- 논문 : https://arxiv.org/abs/1706.03762v5
- 인용횟수 : 37111회 (2022년 3월 기준)
- 날짜 : 2017년 7월
- 학회 : NIPS
💁🏻♀️ My Review
2017년 Google에서 Attention Mechanism만을 사용한 encoder-decoder 구조의 새로운 언어모델 Transformer를 제시하였다. Transformer는 Residual connection을 갖는 feedforward network에서 중간에 attention mechanism을 사용한 모델이며, 다음과 같이 핵심 요소 3가지가 있다.
- multi-head attention
- scaled dot-product attention
- positional encoding
가장 인상 깊었던 점은 self-attention 기법만으로 문장의 context를 뛰어난 이해를 보였고 representation 성능을 높였다는 점이다. 최근 NLP의 SOTA LM들은 대부분 Transformer 기반이라는 점을 꼭 알아두자
- BERT - Transformer Encoder 사용
- GPT - Transformer Decoder 사용
궁금했던 점
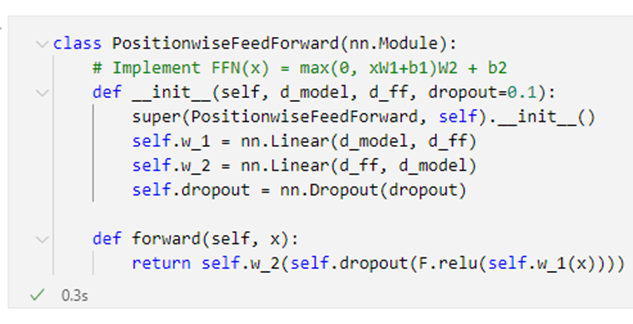
1. FeedForwad Network를 왜 사용하는가?
차원을 늘리는 과정에서 더 많은 연산을 수행해서 크게 확장하기 때문에 숨겨진 내용을 찾을 수 있다.
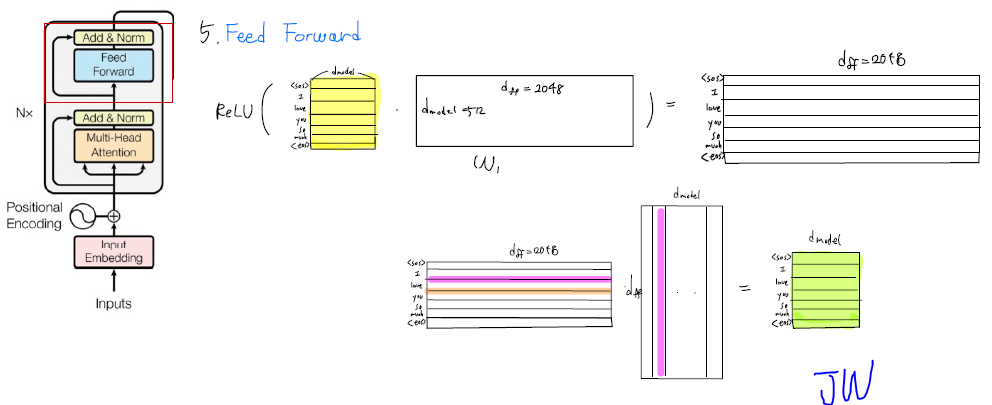
2. 왜 position-wise FeedForward Network라고 하는가?
실제로 코드를 봤을 때는 일반 FeedForward Network은 차이는 없었다.
그러면 굳이 왜 position-wise(=element-wise)라고 했을까? 저자가 다른 관점에서 생각하여 각 token(position)이 각자의 weight로 계산되어 커지고 작아지는 연산이 수행된다는걸 강조하고 싶었던 게 아닐까라고 추측한다.
3. residual connection과 layer normalization은 무엇이고 왜 하는건가?
residual connection이란 잔차 연결로, weight layer를 통과한 F(x)와 weight layer를 통과하지 않은 x의 합을 지칭한다.
왜쓸까?
x+F(x)를 x로 미분하면 최소 gradient를 1로 갖게된다. 따라서 layer가 아무리 깊어도 최소 gradient가 1 이상 가지기 때문에 vanishing gradient 문제를 완화한다.
