Hyperparameter tuning
Hyperparameter tuning은 Neural Architecture Search와 많은 유사점이 있음
Neural Architecture Search(NAS)?
- 신경망 설계를 자동화하는 기술
- 이를 통해 최적의 아키텍쳐를 찾는 것이 목표
- AutoML을 사용해서 huge space에 대한 검색을 자동화할 수 있음
Parameters
1) 학습 가능한 model parameters
- 모델이 training을 통해 학습하는 변수
- ex. 가중치, 편향 등
2) Hyperparameters
- 모델의 좋은 성능을 위해 training 전에 이미 조정되어 있어야 하는 변수
- training 과정에서 최적화되지 않음
- 작은 모델에서도 큰 영향을 줄 수 있음.
- ex. learning rate, 활성화 함수, 가중치 초기화 등
Keras Autotuner Demo
import tensorflow as tf
from tensorflow import keras
# ...(중략)...
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
# 왜 Dense는 512이고, Dropout는 0.2 인가? 찾아봅시다
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)def model_builder(hp):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# 16 부터 512까지 16 step으로 돌면서 최적 찾아보기
# 이거로 대체함 - tuned by Keras tuner
hp_units = hp.Int('units', min_value=16, max_value=512, step=16)
model.add(keras.layers.Dense(units=hp_units, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(10))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model# Hypterband 전략을 사용해서 parameter 선택
# 다른 전략 : RandomSearch, BaysianOptimization, Sklearn
tuner = kt.Hyperband(model_builder,
max_epochs=10,
objective='val_accuracy',
factor=3,
directory='my_dir',
project_name='intro_to_kt')
# early stopping
stop_early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
tuner.search(x_train,
y_train,
epochs=50,
validation_split=0.2,
