[논문리뷰]Unsupervised Visual Representation Learning by Online Constrained K-Means
Self-supervised Learning

CoKe: online Constrained K-means
Online 방식의 SwAV 모델에서 balanced clustering의 문제점을 지적한 논문이다. SwAV는 한 cluster에 동일한 수의 instance들이 포함되도록 했지만 그렇게 하면 clustering이 데이터 분포에 맞게 되지 않을 수 있다.
따라서 CoKe는 clustering에서 k의 비율을 낮게 제한한다.
이 방법을 통해 더 향상된 clsutering을 할 수 있게 되었고 a single view로 학습하기 때문에 학습 시간을 줄이고 컴퓨터 자원을 덜 쓸 수 있게 한 모델이다.
Abstract
cluster discrimination은 clustering과 discrimination으로 구성괸 unsupervised representation learning 중에서 pretext task에 효과적인 기법이다.
Clustering은 discrimination에서 representations를 학습하기 위해 사용하는 pseudo label을 각 인스턴스에 할당하는 일을 뜻한다.
K-Means는 한 batch 단계에서 작동한다.
Coke방식은 각 cluster가 정확히 같은 크기로 경계를 만드는 balanced clustering 방식과는 달리, 데이터의 구조를 파악하기 위해서 각 cluster의 사이즈를 작게 제약한다.
clustering과 discrimination을 분리해서 CoKe는 각 인스턴스로부터 하나의 view만 최적화 시킬 때 좋은 성과를 보였다.
Introduction
Instance discrimination
이미 라벨이 주어진 데이터를 분류하는 supervised learning과는 달리, 적절한 라벨링을 해줘야 하는 pretext task가 필요한 unsupervised learning 방식이 있다. 많은 pretext task가 주어졌는데, 예를 들어, instance discrimination, cluster discrimination, invariant mapping, solving jigsaw puzzles, patch inpaining 등이 있다. 각 instance들을 하나의 클래스로 확인하는 instance discrimination은 간단한 목적때문에 인기가 있다. 하지만, instance discrimination은 instance들을 각각 비교해야하기 때문에 많은 양의 데이터에서는 사용할 수 없다. 또한, instance discrimination의 문제점은 다른 이미지이지만 서로 연관성이 있다는 것을 배제시킨다. 두 이미지를 학습시킬 때 둘은 negative pair라고 학습시키기 때문이다.결론적으로, 대조 비교해서 학습하는 방식(contrastive learning)은 대규모 이미지 문제를 해결했다. memory bank를 사용하거나 instance들을 mini-batch로 조금씩 학습시키는 방식들이 있다.
Clustering discrimination
instance discrimination과 달리, clustering discrimination은 전체 instance 수보다는 상당히 적은 수의 그룹들로 데이터를 나눈다. 그래서, clustering 후 classification task는 대용량 이미지 학습하는 데 효과적이다.
게다가, 비슷한 instance들은 가깝게 서로 끌어당기기 때문에 데이터의 semantic structure(의미론적 구조)를 학습할 수 있다.
하지만, 문제는 매번 전체 데이터셋을 한 batch mode에서 clustering을 해야한다는 것이다.
그래서 online clustering이 효과적인 방법으로 떠올랐다. 그러나, online clustering의 문제는 우세적인 instance들이 한 clustering 집단에 모여있을 수 있다. 이 문제를 해결하기 위해서 ODC(Online Deep Clustering)은 모든 instance들의 representation을 기억하고 우세적인 큰 cluster 집단을 conventional batch mode로 clustering을 하는 방식이 있다.
SwAV는 균형적인 clustering 방식을 사용하고 바로 전 mini-batch로부터 instnace를 한 batch 모드에 할당하는 방식이다. SwAV는 ODC보다 상당히 결과가 좋았다.
