
Advanced Labeling
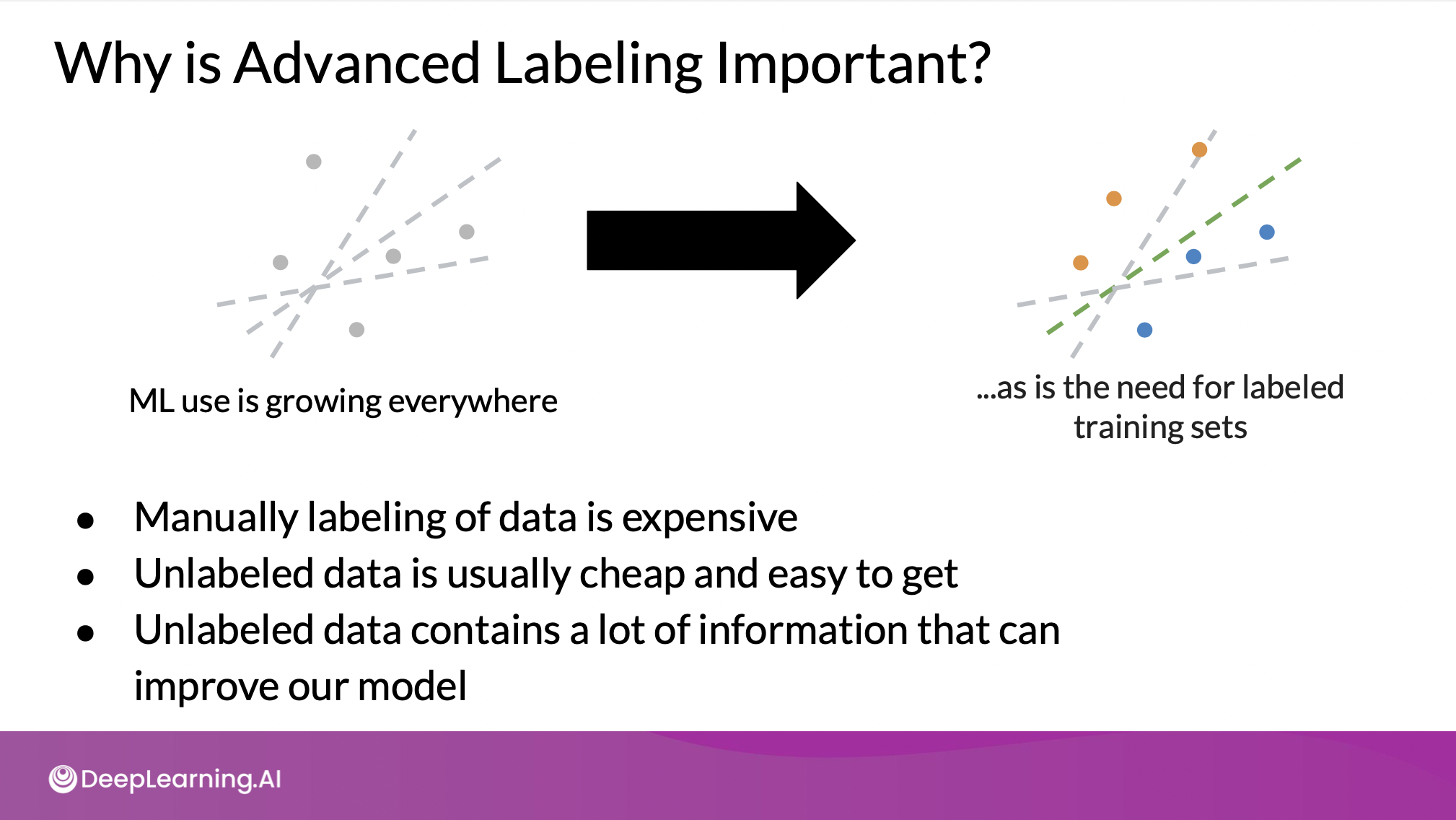
Semi-supervised Learning
사람이 라벨링한 데이터의 lable 클래스가 feature space에서 클러스터링되거나 구조화되는 방식을 통해 유추하여 라벨링되지 않은 데이터와 결합
Label propagation - 그래프 기반
데이터 포인트의 subset에 레이블이 있음

- 레이블이 있는 데이터와 없는 데이터의 유사성 또는 community 구조를 기반으로 레이블 할당
- 이 외에도 다양한 기술이 있음
Active Learning
