✔ Regularization
모델에 제약(penalty)를 주는 것이다. perfect fit을 포기함으로써(training accuracy를 낮춤으로써), potential fit을 증가시키고자(testing accuracy를 높이고자)하는 것이다.
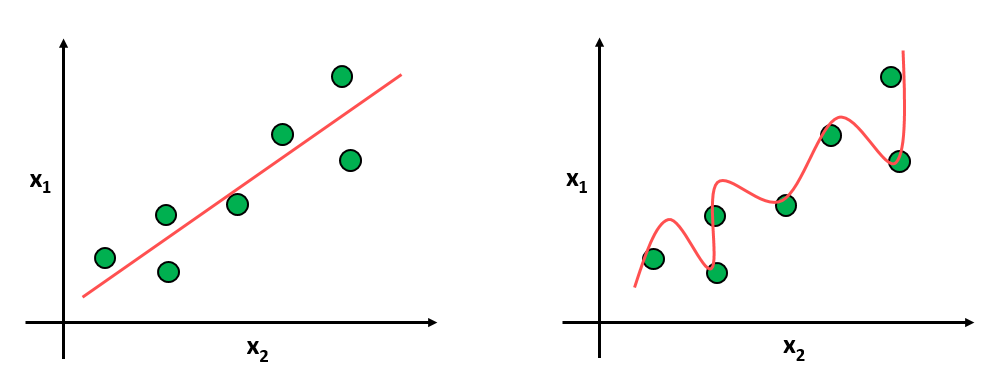
오른쪽 그래프를 보면 모든 training data에 대해서는 완벽하게 fitting되어 있다. 하지만 이 모델은 일반적으로 적용했을 때 올바른 output을 도출하지는 못한다. 요약하자면, 데이터에 너무 과적합되어 모델이 fitting되었으니, 새로운 데이터에도 일반적으로 들어맞는 모델이 만들어내자는 취지에서 Regularization 기법이 등장하였다.
대표적으로 dropout, early stopping, weight decay 등이 있다. 이 방법들 모두 training할 때 모델에게 제약을 거는 방법들이다.
Dropout
해결하려는 문제점 : overfitting
- training dataset에 대해서는 정확도가 매우 높지만, test dataset에서는 낮은 정확도를 보이는 현상
- 즉, 과도하게 training dataset에 대해 모델이 학습한 경우를 말한다
해결책 : dropout
- 신경망의 일부 노드를 랜덤하게 사용하여 학습하는 방법
- pytorch : dropout
# p : 노드를 얼만큼 활용 안 할지 정하는 비율 (default 0.5)
dropout = torch.nn.Dropout(p=drop_prob)
### train
model.train() # 학습 모드에서는 dropout 사용
for epoch in range(training_epochs):
...
### test or validation
with torch.no_grad():
model.eval() # test나 valid에서는 모든 node를 사용L2 Regularization
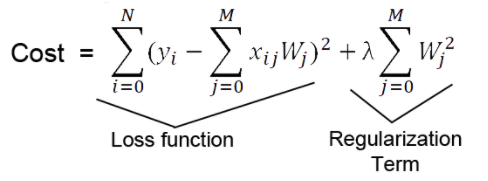
줄이고자 하는 것은 loss funtion의 값이다. 그렇지만 cost가 줄어든다고 무조건 좋은 것인가 하면 그건 또 아니다. 왜냐하면 overfitting이 일어나고 있어서 training data에만 맞춰지는 중일지도 모르기 때문이다.
따라서 기존 cost function 뒤에 추가시켜준 것이 Regularization Term이다. cost를 줄이는 것이 특정 parameter를 엄청 크게 만들어주면서 error를 줄이나면 그것은 하지 않겠다.라는 것이 위의 regularization term의 역할이자 의미이다. term이 커지면 그만큼 앞의 loss function이 cost를 줄인 것을 상쇄시켜 버린다. 왜냐하면 특정값이 너무 커져버린다는 것은 곧 overfitting이 일어나고 있다는 의미가 되기 때문이다.
