
멘토님이 강조하신 본질을 이해하라는 말씀을 듣고 계속해서 되뇌었음. 뭘 공부해야할까? 지금 내가 놓치는건 뭘까?
음성을 텍스트로 처리하는 STT 기술에 Whisper 모델이 사용되는데 이 STT기술은 실시간성을 고려하고 만들어진 기술이 아님.
그럼 데이터 관점에서 어떻게 실시간적인 STT 작업을 할 수 있음?
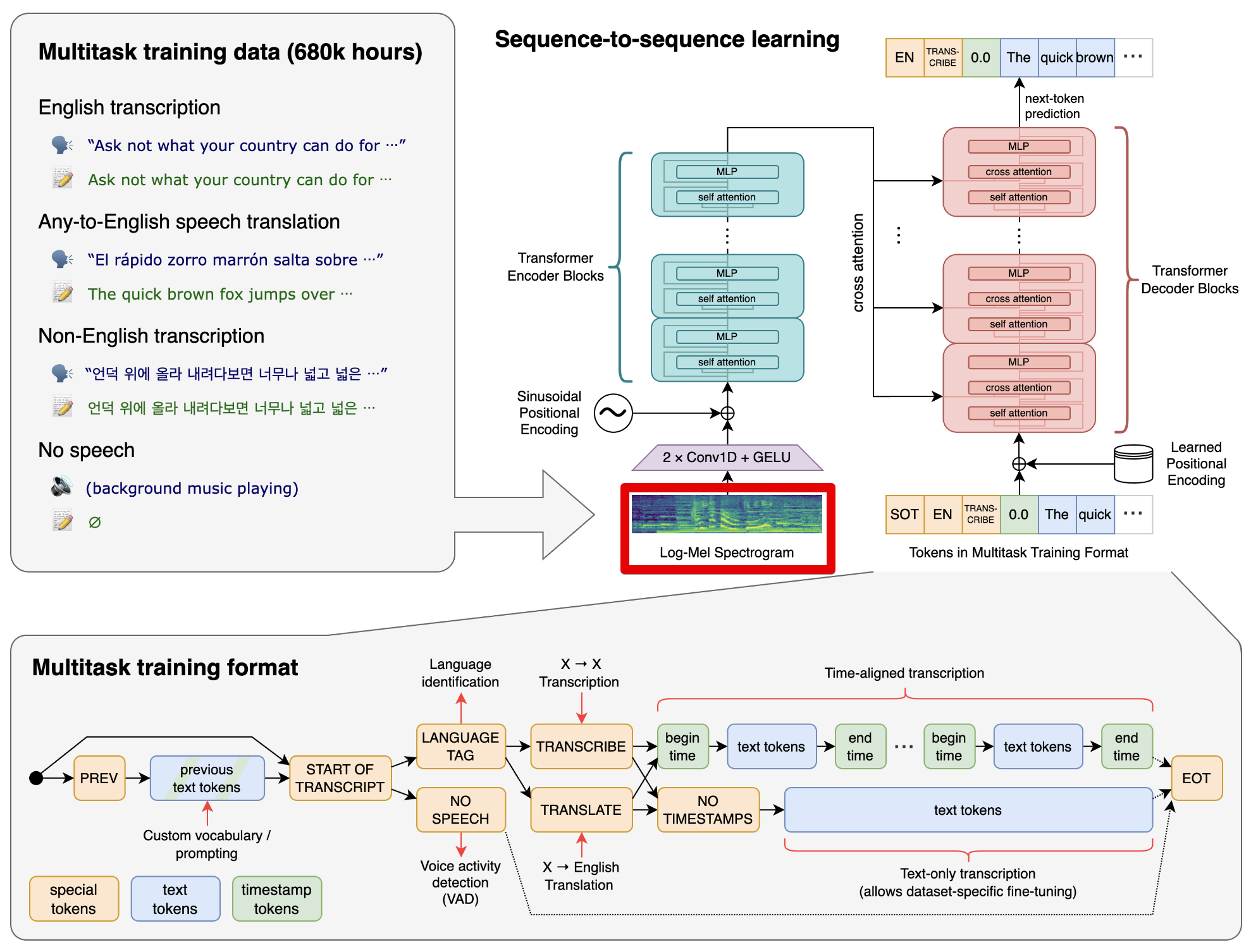
Speech to text는 오디오 데이터를 30초 분량을 하나의 chunk 단위로 입력받으면 인코더와 디코더를 지나 하나의 토큰을 생성하고, 이 과정을 무수히 많이 반복하는 로직을 갖는다.
Whisper는 실시간과 거리가 멀다.
- 30초 보다 긴 오디오 데이터를 입력받는다면?
Whisper는 완전한 문장으로 학습된 모델임. 하지만 입력된 오디오가 완전하지 않다면 당연히 성능은 떨어질 수 밖에 없음.
- 30초 간격의 chunk 단위로 오디오를 끊는다면, 중간에 끊기는 문장이 발생할 수 있음.
- 30초 보다 짧은 오디오 데이터를 입력받는다면?
30초 단위의 청크를 기반으로 추론하기때문에 불필요한 latency가 발생하고, 실시간적으로 토큰을 필요하는 상황과 맞지 않음.
Whisper-Streaming
ufal/whisper_streaming Github repository
'Turning Whisper into Real-Time Transcription System' 논문 링크
논문의 Abstract
Whisper is one of the recent state-of-the-art multilingual speech recognition and translation models, however, it is not designed for real time transcription. In this paper, we build on top of Whisper and create Whisper-Streaming, an implementation of real-time speech transcription and translation of Whisper-like models. Whisper-Streaming uses local agreement policy with self-adaptive latency to enable streaming transcription. We show that WhisperStreaming achieves high quality and 3.3 seconds latency on unsegmented long-form speech transcription test set, and we demonstrate its robustness and practical usability as a component in live transcription service at a multilingual conference.
Whisper-streaming

