역할 분배
프론트엔드와 백엔드의 기본 틀 구조를 맞췄음. 이제 본격적으로 AI 모델들을 붙여서 서비스 완성도를 높혀야 함.
멘토링 시간을 통해 각자 역할을 분배했는데, ㅈㅎ님은 WebRTC를 통해 사용자간의 통신을 구축하고, ㅅㅇ님은 firebase로 사용자 인증 및 로그인을 구현을 담당하기로 함.
나는 마이크로 입력된 오디오 데이터를 텍스트로 변환하고, 이를 NLP 처리해서 사용자의 모국어로 번역하고 다시 TTS로 오디오 데이터로 출력하는 기능을 맡았음.
STT 리서치
오디오 input을 인코더와 디코더를 거쳐 토큰(텍스트)로 변환하는 과정을 갖는데, 한 번 작업을 수행할때 하나의 토큰을 반환함. 이를 GPU 서버에서 반복적으로 여러번 수행해서 사용함. 일반적은 생성형 AI모델과 유사함.
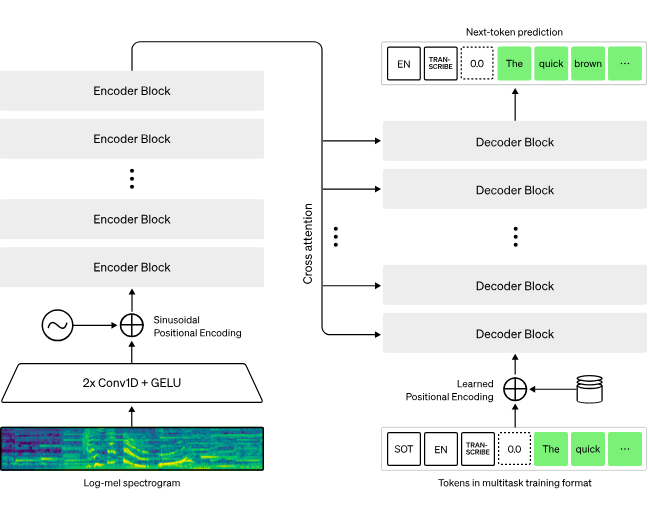
STT 기법에 가장 유명한 모델로 OpenAI에서 만든 Whisper가 있음.
Hugging Face Spaces에도 다양한 모델들이 있고, 구글에 검색해도 많은 깃허브 레포지토리가 있음.
Whisper
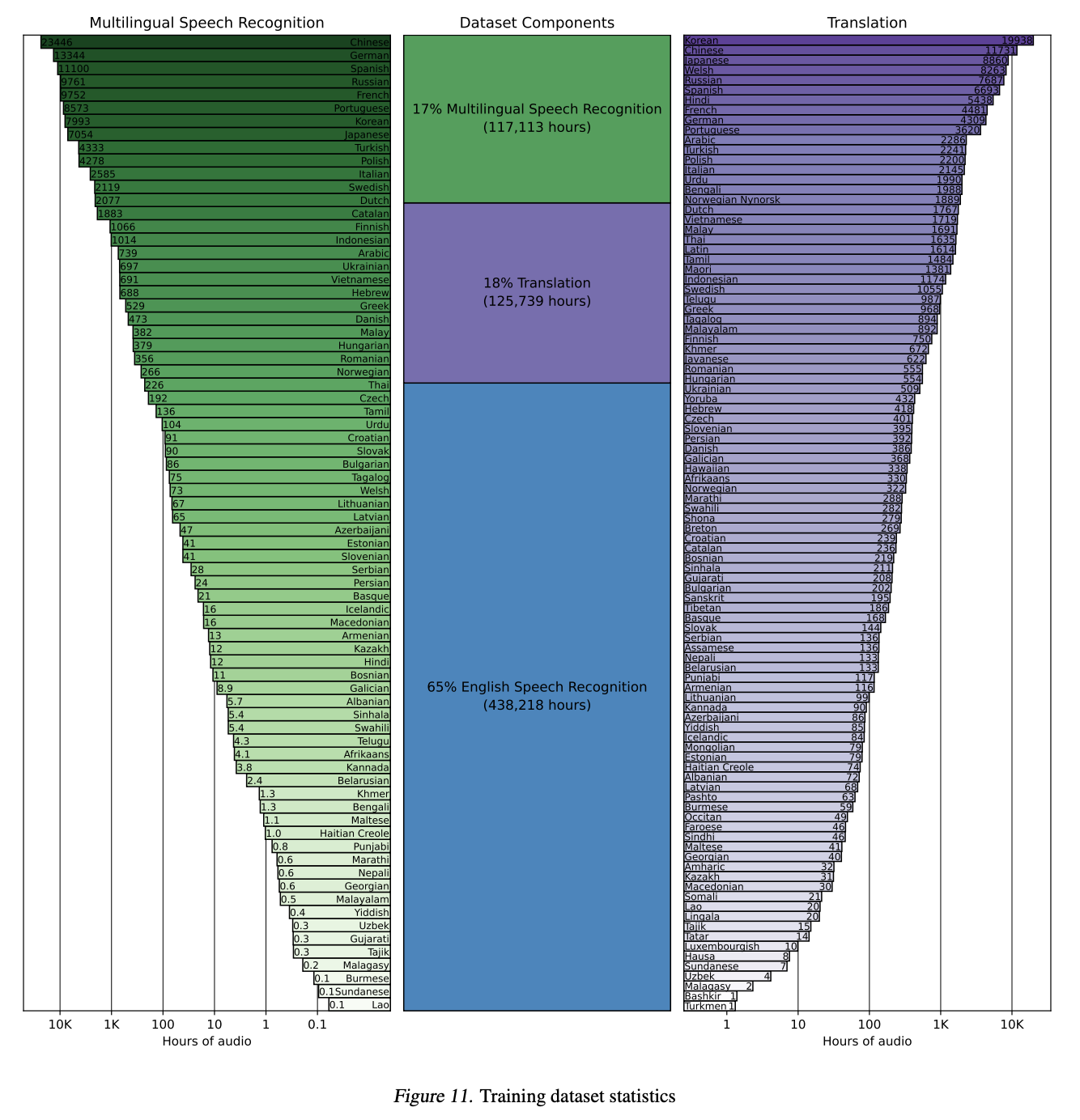
OpenAI가 공개한 Whisper의 논문을 보면, 다국어 모델의 데이터셋의 학습시간을 확인해볼 수 있음. 한국어의 인식 성능도 굉장히 좋은데, 한국어 학습 시간은 7993 시간이라고 함. (물론 영어는 전체 681,070 시간 중 65%를 학습시켰기때문에, 영어 인식률이 가장 높을 것임.)
