
우리 프로젝트의 핵심 기능이 될 Speech Translation 파이프라인과 Faceswap 파이프라인은 고성능 모델을 사용해서 GPU 서버 환경에서 돌아가야하기때문에, 나 포함 팀원들의 컴퓨터에서 실행할 수 없음.
GPU 서버란 필요한 만큼 GPU를 할당받아서 사용가능한 컴퓨팅 서비스라고 함. 일종의 Google Colab.
Google Cloud Compute Engine
이전에 공용 DB를 만들기 위해 가상 머신 인스턴스를 만들었음. 그것과 비슷하게 GPU 인스턴스를 생성하고 거기에 GPU 환경에서 돌아가야할 코드를 동작하게끔 만들어줄 것임.
우선 GCP 홈페이지에 들어가서 Compute Engine 페이지에 들어감.
컴퓨팅 워크로드용 GPU
컴퓨팅 워크로드의 경우 GPU는 다음 머신 유형에 지원됩니다.A3 VM: NVIDIA H100 80GB GPU가 자동으로 연결됩니다. A2 VM: NVIDIA A100 80GB 또는 NVIDIA A100 40GB GPU가 자동으로 연결됩니다. G2 VM: NVIDIA L4 GPU가 자동으로 연결됩니다. N1 VM: NVIDIA T4, NVIDIA V100, NVIDIA P100, NVIDIA P4 GPU 모델을 연결할 수 있습니다.
GPU
GPU 머신 유형으로 NVDIA H100 80GB, A100 80GB, L4, T4, V100, P100, P4가 있다고 하는데, NVIDIA GPU는 크게 3 종류로 나뉨.
- GeForce: 일반적인 게임용
- Qudro: 전문가용, 3d 작업
- A100: high-performance computing (HPC) applications용. 우주공학, 유전자 계산 등 고성능 컴퓨팅용.
NVIDIA GPU GeForce 스펙 읽는 방법
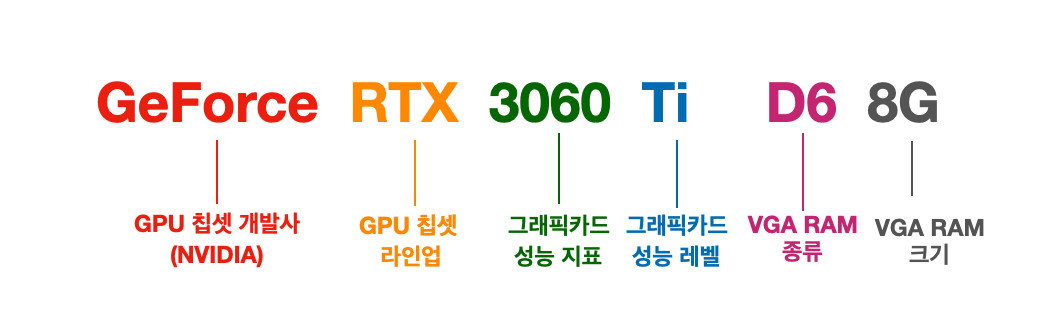
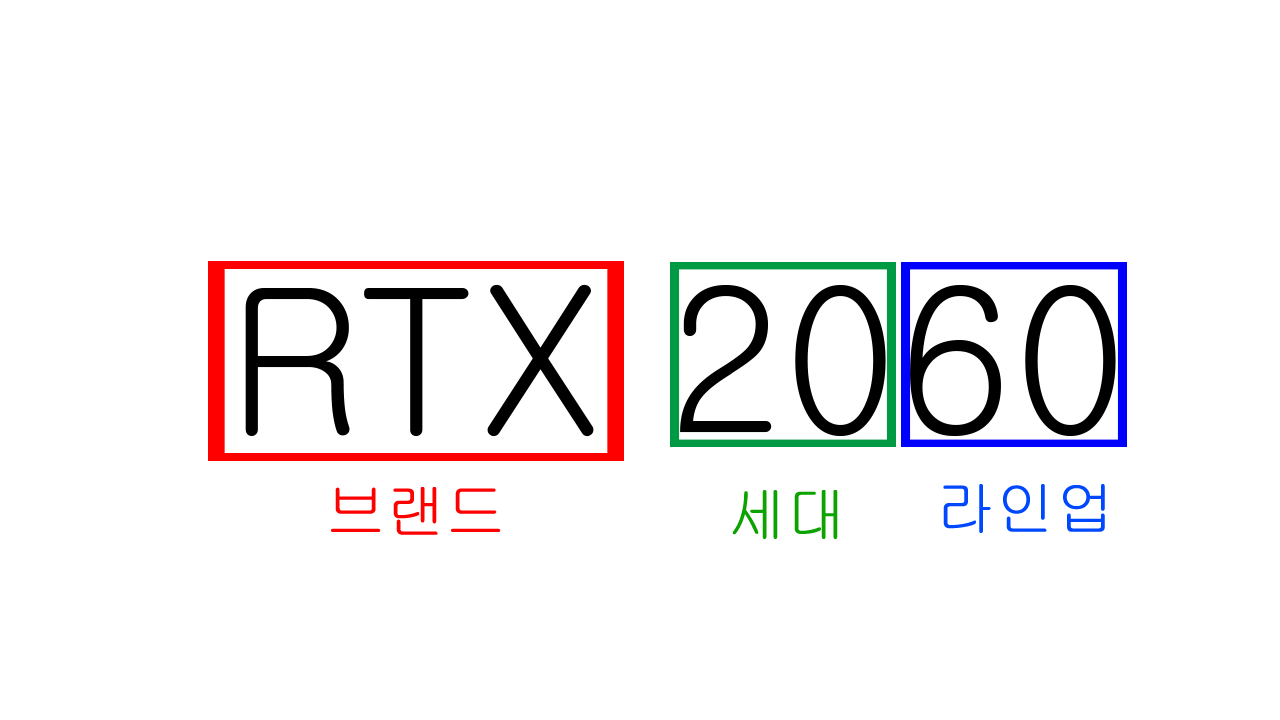
NVIDIA GPU RTX 스펙 읽는 방법
-
앞의 두 자리는 세대를 의미하고, 10, 20, 30 등 10씩 늘어남. 1세대, 2세대, 3세대라고 부름.
