📗서론
이전 포스팅에서 NLP개선을 위해 TSR 알고리즘에 대해 알아보았다. 그 중 Microsoft의 TATR은 어떤 방식으로 cell영역 탐지를 하는지 알아보겠다.
1. TATR
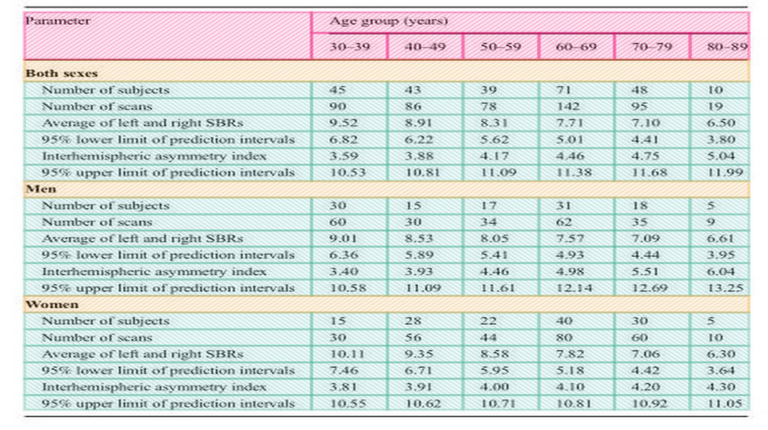
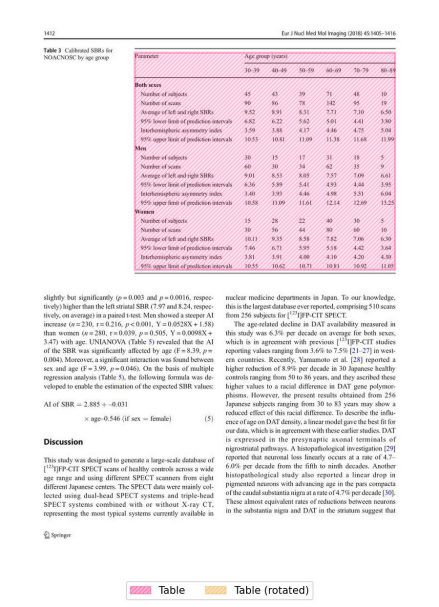
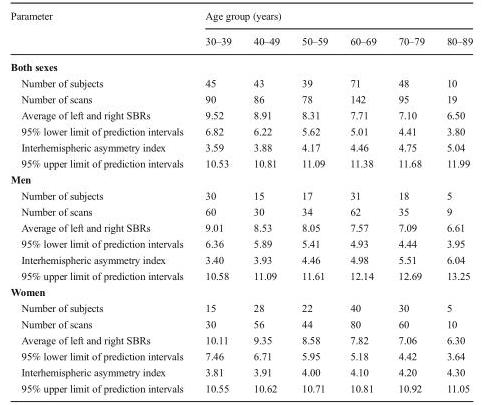
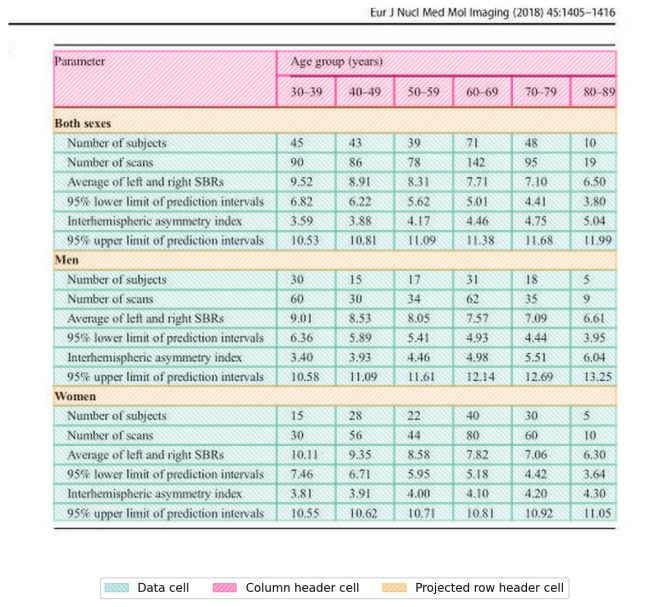
실제 Pubtables-1m에서 test데이터를 Inference 시켜본 결과이다. TATR은 header와 sub header가 구분이 가능하고, 헤더부분의 빈 영역은 병합해주기 때문에 과분할이 일어나지 않는다는 장점이 있다.
