
👉 자료구조와 알고리즘 알아보기
추상적 자료형 (ADT, Abstract data type)
: 문제를 해결하기 위해 필요한 자료의 형태 및 연산을 수학적으로 정의한 모델 (집합, 리스트, 스택, 큐, 트리 등)
자료 구조 (Data structure)
: 추상적 자료형이 정의한 연산들을 구현한 구현체로, 마치 책장 속 책을 배열하는 방법과 같다. (콜 스택, 연결 리스트, 배열 등)
알고리즘 (Algorithm)
: 반복되는 문제를 풀기 위한 진행 절차나 방법으로, 마치 책장에서 책을 찾는 방법과 같다. (정렬, 이진 탐색 등)
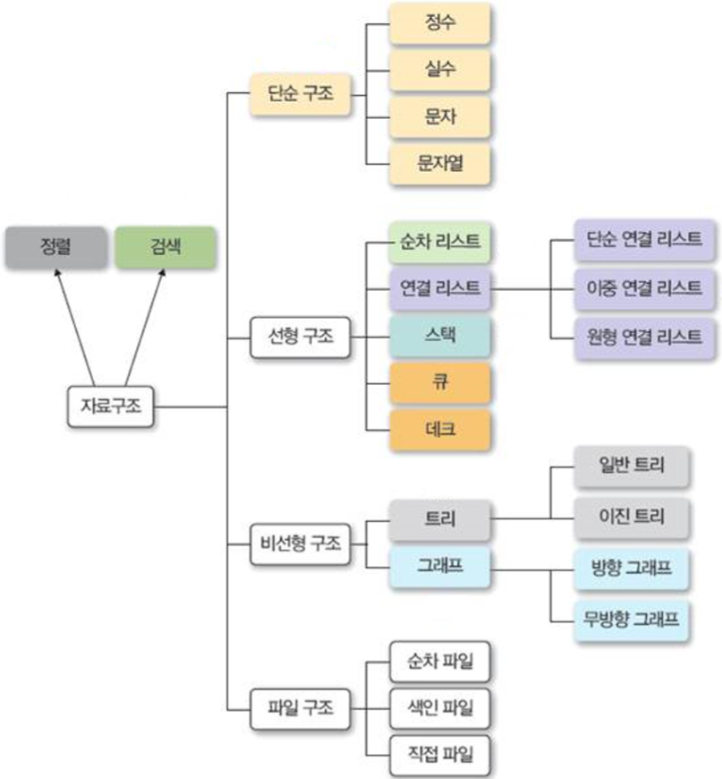
자료 구조 Data structure
- 논리적인 관계로 이루어진 데이터 구성
- 데이터 단위와 데이터 자체 사이의 물리적/논리적인 관계
- 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장
즉 자료 구조란 데이터의 효율적인 접근 및 조작을 가능하게 해주는 저장 및 관리 방식이다. 자료를 구조화하여 데이터를 효율적으로 사용하기 위한 목적을 갖는다.
스칼라 scalar - 하나의 값으로 구성된 자료 구조 (자료 구조를 만드는 가장 작은 기본 단위)
여러 값을 나열한 자료 구조 :
[리스트 list]
(튜플 tuple) - 값 수정 불가능 (함수의 파라미터에 값을 입력할 때 자주 사용)
{'딕셔너리' : 'dictionary'} - 키와 값이 짝을 이루어 나열 (함수의 파라미터에 값을 입력할 때 자주 사용)
pandas 자료 구조
시리즈 series - 데이터 프레임을 구성하는 하위 요소 (데이터 프레임을 다루는 함수 대부분이 시리즈를 이용해 연산)
데이터 프레임 data frame - 행과 열로 구성된 사각형 모양의 표처럼 생긴 자료 구조 (데이터를 다룰 때 가장 많이 사용되는 자료 구조)
알고리즘 Algorithm
- (사전적 의미) 어떤 문제를 해결하기 위한 절차, 방법, 명령어들의 집합
- (프로그래밍적 의미) 주어진 문제 해결을 위해 자료구조, 연산 방법을 선택하는 것
- 컴퓨터가 따라 할 수 있도록 문제를 해결하는 절차나 방법을 자세히 설명하는 과정
알고리즘 패러다임
- 알고리즘의 문제 해결을 위한 유형
알고리즘의 설계와 분석을 특정한 접근 방식이나 전략에 기반하여 이해하는 프레임워크로, 각 패러다임은 특정한 문제 해결 방식이나 알고리즘 설계 원칙을 나타내며, 특정 유형의 문제에 효과적일 수 있다.