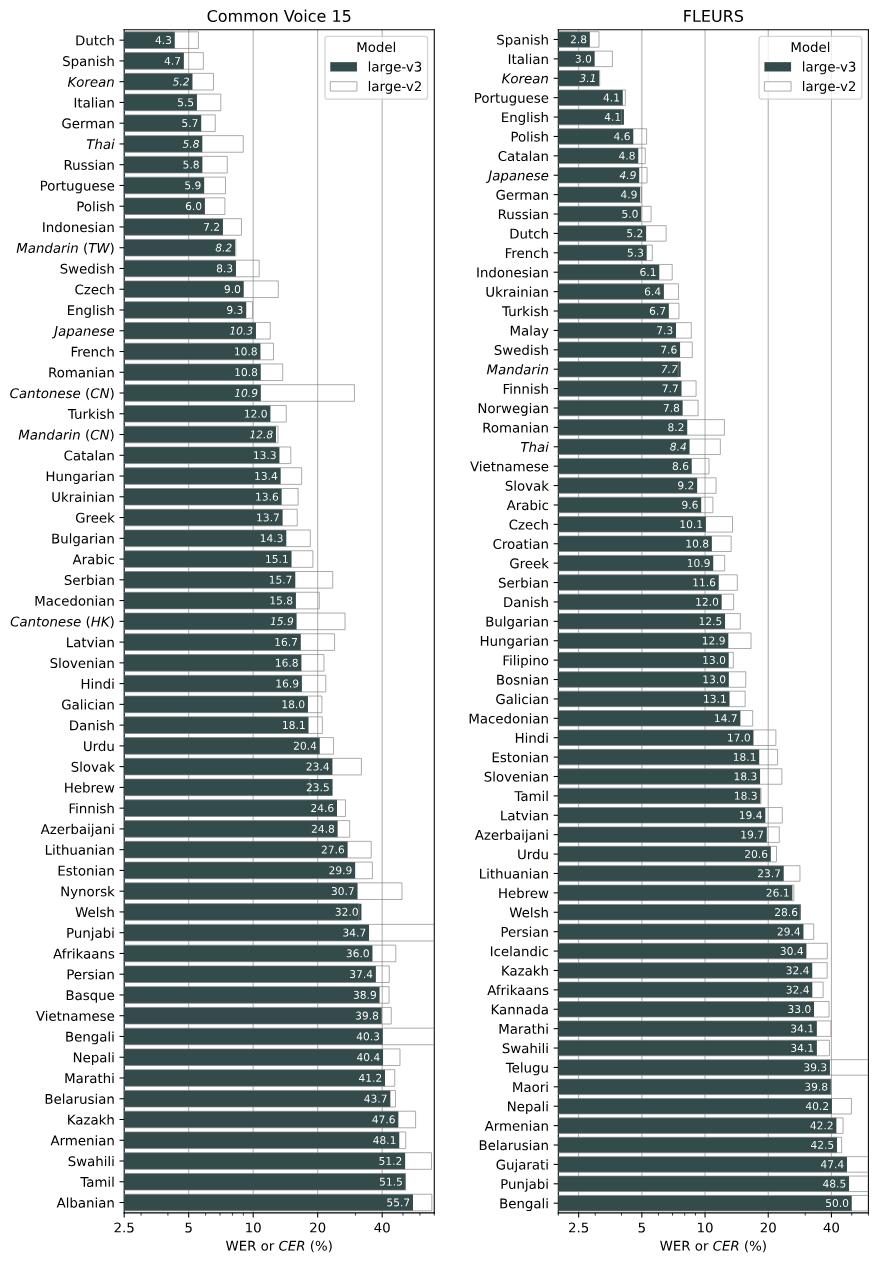
아래 Whisper performance를 보면, 한국어의 단어 오류는 굉장히 낮은 것을 확인할 수 있음. WERs는 word error rates, CER은 character error rates로 둘다 오류를 나타냄. 해당 성능표는 large-v3와 large-v2 모델을 사용해서 비교했음.
Whisper 모델 및 스펙
Whisper 사용 가능한 모델은 아래 표와 같음.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
(나는 2020 MacBook Air M1 메모리 8GB를 사용하는데, RAM때문에 large가 돌아가지 않는다. 일단 테스트용도로는 tiny 버전을 사용하고, 배포를 위해서는 GPU 서버에서 large를 사용할 예정임.)
Whisper GitHub Repository
Whisper 깃허브 리드미에 자세하게 사용방법과, 설치받아야할 라이브러리 등 설명이 잘 되어있음.
Python usage도 있는데, 이 중 DecodingOptions() 함수를 잘 알아야함.
