오늘 배울 것
- selenuium을 이용해서 브라우저 제어하고, 웹 스크래핑하기
(request보다 다양한 것들 할수있음) - 내 웹사이트에 네이버 지도 넣기
- 네이버 지도 API의 다양항 기능 활용해보기
크롤링 vs 스크래핑 차이
- 웹 스크래핑: 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해 오는 것!
- 크롤링: 한국에서는 같은의미로 사용하지만, 자동화하여 주기적으로 웹 상에서 페이지들을 돌아다니며 분류,색인하고 업데이트된 부분을 찾는 등의 일을 하는 것을 뜻한다.
멜론차트를 requests로 스크래핑하기
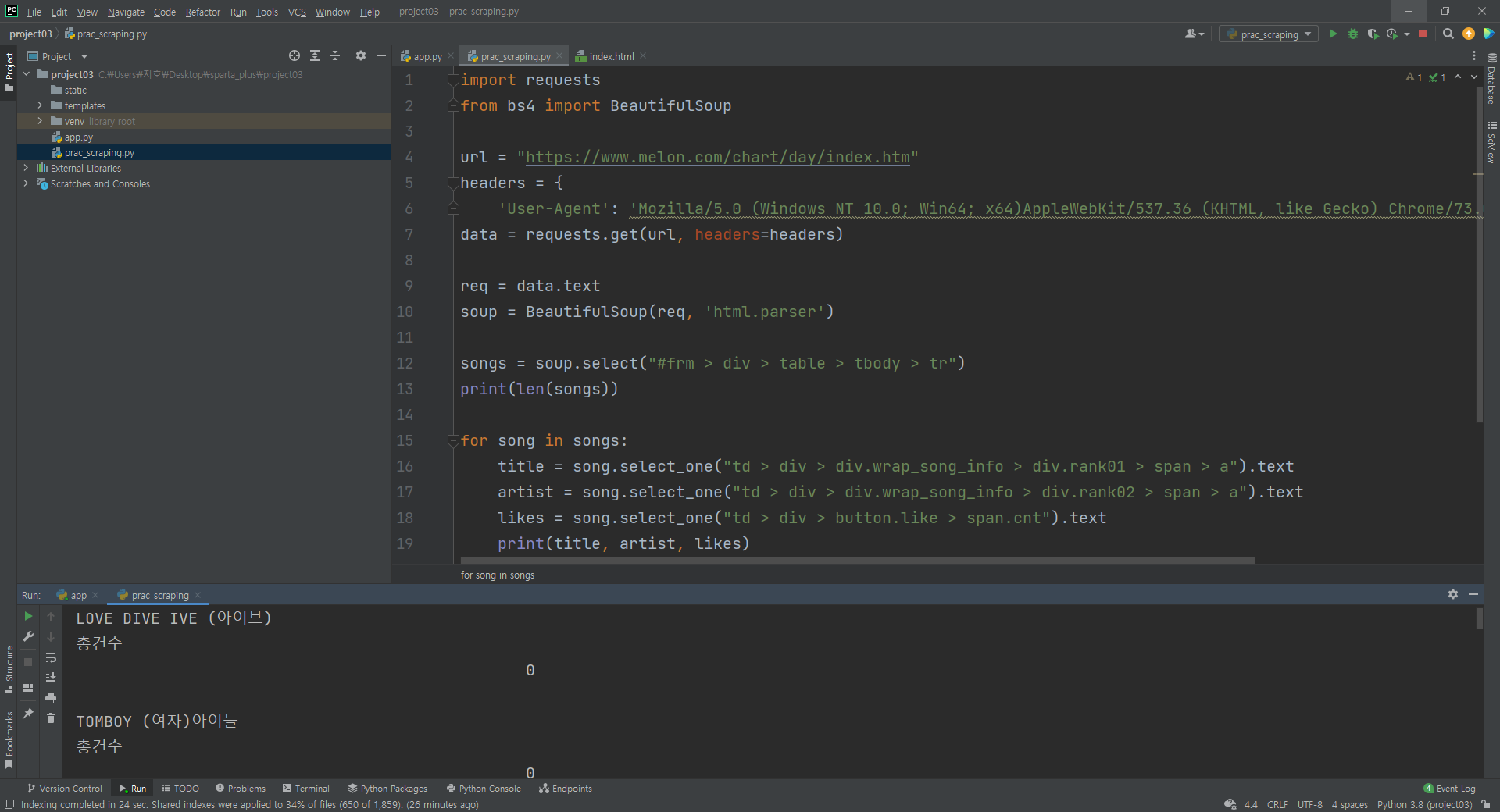
requests랑 bs4를 사용해서 크롤링했는데 좋아요에 갯수가 표시가 안되고 0으로만 나온다.
왜그럴까?
- 멜론차트처럼 동적인 웹페이지를 스크래핑할때는 브라우저에 띄운 후에 소스코드를 가져오는 방법을 사용해야 한다.
(동적인 웹페이지: 한번 HTML이 로드되고 나서 다시 Ajax를 이용해여 정보를 가져와서 페이지를 바꾸는 페이지)
requests는 처음에 0으로 좋아요 개수데이터를 요청하기 전의 데이터를 가져오기 때문
샐레니움으로 스크래핑해보기
- 샐레니움을 사용하기 위해서 구글버전에 맞는 드라이버를 다운받았고, 샐래니움 코드로 변경해주었다.
from bs4 import BeautifulSoup
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome('./chromedriver') # 드라이버를 실행합니다.
url = "https://www.melon.com/chart/day/index.htm"
# headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# data = requests.get(url, headers=headers)
driver.get(url) # 드라이버에 해당 url의 웹페이지를 띄웁니다.
sleep(5) # 페이지가 로딩되는 동안 5초 간 기다립니다.
req = driver.page_source # html 정보를 가져옵니다.
driver.quit() # 정보를 가져왔으므로 드라이버는 꺼줍니다.
