
이 포스팅은 https://github.com/danqi/acl2020-openqa-tutorial 를 참고하여 작성하였습니다.
5. Two-stage retriever-reader approaches
Problem setup
- Input : question Q, D = English Wikipedia (~5 million documents)
- Output : answer A
(a) General framework
DrQA : a frist neural open-domain QA system [Chen et al., 2017]

Document Retriever
- TF-IDF weighted term vector model over unigrams/bigrams
- 학습 X and document 수준의 검색기
Document Reader
독해 문제로 이어진다. Input은 passage P(e.g. paragraph, document)와 question Q이다. Output은 answer A이다. 단, A는 P의 text 일부분이여야 한다. SQuAD 1.1에서 BERT는 90.0 F1, RoBERTa 94.6 F1 성능을 보였다.
어떻게 모델을 학습시킬까?
- 존재하는 reading comprehension dataset(e.g. SQuAD)를 사용한다
- 다른 QA dataset을 사용하기 위해서는 retriever를 사용하여 distanly supervised examples를 생성하다.

Training Time
- Document Retriever는 학습 X.
- Document Reader : SQuAD와 distantly-supervised data로 학습된 LSTM 기반 신경망 기계독해 모델
Inference Time
- document retriever는 top 5 document들을 추출
- document reader는 이 문서들의 모든 paragrph을 읽고 answer과 span score를 예측한다.
- 시스템은 최종적으로 가장 높은 span score를 가진 답을 출력한다.
실험을 통한 성능 개선 방안 제시
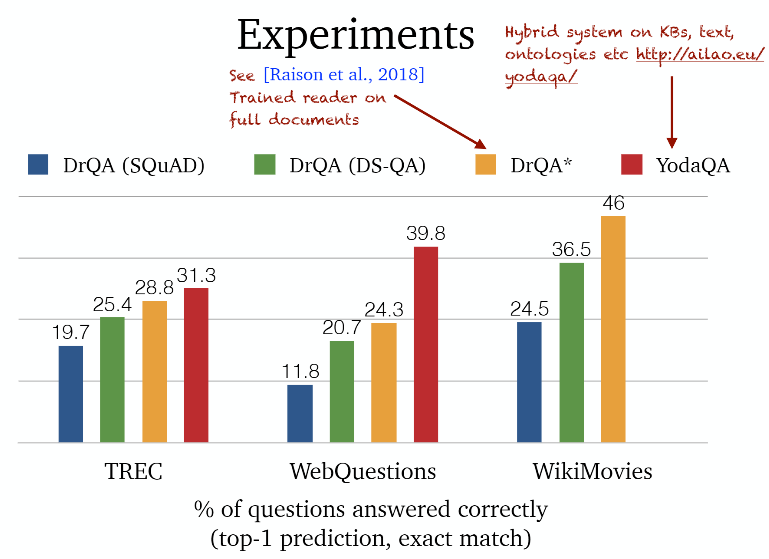
- DrQA는 document 수준에서 검색을 고려한다.
→ Ⅰ paragraph-level retriever가 더 잘 동작할까? - 검색된 문단들에서 답은 추론 시 직접 비교할 수 없다.
→ Ⅱ multi-passage training이 더 나을까? - 각 문단의 중요성은 생략되었다.
→ Ⅲ passage retriever 점수를 사용하거나 더 나은 ranker를 훈련시킬 수 있을까? - Ⅵ retriever는 훈련되지 않았다!
(b) Multi-passage training
Ⅰ. BERTserini [Yang et al., 2019]
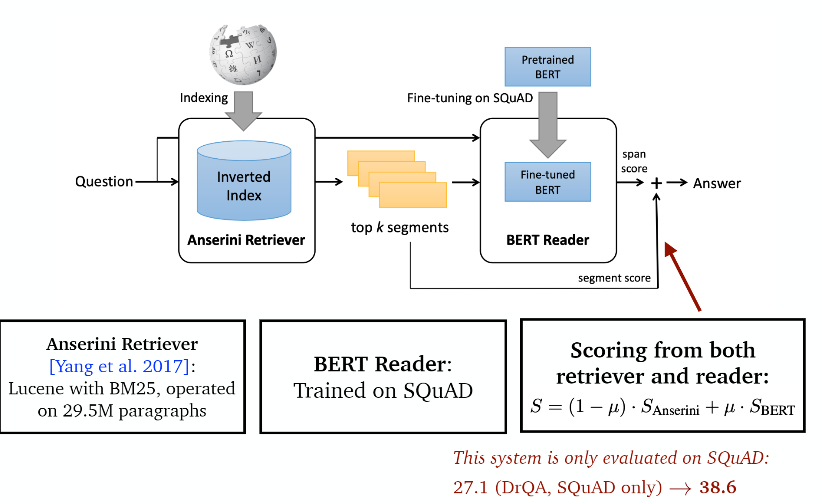
Ⅱ. Multi-passage training [Clark and Gardner, 2018; Wang et al., 2019]
공유된 정규화 : 문단을 독립적으로 처리하지만 각각 mini-batch마다 모든 문단의 span 확률을 계산한다.
