
이 포스팅은 ACL 2020에서 발표한 Open-domain Qusetion Answering 를 참고하여 작성하였습니다. 실제 Tutorial 발표 영상을 보고 싶다면, T8: Open-Domain Question Answering로 이동하세요.
Tutorial 들어가기 전...
(1) 지난 10년 동안 QA 시스템은 얼마나 진전을 이루었는가?
(2) 현재 접근 방식의 주요 과제와 한계는 무엇인가?
(3) 딥러닝 시대에 효율성과 정확도를 어떻게 절충할 것인가?
Tutorial
1. Introduction
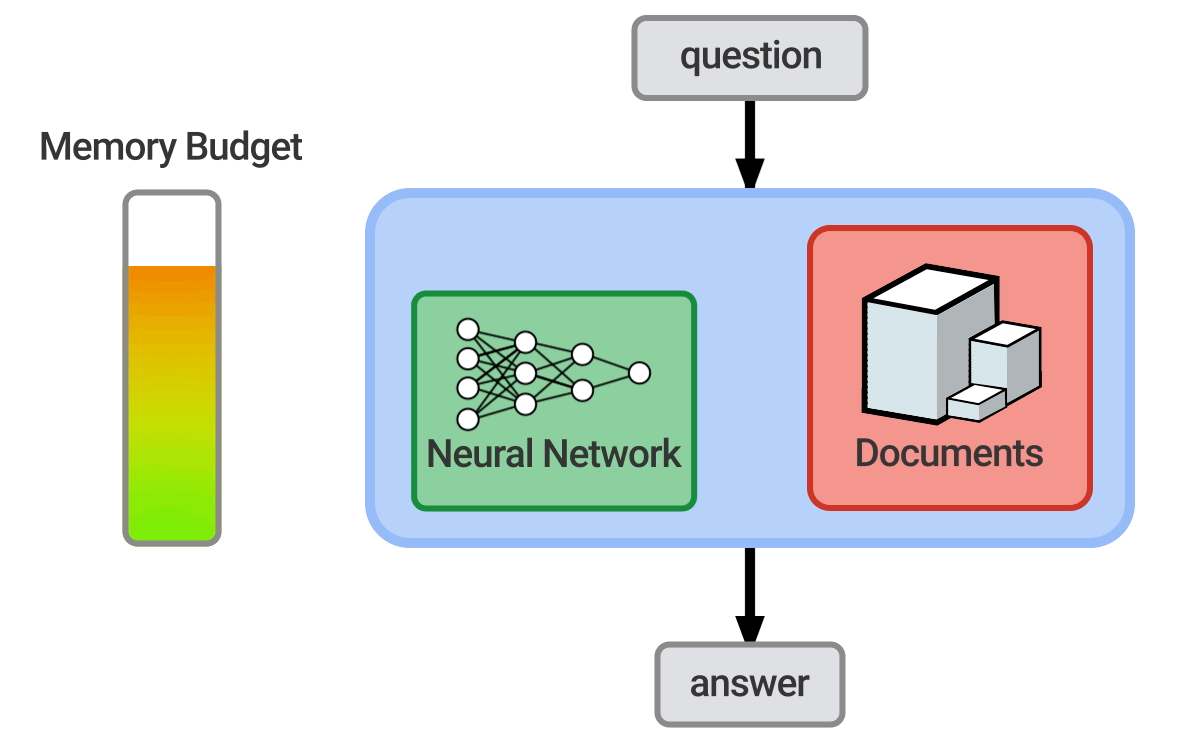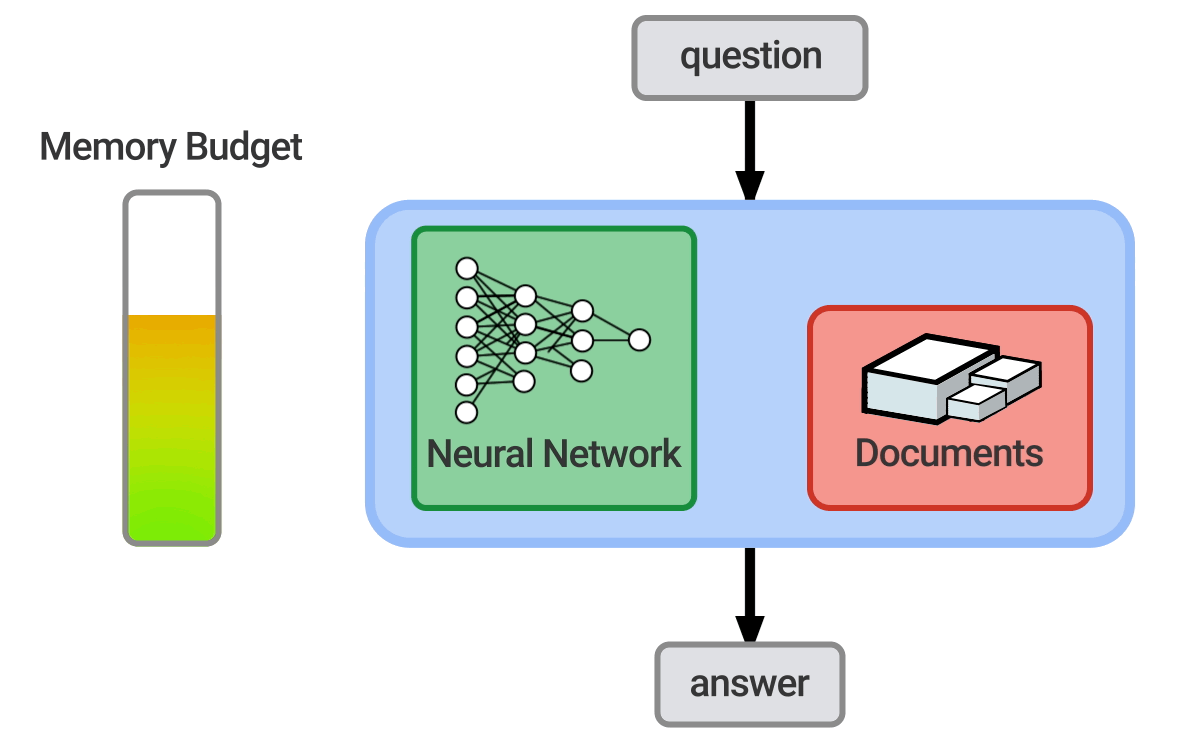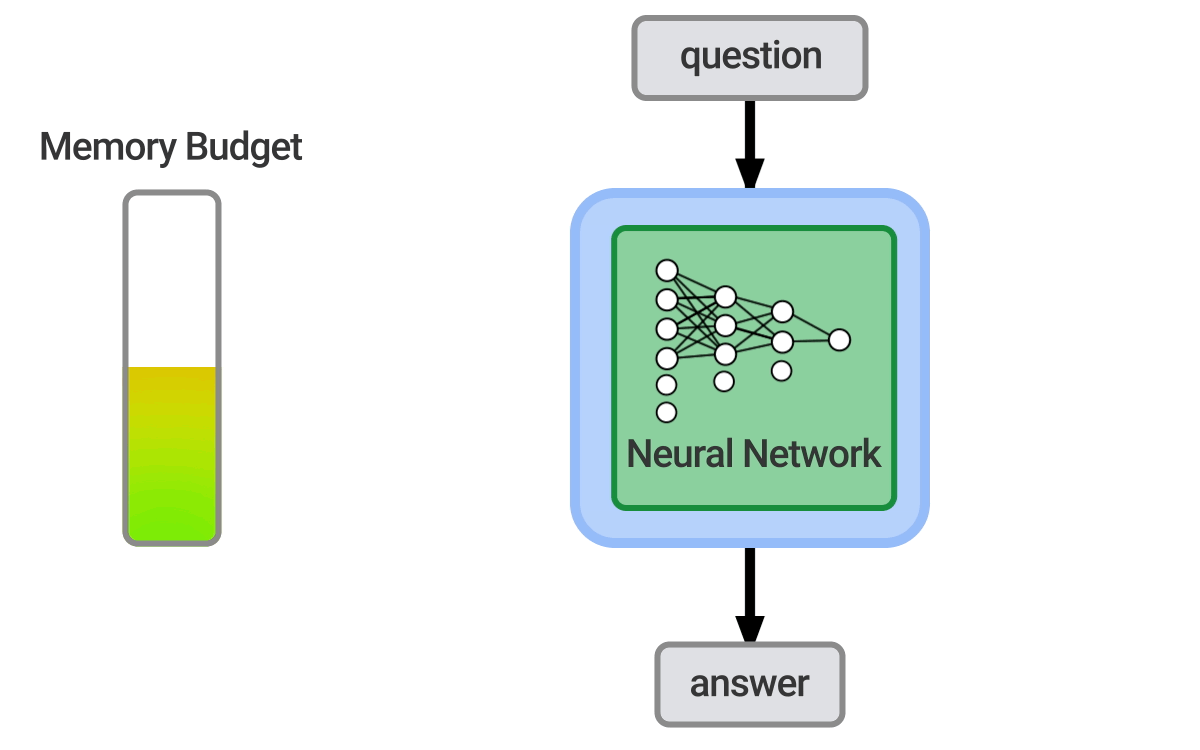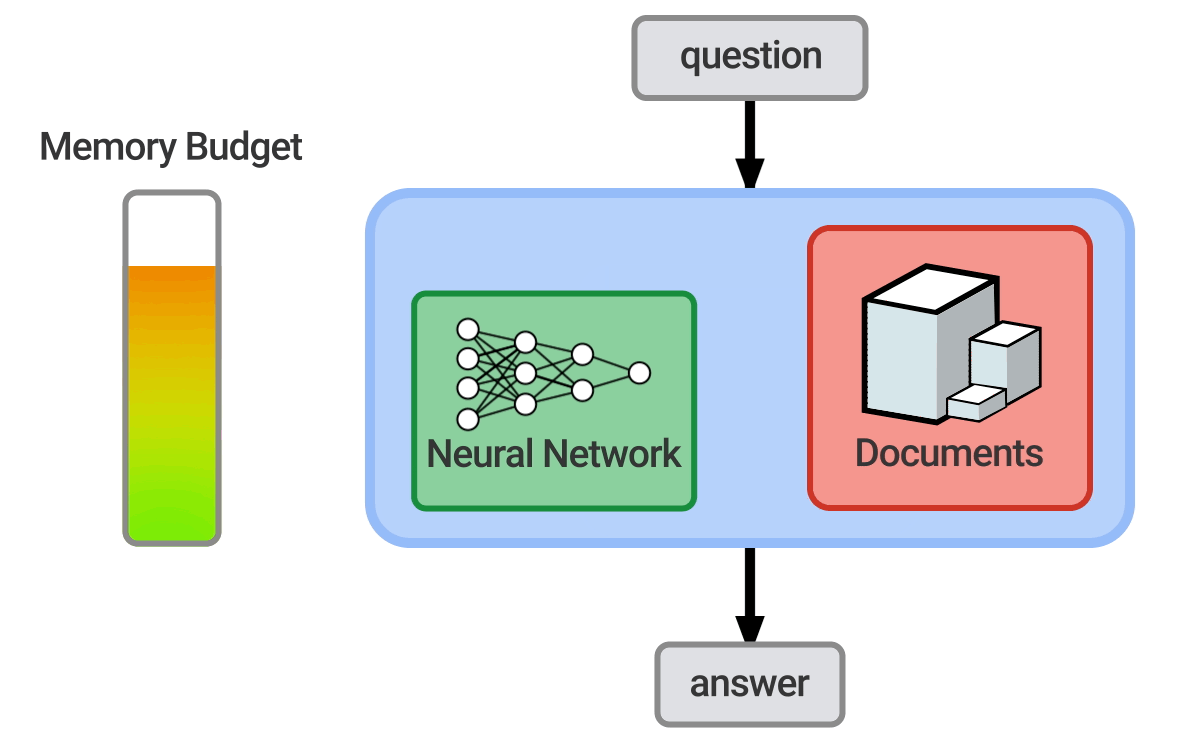
Question answering = 자연어(한국어, 영어 등)로 사람이 제시한 질문에 자동으로 대답하는 컴퓨터 시스템을 구축하는 것
Open-domain = 거의 모든 질문을 처리하고 일반적인 온톨리지와 지식에 의존
Q : Where is Einstein's house? A : 112 Mercer St, Princeton, NJ

- 이 튜토리얼에서는 open domain 텍스트 QA에 중점을 둔다.
- 6에서 KBs와 text를 둘 다 사용하는 하이브리드 접근법에 대해 다룬다.
factoid question answering
질문에 대해 짧고 간결한 정답을 반환
다른 QA 문제와는 대조적 : community QA, non-factoid or long-form QA
* 생성 대신 retrieval과 NLU에 집중

2. Problem definition & motivation
Why give this tutorial today?
