🧠 ML/DL
1.[논문 리뷰] BERT

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova Abstra
2.활성화 함수

신경망모델의 각 layer에서는 input 값과 W, b를 곱, 합연산을 통해 a=WX+b를 계산하고 마지막에 활성화 함수를 거쳐 f(a)를 출력한다. 이렇게 각 layer마다 sigmoid, softmax, relu 등.. 여러 활성화 함수를 이용하는데 그 이유가 뭘
3.Open Domain QA Reserach
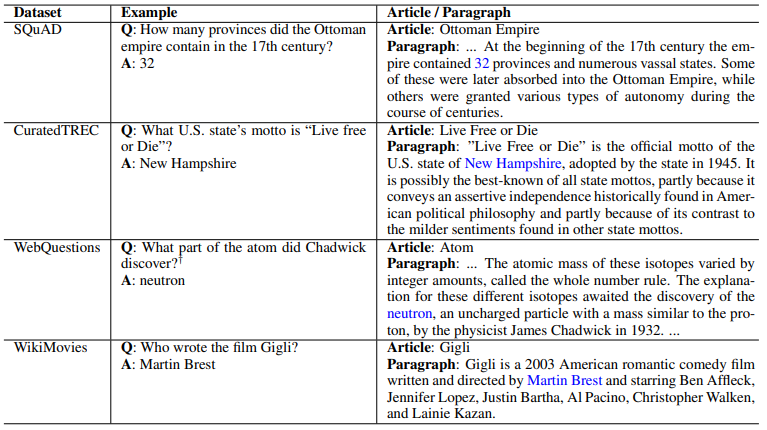
Open Domain Question Answering: 다양한 주제에 대한 대량의 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task구글에 입력된 real query에 대해 long / short / others 타입의 QAOpen-domain QA 테스트
4.ACL2020 Tutorial: Open-Domain Question Answering ver1

이 포스팅은 https://github.com/danqi/acl2020-openqa-tutorial 를 참고하여 작성하였습니다. Description Open-domain Question Answering은 다양한 주제의 대량의 문서 집합을 사용한 질의응답에 관한
5.ACL2020 Tutorial: Open-Domain Question Answering ver2

이 포스팅은 https://github.com/danqi/acl2020-openqa-tutorial 를 참고하여 작성하였습니다. (1) 지난 10년 동안 QA 시스템은 얼마나 진전을 이루었는가?(2) 현재 접근 방식의 주요 과제와 한계는 무엇인가?(3) 딥러닝
6.ACL2020 Tutorial: Open-Domain Question Answering ver3

이 포스팅은 https://github.com/danqi/acl2020-openqa-tutorial 를 참고하여 작성하였습니다. 9\. Open problems and future directions
7.What is end-to-end deep learning?

end-to-end learning은 입력에서 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리한다는 의미이다. 파이프라인 네트워크란 전체 네트워크를 이루는 부분적인 네트워크이다. 예를 들어, 기존의 Speech recognition system은 MFCC
8.ML/DL 주요 학회지

컴퓨터연구정보센터>대회안내에 날짜별, 국내/외별로 검색할 수 있으니 참고 바란다.NIPS, ICML, ICLR가 3대 학회지로 불린다.Neural Information Processing Systems매년 12월 개최최고권위 학회로 유명하며, 1987년부터 개최. 계산
9.[논문 리뷰] Seq2Seq Learning with Neural Networks
나의 Review Abstract 기존 DNN의 한계점 : sequence와 sequence를 매핑하는데 사용할 수 없음 이 논문에서는 문장 구조에 대한 최소한의 가정만 하는 sequence learning에 관한 end-to-end approach를 제시한다.
10.Regularization과 Normalization
모델에 제약(penalty)를 주는 것이다. perfect fit을 포기함으로써(training accuracy를 낮춤으로써), potential fit을 증가시키고자(testing accuracy를 높이고자)하는 것이다.오른쪽 그래프를 보면 모든 training da
11.[논문 리뷰] Attention Is All You Need
Transformer에 대해 개인적으로 궁금했던 점들
12.Autoencoders
Manifold란 고차원 space에 있는 data를 나타낼 수 있는 저차원 subspace를 말한다. 그러므로 manifold learning이란 고차원 data를 잘 아우르는 subspace가 있다는 가정 하에 학습을 진행하는 방법을 의미한다. : 입력과 출력이 동
13.Auto-regressive
Auto-Regressive Auto-Regressive스스로의 회귀자기 자신의 과거를 되돌아간다자기 자신을 입력 데이터로 하여 스스로를 예측하는 모델이전 상태의 정보를 기반하여 예측을 수행하는 모델AR model에서 현시점의 data는 이전 시점의 모든 데이터와 de
14.[논문리뷰] Pegasus (ICML, 2020)
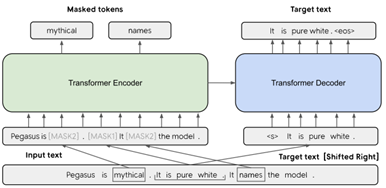
Pre-training objectives tailored for abstractive text summarization have not been exploredLack of systematic evaluation across diverse domainsLarge-sc
15.[논문리뷰] BART (ACL, 2020)
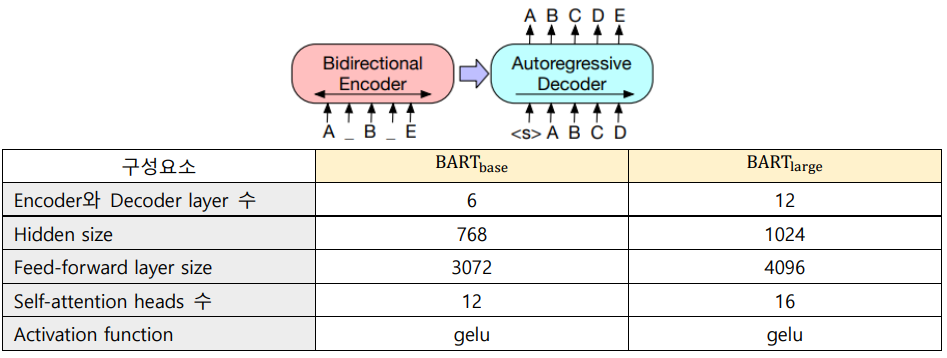
Self-supervised learning으로써 token이 무작위로 mask되었을 때 이를 복원하도록 학습시키는 Masked LM approach들이 큰 성과를 거둠 → 하지만, 현재 approach들은 특정 task(e.g. span prediction, gene
16.고유값(eigenvalue)과 고유벡터(eigenvector)란?
고유값 = eigenvalue고유벡터 = eigenvector보통 영어로 표기하지만, 아래 해석에서는 한국어로 표기함. Definition 1. A nonzero vector x is an eigenvector of a square matrix A if there ex
17."oracle" experiment란?
Notably, the Max oracle which always selects the best candidate has much better performance than the original outputs, ...by SimCLS 발췌A. Stack Overflo