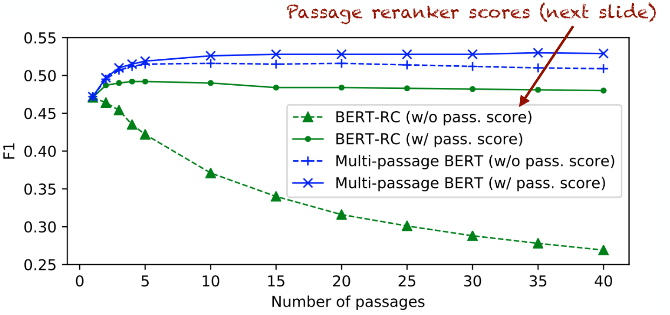
(c) Passage reranking
Ⅲ. Training a passage re-ranker [Wang et al., 2018]
- "deep" re-ranker model를 훈련시키는 것은 각 문단의 관련성을 식별하는데 도움이 된다.

- 이 reranker는 문단이 답을 포함하든 안하든 distant supversion을 사용하여 쉽게 학습시킬 수 있다.
- 더 좋은 해결책은 reader로부터 training signal을 사용하는 방법이다.
Reinforce ranker-reader

Experiements

Training an answer re-ranker [Wang et al., 2018]
만약 모든 문단에서 답변 후보를 출력한다면 모든 증거를 기반으로 답변 후보의 순위를 다시 매길 수 있을까?
- Strength-based re-ranker : 답변 후보가 여러 증거에 의해 뒷받침되는 경우 정답일 확률이 높다.
- Coverage-based re-ranker : 증거 집합이 질문의 대부분의 정보를 포함한다면 답일 확률이 높다.
(d) Denoising distantly supervised data
만약 하나의 문단에 답변이 여러번 언급되면 어떻게 해야 될까? distant-supervised 예제에서 어떤 범위가 정답인지 모른다. 이때 Hard EM Approach를 사용한다.
6. Dense retriever and end-to-end training
⭐ 주요 질문
Q. retriever를 학습시킬 수 있을까?
Q. 검색을 위해 dense representation을 사용할 수 있을까?
(a) Dense passage retrieval
Sparse (희소 표현) vs dense (밀집 표현)
희소 표현 (Sparse Representation)
- 현실에 있는 단어들의 수는 수만 개 또는 그 이상이 존재할 것이고 이 단어들을 모두 벡터로 표현하면 차원소는 굉장히 커질 것이다. 이렇게 만들어진 벡터를 희소 벡터라 하며, 해당 단어 인덱스 값만 1이고 나머지 값은 모두 0으로 구성된다.(=Sparse 하다)
- 두 벡터의 내적이 항상 0이다. 이는 두 벡터가 항상 직교한다는 것이다. 즉, 두 벡터가 항상 독립적이라는 것을 의미하지만, 실제로는 어떤 두 단어 사이에 전혀 관련성이 없지 않다. 예를 들어, 강아지와 고양이는 '동물'이라는 카테고리 안에 속하며 어느정도 유의성을 가진다. 위 예시 외에도 유의어, 반의어 같이 단어들끼리 의미적으로 특정한 관계를 맺고 있다.
밀집 표현 (Dense Representation)
- 밀집 표협은 희소표현의 문제점인 고차원과 내적 값이 항상 '0'인 부분을 해결하기 위한 방법이다.
- 먼저, Sparse vector의 요소값은 0 or 1인 이진 값을 가지지만, Dense vector는 연속형 실수 값을 가진다.