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
@dataclass(frozen=True)
class DecodingOptions:
# whether to perform X->X "transcribe" or X->English "translate"
task: str = "transcribe"
# language that the audio is in; uses detected language if None
language: Optional[str] = None
# sampling-related options
temperature: float = 0.0
sample_len: Optional[int] = None # maximum number of tokens to sample
best_of: Optional[int] = None # number of independent sample trajectories, if t > 0
beam_size: Optional[int] = None # number of beams in beam search, if t == 0
patience: Optional[float] = None # patience in beam search (arxiv:2204.05424)
# "alpha" in Google NMT, or None for length norm, when ranking generations
# to select which to return among the beams or best-of-N samples
length_penalty: Optional[float] = None
# text or tokens to feed as the prompt or the prefix; for more info:
# https://github.com/openai/whisper/discussions/117#discussioncomment-3727051
prompt: Optional[Union[str, List[int]]] = None # for the previous context
prefix: Optional[Union[str, List[int]]] = None # to prefix the current context
# list of tokens ids (or comma-separated token ids) to suppress
# "-1" will suppress a set of symbols as defined in `tokenizer.non_speech_tokens()`
suppress_tokens: Optional[Union[str, Iterable[int]]] = "-1"
suppress_blank: bool = True # this will suppress blank outputs
# timestamp sampling options
without_timestamps: bool = False # use <|notimestamps|> to sample text tokens only
max_initial_timestamp: Optional[float] = 1.0
# implementation details
fp16: bool = True # use fp16 for most of the calculationdecoding.py 중 DecodingOptions 클래스를 보면, beam-size라는 변수가 보일 것임. 주석으로는 # number of beams in beam search, if t == 0라고 달려있지만 무슨 말인지 어려움.
쉽게 말해서 Whisper가 Inference하면 가장 높은 확률을 계산해서 토큰(결과값)을 출력해주는데, beam size를 3 혹은 5라고 설정하면, 확률 순으로 결과값을 출력해줌.
시장조사
-
IIElevenLabs
TTS 기능, STS 기능, voice cloning기능 등을 테스트해볼 수 있음.
-
facebook/seamless-streaming
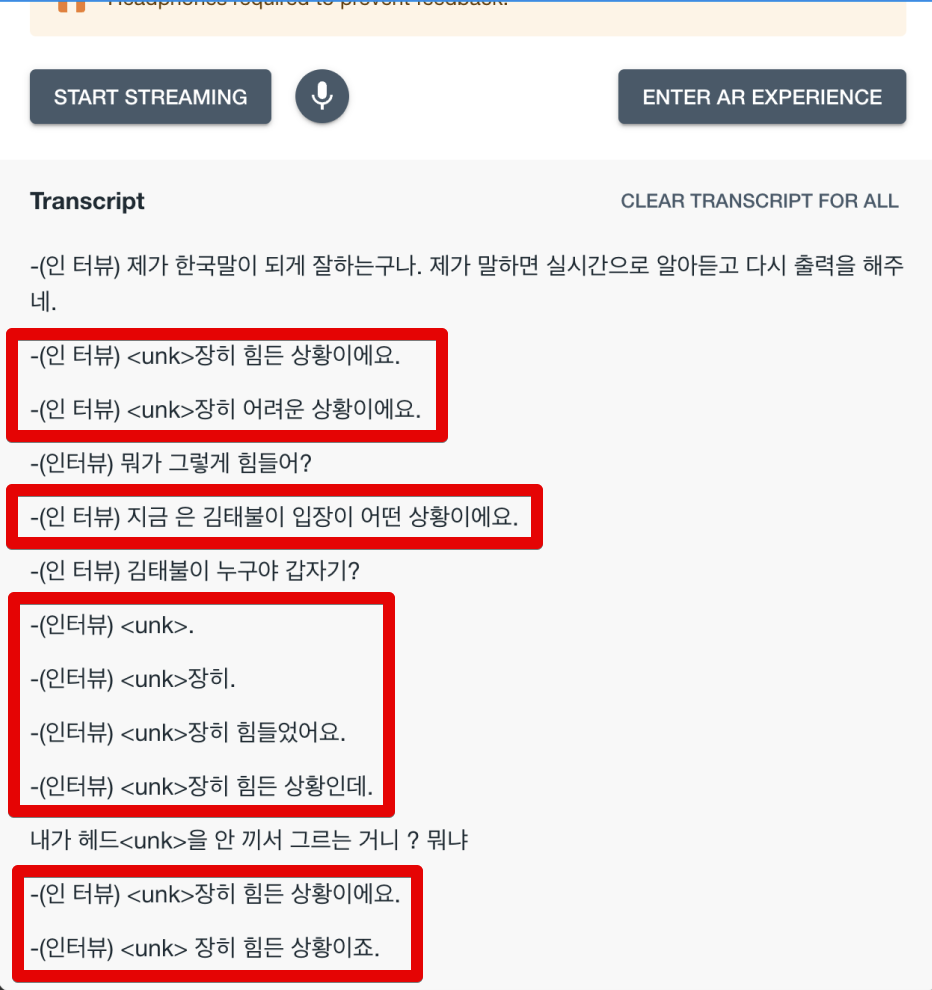
타겟 언어를 한국어로 설정했는데, hallucination이 심한듯하다. 에어팟을 안끼고 해서 그런가 싶어서, 타겟 언어를 영어로 바꿔서 다시 해봤다.