2017년부터 2020년까지의 대규모 unstructured 문서에 대한 open-domain QA에 대한 새로운 기법 제시 및 패러다임
open-domain QA를 위한 기법의 변화
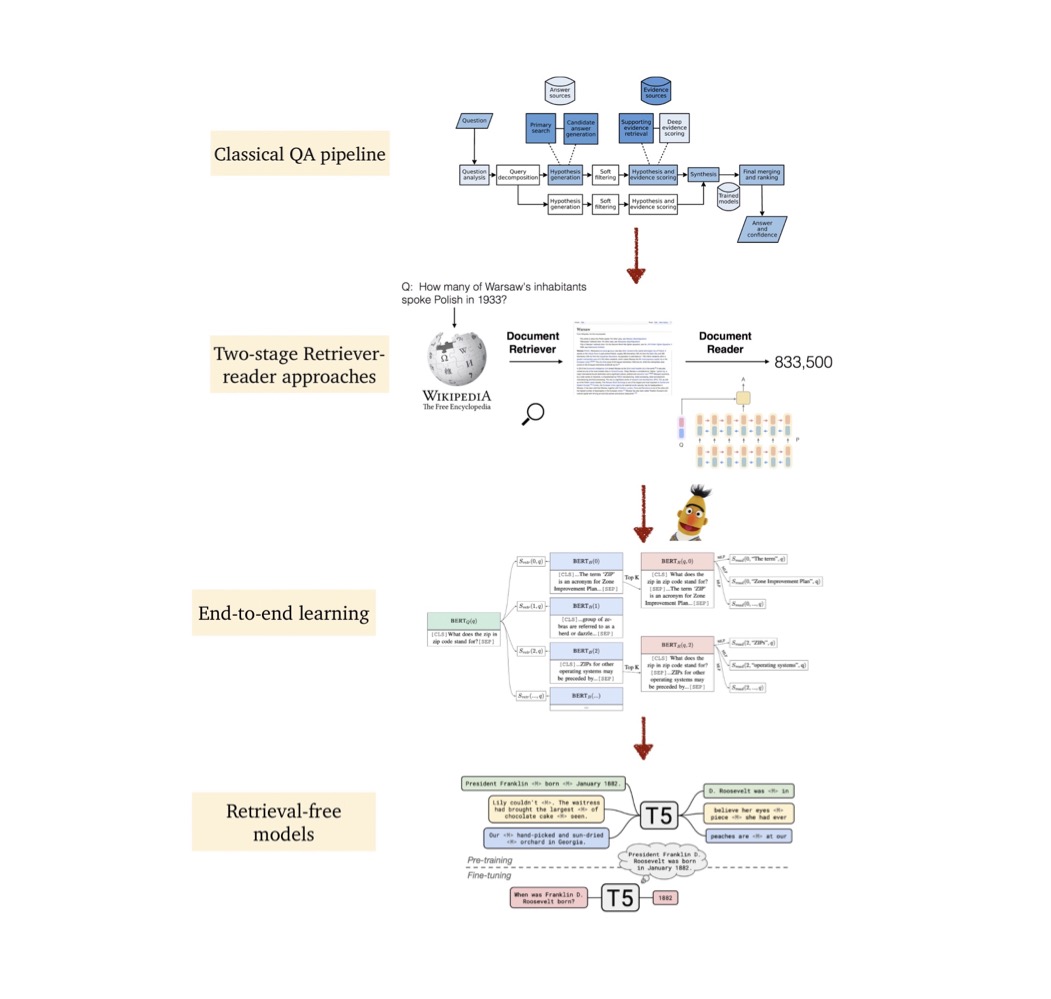
3. A history of open-domain (textual) QA
(a) Early QA systems
- Question-answering machine [Simmons, 1965]
- 자연어로 질의응답하는 일반적인 language processors
- statements 또는 questions을 다룸
| 카테고리 | 내용 |
|---|---|
| List-structured database systems | DB에서 knowldge 정리 |
| Graphic database systems | 텍스트와 그래픽 데이터(e.g. 사진, 다이어그램 등)을 동일한 논리적 표현으로 매핑 |
| Text-based systems | 답을 찾기 위해 코퍼스에서 질문과 텍스트를 매칭 |
| Logical inference systems | 텍스트 포함, 과학 교과서 질문 및 대수 단어 문제에 답하기 |
Baseball [Green et al., 1963]
Q: How many games did the Yankees play in July?-
Step1 : 간단한 dictionary-based 구문 분석
(How many games) did (the Yankees) play (in (July))? -
Step2 : "spec"를 구축하는 semantic 분석
"Who" → ("team" = ?)