그러나, small subset만으로 pseudo-label을 만들면 전체적인 distribution을 알아내기 어려울 수 있다. 게다가, balanced clustering은 각각의 cluster가 정확히 같은 수의 instance들을 갖고 있는데 이것은 데이터를 정확하게 partition구분을 했다고 보기 어렵다.
그래서 이 논문의 저자가 생각한 방식은 clustering과 discrimination, 이 두 단계를 적절하게 바꿔가며 사용하는 것이다. representation을 고정해놓고 clustering은 instance들 간의 관계를 찾는다. 그 이후에 representation들은 clustering으로 나온 label들을 가지고 구별해서 refine한다. CoKe는 online 방식에 최적화했다.
구체적 방식
clustering 방식에서, 각 cluster의 크기를 낮게 제약하는 constrained k-means라는 online 알고리즘을 사용한다. balanced clustering과 달리, 내제된 data structure를 잘 유연하게 모델링 할 수 있다는 장점이 있다.
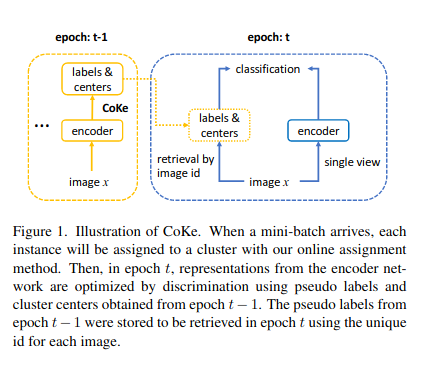
discrimination 방식에서, representation을 학습시키기 위해 전 epoch로부터 기록된 labels와 centers로 standard normalized Softmax loss를 사용한다. clustering과 discrimination 단계를 분리해서 CoKe는 각각의 instance들로 부터 single view와 함께 representation들을 학습하고 small batch size로 최적화시킬 수 있다.
In addition, two variance reduction strategies are proposed to make the clustering robust for augmentations.
CoKe는 momentum encoder나 batch mode solver같은 추가적인 요소들은 없는 simple framework이다.
각 instance에 오로지 하나의 라벨을 갖고 있어서 memory 측면에서 부담이 없다.
CoKe는 MoCo-V2보다 더 좋은 성과를 보였다.
Method
3.1. Objective for Clustering-Based Method
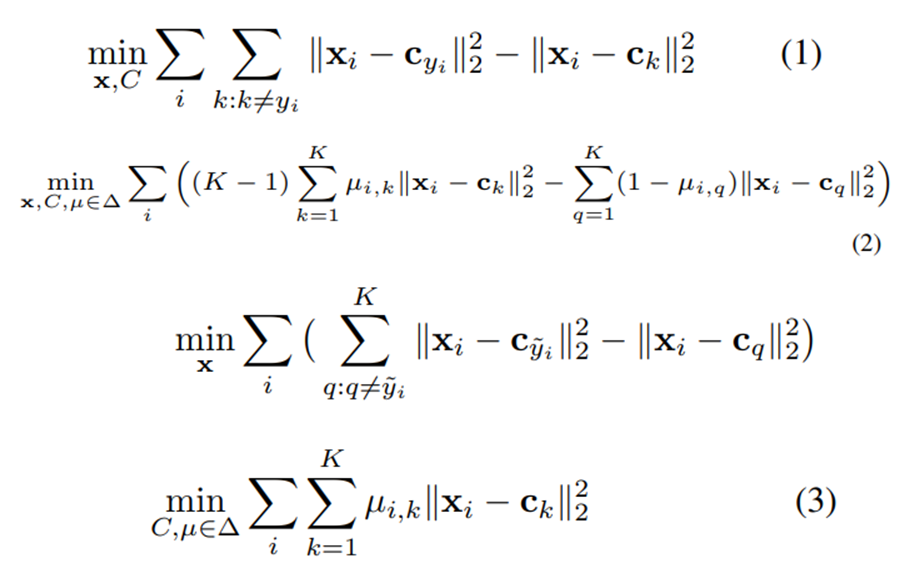
(1)번 식은 x에 대한 라벨 y가 있을 때 데이터를 나누는 구간을 최대화하기 위해, supervised learning에서 최적화를 표현한 식이다.
