 원래 데이터와 유사한 출력으로 복원
- 주요 목적:
- 차원 축소: PCA와 유사하게 고차원 데이터를 저차원으로 변환하면서 데이터의 중요한 특성을 유지
- 잡음 제거: 손상된 데이터를 입력으로 받아 원래의 깨끗한 데이터를 복원 (Denoising Autoencoder)
- 생성 모델: Variational Autoencoder(VAE)는 새로운 데이터를 생성하는 데 사용
- 동작 방식:
- 입력 데이터 → 인코더 → 표현 공간(잠재 공간)으로 압축
- 표현 공간 → 디코더 → 원본과 유사한 출력 생성