데이터가 불균형한 경우, 학습 단게에서 rare class(가장 도움이 되는 레이블)를 선택하는데에 유용. 표준 샘플링 방식이 정확도를 향상시키는데 도움이 안되면 사용할 수 있음. semi-도 active learning에 포함된다고 볼 수 있음
모델 학습에 가장 도움이 되는 라벨링된 example을 선택해서 실행하는 것
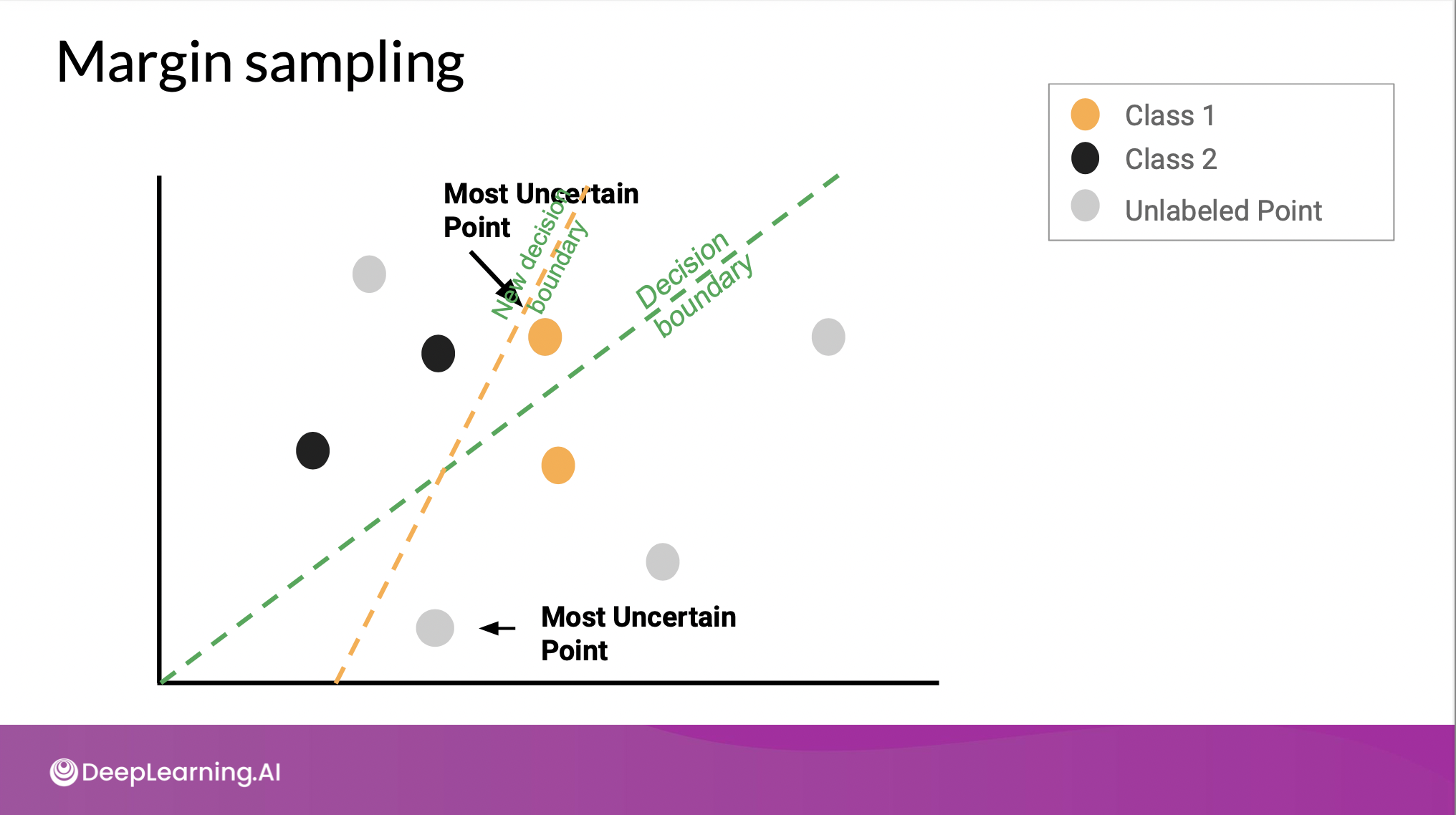
- Margin Sampling : 경계에서 가장 가까운, 가장 불확실한 점 선택 → 새로 경계 그리기 → 그 다음으로 가장 불확실한 점 선택 → ...