하지만 labeling된 데이터가 없을 때 k개의 cluster로 데이터의 분포를 표현한다. i번째 instance는 k번째 cluster에 할당하는데
이것은 각각의 instance가 하나의 single cluster에만 할당된다는 걸 의미한다. (2)번 식은 proxy-based unsupervised representation learning을 뜻한다.
3.2. Online Constrained K-Means
instance가 하나의 같은 클래스에 포함되는 문제를 막기위해 constrained k-means방식을 사용한다. cluster의 크기를 최소로 줄이도록 제한을 두는 것이다. 라벨링 되지 않은 데이터 x와 cluster개수 k가 있을 때 constrained k-means의 목적은
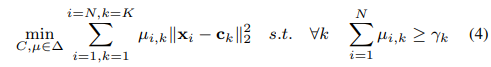
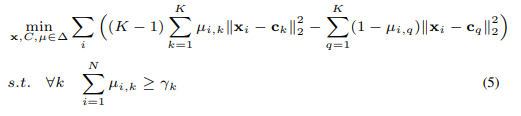
3.2.1. Online Assignment
clustering을 고정시킨 후 representation을 update시킨다.
3.2.2. Online Clustering
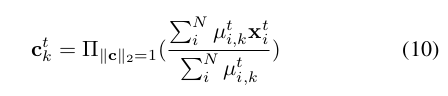
online assignment가 주어졌을 때, constrained k-means방식으로 assignment와 centers를 update한다. t번째 epoch에서 우리는 t-1번째 centers와 pseudo labels를 각 instance들의 mini-batch에 할당한다.
한 instance들의 epoch를 학습시킨 후에 the center들은 10번 식으로 update된다. x(t)는 t번째 epoch에서 i번째 instance의 single view이다.
CoKe는 instance들의 representation을 memorize하지 않는다. contrained k-means 방식에서 변수들은 instance들의 한 epoch에서 update된다.
update하는 single step은 target objective를 최대화하고 clustering의 복잡도를 해결한다.
이러한 방식으로 representations는 더 많은 epoch를 학습할수록 향상되고 clustering도 동시적으로 최적화된다.
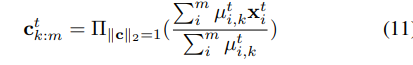
center들은 각각의 mini-batch 이후에 update된다. 11번에서 m은 t번째 epoch에서 instance들의 수이다. 각 epoch마다 한번 centers를 update한다.
3.3 Discrimination
t-1번째에서 얻은 pseudo labels와 centers과 함께 t번째 epoch에서 instance들간의 standard normalized Softmax loss를 최적화함으로서 representation을 학습할 수 있다.
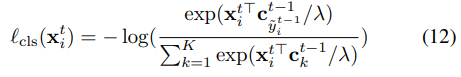
3.4 Variance Reduction for Robust Clustering
Two Views
같은 이미지에서 two views로 representation들을 학습하는 것은 contrastive learning에서 많이 나왔다. 우리의 제안된 방법은 다른 epochs로부터 two view를 사용하는 것이라고 본다. single view는 각 epoch마다 효율적이다. 그럼에도 불구하고 CoKe는 two views를 평가하면서 향상되었다.
하나의 이미지의 two view가 주어지면, assignment에 대한 제약은 모든 view들이 같은 label을 공유한다는 것이다. 그래서, 12번 식에서 loss값은 two view들에 대해 평균화한다. 이런 방식은 single view와 비교했을 때, multiple views는 다른 augmentation들로부터 variance를 줄이고 assignment를 더 안정적으로 만든다.