단, 해당 Base 모델은 Row와 Column단위로 라벨링 되어있어 header가 아닌 data cell부분에 병합된 cell이 있다면 구조분석 하는데 어려움이 있다.
이를 해결하기 위해서는 header영역을 라벨링 한 방식과 동일하게 병합된 data cell영역도 하나의 cell로 라벨링 하면 가능하지만 이렇게 라벨링 하게되면 학습 parameter가 많아지고, 장점이었던 header와 sub header 그리고 data cell이라는 그룹으로 구분이 불가능해진다.
따라서 header와 sub header로 그룹화 할 필요가 없는 경우에만 라벨링하여 재학습을 통해 진행하면 된다.
2. 사전준비
https://github.com/microsoft/table-transformer/tree/main
마이크로 소프트의 오픈소스로 hugging face에 사전학습 모델이 등재되어 있다.
- git 저장소 복제 및 도커 이미지 빌드
git clone https://github.com/microsoft/table-transformer.git
cd table-transformer/detr
docker build -t table-transformer .- 도커 이미지를 빌드 후 컨테이너 실행
docker run --gpus '"device=0,1,2,3"' -it --shm-size=100G --name Table-test -v /yor/volume/path/Table_Detection/:/home/Table_Transformer a627fd2...(image_ID) /bin/bash- --gpus : 본인 PC의 GPU 중 해당 컨테이너에 할당 할 GPU 번호
- --shm-size : GPU의 공유 메모리 설정
- --name : 컨테이너 이름 설정
- -v : 디렉토리 볼륨 설정 /path/to/your/directory/:/path/to/your/container/directory/
❗❗참고로 해당 도커 환경에서는 pytorch1.5를 설치하도록 되어있는데 해당 버전과 코드가 호환되지 않아서 버전을 바꿔 주어야 한다.
pip install torchvision==0.14.1해당 코드를 통해 torchvision을 설치하면 알아서 버전을 맞춰준다.
필자는 이를 통해 버전 문제를 해결 하였지만 추가로 문제가 발생한다면 git 메인에 있는 environment.yml를 참고하여 버전을 맞춰주어야 한다.
이렇게 하면 최소한의 환경 구성이 완료 되었다.
3. 사전모델 다운로드
hugging face에 업로드 된 모델을 코드를 통해 다운로드 할 수 있다.
https://huggingface.co/microsoft/table-transformer-detection?library=true
위 사이트에 들어가서 우측 상단에 </>Use in Transformers 버튼을 클릭하면 모델을 다운받을 수 있는 코드를 볼 수 있다.
from transformers import pipeline
pipe = pipeline("object-detection", model="microsoft/table-transformer-structure-recognition-v1.1-fin")
# Load model directly
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
model = AutoModelForObjectDetection.from_pretrained("microsoft/table-transformer-detection")아니면 깃 주소에 들어가면 모델을 다운받을 수 있다
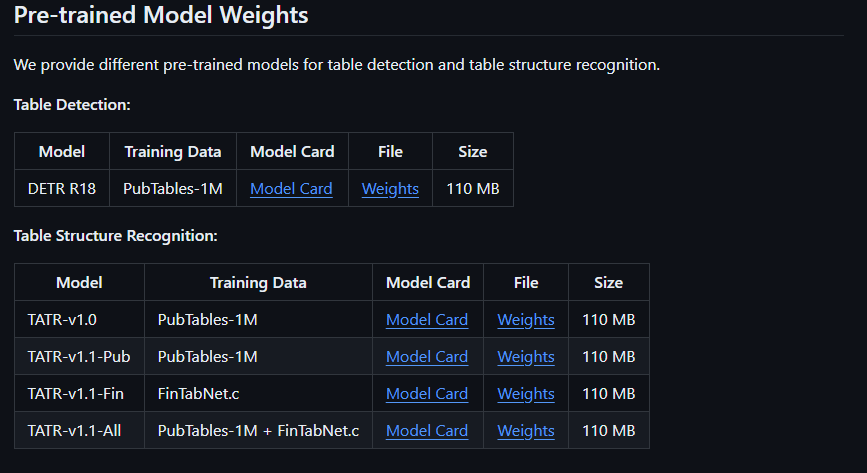
Detection 모델과 Structure Recognition모델 하나씩 다운 받는다.
