고해상도 이미지 합성에 대한 Diffusion Model(확산 모델) 학습의 계산량을 낮추기 위해 Diffusion Model이 해당 손실 항을 적게 샘플링하여 Perceptual(지각적인) 세부사항들을 줄일 수 있지만, 그렇더라도 픽셀 공간에 대한 계산 비용이 많이 들어 시간과 컴퓨팅 리소스가 많이 필요합니다.
논문에서는 학습 단계에서 압축을 명시적으로 분리하여 해단 단점을 보안 하도록 합니다. 이를 위해 이미지 공간과 지각적으로 동일한 공간을 학습하지만 계산 복잡성을 줄여주는 autoencoding 모델을 활용합니다.
해당 방법의 장점으로는
- 고차원 이미지 공간을 남겨두어 저차원 공간에서 샘플링이 수행되기 때문에 계산적으로 효율적
- Unet 아키텍처에서 상송된 Diffusion Model의 inductive bias를 활용하여 공간 구조가 있는 데이터에 효과적
- Latent Space가 여러 생성 모델을 학습시키는 데 사용할 수 있고 downstream task(e.g., CLIP-guided synthesis)에도 활용 가능한 범용 압축 모델을 얻을 수 있음
1. Perceptual Image Compression
Perceptual loss와 patch-based adversarial objective의 조합으로 학습 되는 autoencoder로 구성됩니다.
local realism이 적영되어 재구성 image manifold에 국한되고 objective와 같은 pixel space loss에만 의존하여 발생하는 노이즈(흐릿함)을 방지할 수 있습니다.
1-1) 해당 관련 수식
1. RGB 이미지 에 대하여 인코더 가 를 latent representation 로 인코딩합니다.
2. 디코더 가 latent 로 부터 이미지를 재구성하여 를 만들어 줍니다.
3. 인코더는 이미지를 factor 로 downsampling 하고 에 대하여 fator를 으로 둔다.
Latent space의 분산이 커지는 것을 방지 하기 위해 두 가지 종류로 정규화를 진행
방법1) KL 정규화는 VAE와 유사하게 학습된 latent에서 표준 정규분포에 대해 약간의 KL 패널티를 부과합니다.
방법2) VQ 정규화는 디코더 내에서 벡터 양자화 layer를 사용합니다. 이 모델은 VQGAN으로 해석 될 수 있지만 양자화 layer가 디코더에 의해 흡수 됩니다. LDM은 학습된 latent sapce 의 2차원 구조와 함께 작동하도록 설계되었기 때문에 상대적으로 약한 압축률을 사용하고도 매우 우수한 재구성이 가능합니다. 결과적으로 LDM의 압축 모델은 의 detail들을 더 잘 보존합니다.
Perceptual Image Compression
해당 논문에서 말하는 Perceptual Image Compression는 Autoencoder에서 Latent Space를 학습하는 것을 뜻하며, 이 때 Latent Space의 분산이 크면 Latent Space가 가지고 있는 정보가 이질적이므로 작은 분산을 가지도록 Regularization을 가지고 실험을 진행
Regulariztion 종류
- KL-reg : 학습된 Latent에 약간의 KL-penalty를 줌
- VQ-reg : Decoder안에 Vector Quantiztion을 사용
2차원 구조의 Latent Space를 설계하여 1차원 모델인 Compression과 Reconstruction 성능이 좋음.