callbacks = [stop_early])
- Search output
- Dense를 48로 고치면 더 좋은 결과!
Trial 24 Complete [00h 00m 22s]
val_accuracy: 0.3265833258628845
Best val_accuracy So Far: 0.5167499780654907
Total elapsed time: 00h 05m 05s
Search: Running Trial #25
Hyperparameter |Value |Best Value So Far
units |192 |48
tuner/epochs |10 |2
tuner/initial_e...|4 |0
tuner/bracket |1 |2
tuner/round |1 |0
tuner/trial_id |a2edc917bda476c...|NoneAutoML
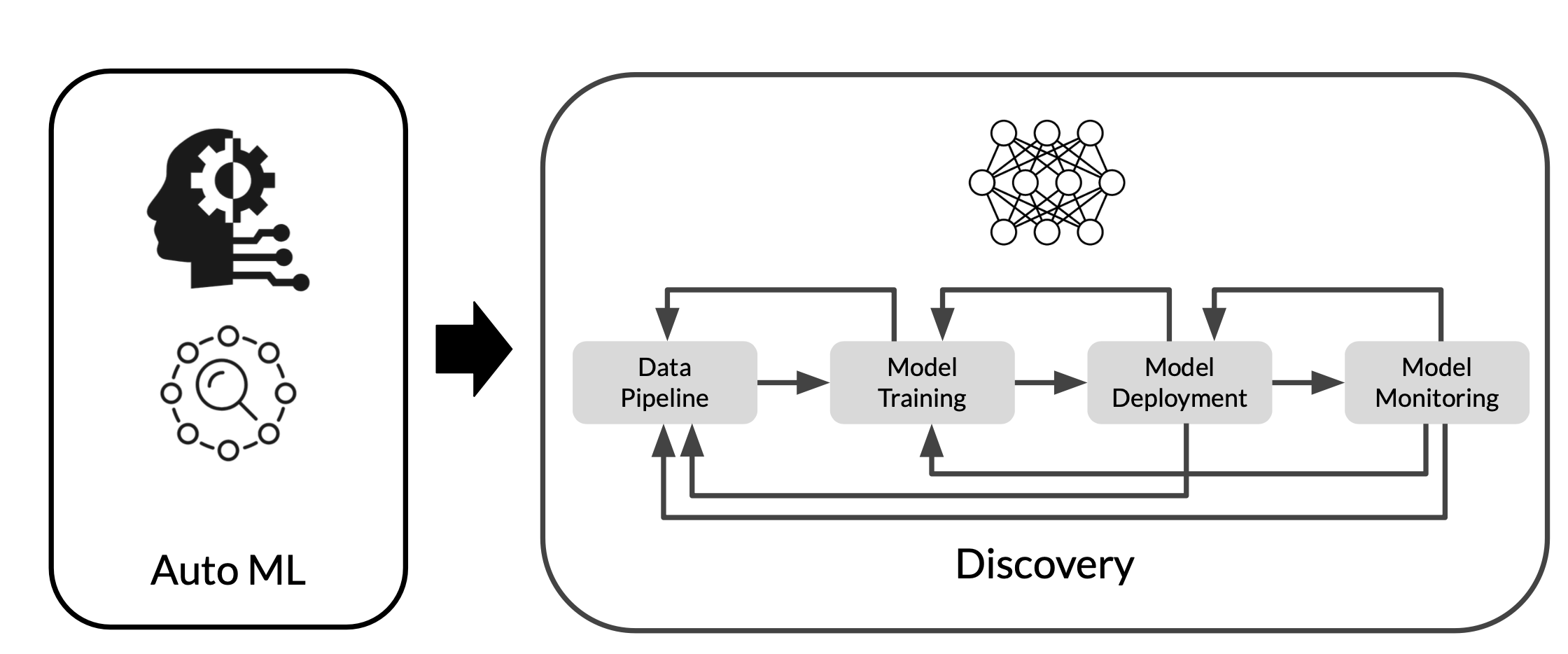
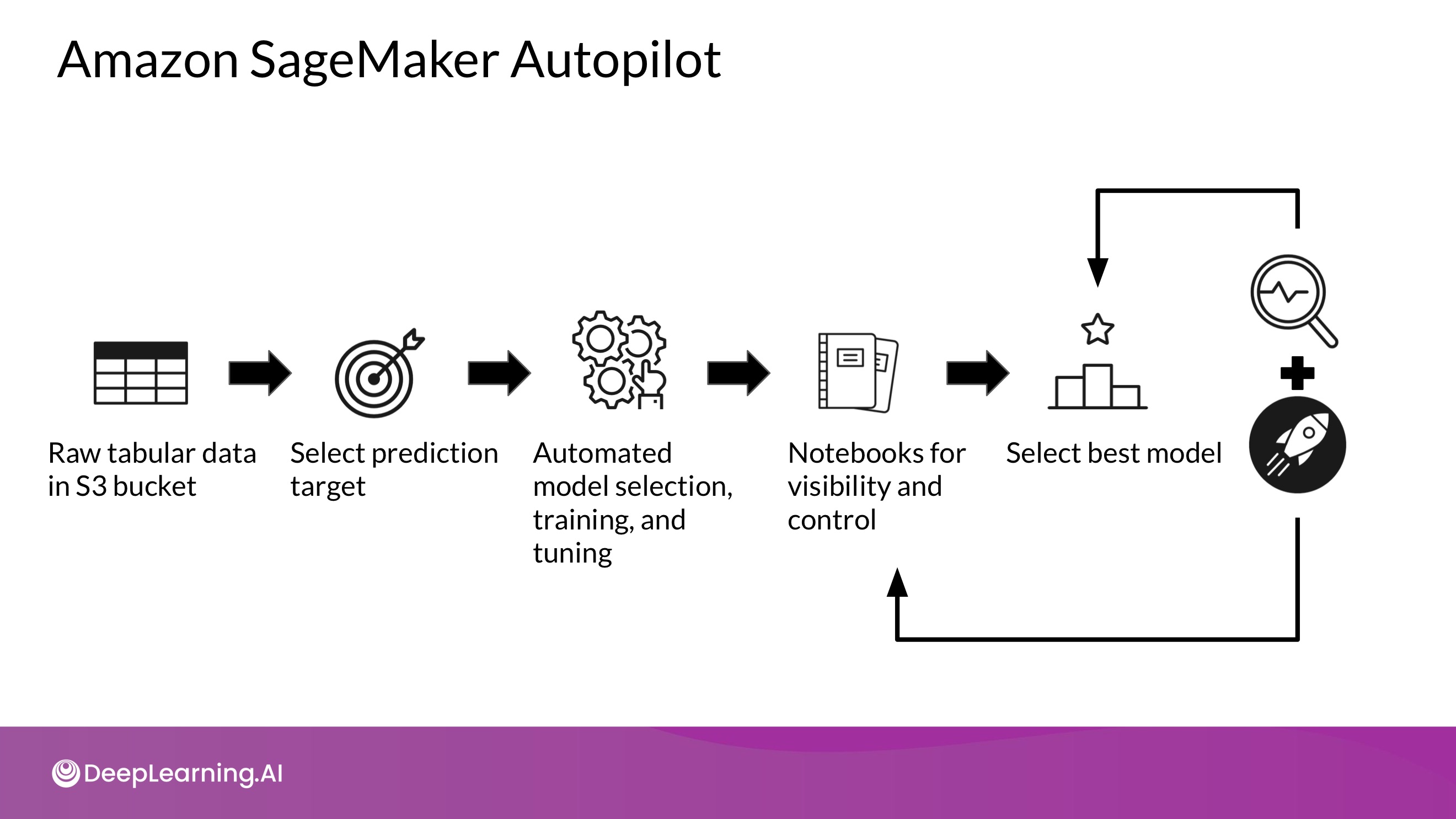
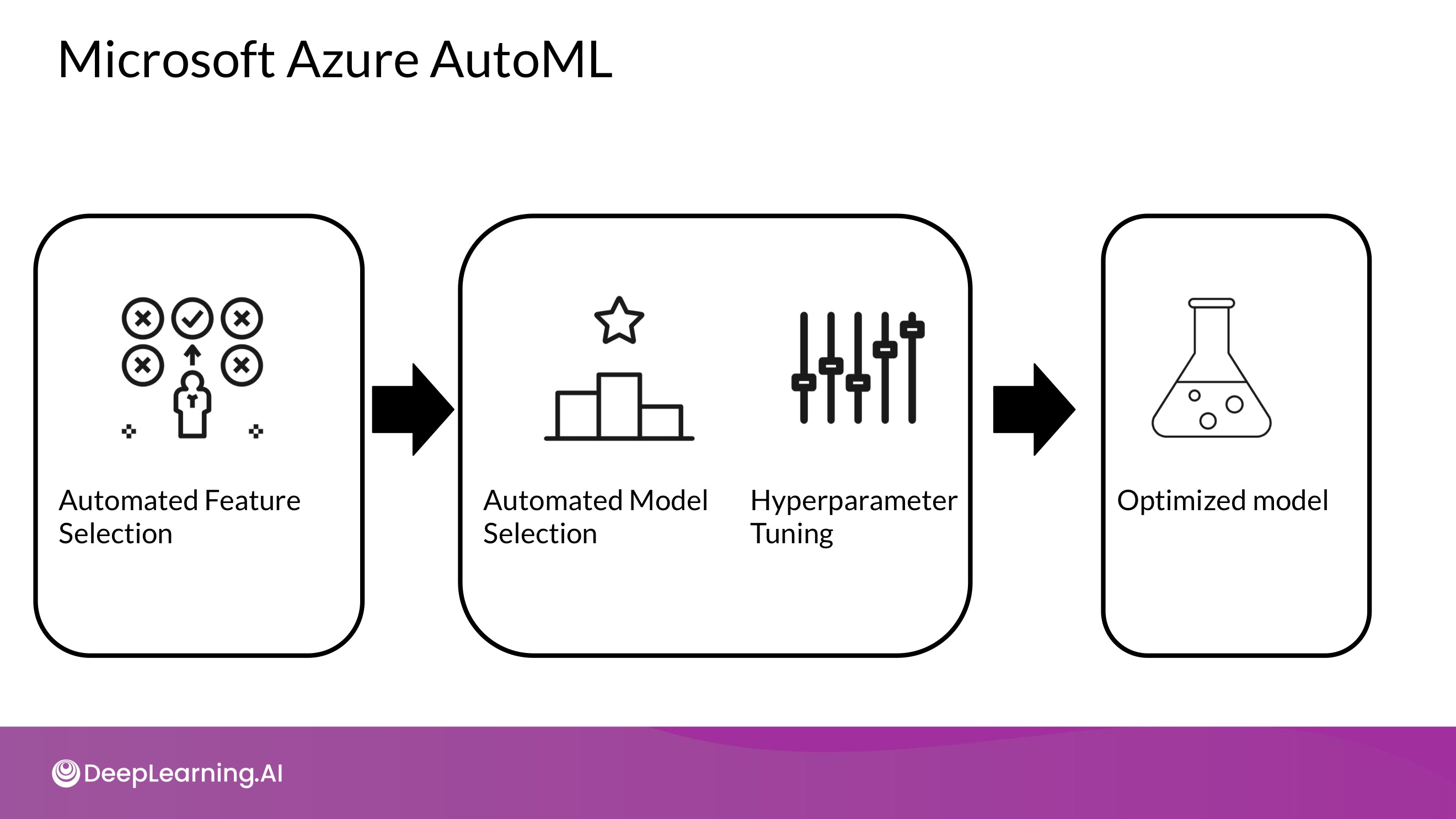
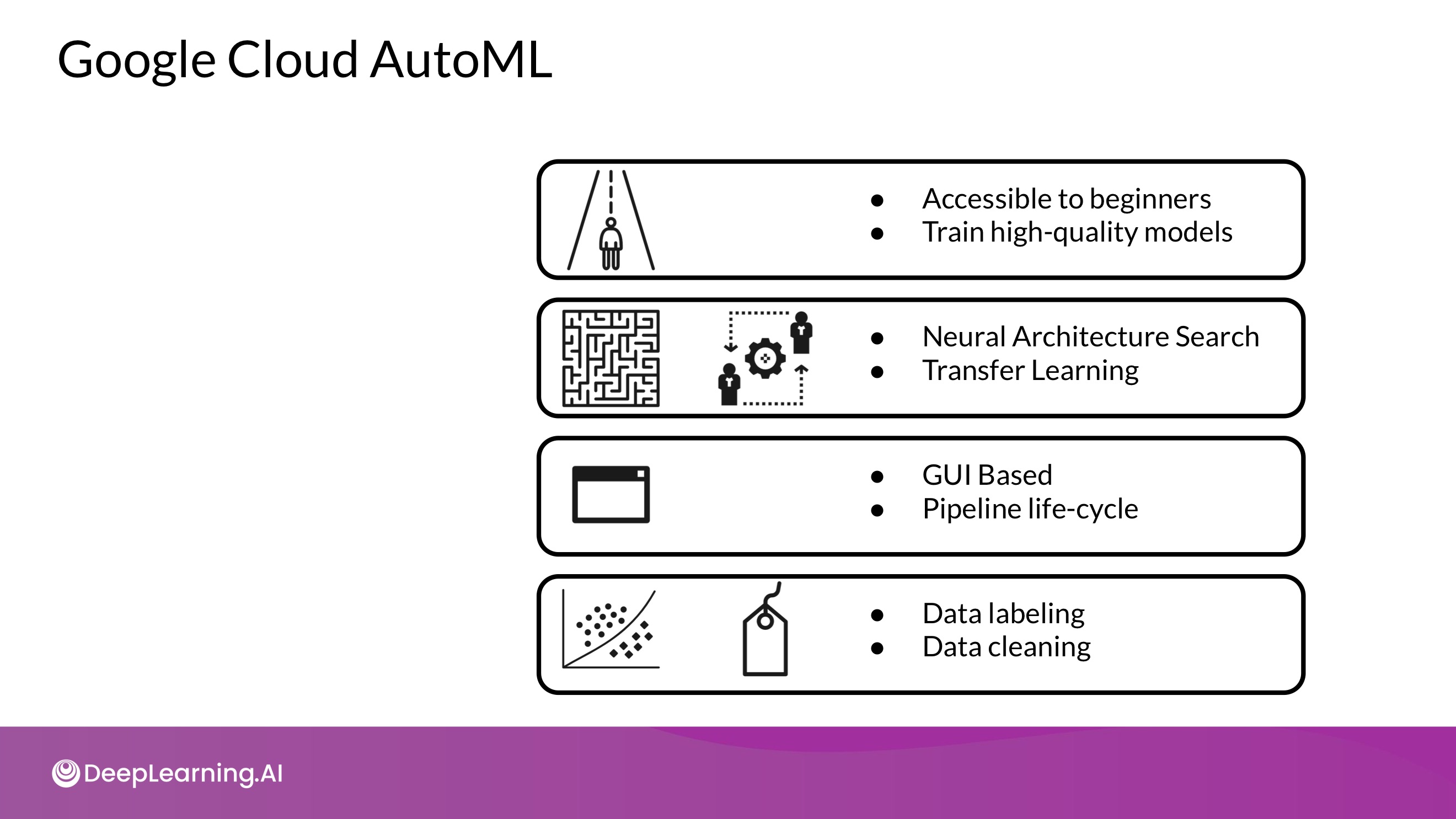
- 머신러닝 프로세스를 End-to-End로 자동화 하는 것이 목적. 기계학습을 잘 몰라도 좋은 성능을 낼 수 있도록!
- 데이터 수집부터 모델 검증까지 전체 ML Workflow를 자동화하는 것이 목표
- 특정 모델에 국한되는 것이 아님.
