
(Dark 모드로 읽어주세요.)
Hi! I'm Jaylnne. ✋
페이스북에서 공개한 파이토치 모델을 돌려보던 중, GPU 환경은 건드리지 않고 모델 성능을 향상시킬 수 있는 방법이 없을까? 하는 궁금증이 들었다. 그런 방법이 없을 리 없다고 생각했다. 아니나다를까 구글링해 본 결과, 내용이 깔끔하게 잘 정리된 글이 있기에 그 글을 쉽고, 간략하게, 한국어로 정리해보려고 한다.
비전공자, ML/DL이 낯선 개발자분들도 이해하실 수 있도록 많이 풀어 설명할 예정이기 때문에 답답하신 분들은 바로 아래 원문을 읽어보셔도 좋을 것 같다.
👇👇👇
[Towardsdatascience] 7 tips for squeezing maximum performance from pytorch
글쓴이는 William Falcon 이라는 분으로 간략한 저자 소개를 보면 페이스북에서 AI 연구원으로 일하고 있다는 걸 알 수 있다. pytorch 는 페이브숙에서 개발한 딥러닝 프레임워크이기 때문에 글 내용을 상당히 신뢰할 수 있을 것 같다.
이제 글의 내용을 본격적으로 정리해보자.
아! 그 전에, 글에서는 전반적으로 pytorch lightning 사용을 기반으로 설명하고 있다는 걸 짚고 넘어가면 좋을 것 같다. pytorch lightning 이 뭔지 잘 모르는 분들을 위해 간략히 설명하자면 아래와 같다.
Pytorch Lightning 이란?

간단히 말해 tensorflow 의 keras 같은 존재라고 할 수 있다. 무슨 말이냐면, pytorch 를 더 쉽게 사용할 수 있도록 도와주는 도구라는 거다. 아래 이미지처럼 pytorch 코드를 더 보기 쉽고 편집하기 쉽도록 깔끔하게 정리해주는 역할을 하고, 훨씬 간단한 코드 작성을 통해 모델 학습, 테슽, 검증, 분산된 GPU/CPU 설정 등이 가능하도록 해준다.

7 Tips 💡
이제 정말 시작해보자.
1. User workers in DataLoaders
DataLoader(dataset, num_workers=8)DataLoaders 에서 workers 를 이용하라고 한다. 흠. 🤔 그러니까 직역하자면, 데이터를 로드해오는 기능에서 일꾼들(?)을 이용하라는 뜻이다. 조금 더 생각해보자. 컴퓨터에서 일을 하는 일꾼이란 프로세스를 말하는 것일 테다. 데이터를 로드하는 기능에서 일하는 일꾼이니, 데이터를 로드해오는 역할을 하는 프로세스겠다.
그런데 여기서는 일꾼'들'을 이용하라고 했다. 즉, 프로세스를 동시에 여러개 올릴 수 있다는 이야기다. 아하- 그러니까, 데이터 로딩 과정에서 몇 개의 멀티프로세스를 올릴 건지 설정하라는 말이다. 그래서 옵션의 이름이 num_workers 인가보다.
👀 그래서 일꾼들을 몇 명, 아니 num_workers 를 몇으로 설정해주면 돼?
글에서는 내 PC가 사용하는 GPU 개수에 4를 곱한 값을 추천한다고 한다.
✅ num_workers= 4 * num_GPU물론 '추천'이지 '필수'는 아니다. 자신의 개발 환경에 맞게 적절히 조절해주면 된다.
2. Pin memory
DataLoader(dataset, pin_memory=True)이번에도 직역부터 해보자. 메모리를 고정해라? 흠. 무슨 말일까.
예를 들어보자. 식당으로 치면, 우리 팀 회식을 위해 식당의 테이블을 예약해두는 거다. 막상 팀원들이 도착했을 때 테이블의 자리가 남을 수도 있지만, 어쨌든 식당 주인은 예약 잡아둔 테이블을 다른 손님들에게 내어줄 수는 없을 것이다. 여기서 '식당의 테이블을 예약하는 것'이 'pin_memory 를 True 로 설정해주는 것'이다.
그럼 식당은 무엇이고 테이블은 무엇일까?
✅ 식당: CPU, 테이블: GPU와 통신하기 위한 CPU의 메모리 공간CPU가 GPU에 데이터를 전송하기 위해서는 GPU와 통신이 되어야 한다. 이 통신 역할을 담당하는 프로세스도 당연히 CPU 메모리를 필요로 할 것이다. 이 CPU와 GPU 간 통신 목적의 메모리를 무조건적으로 일정량 이상 확보해둔다는 의미인 거다.