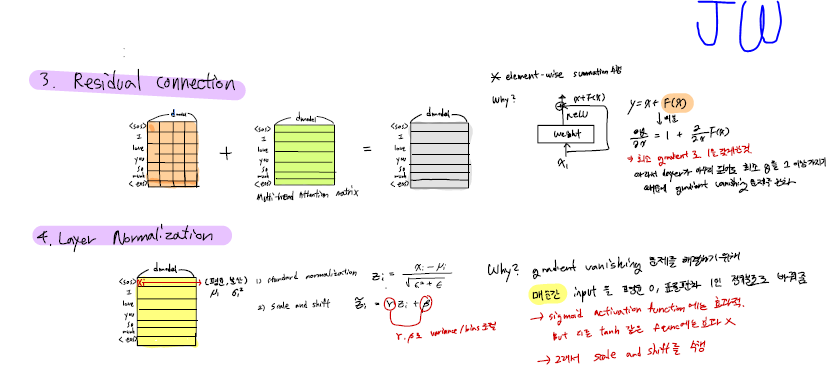
layer normalization은 vanishing gradient 문제를 해결하기 위해, 매순간 input을 평균 0, 표준편차 1인 정규분포로 바꿔준다. 그리고 variance와 bias를 조절할수 있는 scale and shift를 수행한다.
왜쓸까?
아무리 input layer에서 정규분호를 가지는 입력을 줘도 hidden layers를 지나면서 그 분포가 저점 정규분포를 벗어나게 된다. 치우친 상태에서 backpropagation을 하게 되면 대부분의 분포가 gradient가 0인 부분으로 치중되기 때문에 vanishing gradient 문제가 발생한다. 따라서 vanishing gradient를 완화하기 위해 layer normalization를 사용한다.
4. positional encoding은 정확히 무엇인가?
Sin, cos 함수를 사용하여 각 token마다 (1, 𝑑_𝑚𝑜𝑑𝑒𝑙) 크기의 위치 벡터를 생성하는 것이 positional encoding이다.
왜 필요한가?
RNN이 단어의 position에 따라 단어를 순차적으로 입력받아서 처리하기 때문에 각 단어의 위치 정보를 가질 수 있었다. 하지만, Transformer는 단어를 순차적으로 입력받지 않는다. 그래서 Transformer의 encoder와 decoder에게 문장의 순서 정보를 주기 위하여 positional encoding을 사용한다.
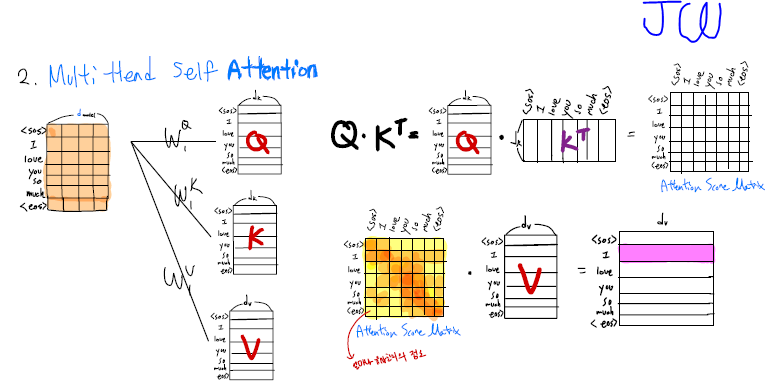
5. Attention Mechanism을 하는 이유는 무엇인가?
Self-attention 즉 자기 자신 위치에서 문장 내 다른 token들과의 유사도를 비교하여(dot product) 의미론적으로 가까운 token을 찾기 위해 attention mechanism을 사용한다. 그러므로, Attention mechanism을 하는 이유는 입력 문장의 각 token에서의 어떤 token으로의 의미가 집중(attention)되는지 알 수 있다. 그래서 encoder layers가 깊을수록 자기 자신의 token이 주변 token들과의 attention이 높아지는 걸 확인할 수 있다.
의미론적으로 가까운 token이 무엇일까?
- 의미나 뜻이 유사한 token을 말하며, 이러한 token들은 벡터 공간 상 가까운 거리에 위치해있다.
- 너무 - 엄청
- 푸르다 - 파랗다
- 영국 - 잉글랜드
- 궁핍하다 - 가난하다
그러면 실제로 pre-trianed Transformer Encoder의 Multi Head Attention Layer에서 각 head 에 대한 attention score matrix를 시각화를 수행해보면 어떨까?