- Neural Architecture Search (NAS)는 AutoML의 핵심이자 ANN 설계를 자동화하는 기술
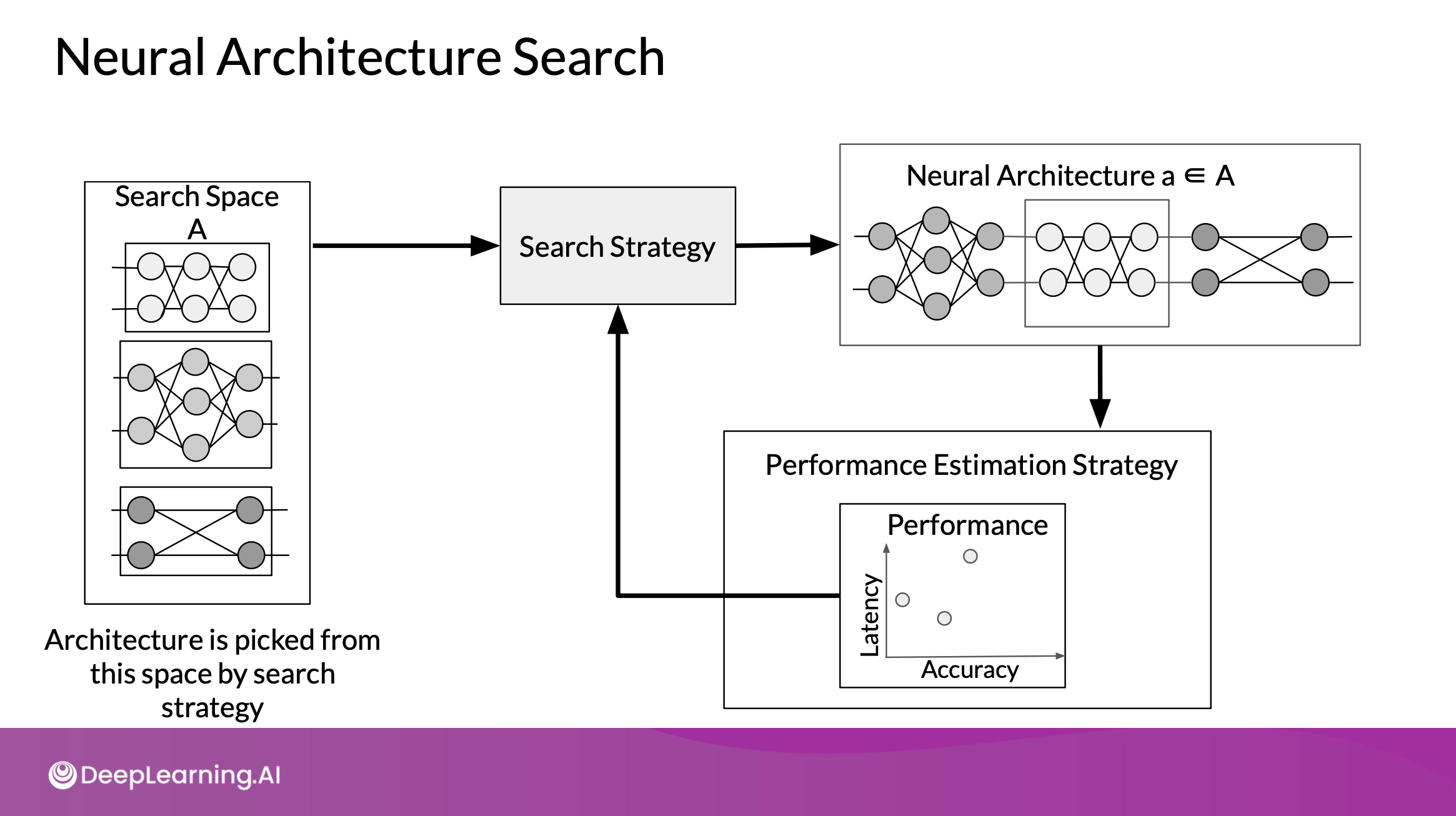
- Search Space
모델링에 가장 적합한 space로 아키텍쳐의 범위 정의. 하지만 사람의 생각이 들어가서 더 좋은 걸 찾지 못할 수도 있음 - Search Strategy
정의한 search space를 검색 & 아키텍쳐 선택. 빨리 검색하면 좋지만, 너무 빠르면 sub optimal region으로 수렴할 수도 있음 - Performance Estimation Strategy
다양한 아키텍쳐 성능 측정 & 비교
- Search Space
Search Space
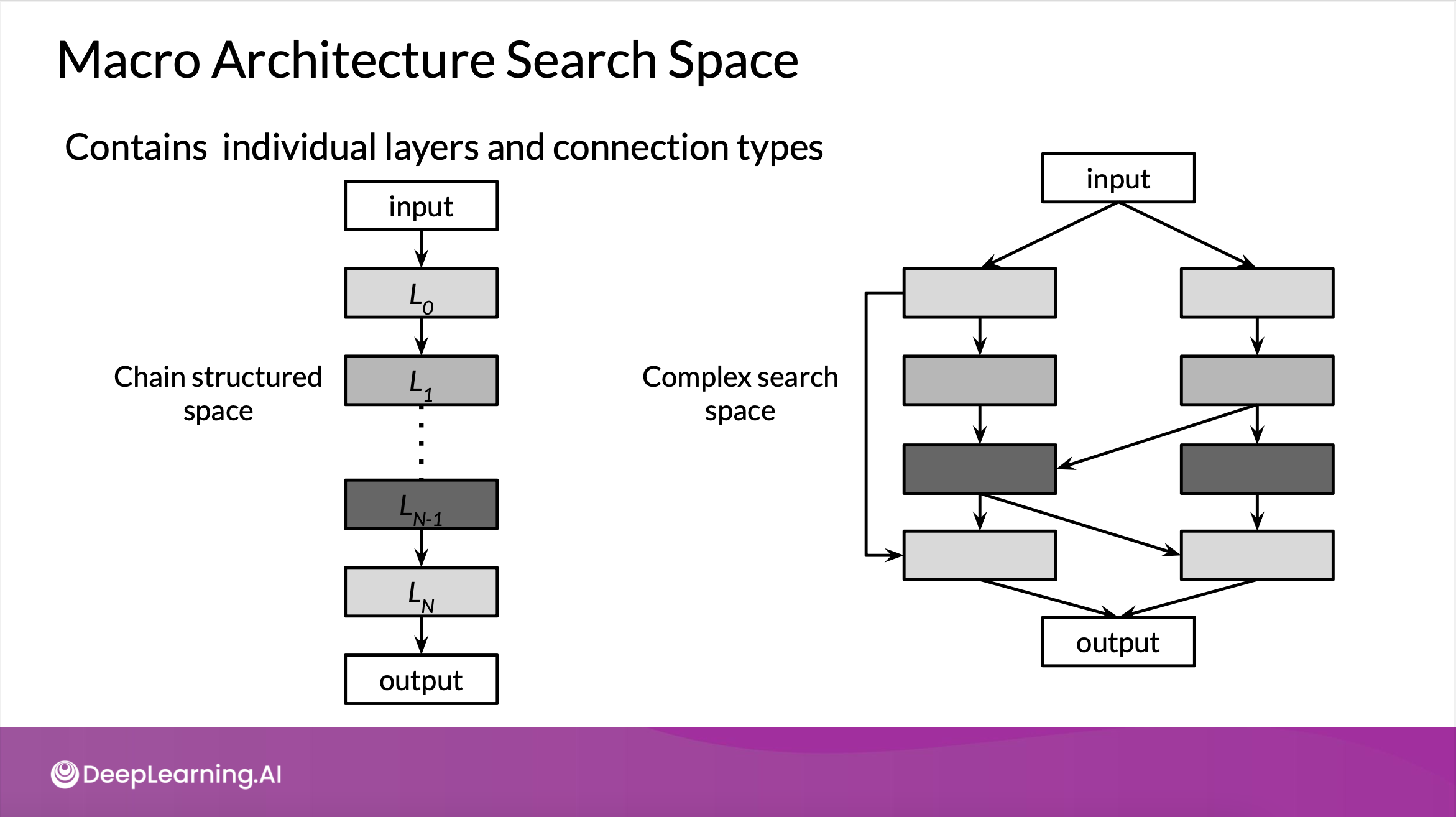
1) Macro
- 신경망 layer를 겹겹이 쌓거나
- multiple branches와 skip connection을 통해
- 간단하게 최고의 모델을 레이어별로 쌓는 것
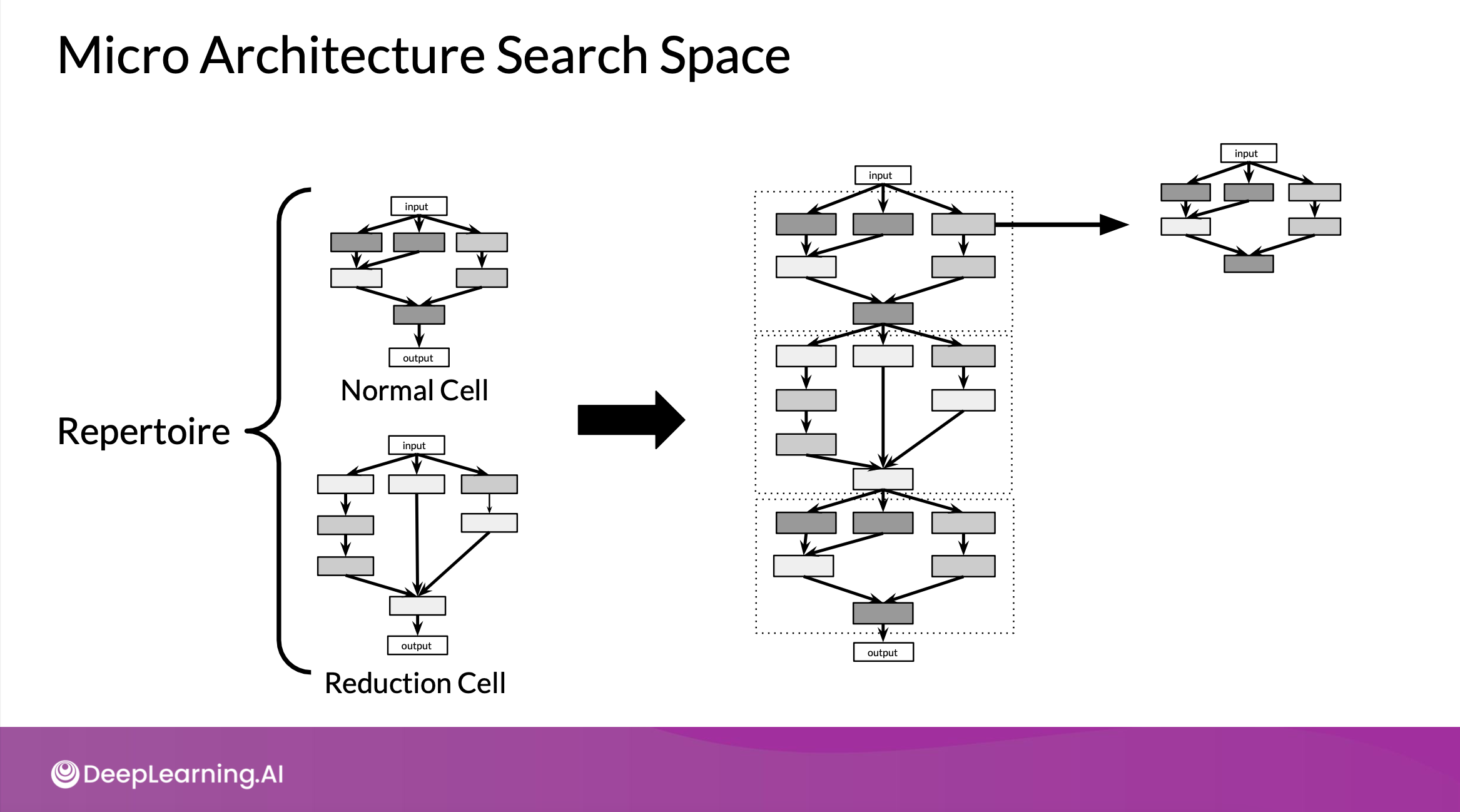
2) Micro
- 각각 더 작은 네크워크인 normal cell과 reduction cell로 신경망을 구축
- 최종 network를 만들어내기 위해 쌓일 수 있음
- layer를 cell로 바꾸면서, 더 복잡하게 결합할 수 있음
Search Strategy
- 가장 좋은 성능을 보여주는 아키텍쳐를 검색
- ex. Grid Search, Random Search, Bayesian Optimization, Evolutionary Algorithms, Reinforcement Learning
1) Grid Search & Random Search
- Grid : 모든 가능성을 찾아봄
- Random : search space에서 다음 옵션을 random하게 선택함
- 작은 search space에 적합, search space가 어느 정도 이상 커지면 의미가 없음
2) Bayesian Optimization
- 가우시안 분포가 전제되어 있다고 가정
- 이 확률분포로 제한하고 다음 옵션을 선택하게 함
- In this way, promising architectures can be stochastically determined & tested (?????)