- Cluster-based sampling : feature space에서 다양한 클러스터링 방법을 사용해서 다양한 포인트 set 선택
- Query-by-committe : 여러 모델을 훈련하고, 그 중 불일키가 가장 높은 data point를 선택
- Region-based sampling : (new!) high level에서 input space를 구분되는 영역으로 나눠서, 그 영역들에서 active learning을 실행
Weak Supervision
하나 이상의 source의 정보를 이용해 레이블을 생성하는 방법
- subject matter experts
- 이런 경험적 방법론을 구성하는데에 가장 일반적으로 쓰임
- coverage set & coverage set의 true label 확률 기대값(noise 있다? = correct일 확률이 있다)
- 라벨링을 자동화할 수 있는 heuristics의 목록(??)
- 결과 label은 우리가 아는 deterministic label보다 노이즈가 있음
- 레이블이 지정되지 않은 데이터에 대해 하나 이상의 noisy 조건부 분포로 구성
noisy source 각각의 관계성을 결정하기 위해, 각 supervision source의 신뢰성을 생성모델 학습을 통해 learn
방법
1) true label을 모르는 unlabeled data로 시작
2) weak supervision source를 몇 개 섞어 넣음
*노이즈가 있고 불완전한 자동화 라벨링을 적용하는 경험적인 방법들(???)
Snorkel 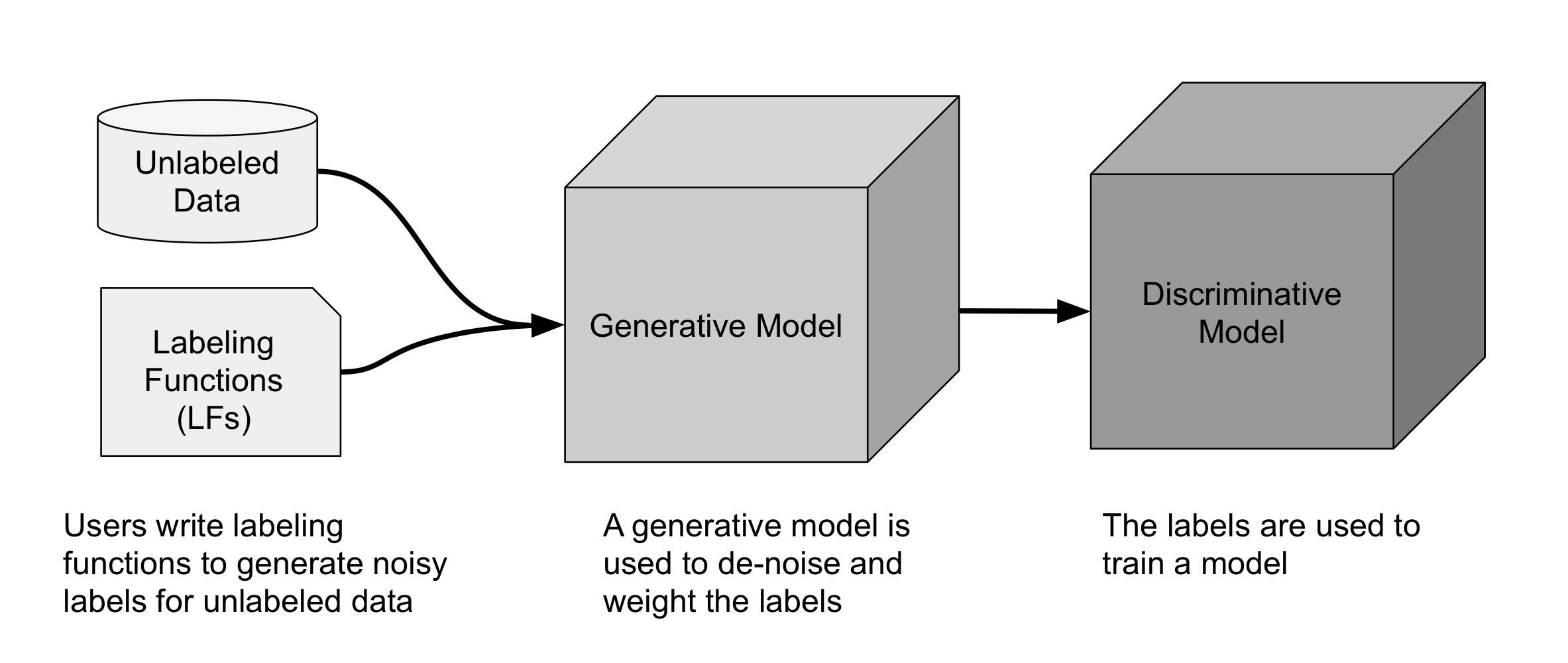