-
사용한 pre-trained model
- OpenNMT 에서 공개한 pre-trained Transformer
- Attention Is All You Need 에서 공개한 Transformer base model 과 아키텍처 , 학습방법 , 사용한 Machine Translation dataset 이 동일함 (BLEU 26.89)
- Dataset : WMT 2014 English German dataset -
input : The log file can be sent secretly with email or FTP to a specified receiver
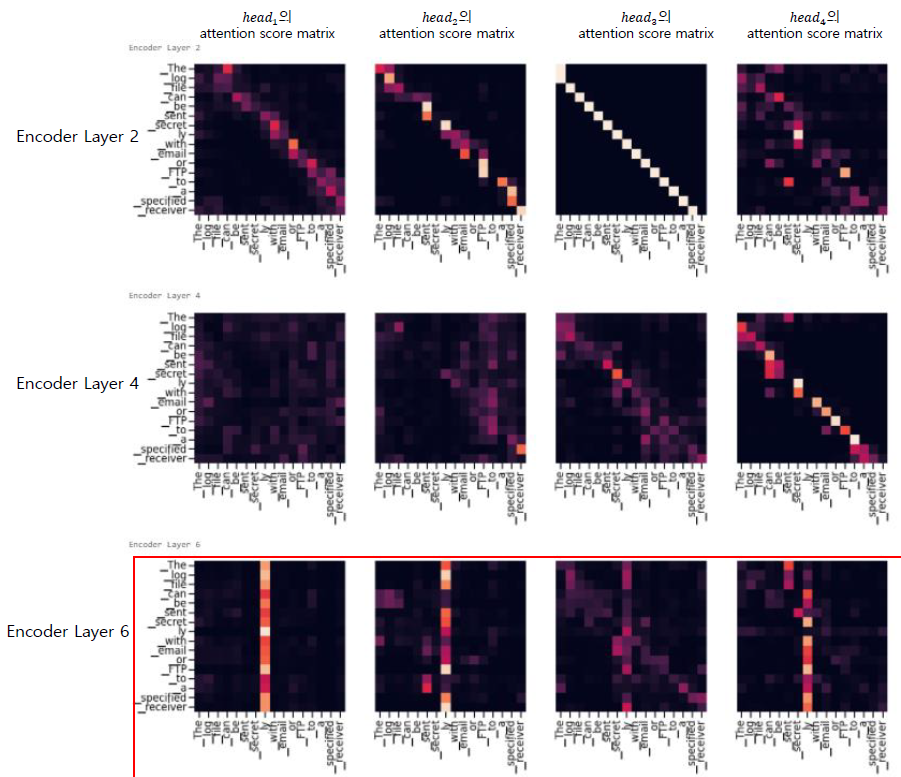
- 결과
- Encoder layer 를 지날수록 각 token 이 다른 tokens 과의 attention 을 학습하는 걸 확인할 수 있었음
- 하지만 , Encoder layer 6 에서ly token에서 전체 tokens 의 attention 이 높은 현상이 일어남
→ 조사 결과 , 아직 명확한 이유에 대해서는 밝혀지지 않음
→ 2019 년 EMNLP 에서 Revealing the Dark Secrets of BERT 란 논문에서 각 attention score matrix pattern 에 대해 분석하였음
Transformer PyTorch 추천코드
추천하는 순서대로 리스트를 작성하였다
PyTorch 공식코드
- LANGUAGE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
- https://pytorch.org/tutorials/beginner/transformer_tutorial.html
Harvard NLP Tutorial
- The Annotated Transformer
- 하버드 NLP 그룹에서 작성한 Transformer tutorial이다.
- http://nlp.seas.harvard.edu/2018/04/03/attention.html
paul-hyun/transformer-evolution
- github : https://github.com/paul-hyun/transformer-evolution
- 한국인이 작성한 코드라서 이해하기 훨씬 편함
- transformer 이외에도 BERT, GPT, T5 등에 대해서도 코드 정리가 되어있음
- transformer 개념이 잘 이해가 안 될때는 본 작성자가 올려놓은 Transformer Evolution.pdf하길 바람. 개인적으로 처음 논문을 봤을 때 이해가 잘 안되었던 부분을 잘 설명해놓음
tunz/transformer-pytorch
- github : https://github.com/tunz/transformer-pytorch
- ⭐ starred : 225
- 실제 Tensorflow Transformer 코드와 Paper 사이에 일부 다른 차이점을 적용한 코드
- Blog Transformer Details Not Described in The Paper를 먼저 본 후 코드를 보는 걸 추천함