3) Evolutionary Methods
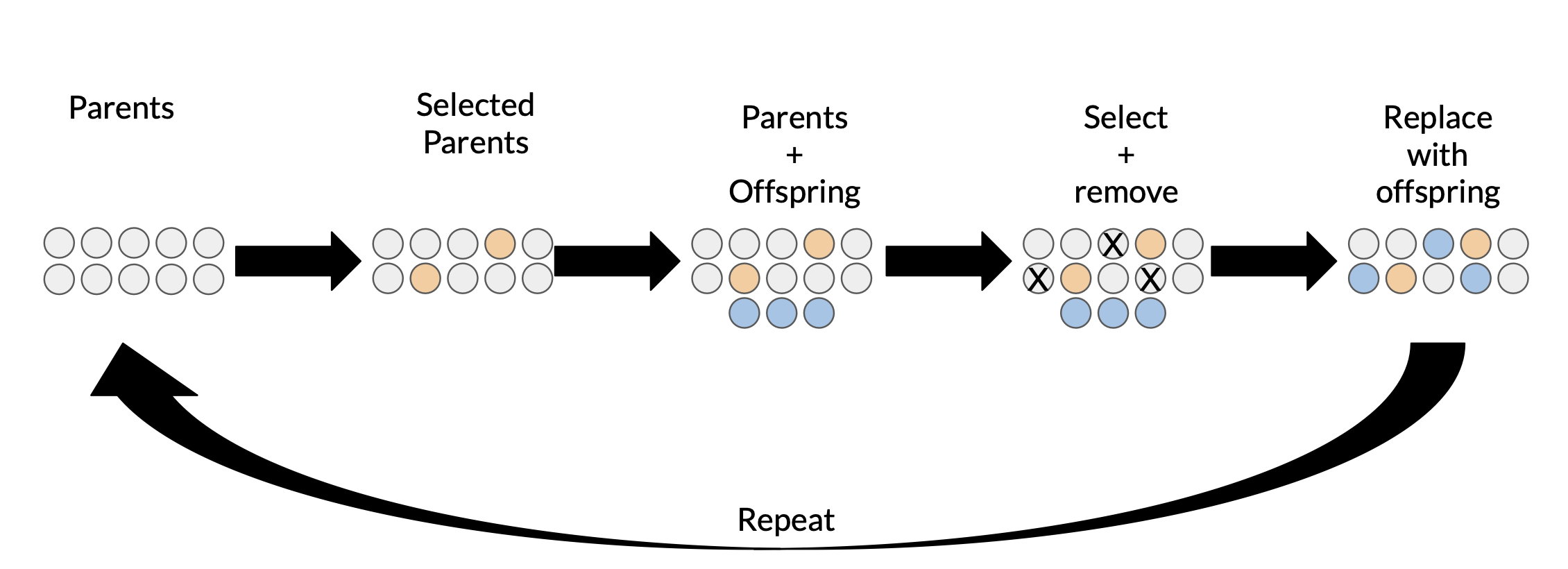 n개의 - 서로 다른 모델 아키텍쳐가 랜덤하게 생성
n개의 - 서로 다른 모델 아키텍쳐가 랜덤하게 생성
- X개의 가장 높은 성능을 낸 모델이 selected parent
- Offspring = 각 parent의 복사/변형/조합
- 성능 평가 전략(adding/removing layer or connection, layer 사이즈 변경, 하이퍼 파라미터 변경 등) 사용
- Y개의 가장 성능이 안좋거나 오래된 모델, 혹은 파라미터 조정으로 선택
- 제거된 모델을 offspring으로 대체해서 새로운 모집단으로 사용
4) 강화학습
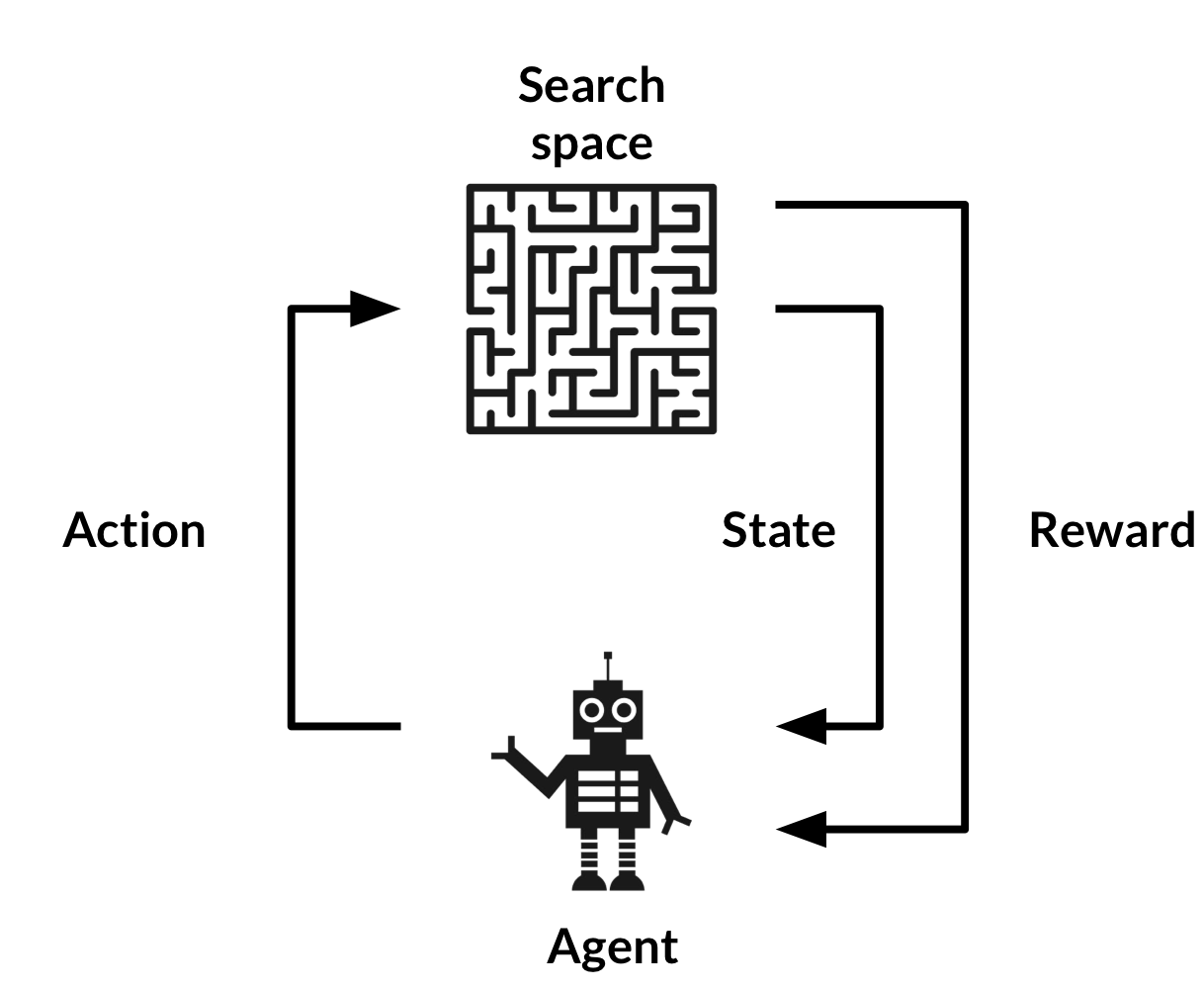
- 보상 최대화를 위한 action