| Sparse vector | Dense vector |
|---|---|
| 9차원 벡터 9개 | 색상, 모양이라는 2가지 속성으로 구성된 2차원 벡터 |
- 밀집 벡터는 그 값이 연속적인 실수값이기 때문에, 벡터 간 거리나 유사도를 잴 수가 있다.
※ Vocab : 중복된 단어가 없는 서로 다른 단어들의 집합
※ One-hot encoding : 표현하고 싶은 단어의 index를 1, 나머지를 모두 0으로 설정
그런데, 2019년 이전에는 open-domain QA에서 Sparse representation은 Dense보다 늘 뛰어는 성능을 보였다. 그러면 왜 지금은 dense retrieval을 사용할까?
-
5M 문서, 30M 문단들, 60B 문장들로부터 encode, index, search해야한다.
* 2011 best paper : Learning Discriminative Projections for Text Similarity Measures- 언어 간 문서 검색, 광고 관련성 예측, 웹 검색 랭킹
-
dense model이 작동하도록 하는 것은 쉽지 않다. (많은 labeled data가 필요함)
-
fast maximum inner product search를 지원할 더 나은 기술과 툴을 가지고 있다.
(b) Joint training of retriever and reader
ORQA [Lee et al, 2019]
retriever와 reader를 동시에 학습하는 최초의 모델
Key contributions
- retriever와 reader는 모두 NNs으로 학습할 수 있다. (=BERT)
- 오직 question-answer 쌍들로만 학습! reading comprehension dataset 사용 X!
- 어려운 검색 문제를 해결하기 위해 Inverse Cloze Task (ICT)라는 새로운 pre-training task
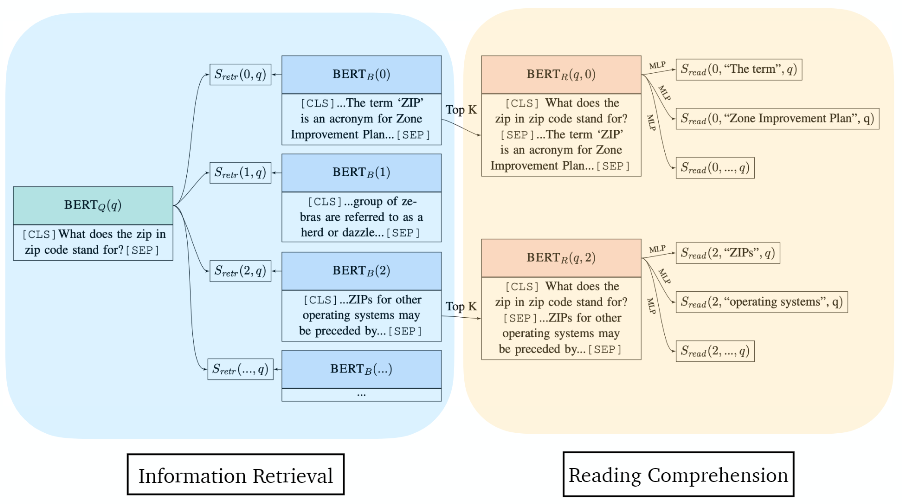
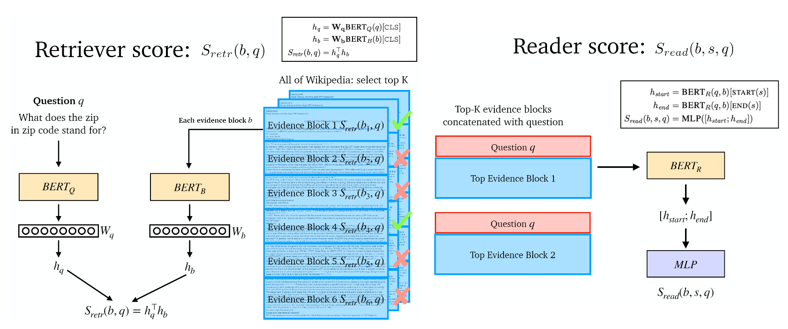
Notations
b : text block, s : b 내의 text 범위, q : 질문
Modeling: S(b, s, q) = Sretr(b,q) + Sread(b,s,q)
Inference : a* = TEXT(argmax S(b,s,q)
모델 학습 방법
Pre-training : Inverse Cloze Task (ICT)
문장을 pseudo-question으로, 문맥을 pseudo-evidence라 여긴다. 다른 랜덤 옵션들 사이에서 올바른 context를 예측하는 것이 목표이다. 여전히 모델에게 word matching 학습을 권장한다. ICT masking rate이 90%이였을 때 질문에 대한 EM 수치가 가장 높게 측정되었다.
experimental results
- TriviaQA, SQuAD에서는 BM25+BERT가 더 우수한 성능을 보였다.