4. 사전모델 Inference
우선 폴더 구조는 다음과 같이 구성 하였다
└─table-transformer
├─models
│ ├─det
│ └─rec
└─src
├─data
├─det_data
└─result
├─det_result
├─extract_result
└─rec_result
- models/det : detection모델 저장
- models/rec : recognition모델 저장
- src/data : 원본 이미지 저장
- src/det_data : detection한 결과 저장 (recognition 시 Crop된 이미지 필요)
- result : Inference에는 Detection, Recognition, Extraction 3가지 옵션이 있다.
- 실행 코드
- To run table detection on a folder of document page images:
python3 inference.py --mode detect --detection_config_path ./detection_config.json --detection_model_path ../models/det/pubtables1m_detection_detr_r18.pth --image_dir ./data --out_dir ./result/det_result -o -p -z --crop_padding 20- To run table structure recognition on a folder of cropped table images:
python3 inference.py --mode recognize --structure_config_path ./structure_config.json --structure_model_path ../models/rec/pubtables1m_structure_detr_r18.pth --structure_device cuda --image_dir ./data --out_dir ./result/rec_result -o -l -c -z- To run table extraction (detection and recognition combined end-to-end) on a folder of document page images:
python3 inference.py --mode extract --detection_config_path ./detection_config.json --detection_model_path ../models/det/pubtables1m_detection_detr_r18.pth --detection_device cuda --structure_config_path ./structure_config.json --structure_model_path ../models/rec/pubtables1m_structure_detr_r18.pth --structure_device cuda --image_dir ./data --out_dir ./result/extract_result -o -l -z --crop_padding 203가지 Inference 명령어에는 -o -c -z와 같은 옵션이 있는데 이는 여기를 참고하여 필요한 옵션을 사용하면 된다.
5. Inference 결과
- 원본이미지
- Detection 결과
- Table Detect
- Table Crop
- Recognition 결과
모델 학습방법
- 디렉토리 구조
└─det_train_data
│
├─images
├─train
│─val
│─ train_filelist.txt
└─ val_filelist.txt- images : Train, Valid Image Set
- train : Train에 사용될 xml파일
- val : valid에 사용될 xml파일
- train_filelist.txt : train폴더에 있는 xml파일 리스트
- val_filelist.txt : val폴더에 있는 xml파일 리스트- Detection model
python main.py --data_type detection --config_file detection_config.json --data_root_dir ./det_train_data- Recognition model
python main.py --data_type structure --config_file structure_config.json --data_root_dir ./rec_train_data📗 결론
PubTables-1M의 Test 데이터를 통해 나온 결과를 보면 상당히 높은 수준의 Table 구조 분석이 가능한 것으로 보인다. 다만 해당 데이터셋은 논문의 이미지로 해당 양식과 다른 이미지가 Input으로 들어오면 성능이 다소 떨어진다. Train코드도 제공 해 주고 있기 때문에 본인의 도메인에 맞게 학습시켜 사용할 수 있을 것 같다.
🎈 TO DO
해당 Base모델은 header부분에 cell이 병합되어 있는 경우 table spanning cell로 label되어 있지만 data cell에는 병합된 부분에 대해 고려하지 않았다. Column과 Row 단위로 라벨링 되어 있어서 Input 이미지에 병합된 data cell이 있으면 셀이 과다하게 분할되는 경우가 있다.
그룹화를 포기하고 라벨링을 다시할지, 다른 알고리즘을 찾아볼지 정해 보도록 하겠다.
논문 출처