- 각 action 후, agent의 상태와 환경이 업데이트 & performance metric에 따라 보상 발생
- 다음 action이 가능한 범위 결정. 환경 = search space, 보상함수 = 성능 평가 전략

Performance Estimation Strategy 성능 평가 전략
각 아키텍쳐의 validation accuracy를 측정하는 것이 가장 간단. 하지만 너무 costly함
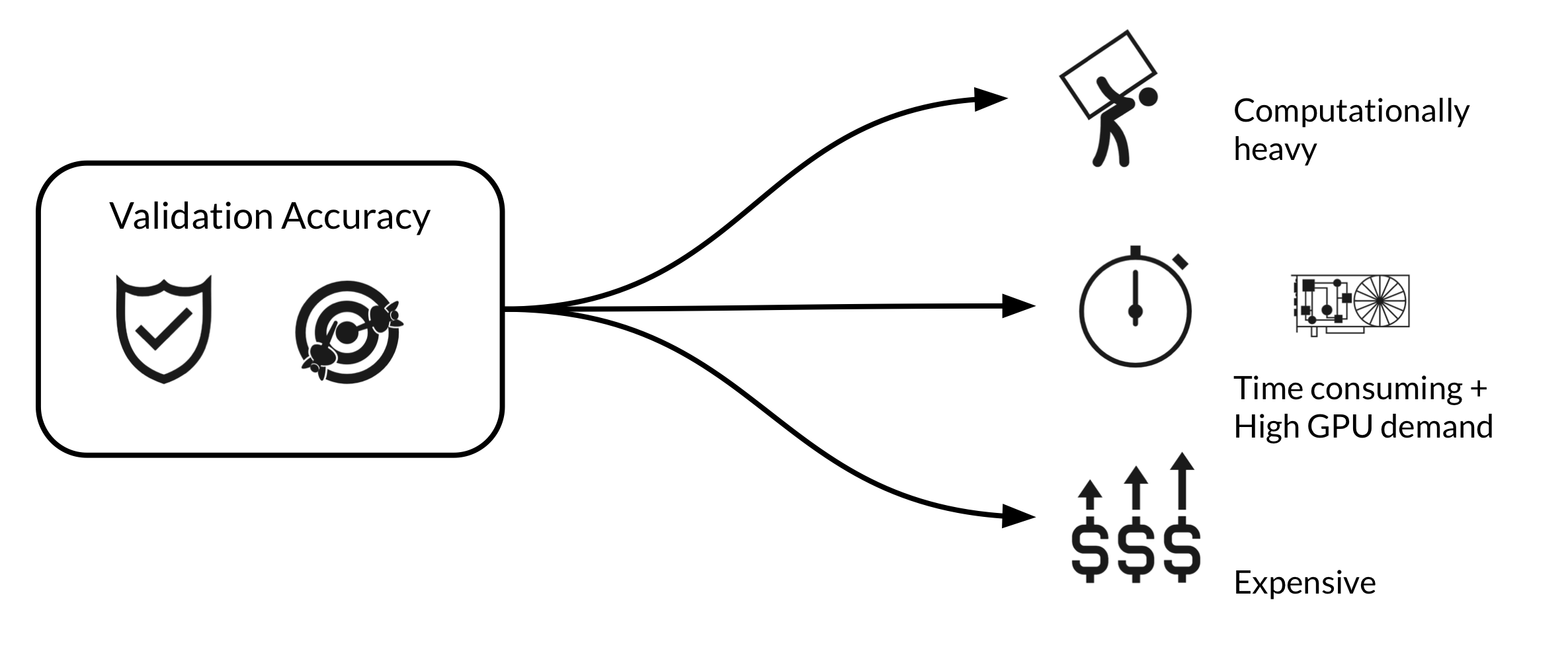
➡️ cost를 줄이는 방법
1) 낮은 fidelity(정확도?) estimate
- 데이터의 subset에 대해 학습하거나, 낮은 해상도의 이미지 사용, 필터/cell을 적게 사용하여 훈련 시간을 줄임
- 하지만 성능이 과소평가 & 아키텍쳐의 상대적인 순위가 변경됨
= ㅂㄹ다..