영어로 설정하면 성능이 훨씬 좋은 듯.
-
ufal/whisper_streaming
프라하 카렐 대학교와 NICT, 일본의 정보통신분야 국립 연구소에서 발간한 논문 "Turning Whisper into Real-Time Transcription System"에 따르면 Whisper는 실시간 전사를 위해 개발되지않았기때문에, 실시간적인 transcription을 위해서 Whisper-Streaming을 개발했다고 함. 아래 데모 영상을 보면 정말 실시간적으로 STT가 진행되는 모습임.
https://player.vimeo.com/video/840442741
로직도
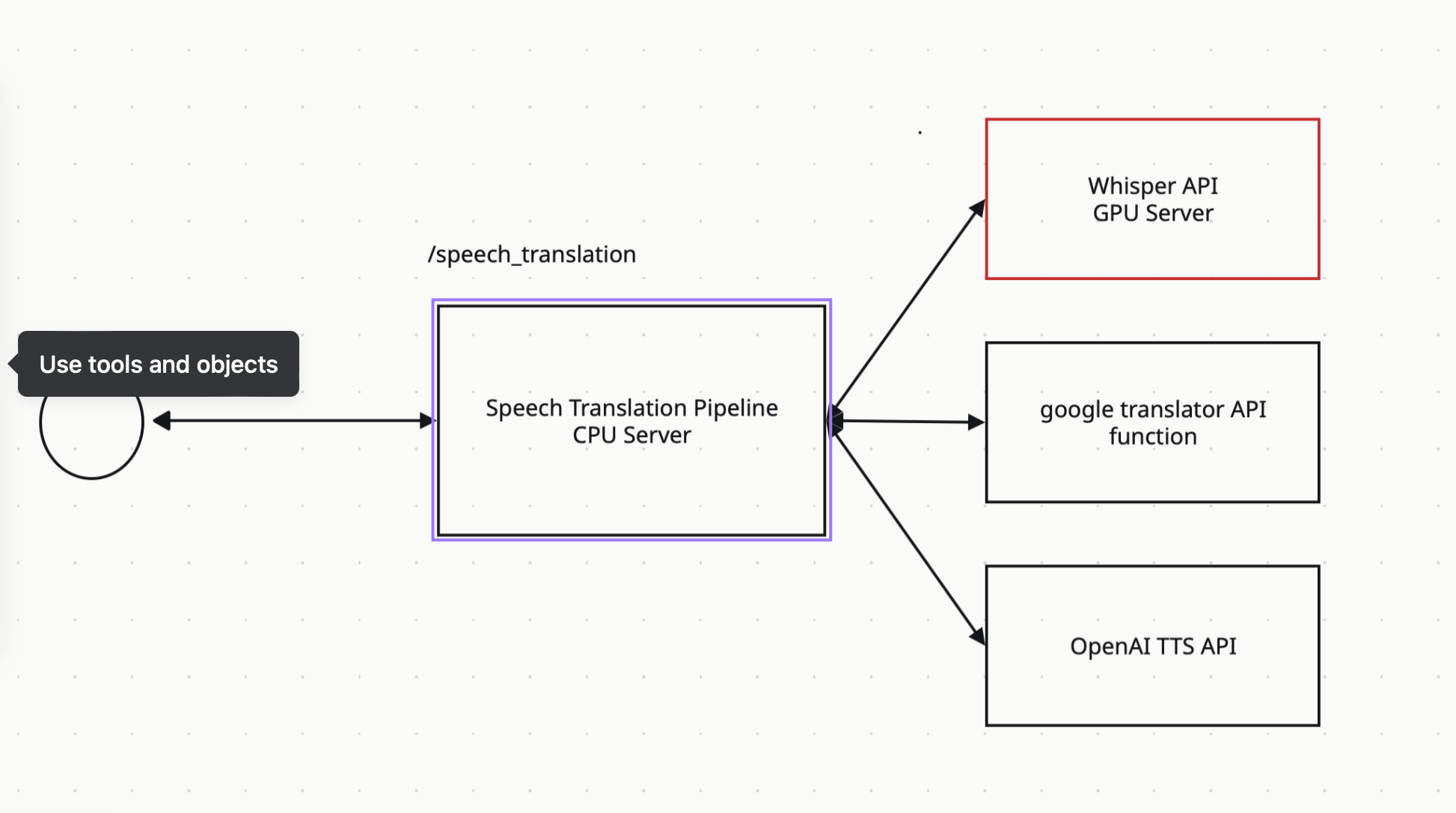
내가 맡은 파트를 수행하기 위해서 위 이미지와 같이 요청을 받으면 Whisper로 STT 작업을 하고, google translator로 번역하고, 이를 OpenAI TTS api로 다시 오디오로 출력할 계획임.
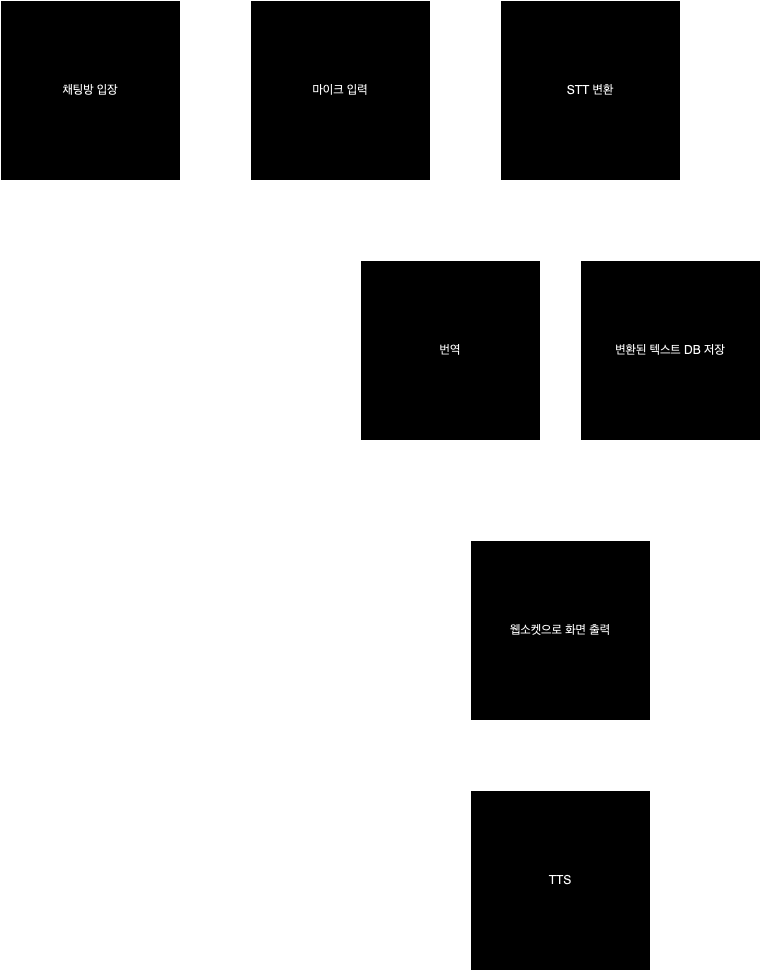
draw.io를 사용해서 간단하게 그려본 플로우다. (STT 처리한 데이터를 바로 화면에 웹소켓으로 보여줄지, client측에서 DB쿼리를 사용해서 보여줄 지는 실제로 해보면서 결정하려고 함.)