- Natual Questions, WebQuestions, CuratedTrec에서는 ORQA가 더 우수한 성능을 보였다.
| TriviaQA, SQuAD | Natual Questions, WebQuestions, CuratedTrec |
|---|---|
| BM25+BERT가 더 우수한 성능 | ORQA가 더 우수한 성능 |
| question에 대한 답을 이미 알고있음 | information-seeking questions |
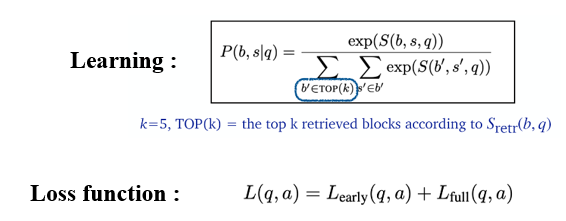
REALM: Retrieval-augmented Language Model [Guu et al., 2020]
retriever와 reader를 둘 다 pre-training한다!
- MLM pre-training
- cold start 때문에, pre-training 첫 단계에서는 ICT를 사용함
- Salient span masking : span masking과 유사하지만 named entities+dates만 mask한다.
- pre-training을 위해 Wikipedia보다 더 큰 말뭉치를 사용 (CC-News 40.4 vs Wikipedia 39.2)
- 비동기로 BERT를 update
결과적으로 NQ에서 REALM이 ORQA보다 우수한 성능을 보였다. (REALM 40.4 > ORQA 33.3)
Summary
앞의 2개의 연구(Lee et al., 2019; Guu et al., 2020)는 충분한 성능을 내기 위해서는 추가적인 사전학습이 필요하다는 한계점이 있고, Seo et al., 2019는 sparse representation을 사용하지 않아도 됨을 강조하였지만 오히려 성능의 하락을 보고하였다.
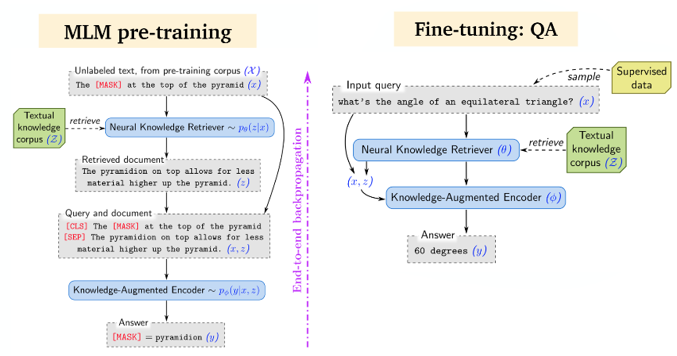
Dense Passage Retrieval(DPR) [Karpukhin et al., 2020]
Open-Domain QA의 성능을 향상시키기 위해 기존의 information retrieval(IR) 방식의 모듈을 dense retrieval(DR)로 바꾸어 사용하는 방법을 제안한다. 특히 dual-encoder 구조를 이용해서 question과 document의 dense representation을 어떻게 효율적으로 만들것인지에 대한 주제를 다룬다.
Key contribution : pre-training 없이 적은 Q/A pairs를 가지고 dense retrieval를 학습시킬 수 있다. 즉, pre-training없이 작은 데이터로 fine-tuning하는 것만으로 충분한 성능을 만들 수 있다.
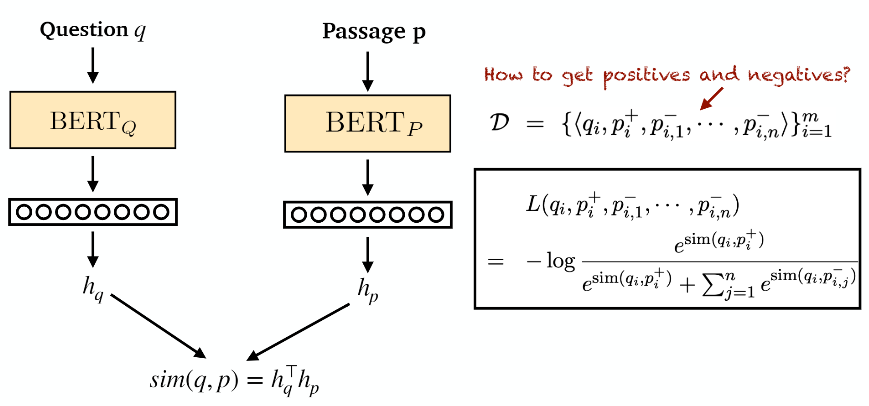
pre-trained BERT로 이루어진 2개의 encoder를 사용하여 Question q와 Passage p를 encoding하고, q와 p 간의 상관관계점수는 위와 같이 dot-product로 계산한다. 실제 추론 시에는 주어진 질의와 후보 문서들 간의 score를 계산해서 top-k개의 passage를 검색하는 방식을 사용한다.