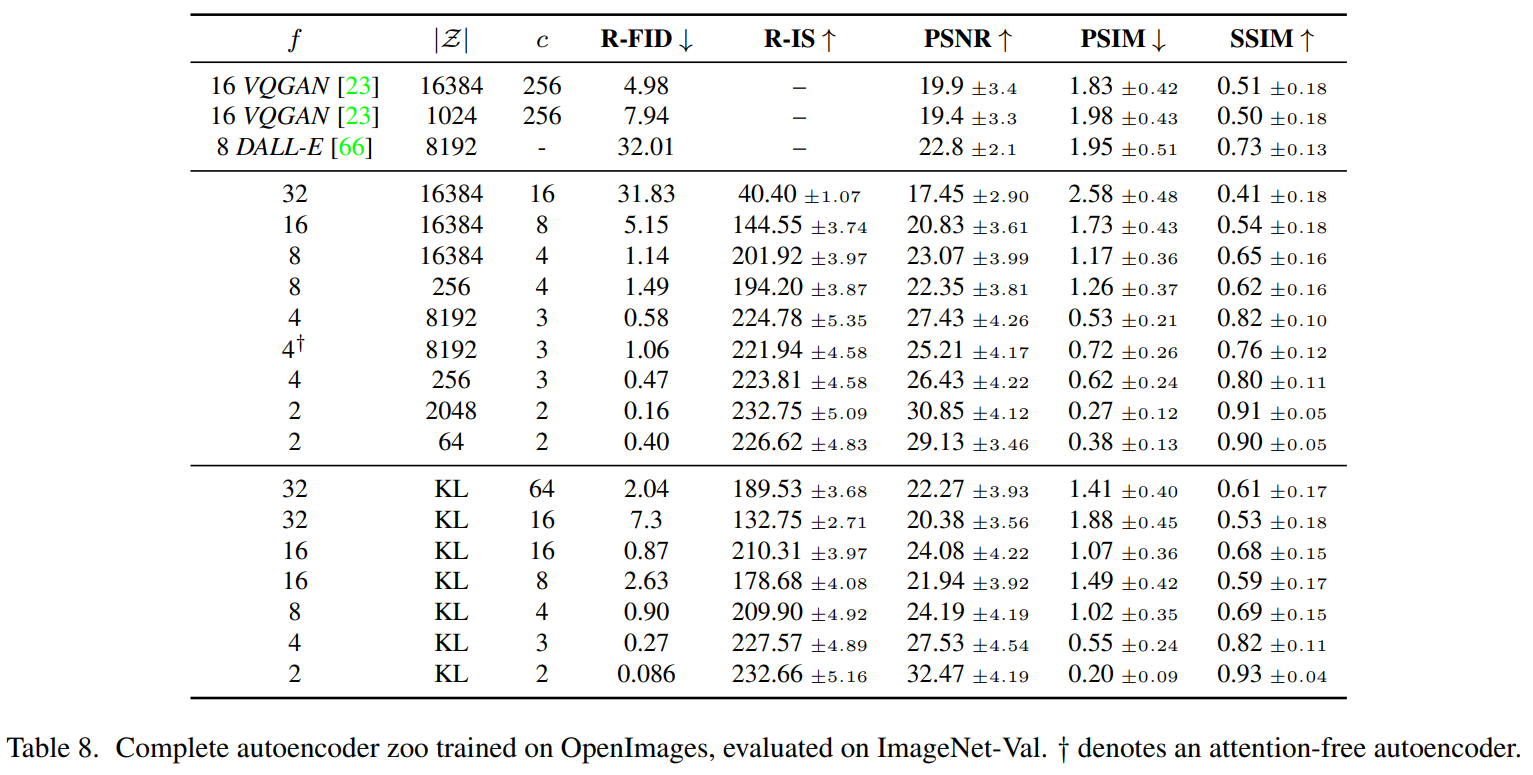
결과표
Autoencoder는 patch-based discriminator 로 adversarial 방식으로 학습하며, 높은 수준의 재구성을 위해 매우 작은 크기의 정규화를 사용합니다. 예를 들어, KL항에 대한 가중치를 으로 작게 두거나 코드북 차원 을 높게 설정합니다.
Autoencoding model 의 전체 목적 함수 수식
-
- Encoder 와 Decoder 의 파라미터를 최적화하여 손실 함수 를 최소화하려는 과정
- 와 는 Autoencoder의 주요 구성 요소로, 는 입력 를 latent space으로 변환하고, 는 잠재 공간에서 다시 원래의 로 복원
-
- 의 파라미터를 최적화하여 손실 함수의 일부를 최대화하는 과정
- 판별자가 생성자(즉, )가 생성한 샘플과 실제 데이터를 더 잘 구별하도록 학습하는 adversarial(적대적)훈련의 핵심
-
전체 구조
- , : Autoencoder 는 Reconstruction Loss와 Regularization Term을 최소화하면서, 는 Adversarial Loss를 최대화 하려고 서로 경쟁
- 이 구조는 Adversarial Training의 원리따름
- 와 간의 상호작용으로 모델은 더 강력한 reconstruction(재구성)능력과 현실감 있는 샘플을 생성
-
나머지 수식 의미
- - 입력 와 Autoencoder가 복원한 간의 재구성 손실
- - Adversarial Loss, 가 를 진짜와 구분하려는 손실
- - Discriminator가 실제 데이터 를 진짜로 분류하는 데 성공했는지를 측정
- - Regularization Loss로, 모델의 일반화 성능을 향상시키기 위해 추가된 항목
-
결론
- - Autoencoder가 자신의 성능(재구성 및 현실감)을 최대화하려고 노력
- - Discriminator가 샘플 구별 능력을 강화하려고 노력
- Autoencoder와 Discriminator가 경쟁하면서 동시에 학습하는 Adversarial Training의 핵심 개념
수학 기호 의미
- 임의의 작은 양수
- 자연수
- 실수
- 기댓값 (Expected Value)
- 오른쪽에 속함
- Discriminator() : 판별자 : 파라미터
다음에는 Latent Diffusion Models에 대한 해석을 준비하도록 하겠습니다.
