Pretraining이 사용되는 경우가 있음.
- 헬스케어, 법조계 산업 등 분야에 따라 pretrain을 해야하는 경우
- 일본어나 태국어 등 언어에 따라 pretrain을 해야하는 경우
Why Pre-training
Pretraining이 가장 효율적인 방법인 경우에 대해 학습
pretraining없이 fine tuning만으로 새로운 지식을 추가하려고 하는 경우가 많은데, base model에 새로운 지식이 not well represented하다면, 결과가 좋지 않다고 함.

Generate Python samples with finedtuned Python model
가장 큰 숫자를 정의하는 함수를 생성하라고 프롬트를 작성할때, finedtuning만 된 모델을 사용하면, 아래와 같이 부정확한 결과가 나옴. 
Generate Python samples with pretrained Python model
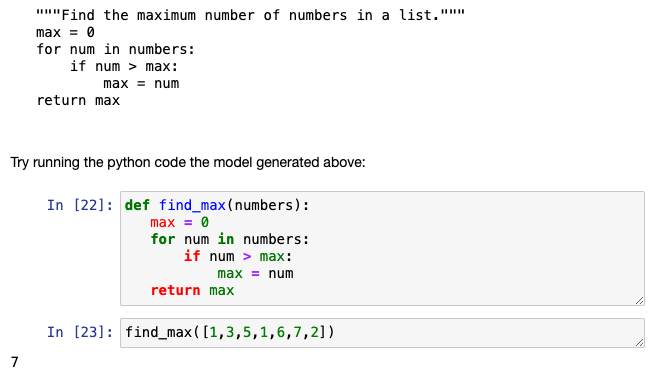
정확한 함수 코드가 생성되고, 작동시켜보면 정확한 값을 도출하는 것 확인.
Data Preparation
Pretrain을 할때 높은 품질의 데이터셋을 사용하는 것이 중요함.

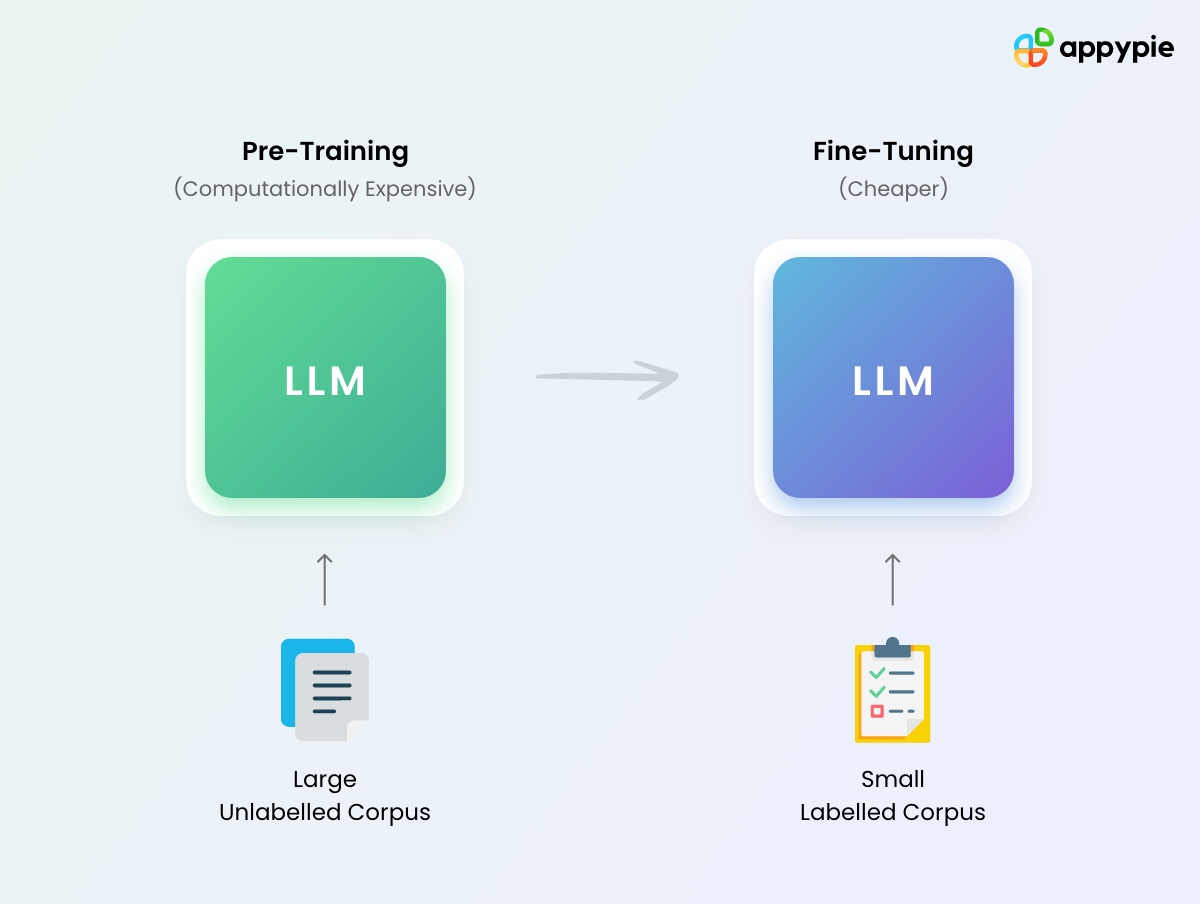
- Pretraining은 마치 많은 책을 읽고, 지식을 학습하는 개념과 비슷
- Fine-tuning은 시험에서 잘 볼 수 있게 질문에 대한 답을 찾는 개념과 비슷

- 반복되는 불필요한 단어를 사전에 삭제
- 영어 LLM을 만들고 싶으면 영어를 제외한 다른 외국어는 삭제