- 오디오 데이터를 일정시간 간격으로 나눔. 이것이 chunk이고 이 크기는 minimum_chunk_size 매개변수로 설정됨. 기본값으로 1초가 설정되어있음.
- 각 iteration에서 audio buffer의 크기를 1초씩 증가시켜서 whisper streaming에 입력함.
- 문장 끝에 마침표나 물음표 등을 만날때까지 오디오 데이터를 반복적으로 처리함. 문장의 끝에 도달하면 현재 버퍼 내용을 처리하고, 버퍼를 다음으로 이동시켜서 다음 문장을 처리하기 시작함.
=> Whisper는 문장단위로 훈련되었기때문에 당연히 시작과 끝이 완전한 문장이 입력되면 가장 최적의 결과를 제공함.
Local Agreement (n=2) 알고리즘
Local Agreement 알고리즘은 토큰이 확정되기 위해 두 개의 연속적인 오디오 버퍼에서 동일하게 생성되어야함.
LocalAgreement (Liu et al., 2020) is a streaming policy that outputs the longest common prefix
of the model on n consecutive source chunks, or an
empty segment when less than n chunks are available. Based on the IWSLT 2022 shared task on simultaneous translation, the CUNI-KIT system compared LocalAgreement to other policies (hold-n
and wait-k) with different chunk sizes. They found
that LocalAgreement with n = 2 was the most effective policy. Therefore, we use LocalAgreement2 for identifying stabilized target segments.
- 최초로 토큰이 출력되면 공통된 prefix로 확정할 비교대상이 없기때문에 아무것도 확정되지 않음.
- 모델이 인코더, 디코더 과정을 거쳐서 더 많은 토큰을 생성해내고, 이때 기존에 생성된 토큰과 동일하다면 확정함.
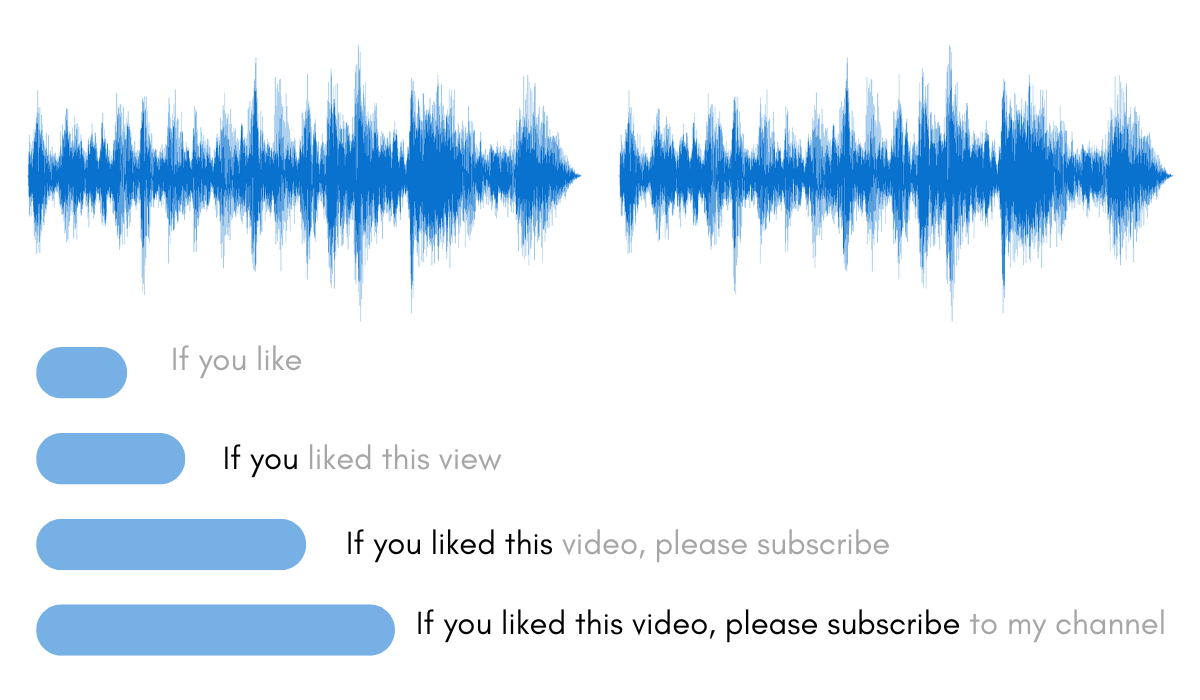
- Whisper 모델이 "if you like"라는 세 개의 토큰을 출력함.
- "if you like to"라고 할 때, 첫 번째와 두 번째 토큰인 "if you"는 이전 단계와 일치하므로 이 두 토큰은 확정됨.
- 최소 두 개의 연속적인 chunk에서 생성되기 전까지는 확정되지 않음.
"view"라는 처음에 생성된 토큰이 "video"로 변경됨.
Prompt tokens

Joining for inter-sentence context
The Whisper transcribe function utilizes a “prompt” parameter to maintain consistency within a document (consistent style, terminology, and inter-sentence references). We extract the last 200 words from the
confirmed output of previous audio buffers as the
“prompt” parameter, as shown in Figure 1 (yellow
backgrounded text).
논문의 참고 이미지에 나와있듯이 생성된 토큰은 prompt으로 사용되기때문에, STT의 통일성이 유지될 수 있음.

쫌 치네요 진우님