각각의 알고리즘 패러다임은 특정한 유형의 문제에 뛰어난 성능을 보이는 반면, 다른 유형의 문제에는 적합하지 않을 수 있다. 알고리즘 디자인에서는 주어진 문제의 특성에 따라 적절한 패러다임을 선택하는 것이 중요하다.
1. 탐욕(그리디)
- 실행되는 순간마다 최상의 결정 (가장 적합한 동작)을 내리는 알고리즘
- 각 단계에서 현재 상태에서 가장 최선의 선택을 하는 알고리즘입니다. 각 단계에서 최적의 선택을 함으로써 전체적인 최적해를 찾는다는 아이디어에 기반합니다.
2. 분할 정복
- 큰 문제를 작은 부분 문제로 분할하고, 각 부분 문제를 해결한 후, 그 결과를 결합하여 최종적인 해를 얻는 알고리즘입니다. 대표적인 예로는 병합 정렬과 퀵 정렬이 있습니다.
3. 동적 계획법
- 과거에 내린 결정이 앞으로의 결정에 영향을 주는 알고리즘
- 작은 부분 문제의 해결 결과를 저장하고, 나중에 동일한 부분 문제가 다시 나타날 때 이전에 계산한 결과를 사용하여 중복 계산을 피하는 알고리즘입니다. 최적 부분 구조와 중복 부분 문제가 필요한데, 대표적인 예로는 피보나치 수열 계산이 있습니다.
4. 백트래킹
Backtracking (백트래킹):
- 가능한 모든 해를 시도하면서 문제의 해를 찾는 알고리즘입니다. 하나의 후보해를 시도하다가 더 이상 진행할 수 없으면 이전 단계로 돌아가서 다른 후보해를 시도합니다. 많은 경우 조건을 만족하는 모든 해를 찾는 데 사용됩니다.
5. 브루트 포스
- 가능한 모든 경우의 수를 고려하여 해를 찾는 간단하면서도 직관적인 알고리즘입니다. 모든 가능성을 시도하여 문제를 해결하므로 최적화가 부족할 수 있습니다.
6. 확률적 알고리즘
Randomized Algorithms (확률적 알고리즘):
- 확률적인 기법을 사용하여 문제를 해결하는 알고리즘으로, 실행할 때마다 다른 결과를 얻을 수 있습니다. 확률적 선택이나 무작위성을 활용하여 성능을 향상시키는 데 사용됩니다.
이 외에도 많은 알고리즘 패러다임이 존재한다.
7. 그래프 알고리즘
Graph Algorithms (그래프 알고리즘)
8. 정렬 알고리즘
9. 탐색 알고리즘
Searching Algorithms (탐색 알고리즘)
10. 문자열 매칭 알고리즘
String Matching Algorithms (문자열 매칭 알고리즘)
11. 머신러닝 알고리즘
Machine Learning Algorithms (머신러닝 알고리즘)
알고리즘 패러다임 비교