Conditions (e.g., "winning","how many") → routines -
Step3 : 실행
The Picture Language Machine [Green et al., 1963]

Protosynthex [Simmons+, 1963]
- Answer questions from an Encyclopedia
- Matching questions & text in dependency logic [Hays, 1962]
Limited suceess
- Small & limited domains and scopes
- Not data-driven (대부분 rule-based)
Open questions
- Meaning representations & the need of formal langauges
- Syntactic and semantic disambiguation
- Combine parital answers from various sources
(b) TREC QA competitions
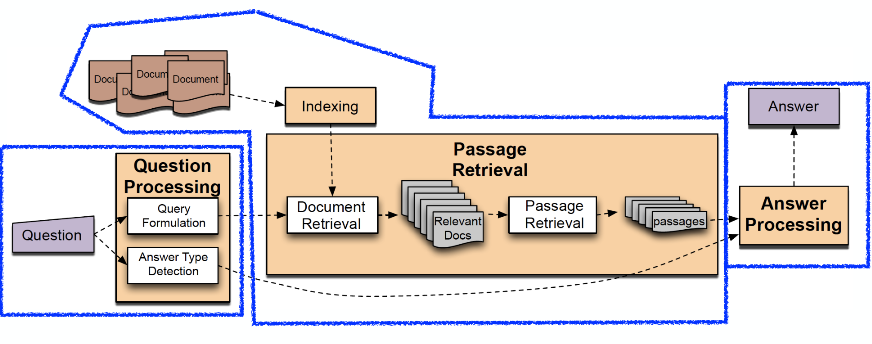
- TREC = Text Retrieval Conference
- 검색의 다음 버전으로 IR 커뮤니티에서 시작 : 관련된 문서 → 짧은 답
- 공유된 tasks & 경쟁
* corpus : newswire (AP, WSJ, LA Times, etc.); 979k articles, 3GB- Test set : 500 questions from Excite, Encarta, MSNSearch, AskJeeves
- 사람이 QA 시스템의 답 정확도를 판단
1. Query formulation
: 질문에 키워드 선택
2. Answer type detection
: answer type 종류에는 entity, human, location, numeric 등이 있다
3. Passage retrieval
: info retrieval methods을 통해 문서(document) 검색 → 문서를 문단(paragraphs)으로 쪼개어 검색 → hand-crafted features 기반 선형 ML 모델 사용하여 Passage 랭킹화/선택
4. Answer extraction/processing
: hand-crafted features + heuristics인 분류기 사용
: 문단에 answer-type named-entity tagger 실행
AskMSR : data-intensive QA
Web Redundancy(웹 중복성)을 활용. Web에서 많은 언급이 있기 때문에 "쉬운" 것들을 찾기 위해 패턴을 사용함.
예) "In what year did Abraham Lincoln die?"
- Query patterns : "Abraham Lincoln died in XXXX", "Abraham Lincoln (YYYY-XXXX)"
- 문서에서 가장 빈번한 n-gram를 답으로 사용
Observations
- 언어 모델로서의 검색 엔진
- 패턴 공식은 더이상 필요하지 않다
- head questions에는 유용하지만 끝(tail)에는 X
- 신뢰할 만한 증거를 제공하지 않는다
(c) IBM's DeepQA project
영상 : Watson and the Jeopardy! Challenge
2011년 2월 IBM의 슈퍼컴퓨터 Watson이 Jeopardy에서 인간 챔피언들을 이기는 사건이 발생했다. Jeopardy는 미국 유명 퀴즈쇼인데 대답을 제시하면 질문을 알아맞히는 이 게임에서 왓은은 역대 최강자의 인간 챔피언들을 압도했다. 인간처럼 생각할 수 있을 뿐만 아니라 속도와 정확성에서 인간을 능가했다.