Loss function는 주어진 후보들의 모든 score 중 실제로 관련이 있는 문서(positive sample)가 제일 높은 값을 갖도록 negative log-likelihood로 학습을 수행하게 된다. (p+ : 정답, p- : negative sample) negative sample을 만드는 방법이 학습에서 가장 중요한 요소일 것이다. 저자는 3가지 방법을 실험해 보았다. 또한 학습 시 variation으로 in-batch negative가 추가되었다.
▶ Negative sample을 만드는 방법
(1) Random : corpus 내의 random한 passage를 뽑는 방법
(2) BM25 : 실제 정답을 포함하고 있지 않지만 corpus 내의 BM25를 기준으로 top-k의 문서를 사용하는 방법
(3) Gold : 다른 질의의 positive passage
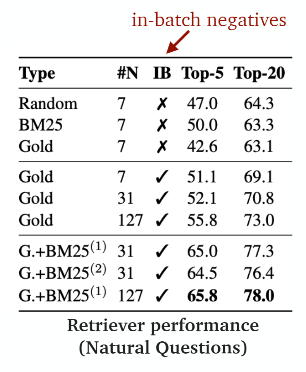
결과적으로 in-batch negative sampling을 통해 연산에 필요한 메모리 양을 줄이고, batch-size를 키운 경우에 성능이 향상되었다. 특히 BM25를 통해 뽑은 negative sample을 1~2개 추가하는 경우에 가장 높은 성능을 보였다.
결론은 random만으로 학습시키는 것도 중요하지만, 좀 어려운 sample도 답변 후보에 넣어주는 것이 긍정적인 효과를 이끌어낸다는 것이다.
▶ 실험

-
Retriever performance on NQ
retrieval를 얼마나 잘하는지를 평가하는 실험이다. 제안하는 방법이 BM25 보다 retrieval에서 우수한 성능을 보였다. -
end-to-end QA performance
제안한 retrieval로 변경하는 경우 QA task에서 얼마나 성능이 좋았는지 평가하는 실험이다. DPR이 NQ, WebQ, TREC, TriviaQA에서 BM25보다 더 나은 성능을 보였다. DPR은 더 큰 dataset(41.5 vs 39.2 on NQ)에서 REALM보다 더 나은 성능을 보였다.
※ Joint training vs pipeline training of retriever and reader → Pipeline training이 더 효율적이다. index를 한 번만 생성하면 된다.
※ Reading comprehension vs QA datasets
→ 큰 차이는 없다 (41.5 vs 41.0 on NQ)
※ BM25 + DPR이 DPR보다 약간 더 좋은 성능을 보이지만 차이는 별로 크지 않다.
Retrieval-Augmented Generation (RAG) [Lewis et al., 2020]
parametric memory와 non-parametric memory을 결합한 RAG와 범용적인 fine-tuning 방법을 제안
- parametric memory : pre-trained seq2seq model. latent document와 입력을 통해 출력을 생성함.