👀 그런데 왜 그렇게 하면 좋은 걸까?
pytorch 포럼 커뮤니티의 글을 살펴본 바, 그 이유는 pin_memory 를 활성화했을 때 CPU가 GPU로 데이터를 전송하는 속도가 빨라지기 때문이라고 한다. 따라서, 속도 차가 의미 없을만큼 데이터가 작거나, 애초에 처음부터 데이터를 GPU에 로드했다면 상관이 없다.
3. Avoid CPU to GPU transfers or vice-versa
# BAD
.cpu()
.item()
.numpy()
# GOOD
.detach()CPU와 GPU 사이에 데이터가 전송되는 과정을 피하라고 하면서 추천하는 메소드와 추천하지 않는 메소드를 구분하고 있다.
BAD 에 해당하는 코드들은 데이터를 CPU 에 올리는 역할을 한다. pin_memory 설명에서 이미 짐작했겠지만 CPU 에서 GPU 로 데이터를 전송하는 일에도 시간이 걸린다. 그래서 GPU 의 데이터를 굳이 CPU 로 옮기는 해당 코드들은 비추천한다고 한다. (물론, 사용하지 말라는 것이 아니고 사용을 너무 남발하지 말자는 의미이다.)
반대로 GOOD 에 해당하는 코드는 사용을 추천하고 있다. 모델이 학습하는 과정에서 back propagation 을 하기 위해 사용하는 계산 그래프를 없애고 싶다면 .detach() 코드를 이용하라고 설명하고 있다.
4. Construct tensors directly on GPU
# BAD
t = tensor.rand(2, 2).cuda()
# GOOD
t = tensor.rand(2, 2, device=torch.device('cuda'))3번 팁 설명에서 이미 언급했듯, CPU 와 GPU 사이에 데이터를 전송하게 되면 속도가 많이 느려진다. 그러니 가장 좋은 방법은 GPU 에 곧장 데이터를 로드하는 방법이다. 이번에도 저자는 비추 코드와 추천 코드를 명시주었다. 앞으로는 # BAD 방식보다 # GOOD 방식으로 코드를 작성할 수 있도록 유념하자.
5. Use DistributedDataParallel not DataParallel
5번 팁은 한 개가 아닌, 여러 개의 GPU 를 이용할 때 도움이 되는 방법이다. 어김없이 직역부터 해보자면, DataParallel(DP) 이 아닌 DistributedParellel(DDP) 을 사용하라, 이다. 흠. DP 와 DDP 가 뭔지부터 알아야 이해가 되겠다.
글에서 설명하고 있는 내용만으로는 이해가 어려워 추가로 구글링을 진행해 보았다. 간단히 말해 DP 방식은 multi-threading 이고 DDP 방식은 multi-processing이다. 그럼 또 멀티 쓰레딩은 뭐고, 멀티 프로세싱은 뭘까? 두 개의 무슨 차이가 있는 걸까?
우선 프로세스(process)란 엄밀히 말해 작업을 위해 실행되어야 할 명령어의 목록 (더욱 정확히는 그 목록을 가지고 있는 메모리)를 뜻하는 말이다. 그리고 이 명령어 목록의 명령어 하나하나를 실행하는 실제 작업자가 스레드(thread)인 것이다.
그러니 멀티 스레딩이란 프로세스는 하나, 이 프로세스의 명령어를 실행하는 스레드는 여럿이라는 뜻이고, 멀티 프로세싱이란 반대로 프로세스가 여러 개, 각 프로세스를 실행하는 스레드는 하나씩이라는 뜻이다.
# DP
Trainer(distributed_backend='dp', gpus=8)
# DDP
Trainer(distributed_backend='ddp', gpus=8)pytorch ligntning 을 이용하는 경우 위 예시처럼 코드가 아주 간단하다.
👀 그런데 왜 multi-processing 인 DDP 방식이 multi-threading 인 DP 방식보다 빠른 걸까?
그 답은 바로 python 의 GIL(Global Interpreter Lock) 때문이다. 또 모르는 용어가 나왔다고 당황하지 말자. Lock 이라는 단어가 포함되어 있으니 무언가를 못하도록 '잠그는' 기능일 것이다. 무엇을 못하도록 할까? 여러 개의 스레드가 동시에 실행되지 못하도록 막는 기능이라고 생각하면 된다. 그래서 python 언어를 기반으로 하는 pytorch 에서는 DP 방식이 아닌 DDP 방식을 추천하는 것이다.
6. Use 16-bit precision
32-bit 로 구성된 데이터를 16-bit 로 변환하여 사용하는 것이 6번째 팁이다. 32-bit 데이터를 16-bit 로 변환하면 데이터가 차지하는 메모리 용량이 절반으로 줄 거다. 그럼 모델 학습의 배치 사이즈를 두 배로 늘려서 학습 속도를 더 빠르게 향상시킬 수가 있다.
