Problem
- Pre-training objectives tailored for abstractive text summarization have not been explored
- Lack of systematic evaluation across diverse domains
- Large-scale document-summary datasets are rare → the most common setting is low-resource summarization (low-levels of supervision, very-little supervision)
Solution
- study a new self-supervised pre-training objective - GSG specifically for abstractive summarization
- Pegasus_large model equals or exceeds SOTA on 12 diverse summarization tasks
- Pegasus_large obtains SOTA results in 6 datasets with only 1000 examples (low-levels of supervision)
Pre-training Objective for summarization
Gap Sentences Generation (GSG)
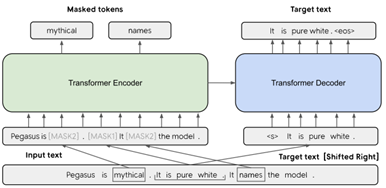
Hypothesize that using a pre-training objective that more closely resembles the downstream task leads to better and faster fine-tuning performance
- select and mask whole sentences from documents
- concat the gap-sentences into a pseudo-summary
- the corresponding position of each selected gap sentence is replaced by a mask token [MASK1] to inform the model
▶ Gap sentences 선택 방법 (GSG의 ①번 stage)
Gap sentences(document 내 important/principal sentences)를 30% 선택함
6가지 variants = Lead, Random, Ind-Orig (Best), Ind-Uniq, Seq-Orig, Seq-Uniq
Experiments
▶ Pre-training Corpus

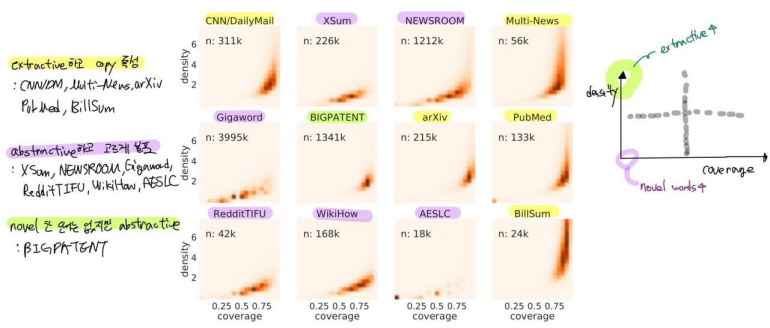
▶ Downstream Tasks/Datasets : XSum, CNN/DailyMail, NEWSROOM, Multi-News, Gigaword, arXiv, PubMed, BIGPATENT, WikiHow, Reddit TIFU, AESLC, BillSum
※ Appendix에 제시된 12가지 downstream tasks의 특성
▶ Pegasus_base(223𝑀 𝑝𝑎𝑟𝑎𝑚𝑠), Pegasus_large(568𝑀 𝑝𝑎𝑟𝑎𝑚𝑠)

Effect of pre-training corpus (Pegasus_base)
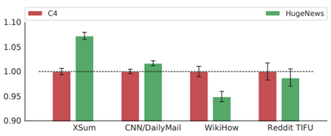
- HugeNews로 pre-trained model은 news datasets(XSum, CNN/DM)에서 더 높은 성능을 보임
- C4로 pre-trained model은 non-news informal datasets(WikiHow, Reddit)이 더 높은 성능을 보임
→ pre-training models은 domain이 aligned되어 있을 때 더 효율적으로 transfer learning을 수행한다
Effect of pre-training objectives (Pegasus_base)
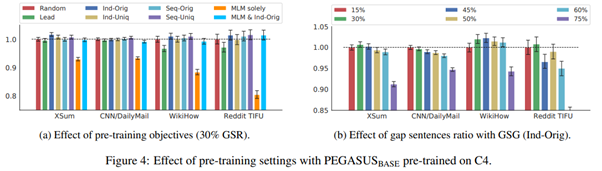
- GSG에서 Ind-Orig가 가장 best performance를 보임
- best performance로 측정된 GSR(Gap Sentence Ratio)는 모두 0.5 이하
- MLM(Masked LM)을 단독으로 사용할 경우 현저하게 성능 저하됨 (초기 100k ~ 200k steps시 fine-tuning 성능을 향상시키지만, 500k steps으로 갈수록 추가적인 이득을 억제함)
→ GSG는 Ind-Orig, GSR은 0.3, MLM 제외를 Pegasus_large model에 적용
Effect of vocabulary (Pegasus_base)
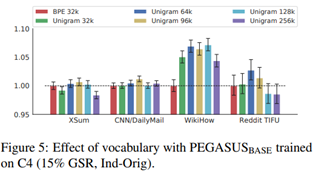
- SentencePiece Unigram이 Byte-pair-encoding(BPE)보다 더 효과적임 (Unigram 96k on XSum/CNNDM, Unigram 128k on WikiHow, Unigram 64k on Reddit TIFU)
→Pegasus_large에 Unigram 96k를 사용함
Larger Model Results (Pegasus_base, Pegasus_large)
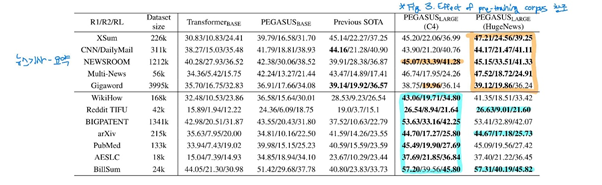
Pegasus_base 실험에서 얻은 hyper-parameter로 Pegasus_large에 적용하였을 때, 이전 - SOTA 대비 모든 downstream task에서 SOTA를 달성함
- Small dataset (Multi-News, Reddit, AESLC, BillSum) 대부분인 pre-training으로부터 큰 이점을 얻음

느리지만 확실하게 🐢