Problem
Self-supervised learning으로써 token이 무작위로 mask되었을 때 이를 복원하도록 학습시키는 Masked LM approach들이 큰 성과를 거둠
→ 하지만, 현재 approach들은 특정 task(e.g. span prediction, generation etc)에만 주력하여 범용성(applicability)가 떨어진다는 문제점이 있음
Model Architecture
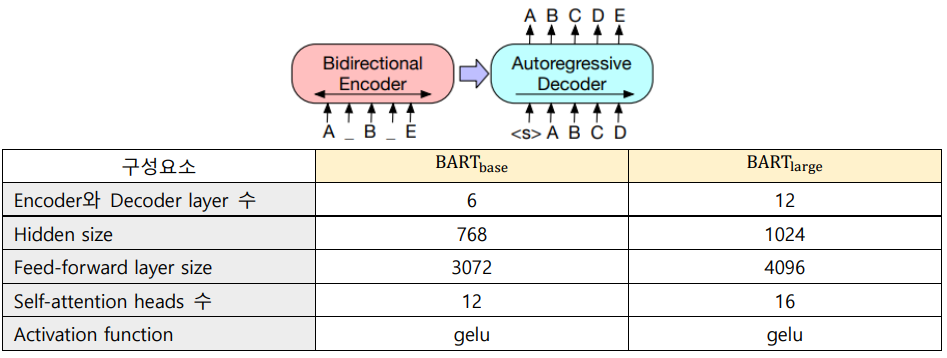
BART : Bidirectional and Auto-Regressive Transformers (Seq2Seq model)
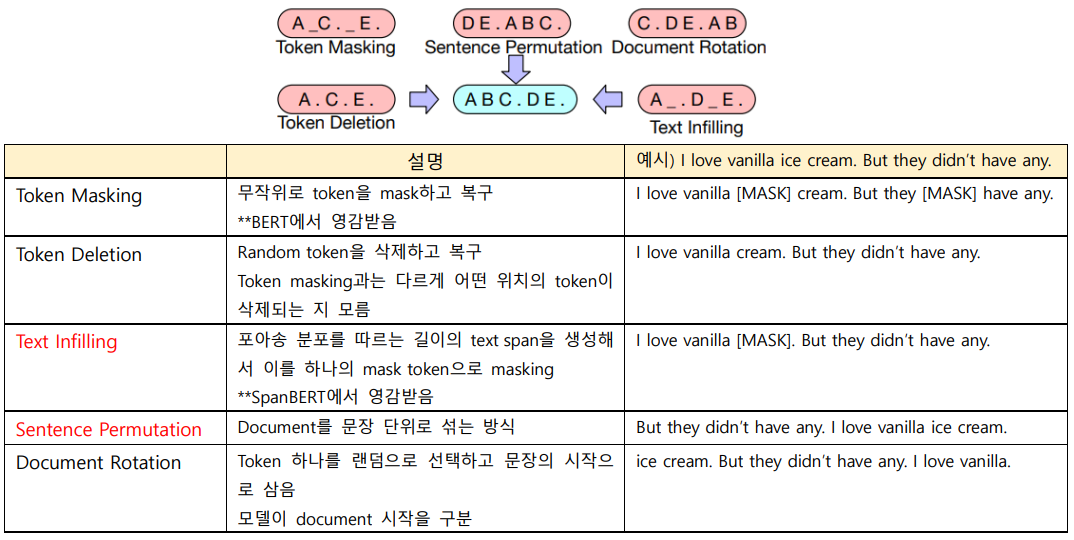
Noise function에 의해 text를 손상시키고 이를 복원하는 task로 pre-training함 (denoising autoencoder)
pre-training BART
5가지 noising task에 대해 실험
Fine-tuning BART
Comparing pre-training objectives
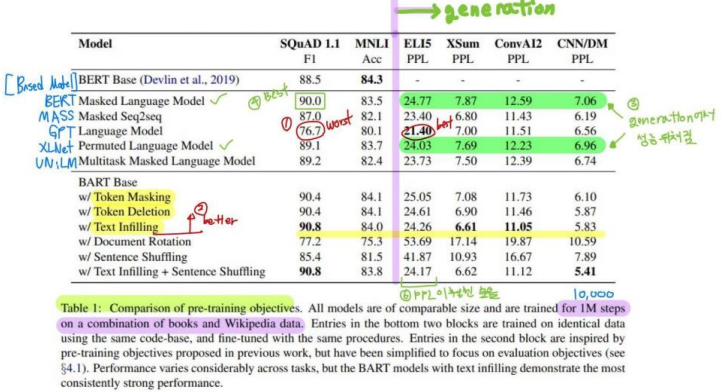
1) pre-training methods의 성능은 task에 따라 크게 다르다
Ex) Language Model, best score 21.40 PPL on ELI5 and worst score 76.7 F1 on SQuAD
2) Token masking은 중요하다
Document Rotation과 Sentence Shuffling은 Token Masking, Token Deletion, Text Infilling보다 훨씬 안좋은 성능을 보임
3) Left-to-right pre-training은 generation 성능이 좋다