- non-parametric memory : DPR. 입력을 통해 latent document 제공
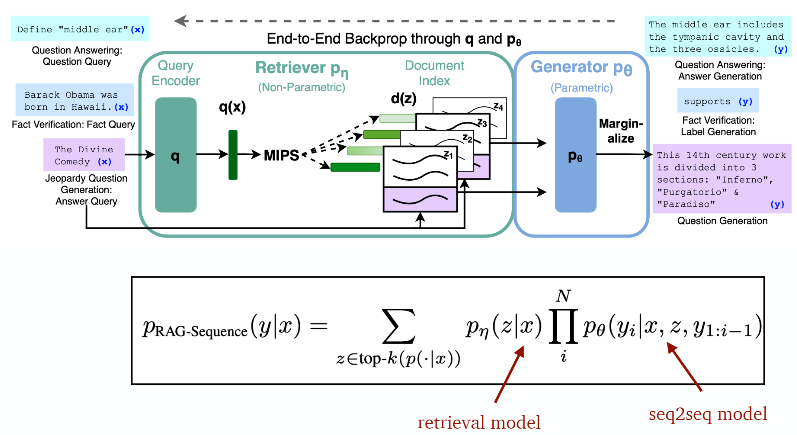
input sequence x를 사용하여 text passage z를 검색하고 target sequence y를 생성하는 RAG model
1. query x에 대해 distribution을 반환하는 parameter η을 가진 retriever p(z│x)
2. previous token y, original input x 및 retrieved passage z의 context를 통해 현재 token을 생성하는 θ로 parameterized된 generator
Retriever 및 generator를 end-to-end로 학습하기 위해 검색된 document를 latent variable로 취급한다. 생성된 텍스트에 대한 분포를 생성하기 위해 latent document를 다른 방식으로 marginalization하는 2가지 모델을 제안한다.
- RAG-Sequence Model : 동일하게 검색된 문서를 사용하여 target sequence를 생성
- RAG-Token Model : 각 target token에 대해 다른 latent passage를 사용한다. 이를 통해 generator는 답변을 생성할 때 여러 document에서 내용을 선택할 수 있다.
(c) Dense-sparse phrase indexing
DenSPI : Dense-Sparse Phrase Index [Seo et al., 2019]
key question : 문서나 문단 대신 문장 수준으로 인코딩/인덱스함으로써 retriever + reader의 "retriever" 문제를 간소화하는 것이 가능할까?
decomposability gap : 질문과 구절/답은 독립적으로 인코딩되어야 한다
확장성 : 60억 Wikipedia 구절들
DenSPI : Contextualized sparse representations [Lee et al., 2020]
- Sparc : sparse 용어에 대해 다른 가중치를 사용
- TREC +4.1%, SQuAD +4.5% 향상
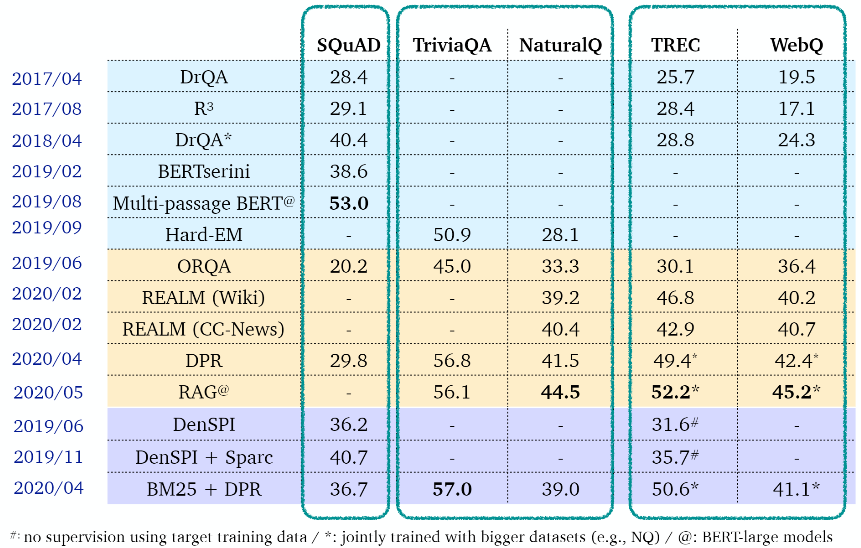
Summary
-
ORQA/REALM : 어떠한 sparse IR 요소 없이 retriever와 reader를 둘 다 학습시는 것이 가능하다는 것을 입증하였다. pre-training의 신선한 방식을 요구하였다.
-
DPR/RAG : pre-training 없이 적은 Q/A pairs만을 사용하여 dense retrieval을 학습할 수 있다
-
DenSPI/Sparc : 명시적인 "reader"를 요구하지 않고 phrase 수준에서 index화하고 검색할 수 있다. 추론 시간은 매우 빠르지만 성능은 약간 떨어진다. sparse feature는 여전히 중요하다.
7. Retriever-free approaches
No explicit retriever?
key question : pre-trained LM을 "knowledge storage"로 사용할 수 있을까?
