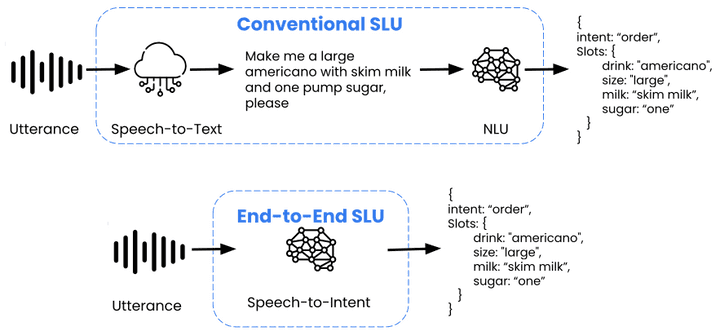
Speech to Intent란?
S2I(Speech to Intent) 모델은 음성 데이터를 텍스트로 변환하는 중간 단계를 생략하고, 음성 데이터만으로 사용자의 의도를 바로 파악하는 기술임. 기존의 NLU(Natural Language Understanding) 방식에서는 음성을 먼저 텍스트로 변환한 다음 텍스트를 분석해서 의도를 추론하는데, S2I는 음성을 바로 처리해서 더 빠르게 의도를 파악하는 게 특징임.
S2I에 사용되는 두 가지 기법
NLU (Natural Language Understanding):
작동 방법: 먼저 음성 데이터를 STT(Speech to Text)로 텍스트로 변환하고, 그 텍스트를 분석해서 사용자의 의도를 파악하는 방식.
장점: 텍스트 기반의 분석이기 때문에 다양한 데이터셋과 모델들이 이미 많이 나와 있고, 정확도가 높음.
단점: 텍스트로 변환하는 과정에서 지연이 생길 수 있고, 그 과정에서 오류가 생기면 의도 분석도 잘못될 수 있음.
SLU (Spoken Language Understanding):
작동 방법: 음성을 바로 분석해서 텍스트로 변환하는 과정 없이 의도를 파악하는 방식.
장점: 텍스트 변환을 생략하기 때문에 더 빠르고, 실시간 처리에 적합.
단점: 학습 가능한 데이터가 적고, 특정 도메인에 특화된 경우가 많아서 범용적으로 쓰기는 어려움.
NLU vs SLU 비교
| 구분 | NLU | SLU |
|---|---|---|
| 작동 방식 | 음성 → 텍스트 변환 후 의도 분석 | 음성을 바로 분석해서 의도 파악 |
| 속도 | 텍스트 변환 과정 때문에 느림 | 빠름, 실시간 처리 가능 |
| 장점 | 이미 널리 사용되고 다양한 데이터셋 활용 가능 | 텍스트 변환 없이 바로 음성을 처리함 |
| 단점 | 변환 과정에서 발생하는 오류와 지연 | 학습 가능한 데이터 제한, 도메인 특화 |
S2I 모델들
S2I-Micro
모델 사이즈: 29 KB (소형 모델)
장점: 빠른 추론 시간으로 실시간 처리에 적합하고, 저전력 장치에서도 동작
단점: 간단한 명령어에 대한 의도 분류에만 적합하며, 다국어 지원은 안 됨
Snips NLU
모델 사이즈: Python 라이브러리 기반의 경량 모델
장점: CPU에서도 가볍게 동작하고, 사용자가 명령어와 슬롯을 직접 정의해서 맞춤형 학습이 가능하다. 다국어도 지원함.
단점: 버전 호환성 문제로 환경에 따라 적용이 어려울 수 있음.
distilbert-base-uncased-mnli
모델 사이즈: 67M 파라미터 (소형)
장점: 빠른 추론 속도와 다국어 지원이 가능하다. 실시간 처리에도 적합하다.
단점: 상대적으로 성능이 떨어질 수 있다.
xlm-roberta-large-xnli
모델 사이즈: 355M 파라미터 (대형 모델)
장점: 다국어 지원이 가능하고, 다양한 언어에서 뛰어난 성능을 보인다.
단점: 모델이 크고, 메모리와 리소스를 많이 사용해서 지연이 생길 수 있다.
추가 연구가 필요한 모델들
- synesthesiam/voice2json: 음성을 JSON 형식으로 변환하는 음성 인식 모델
- hritools/speech-to-intents: 음성을 바로 의도로 변환하는 S2I 모델
- LuluW8071/Virtual-Assistant: 음성 인식과 의도 분석을 결합한 가상 비서 시스템
- qanastek/XLMRoberta-Alexa-Intents-Classification: XLM-R 기반의 알렉사 의도 분류 모델
- jameslyons/python_speech_features: 음성 인식 및 처리를 위한 Python 라이브러리
결론
S2I 모델은 음성을 바로 처리하는 덕에 빠른 추론 속도와 실시간 처리에 강점이 있지만, 다국어 지원이나 복잡한 의도 처리에서는 성능이 부족할 수 있음. 프로젝트에 맞는 모델을 선택하려면 성능과 확장성을 잘 고려해서 판단하는 게 중요함.