- Toxic language 삭제
- 개인정보 삭제
- 문서 작성 형식에 신경 써야함
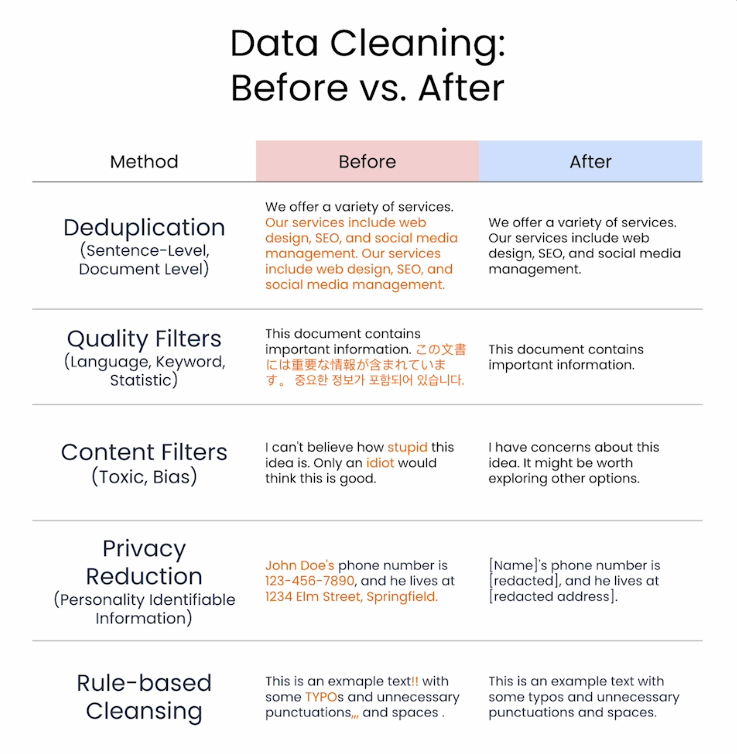
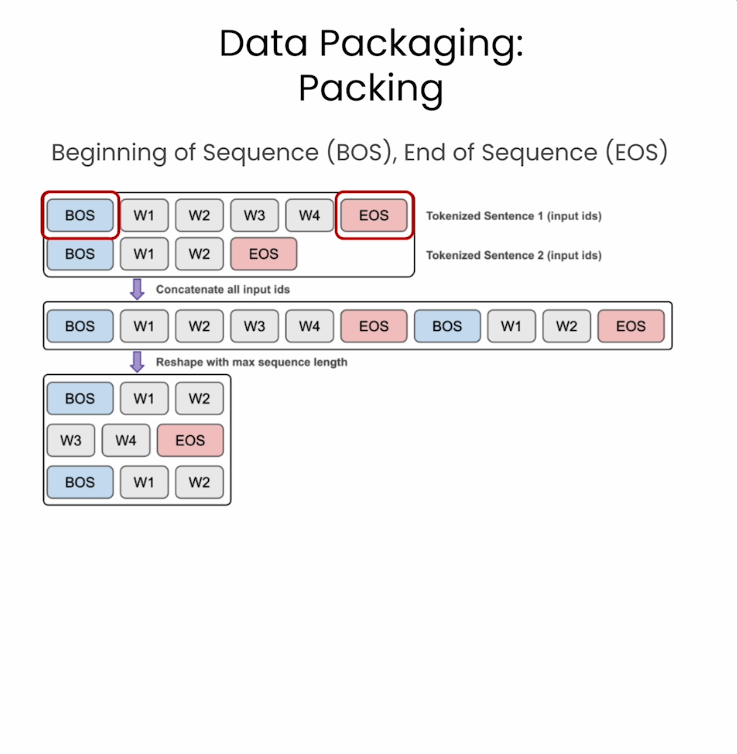
Packaging Data for Pretraining

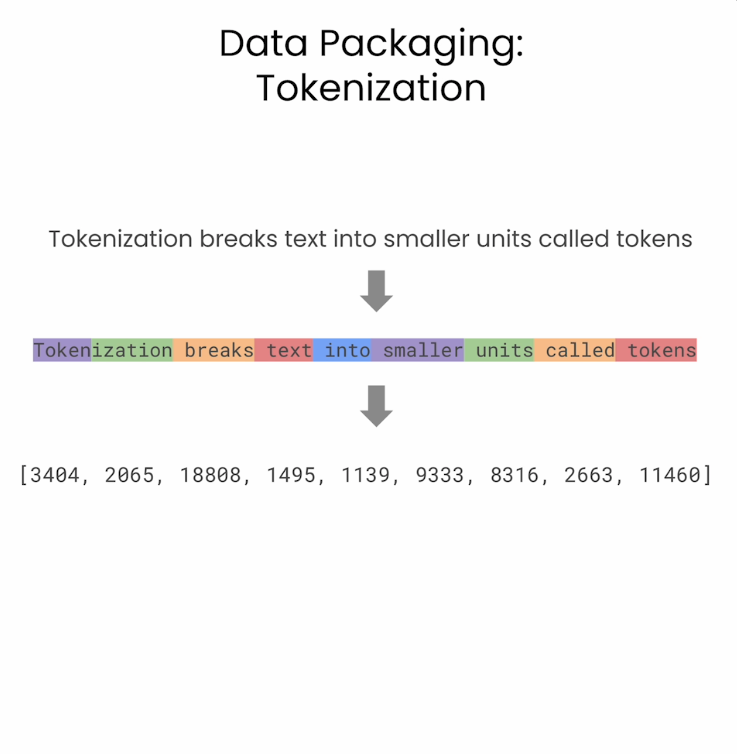
1. Tokenizing and creating input_ids
Tokenization을 통해 문장text을 토큰이라 불리는 작은 유닛으로 나눔.
2. Packing
Reshape해야함. Sequence의 처음과 마지막 부분에 special token을 추가해해서 패키징함.
- BOS: Beginning of Sequences
- EOS: End of Sequences