IBM Waston Deep QA architecture
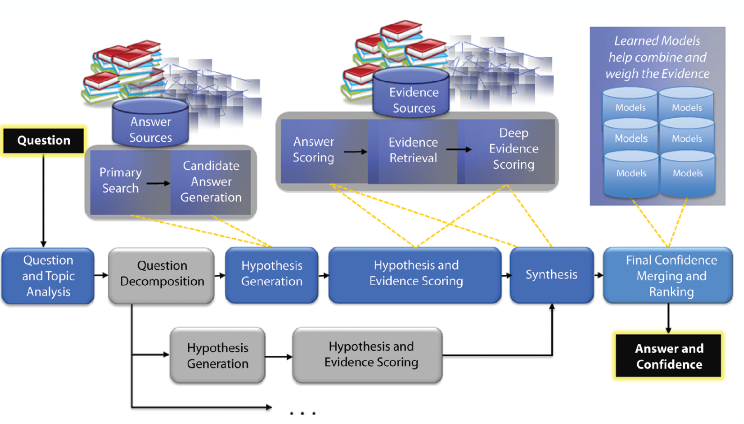
Minimal DeepQA pipeline
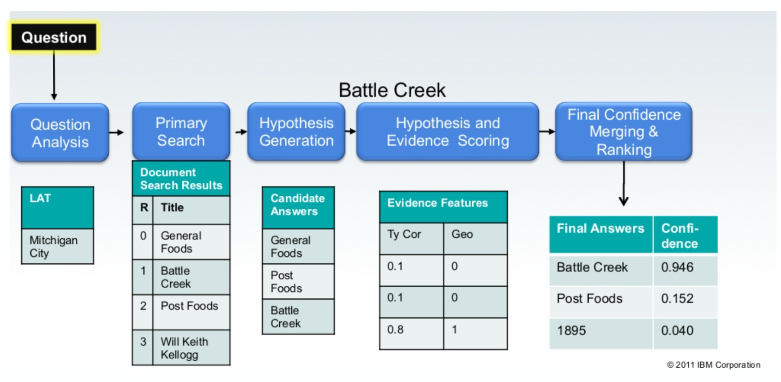
IBM Watson DeepQA의 성공
왜 가능했을까?
- 강력한 엔지니어링 지원을 기반한 대규모 팀 작업
- Jeopardy 퀴즈쇼의 질문은 사실 대답하기 쉬움
- 위키피디아는 진부한 질문에 대한 중요한 자원임
영향
AI의 중요한 이정표로 인심됨
QA 연구에 대한 흥미를 다시 불러일으킴
(d) More recent developments : 2013+
2개의 목표 1) AI 지능을 테스트 (MRC) 2) 사용자 정보 요구를 만족시키는 것
- Machine Comprehension Test [Richardson et al., 2013]
- Standford QA Dataset (SQuAD) [Radjpurkar et al., 2016]
- Reading Comprehension : RACE [Lai et al., 2017], DuoRC [Saha et al., 2018]
- Fill-in-the-blank questions : DeepMind Q&A Dataset [Hermann et al., 2015], Facebook Children Stories [Hill et al., 2016]
- Reasoning challenges : Facebook bABI [Weston et al., 2015], AI2 ARC [Clark et al., 2018], Multi-RC [Khashabi et al., 2018]
- Multi-turn questions : SQA [Iyyer et al., 2017], QuAC [Choi et al., 2018], CoQA [Reddy et al., 2019]
- Multi-hop questions : HotpotQA [Yang et al., 2018], OBQA [Mihaylov et al., 2018], QASC [Khot et al., 2020]
4. Datasets & evaluation
(a) Reading comprehension vs QA datasets
dataset의 역할
- task를 근산화하기 위해 dataset을 사용한다
- model 학습과 평가를 위해 좋은 품질의 데이터가 필요 (공정한 비교, 재현 가능한 결과)
Open-domain QA Dataset에 관한 우려사항
그럼 질문과 답의 출처는 어디서 오는걸까?
정답의 정확성은 어떻게 정의하지?
뒷받침하는 증거를 제공해야 하나?
다양한 데이터 사용법/구성

Datasets & Evalutation

(b) Categorization of QA datasets
TriviaQA

SearchQA

Quasar-T

Natural Questions

(c) Evaluation metrics
어떤 Question-answer pairs도 사용될 수 있다. 단, Wikipedia 내에 답변이 없을 수 있고 답을 포함한 문단이 증거를 뒷받침하지 않을 수 있다.
Open-Domain QA Datasets used in ORQA
- Natural Questions
- WebQuestions [Berant et al., 2013]
- CuratedTREC [Baudis & Sedivy, 2015]
- TriviaQA
- OpenSQuAD [Rajpurkar et al., 2016]
다음 내용은 ACL2020 Tutorial: Open-Domain Question Answering ver3에서 이어집니다.

도움이 되었어요!! 감사합니다 😂