# soup = BeautifulSoup(data.text, 'html.parser')
soup = BeautifulSoup(req, 'html.parser') # 가져온 정보를 beautifulsoup으로 파싱해줍니다.
songs = soup.select("#frm > div > table > tbody > tr")
print(len(songs))
for song in songs:
title = song.select_one("td > div > div.wrap_song_info > div.rank01 > span > a").text
artist = song.select_one("td > div > div.wrap_song_info > div.rank02 > span > a").text
likes = song.select_one("td > div > button.like > span.cnt").text
print(title, artist, likes)이렇게 적용했는데 계속해서 "총 건수"라는게 떠서 이것을 없애주기 위해서 코드를 약간만 변경해주었다.
for song in songs:
title = song.select_one("td > div > div.wrap_song_info > div.rank01 > span > a").text
artist = song.select_one("td > div > div.wrap_song_info > div.rank02 > span > a").text
likes_tag = song.select_one("td > div > button.like > span.cnt")
likes_tag.span.decompose() # span 태그 없애기
likes = likes_tag.text.strip() # 텍스트화한 후 앞뒤로 빈 칸 지우기
print(title, artist, likes)
span태그를 없애주니까 총 건수가 사라지고 잘 출력된다.
브라우저 제어하기
브라우저를 제어한다는 것은 무엇일까? 단순히 HTML만을 띄우는 것이 아니라, 샐레니움을 이용해서 스크롤, 버튼 클릭 등 다양한 동작을 하는 것!
from bs4 import BeautifulSoup
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome('./chromedriver')
url = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query=%EC%95%84%EC%9D%B4%EC%9C%A0"
driver.get(url)
sleep(3)
req = driver.page_source
driver.quit()
soup = BeautifulSoup(req, 'html.parser')
images = soup.select(".tile_item._item ._image._listImage")
print(len(images))
for image in images:
src = image["src"]
print(src)
이 코드대로하면 네이버에서 아이유를 검색한 한 페이지의 이미지주소의 URL이 출력된다.
한 페이지에 50건의 아이유 사진의 URL을 받아볼수있었다.
from bs4 import BeautifulSoup
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome('./chromedriver')
url = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query=%EC%95%84%EC%9D%B4%EC%9C%A0"
driver.get(url)
sleep(10)
driver.execute_script("window.scrollTo(0, 1000)") # 1000픽셀만큼 내리기
sleep(1)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(10)
req = driver.page_source
driver.quit()
soup = BeautifulSoup(req, 'html.parser')
images = soup.select(".tile_item._item ._image._listImage")
print(len(images))
for image in images:
src = image["src"]
print(src)
업로드되고 10초뒤에 1000픽셀만큼 스크롤하고 1초뒤에 다시 바닥까지 스트롤하는 코드를 입력해주었다.
execute_script("window.scrollTo(0, document.body.scrollHeight);")execute_srcpit("")는 내가 쌍 따옴표안에 쓴 명령어를 크롬 브라우저가 실행해줘! 라는 뜻이다.
window.scrollTo(x,y)는 윈도우야 스크롤해줘! 라는뜻이고 안에는 x과y좌표값이다, document.body.scrollHeight는 내가 보고있는 문서의 높이, 즉 내가 보고있는 document의 body태그 안에 스크롤의 높이니까 내가 보는 문서의 전체 높이이다.
네이버 지도 API
네이버 지도 api를 사용하기 위해서 네이버 클라우드 플랫폼에 가입하고, api를 받는다.
그리고 html에 코드 넣고 html에서 브라우저로 열어주면 에러가 난다.
왜? 이전에 locahost:5000에서만 사용하겠다고 했는데, 파이참에서 바로 브라우저로 띄우면 주소가 에러가 나기때문!
네이버 클라우드에서 localhost:5000을 넣어줘야하는데 local:5000을 넣어서 자꾸 에러가 났었다.
API를 설계 해보았다
- 맛집 정보 스크래핑하기
- 지도보여주기
- 각 맛집 별 마커, 정보창, 카드 만들고 서로 연결하기
정도가 나타났다.
맛집 정보 스크래핑하기
- SBS TV맛집에서 맛집정보를 스크래핑을 해보았다
느낀점
- TIL을 오늘 공부한걸 정리하는 느낌도 좋지만, 공부내용을 정리하는 것은 다른곳에다 중점적으로정리해놓고, 오늘느낀점이나 특히나 유용했던 내용들을 담아야겠다.
- 오늘강의는 재미있고 유용하게수강했는데, 12시쯤에 어떤일때문에 집중을 잘못했던게 아쉽다.
- 인스턴스 과금이 나와서 중지했다가 다시 실행시키니까 IP가 변동되어서 DB에 저장이 잘 되지 않았다..ㅠㅠ 그래서 이문제를 해결하려고 처음엔 인스턴스를 수정하다가 안되서 다시 만들었는데 GIT BASH를 통해서도 자꾸 CONNECT REFUSE가 나와서 또 다시해보다가 잘 해결되었다..