- 탐욕 알고리즘과 동적 프로그래밍 알고리즘 모두 문제를 더 작은 단위로 나누는 데 중점을 둔다.
- 탐욕 알고리즘은 특정 순간에 최적인 해결 방법을 찾는다.
(근사치) - 동적 프로그래밍 알고리즘은 문제를 해결하는 다양한 해결 방법을 찾아 저장한 후 나중에 재사용한다.
(최적화)
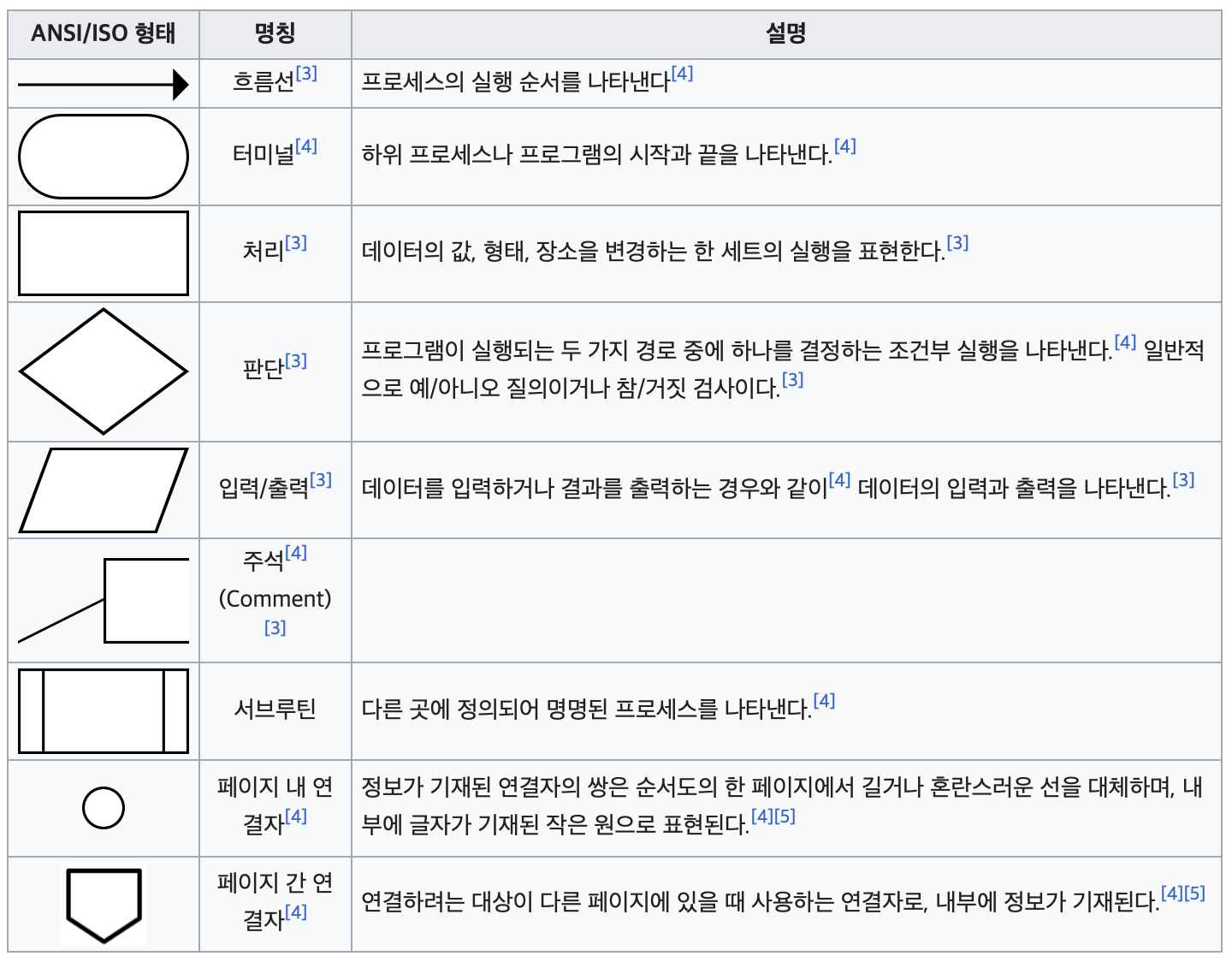
순서도 Flowchart
워크플로 혹은 프로세스를 보여주는 다이어그램의 한 종류다. 여러 종류의 상자와 이를 이어주는 화살표를 이용해 주어진 문제에 대한 솔루션 모델을 보여준다. 프로세스 작용은 이 같은 상자들과 작업의 흐름(workflow)을 나타내는 화살표 연결로 나타낸다.
알고리즘 평가법 : 복잡도
우리는 문제를 빨리 해결하는 알고리즘을 원한다.
알고리즘은 시간과 공간 (컴퓨터의 메모리) 두 가지의 평가 기준이 있으며, 공간은 물리적으로 늘릴 수 있지만 시간은 불가능하므로 시간 복잡도가 더 중요하다.
시간 복잡도 Time Complexity : 문제의 크기와 이를 해결하는 데 걸리는 시간 사이의 관계 (알고리즘 성능 효율성)
평균 시간 복잡도 Average Time Complexity: 임의의 입력 패턴을 가정했을 때 소요되는 시간의 평균최악 시간 복잡도 Worst-case Time Complexity: 가장 긴 시간을 소요하게 만드는 입력에 따라 소요되는 시간
공간 복잡도 Space Complexity : 문제의 크기와 이를 해결하는 데 필요한 메모리 공간 사이의 관계 (자원이 제한된 시스템에서 사용)
복잡도 특징 :
- 시간 복잡도는 공간 복잡도보다 작거나 같다.
- 알고리즘을 분석하거나 성능을 측정할 때는 시간 복잡도를 훨씬 더 자주 이용한다.
- 연습하다보면 코드 없어도 시간 복잡도를 구할 수도 있다.
알고리즘의 시간 복잡도를 분석하는 방법 :
실제적인 방법: 입출력 데이터의 양이 알고리즘 동작에 미치는 영향을 관찰하고 기록하는 것 (정확성이 떨어지며 사용 범위가 제한적인 단점)수학적인 방법 (점근적 분석): 수학적으로 알고리즘 성능의 한계를 증명하는 것으로, 알고리즘 성능이 최악이 되는 경계를 판단하거나 알고리즘의 평균 성능을 찾음
거듭제곱 (Exponentiation)
n^-1= 1/n
n^0= 1
n^1= n
로그 (Logarithms)
거듭제곱의 반대 개념
logₐb = x⇨a^x = b: b를 a로 몇 번 나누어야 1이 되는가?