- 라벨링 안된 데이터 + 라벨링 functions = noise가 많은 라벨 생성
- 생성모델로 de-noise & 중요도를 가중치로 다른 labeling function에 부여
- de-noise된 라벨이 있는 discriminative model을 훈련
Data Augmentation
기존 데이터를 약갼 변형해서 많은 데이터를 생성, 모델의 성능을 개선하고 real example에 없는 새로운 valid example을 만들어내서 feature space의 coverage를 개선하는 것.
- 하지만 잘못된 답을 배우거나 원치 않았던 노이즈가 발생할 수 있음
- 과적합을 줄이고 모델의 일반화 능력을 높일 수 있음!
# ex
def augment(x, height, width, num_channels):
x = tf.image.resize_with_crop_or_pad(x, height + 8, width + 8)
x = tf.image.random_crop(x, [height, width, num_channels])
x = tf.image.random_flip_left_right(x)
return x다른 고급 기술
- 비지도 데이터 증강 ex. UDA, GAN을 이용한 semi-supervised learning
- 정책 기반 데이터 증강 ex. AutoAugment
Preprocessing Different Data Types
Time series data
이벤트가 발생한 시간을 기록한 data point의 나열
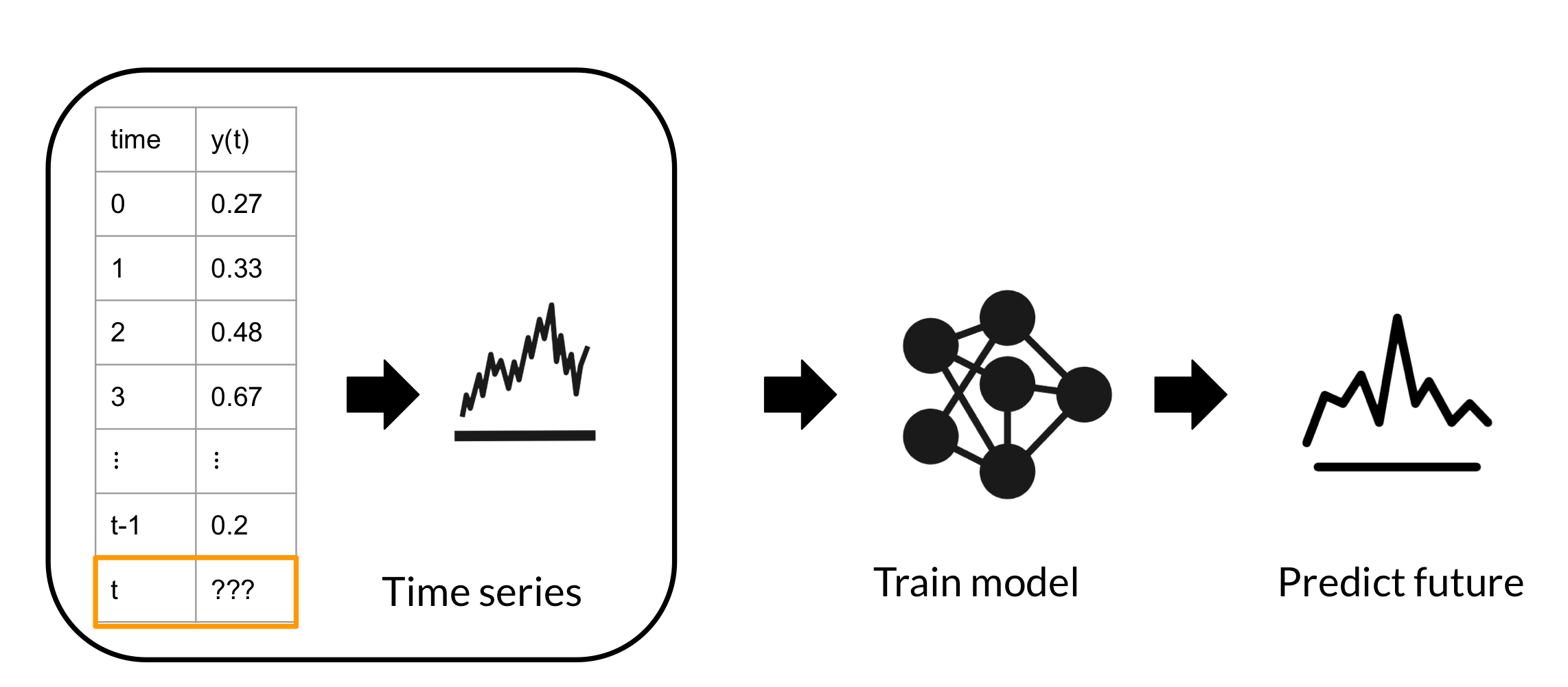