또 특정한 GPU 모델(C100, 2080Ti)은 16-bit 계산에 특화되어 있기도 하다고 한다. 그래서 32-bit 계산을 시행할 때보다 16-bit 데이터를 계산할 때 속도가 3배에서 많게는 8배까지도 빨라질 수 있다고. 🙌
Trainer(precision=16)이 또한 pytorch ligntning 을 사용하면 간단하게 설정할 수 있다.
Note) pytorch 1.6 이전 버전에서는 Nvidia Apex 도 함께 설치해주어야 한다. 하지만 그 이후 버전에서는 pytorch ligntning 을 사용할 때 자동으로 pytorch 버전을 인식해 32-bit 로 진행할지 16-bit 로 진행할지 결정해 준다고 한다.7. Profile your code
마지막 팁은 '당신의 코드를 프로파일링 하라' 이다. 프로파일링이란? 우리가 실행한 프로세스가 어떻게 돌아가고 있는지를 자세히 분석하여 보여주는 것이라고 한다. 작업마다 시간이 얼마나 걸렸고 메모리를 얼마나 차지했는지 등을 한눈에 보여주니까, 모델의 학습 속도가 너무 느리다고 생각될 때 이 프로파일링을 이용하면 어디서 병목이 발생하고 있는지 쉽게 찾아낼 수가 있을 것이다.
Trainer(profile=True)위 코드처럼 profile 을 활성화시켜주면, 아래 그림과 같은 결과를 얻을 수 있다.
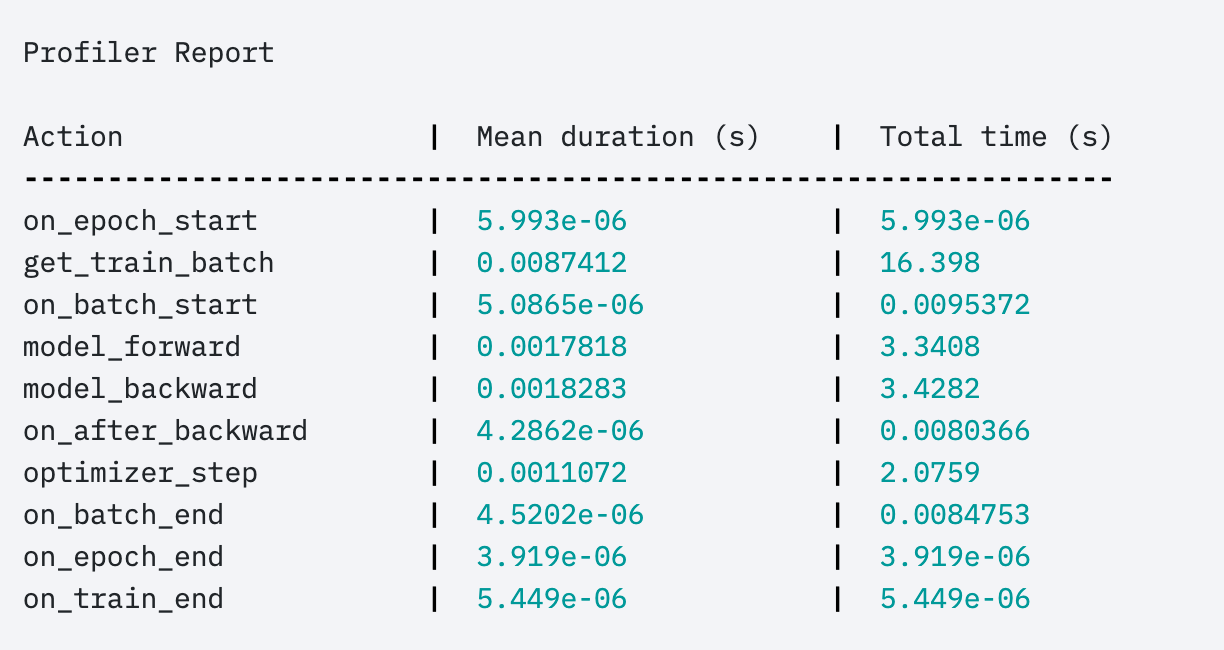
사실 위 결과는 pytorch ligntning 에 기본으로 내장된 프로파일러가 작동된 결과이다. 그렇다면 다른 프로파일러를 작동시킬 수도 있다는 말이 되겠다.
예를 들어,
profiler = AdvancedProfiler()
Trainer(profiler=profiler)이렇게 다른 종류의 profiler 를 지정해주면 아래와 같이 다른 형태의 결과물이 나올 수도 있다.

잘못된 내용이 있으면 댓글로 알려주세요. 🙇♀️

안녕하세요 저가 질문이 있는데, 왜 num_workers값을 지정했는데 GPU가아닌 CPU에서 모델이 학습이 될까요,.? num_workers값을 지정안했을때는 GPU로 학습을 합니다..
GPU 이용률 증가시켜보려했다 참 막히네요..