1부터 n까지의 합
n*(n+1) / 2: n+1을 n번 곱하고 2로 나눈 값
참고 : 파이썬 기능의 시간 복잡도
| 함수 | 시간 복잡도 |
|---|---|
| type(), len() | O(1) |
| max(), min() | O(n) |
| str() | O(logn), O(d) - 파라미터 n, n의 자릿수 d |
| append() | O(1) |
| insert(), del, index(), reverse() | O(n) |
| .sort(), sorted() | O(nlogn) |
| slicing[a:b] | O(b-a) |
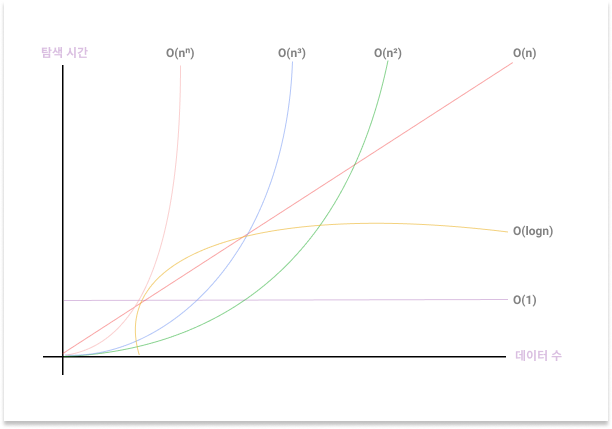
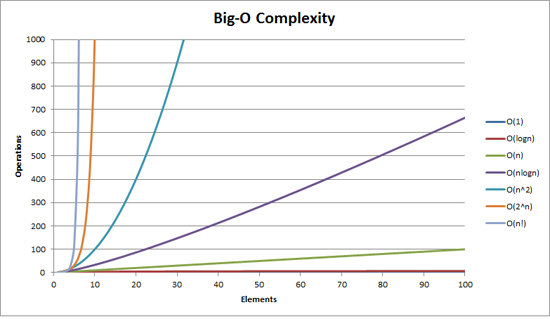
빅오 표기법 Big-O nonation
- 점근 표기법 Asymptotic notation의 일종
- 빅 오메가, 리틀 오메가, 빅 오, 리틀 오, 세타 등 다양한 표기법 존재 - 어떤 함수의 증가 양상을 다른 함수와의 비교로 표현하는 방법
- 알고리즘 사이의 점근적 증가율 비교를 위해 사용
- 알고리즘에 입력하는 데이터양의 증가에 다른 처리 시간 변화율
- 알고리즘의 실행 시간이 최악인 경우를 나타내는 것 = n이 크다고 가정
2n² + 9n + 35: n의 영향력이 더 큰 것만 남기고, 숫자는 삭제하여 표현 =O(n²)=빅 오 오브 엔의 제곱
Big-O nonation 표현
빅 오 표기법은 상수를 무시한다.
다양한 차수가 한데 섞여 있을 때는 가장 높은 차수의 N만 고려한다.
O(n): 선형 시간 (원소의 개수 n에 비례하여 걸리는 시간)
- 반복문이 있을 경우O(1): 상수 시간 (원소의 개수와 상관없이 고정되어 걸리는 시간)
- 반복문이 없을 경우O(logn)=O(log₂n): 로그형 알고리즘 (시간이 선형적으로 증가하면 n이 기하급수적으로 증가 = n이 클수록 실행 시간은 줄어듦)
- 데이터가 두 배로 증가할 때마다 한 단계씩 늘어나는 알고리즘O(nlogn): 선형-로그형 알고리즘 (데이터 입력량이 n배 늘어나면 실행 시간이 n배 조금 넘게 늘어남)O(n) * O(logn)
- 두 종류의 반복문이 중첩된 경우O(n²): 2차 알고리즘 (데이터 입력량의 제곱에 비례한 실행 시간)
- 반복문 안에 반복문이 있을 경우O(n³)O(2^n): 지수형 알고리즘 (데이터 입력이 추가될 때마다 실행 시간이 2배로 늘어남)O(n!): 계승(팩토리얼)형 알고리즘 (데이터 입력이 추가될 때마다 실행 시간이 n배로 늘어남)
성능 순서 : O(1) > O(logn) > O(n) > O(nlogn) > O(n²) > O(n³) > O(2^n) > O(n!)
자료구조와 알고리즘에 대한 자세한 내용은 여기서 볼 수 있다.
🌟 개발 블로그 참고 🌟
ChatGPT https://ko.wikipedia.org/wiki/순서도 코드잇