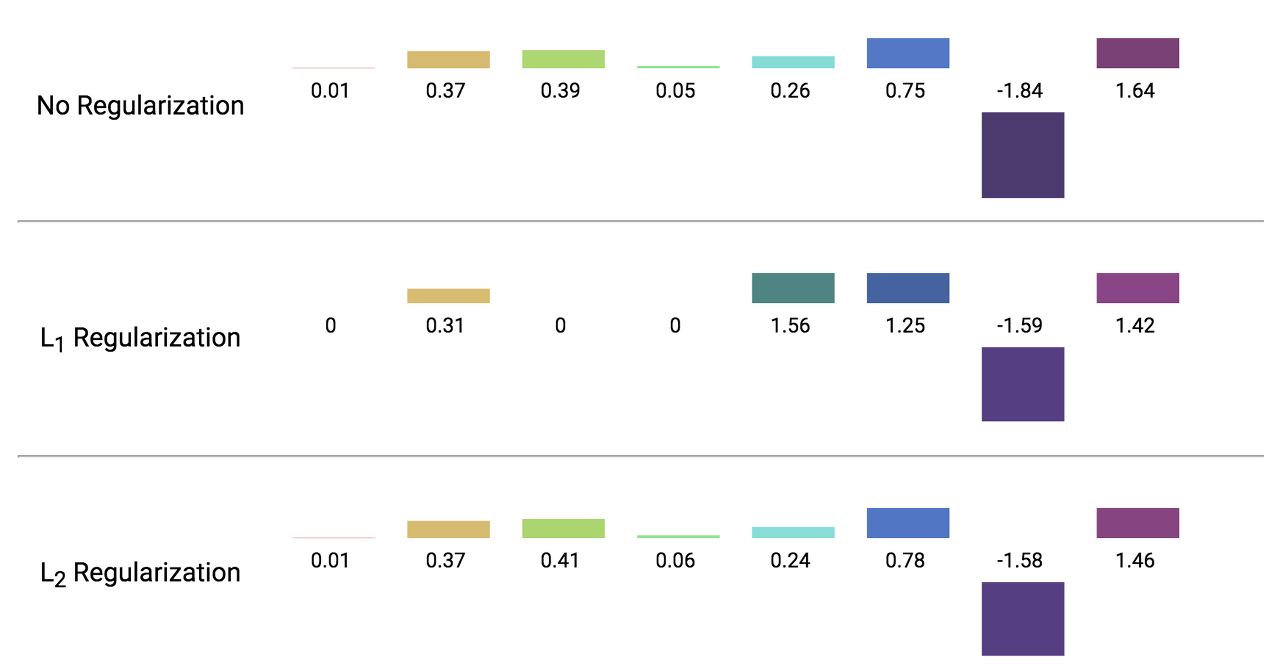
L1 Regularization (Lasso)
- Feature selection : 파라미터값을 0으로 보내기에 변수 제거의 효과가 있음
- 영향을 크게 미치는 핵심적인 feature만 반영함
L2 Regularization (Ridge)
- 전체적으로 파라미터 값이 작아지도록 함
▼ 출처 : https://dailyheumsi.tistory.com/57
✔ Normalization (정규화)
Normalization은 데이터의 범위를 사용자가 원하는 범위로 제한한다. 즉, Normalization은 데이터를 scaling하기 위해 사용한다. 예를 들어, 이미지의 경우 픽셀이 0부터 255 사이의 값을 가지는데, 이를 255로 나누어주면 0.0 ~ 1.0 사이의 값을 가지게 된다. (feature scaling)
Standardization (표준화)
정규화 방법 중 하나로 표준화가 있는데, 표준화는 표준정규분포를 갖게 하고 싶으면 데이터의 평균과 표준편차를 사용하면 된다.
왜 사용할까?
Normalization는 optimial soultion으로써 parameter의 수렴속도가 빨라진다는 것이다.
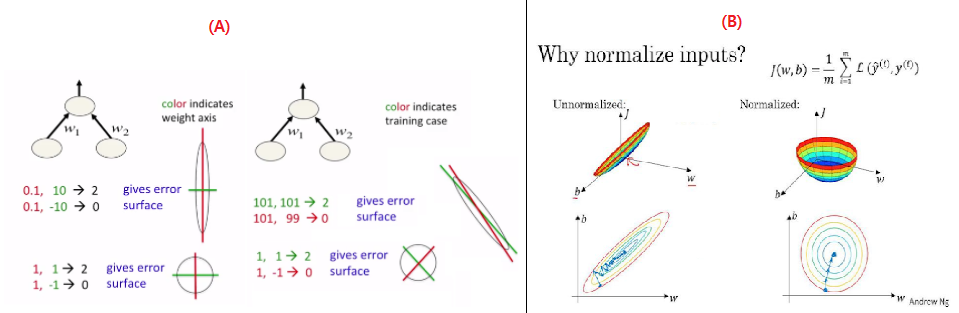
(A)에서 loss를 w1,w2를 축으로 하는 parameter space로 표현하고, optimal이 원점에 있다고 가정하자. 정규화 전에는 loss function의 형태가 Elongated(가늘고 길죽한)되어 있지만 정규화 후에는 spherical(구 모양)으로 바뀌었다. (B)처럼 parameter space가 spherical일 때, 즉 정규화를 했을 때 optimal solution을 더 빠르게 찾아간다는 것이다.
딥러닝에서의 normalization
딥러닝은 input layer에서 정규화된 값을 입력하더라도, weighted sum과 activation function을 거치면서 다시 비정규화된 형태로 parameter space가 변경될 것이 분명하다. 이때 가 각 노드별로 다시 normalization을 해줄지, 혹은 표준정규분포를 갖게 해줄지, 아니면 layer들을 묶어서 모든 node가 같은 scale을 갖게 정규화 해줄지 선택지가 있다. 하지만, 어떤 기준을 삼느냐에 따라 정규화 방법이 달라질 순 있지만 원리는 거의 비슷하다.
참조