Masked LM과 Permuted LM은 다른 generation task에서 성능이 뒤처짐
4) SQuAD에서 Bidirectional encoders는 중요하다
SQuAD에서 Language Model은 Masked LM보다 -3.3 F1 score가 낮음
5) Pre-training objective만 중요한 요소는 아니다
Permuted LM은 XLNet보다 성능 안 좋음 → XLNet의 relative-position embeddings 또는 segment-level recurrence 같은 다른 아키텍처 향상 기법 포함을 안 했기 때문일 것임
6) Pure language model이 ELI5에서 가장 성능이 좋다
ELI5 (long-form abstractive QA task)가 이상치(outlier)인 것 같음. (다른 task보다 훨씬 높은 PPL. 다른 models이 BART를 이긴 유일한 task이다)
7) BART는 일관성있게 강한 성능을 보였다
Experiments
RoBERTa와 비슷한 규모가 되도록 setting (encoder/decoder 12 layers, hidden size 1024
Text infilling과 Sentence Permutation으로 pre-training 진행
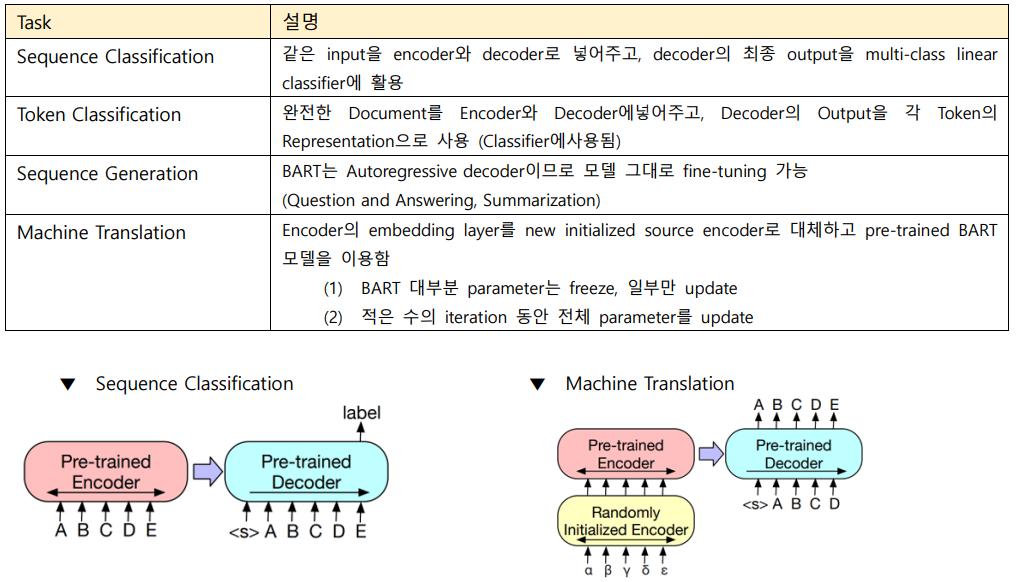
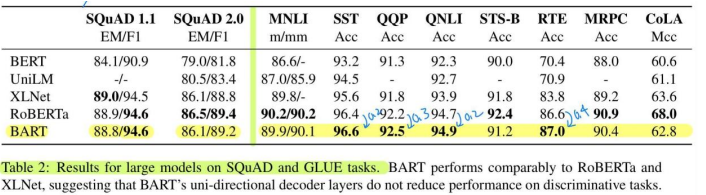
Discriminative Tasks
전반적으로 대부분의 task에서 약간 낮거나 비슷한 성능을 보임
Generation Tasks
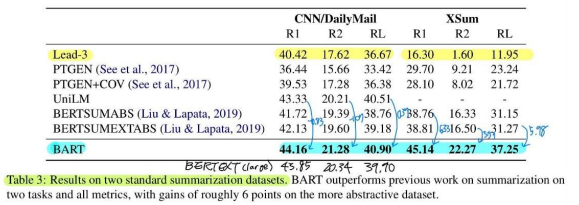
Summarization, Dialogue, Abstractive QA, Translation 모두 SOTA 달성. 특히, Summarization task에서 +6 points라는 엄청난 성능 향상을 보임