멘토님의 조언
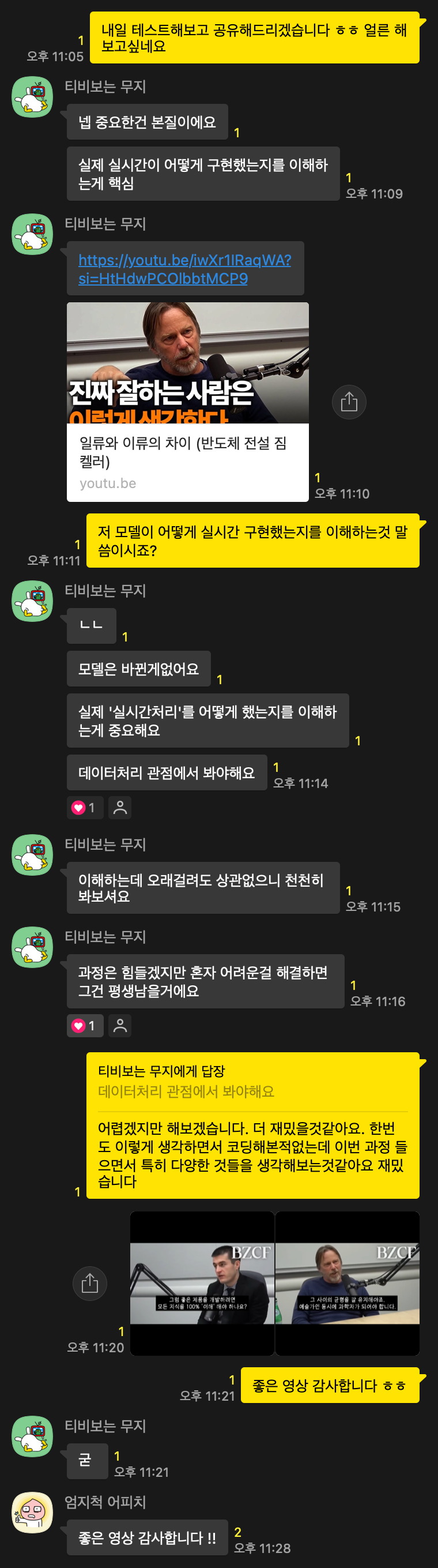
불과 한달 전 풀스택 개발자 6개월 과정을 듣고 이번 AIX 심화 과정을 듣고있다. 나한테 많은 변화가 생긴 것 같다. 이전엔 그저 수업내용을 따라가고, 새로운 문법을 배우는데에만 급급했던 나는 유튜브 영상 속의 좋은 '레시피'를 배우려고 하는 요리사와 같았다. 하지만 멘토님께서는 본질을 이해하는 것이 중요하다고 하신다.
"레시피에는 분명한 한계가 존재합니다. 최고의 빵 레시피를 알고있어도 오믈렛을 만드는 법은 알 수 없죠. 하지만 요리의 본질을 이해했다면, 빵, 오믈렛, 샌드위치...다양한 음식을 만들 수 있습니다."


유튜브 시청 강추 (https://www.youtube.com/watch?v=iwXr1IRaqWA)

STT에 대해서 자세한 설명 감사합니다^^ 제 블로그도 놀러오세요 제발