- 과거의 데이터를 이용하여 정확히 미래를 예측하고자 함
- 데이터의 주기성과 계절성을 플롯으로 확인
윈도우 전략
ex. 6시간 과거 데이터로 1시간을 예측하려는 모델의 window
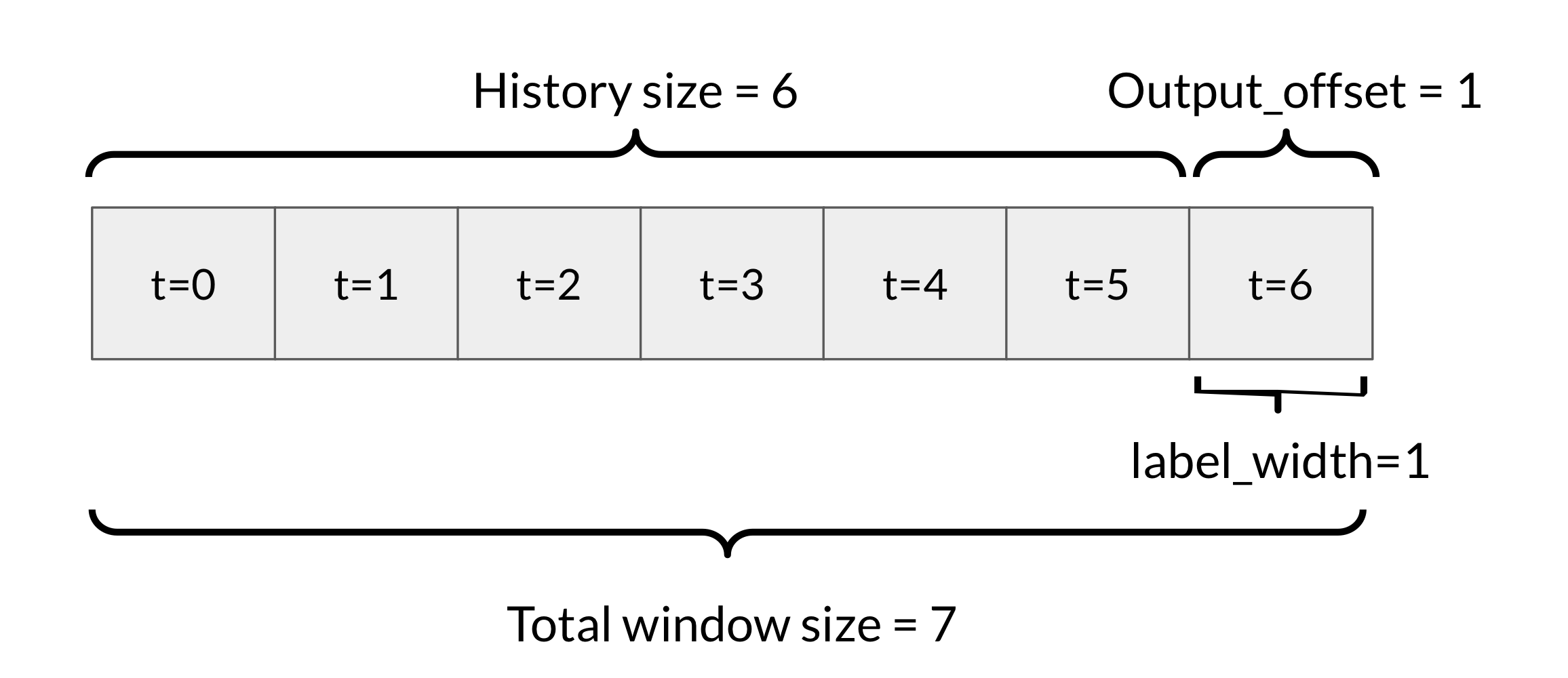
- Sampling
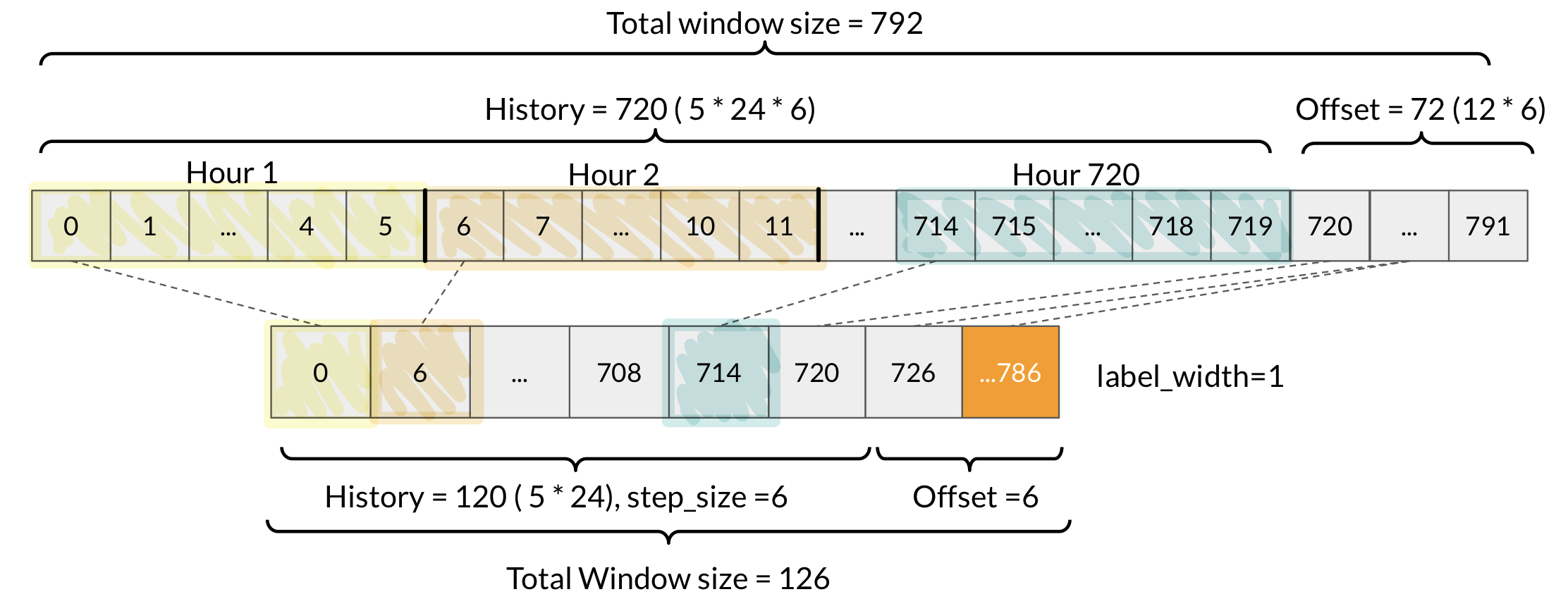
- 1시간에 6번씩 기록 but 큰 차이 없다? 한 시간에 1개씩만 대표적으로 뽑아서 진행
Sensors & Signals
Signal : 센서에 의해 수집된 실시간 데이터(timestamp) "시계열 데이터"
ex. accelerometer data - 스마트폰(센서)으로부터 수집된 사람 움직이는 시그널
Human Activity Recognition (HAR)