모든 text를 명시적으로 저장하고 dense/sparse 표현으로 검색하는 대신, 답을 얻기 위해 LM을 query할 수 있을까?
Open domain QA에서 새로운 추세로 떠오르는 방법은 대규모 사전학습 모델에 기반해 내재된 지식베이스(KB)를 활용하는 것이다. 이 방식에서는 추론 시, 직접적으로 text에 접근하지 않는다. GPT-2, GPT-3, T5 같이 잘 사전학습된 모델은 zero-shot 셋팅에서 사용자의 질문에 바로 답변을 리턴한다.
- few-shot learning : 풀고자 하는 문제에 대해 몇 개의 예시만 보고 태스크에 적응하여 문제를 푸는 것. 모델의 문맥 윈도우에 넣을 수 있는 만큼 많은 예제를 넣음
- one-shot learning : 하나의 예제만을 허용함
- zero-shot learning : 예제는 사용하지 않음. task에 대해 설명 혹은 지시사항만을 모델에게 줌
GPT-2 [Radford et al., 2019]
언어를 정확히 학습했다면 finetuning 없이 zeroshot만으로 좋은 성능을 내는 것을 목적을 가진다. Transformer의 decoder 부분만을 사용하여 학습을 진행한다. 7가지 NLP task에서 SOTA를 달성하였고 특히 Generation 파트에서 뛰어난 성능을 내었다.
zero-shot setting에서 Natural Questions에서 4% 정확도를 지녔다. (supervised systems보다 훨씬 나쁜 성능)
GPT-3 [Brown et al., 2020]
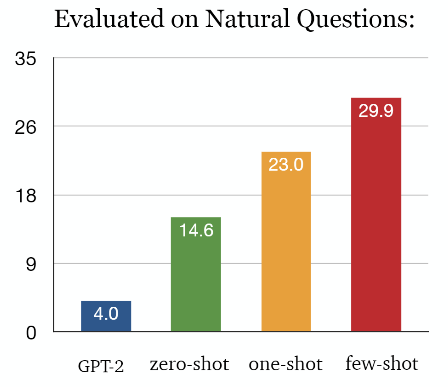
이러한 few shot learning은 대부분의 NLP 모델들이 고전하고 있는 문제 중 한 가지이다. 각종 NLP task에 대해 좋은 성능을 내고 있는 BERT, GPT 같은 모델도 성능을 내기 위해 수백, 수천 개의 예제를 가지고 fine-tuning을 해야 한다.
task와 무관하게 학습된 모델이라도, 좋은 성능을 위해서는 fine-tuning이 필요하다.
T5 [Roberts et al., 2020]

"통합 텍스트-텍스트 트랜스포머로 전이 학습의 한계를 탐구" 논문에서, T5는 encoder와 decoder를 결합한 transformer 모델이다. 모든 NLP task를 통합할 수 있도록 text-to-text 프레임워크를 사용한다. T5는 NLP task 자체를 하나의 모델로 학습할 수 있도록 하는 것이 특징이다.
T5에서는 클래스 레이블 또는 입력 범위만 출력할 수 있는 BERT 모델과 달리 모든 NLP 작업을 입력 및 출력이 항상 텍스트 문자열인 통합 텍스트-대-텍스트 형식으로 재구성할 것을 제안한다. 모든 작업은 텍스트를 모델에 대한 입력으로 사용하며 일부 대상 텍스트를 생성하도록 훈련되었다. 특히, 문서요약, 기계번역, 질문 응답을 포함한 모든 NLP 작업에서 동일한 모델, 손실 함수 및 하이퍼 파라미터를 사용할 수 있다.
8. Open-domain QA using KBs and text
Knowledge Base
- 현실의 지식을 저장한 대규모 데이터베이스
- WikiData, DBPedia
- Knowledge Graph 형식으로 지식 저장
Knowledge Graph
- 객체(entity)들 가느이 관계(Relation)가 표현된 유향 그래프
- Node : Entity (고유명사, 연도, 대표속성) / Edge : Relation
Hybrid Approach
- 문제/텍스트의 언급을 KB에 연결하는 entity linking
- 정답 분류를 위한 그래프 표현
Related Paper
- GRAFT-Net [Sun&Dhingra et al., 2018]
- PullNet [Sun et al., 2019]
- Knowledge-aware Reader [Xiong et al., 2019]
- Knowledge-Guided Text Retrieval [Min et al., 2020]