-
뒤의 두 자리는 라인업을 의미하고, 쉽게 생각해서 버전이라고 생각하면 됨.
A100 서버용 GPU

한 장당 약 5천만원 가량한다고 함. 서버용이라서 일반 컴퓨터에 부착하는 용도가 아님. 대여폭이 일반 컴퓨터용보다 크기 때문에 성능이 훠얼씬 좋다고 함.마더보드 or 메인보드

이렇게 생긴 마더보드(=메인보드)에 CPU, 메모리, PCIe 등을 꼽는 것인데, 하드웨어는 잘 모르기때문에 앞으로 차차 공부할 예정.
인스턴스 생성
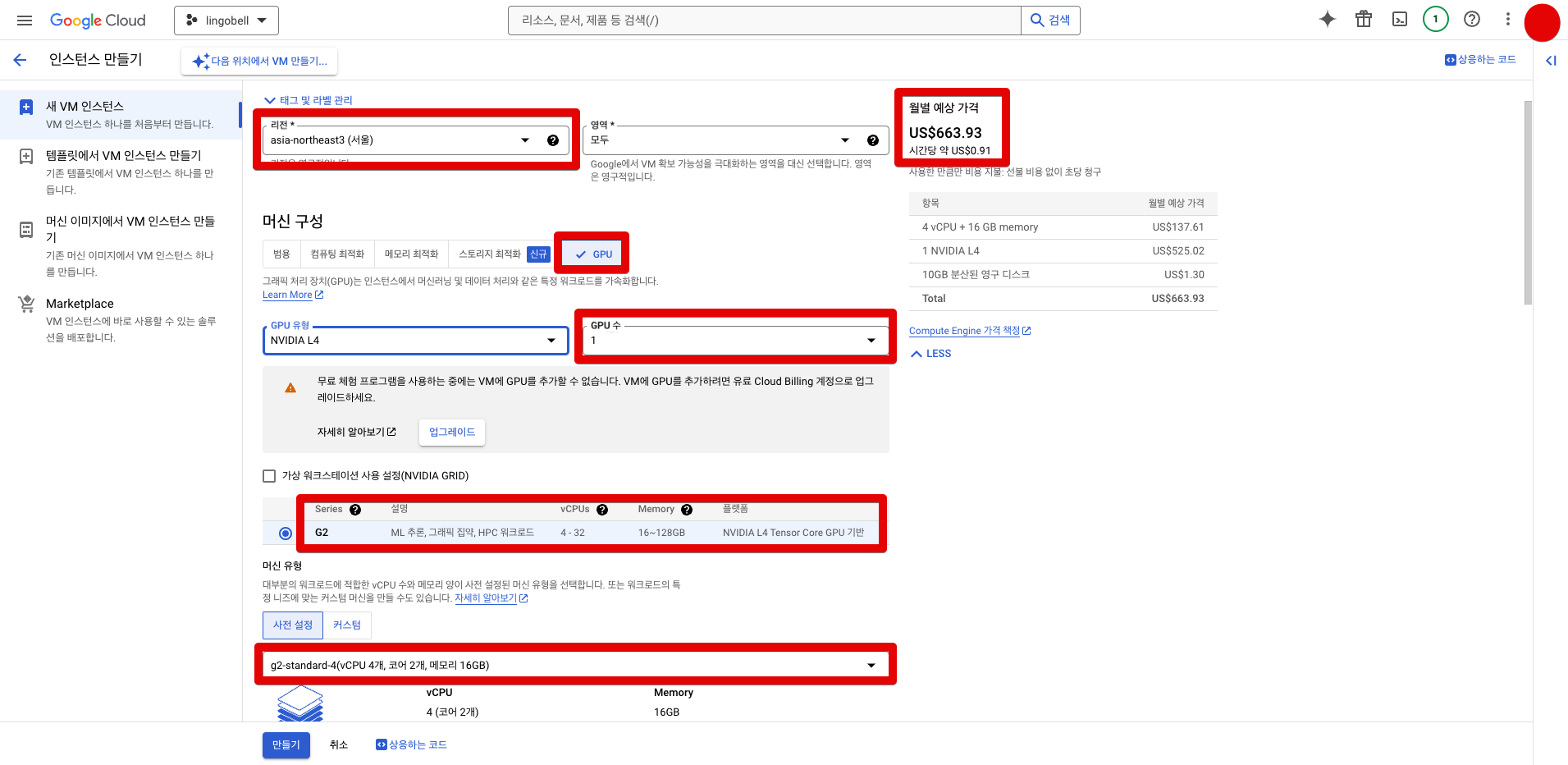
- 머신 계열: NVIDIDA GPU
- 시리즈: G2
- 머신유형: g2-standard-4
- region: asia-northeast3-b
- 부팅 디스크 운영체제: Ubuntu 20.04 LTS
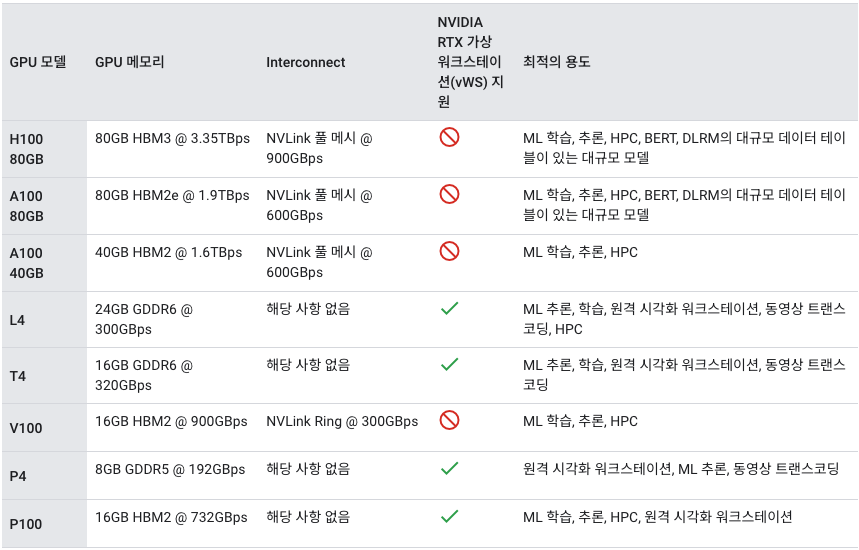
GCP에 나와있는 일반 비교 차트를 보면, 알파벳뒤에 세 자리 숫자가 붙어있는 GPU 모델이 있고 한 자리 숫자가 붙어있는 모델이 있음. 한 자리 수인 L4와 T4는 모델을 학습할때 사용하는 것이 아닌 추론할때 사용하는 모델임. 우리 프로젝트에는 추론만 하면 되기때문에 가격 경쟁력있는 L4를 사용함.
GCP의 GPU 서버 인스턴스를 활용하여 코드 실행
-
GCP 인스턴스 접속
gcloud compute ssh <인스턴스 이름> --zone <region 정보: 나는 asia-northeast3-b로 했음>
-
CUDA, cuDNN 설치