사람의 활동을 제대로 인식하기 위해서는 센서 데이터를 적절하게 segmentation해야 함(윈도우 전략과 비슷)
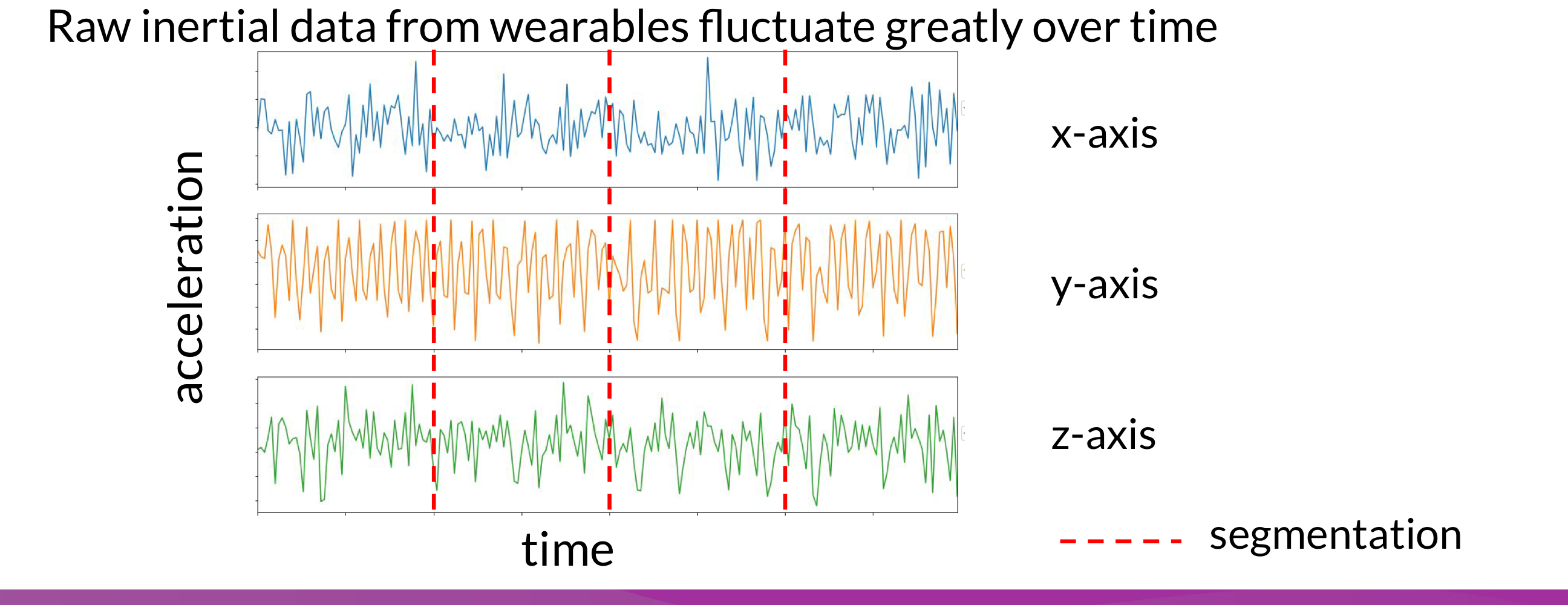
1. 분할
- segment를 기반으로 feature extraction, classification, validation 등이 이루어짐
- 길이는 context와 sampling rate에 따라 바뀌지만 주로 1~10초
- 변환
- 모델링을 위해 변환이 필요함
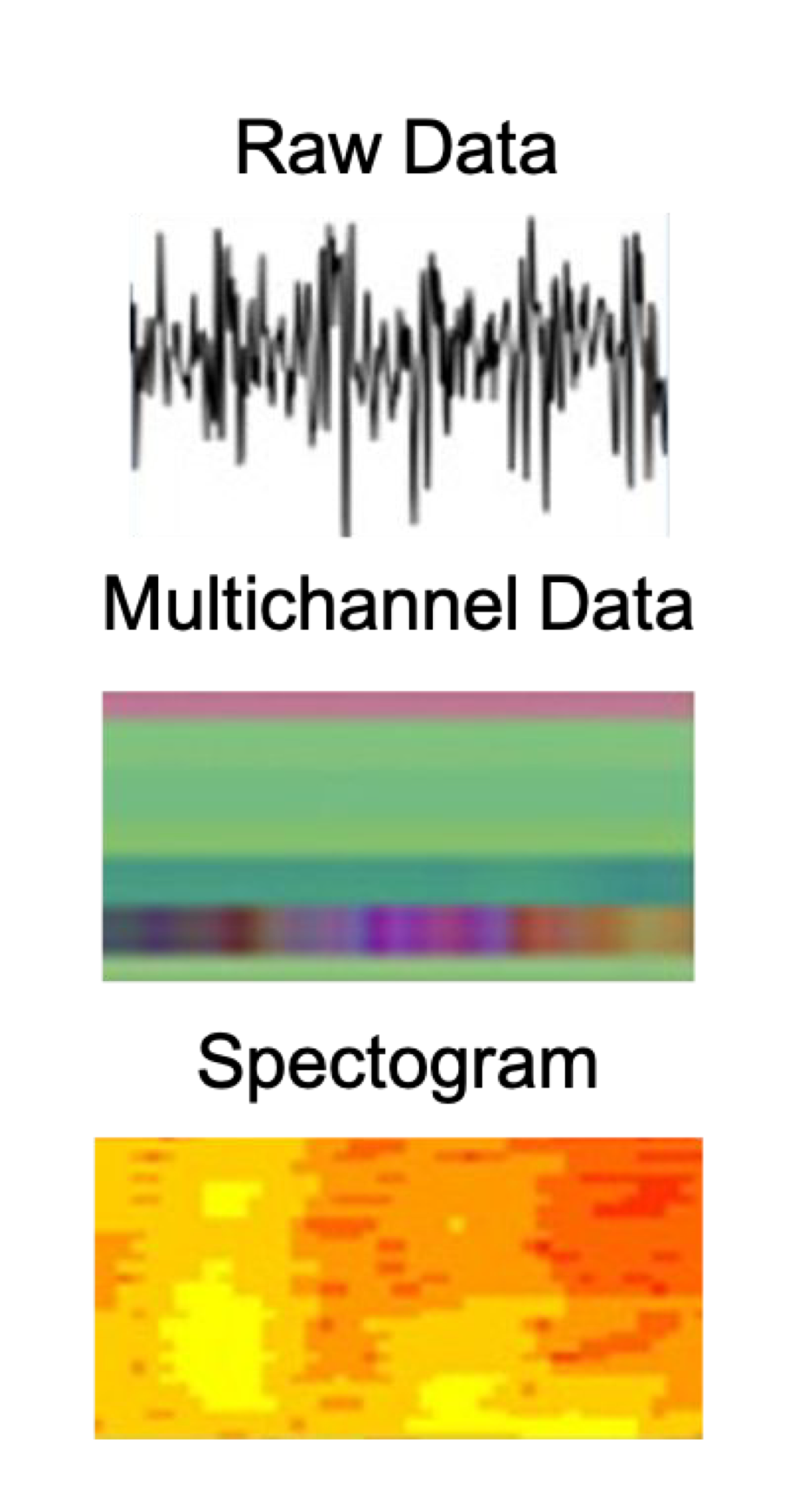
- Spectrograms : 신호를 주파수 & 시간 함수로 표현한 것. intertial data points 사이의 강도 차이를 잘 나타냄.
- 정규화 & 인코딩, Multichannel, Fourier 변환 등