2) 학습 곡선 Extrapolation(추론)
- 학습 곡선을 안정적으로 예측할 수 있는 것이 있다고 가정 = sensitive & valid
- 몇 번 반복 + 지식 = 초기 학습 곡선으로부터 추론 & 성능이 좋지 않은 모델 종료
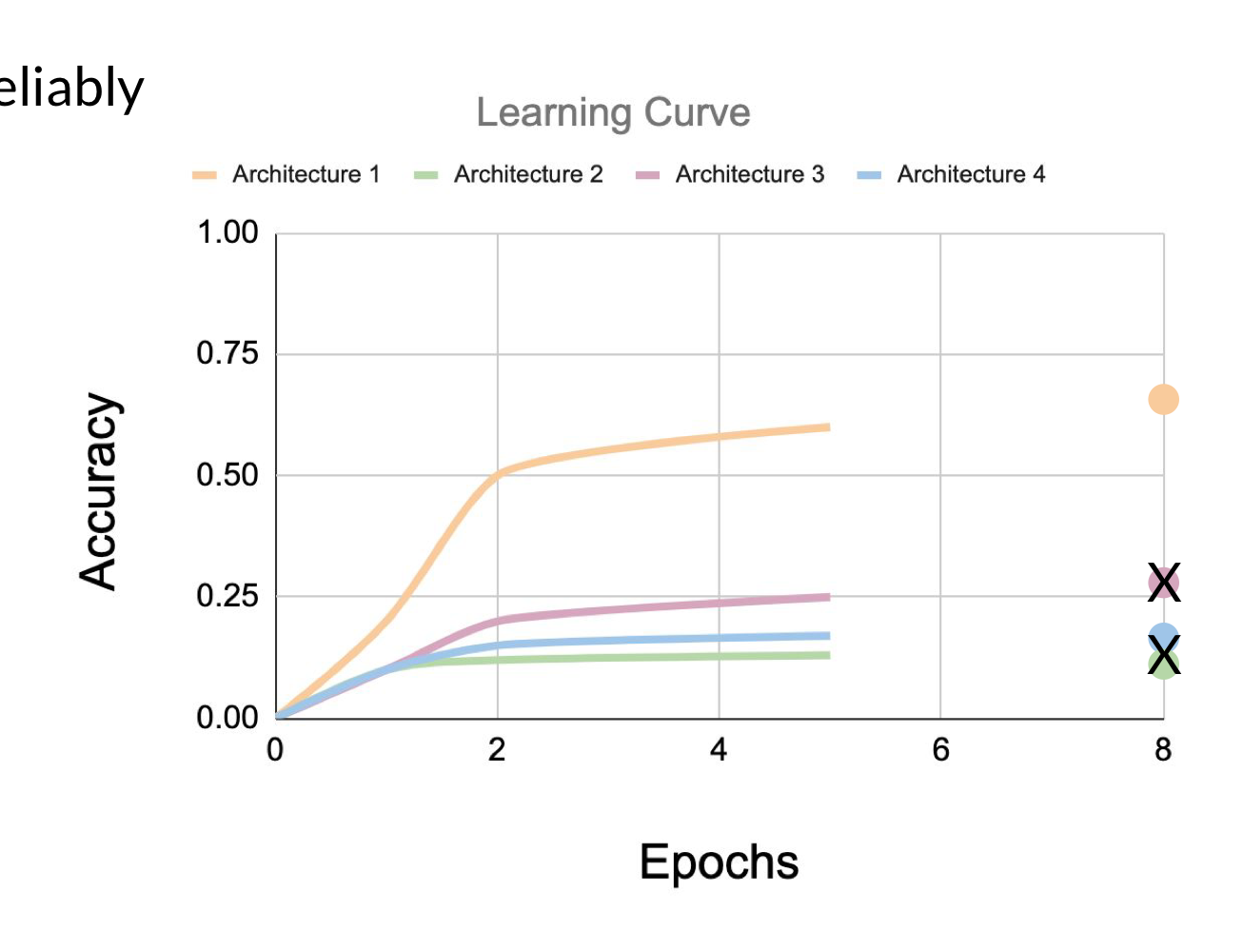
- ≒ Progressive neural arichitecture search algorithm : (NAS 방법론) 대리 모델 학습 & 아키텍쳐 속성을 사용해서 성능 예측
3) 가중치 Inheritance by Network Morphism
- 이전에 훈련된 아키텍쳐의 가중치를 기반으로 가중치 초기화
≒ transfer learning - Network Morphism : 기본 function 변경 없이
- parent 네트워크의 정보 상속 받음 = 빠름
- 아키텍쳐 크기 상한선이 없는 search base 허용 = 네트워크 사이즈 제한 없음(???)
AutoML on Cloud