sudo apt-get update sudo apt-get install -y build-essential sudo apt-get install -y cuda tar -xzvf cudnn-*-linux-x64-v*.tgz sudo cp cuda/include/cudnn*.h /usr/local/cuda/include sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64 sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*쿠다 설치하는 도중에 디스크 용량 다 참. 기본 10GB를 그대로 두고 인스턴스 생성했는데,CUDA 설치하는데에만 9.5GB를 차지함. 그래서 다시 GCP가서 50GB로 수정하고 다시 CUDA 설치 시작함.
-
Python, 필요한 패키지 설치
sudo apt-get install -y python3 python3-pip conda create -n <GPU 서버에서 실행시킬 파일 이름> python=<사용할 파이썬 버전: ex) 3.10> conda activate <생성한 파일 이름> -
코드 업로드
scp -r /path/to/local/code <유저>@<GPU 서버의 인스턴스 IP>:/path/to/remote/directory -
포트 포워딩 설정
GCP 방화벽 규칙에 엑세스 허용을 설정해줘야 외부에서 접속할 수 있음.
- 방화벽 규칙 추가
- GPU 서버 인스턴스에 태그 추가
-
프론트엔드 API 호출부에 GPU 서버 호출 추가
const response = await axios.post('http://<인스턴스 IP주소>:8000/api/endpoint', data);프론트엔드에서 GPU서버로 오디오 파일이 STT를 성공적으로 하는 모습.