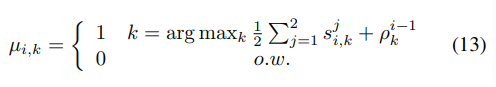

Experiments
4.1.1 Balanced vs. Constrained Clustering
balanced clustering(SwAV가 사용한 clustering 방식)은 각 cluster에 똑같은 수의 instance들이 들어가도록하는 방식
Constrained clustering은 각 cluster의 크기를 lower-bounds하는 방식
r = N/K이기 때문에 1은 balanced learning이다.
k=3000이라고 설정하고 r' = 1이라고 설정할 때, 각 cluster는 이미지 N장/ K로 balanced clustering을 한다.
#Cons: constrained cluster size
#Min: 가장 작은 cluster의 실제 크기
#Max: CoKe의 마지막 epoch로부터 가장 큰 cluster
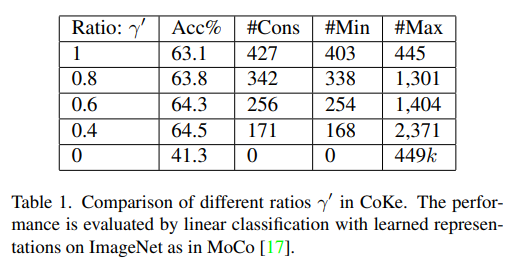
위 그림은 balanced clustering은 single view를 학습할 때, 63.1% 정확도를 보였다.
r' = 0.8일 때, 최소 cluster크기는 403에서 338로 줄었고 가장 큰 cluster의 크기는 balanced clustering의 instances의 두 배 이상이다. r'=0.4로 했을 때, balanced clustering보다 1.4% 증가했다. r' = 0이면 각 cluster에 instance가 없어서 부딛히는 문제가 발생하기 때문에 정확도는 확 내려가는 것이다.
이 방법은 데이터를 작게 잘라 학습시킨 SwAV방식보다 assignments를 더 최적화시킬 수 있다.
r'=0.4일때, 우세한 cluster, 즉 하나에만 쏠린 cluster가 없다고 판단했다. 가장 큰 cluster는 2371개 instance들을 가지고 있어서 unlabel 데이터를 적절하게 나누는데 효과적이라고 봤다.
4.1.2 Coupled Clustering and Discrimination

CoKe모델은 clustering과 discrimination을 분리해서 학습한다. 현재 epoch에서 데이터를 구분하기 위해 last epoch로부터 clustering한 결과를 모으는 방식이다. 위 table 2는 다른 label들과 center들을 구분한다. t-1은 지난 epoch의 center와 label이고 t는 현재 center와 label이다.
우선, 우리는 last epoch에서 label과 center를 구할 수 있다. CoKe는 최고 성능을 보인다. C(t)는 10%이상 떨어지는데 이것은 last epoch에서 center를 유지하는게 중요하는 것의 중요성을 보여준다. 라벨 y(t)에서 두 variant들은 representation을 제대로 학습하지 못한다.
k-means에서는 k를 설정해주는 것도 중요한 실험이다.
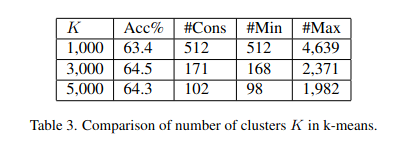
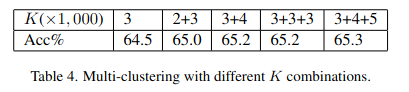
우선 k=3000일때 가장 정확도가 높게 나왔다. 그 후에 multi-clustering이라는 방법을 사용했는데 k를 섞어서 사용하는 것이다. 65.3%로 정확도는 마지막에서 가장 좋았는데 같은 k만 사용할 경우와 k를 섞어서 사용한 경우, 후자가 더 좋다는 것을 보여주는 실험이었다.
4.2 Comparison with State-of-the-Art on ImageNet
ImageNet에서 linear classifier로 학습시킨 SOTA를 달성한 모델들과 비교한 결과이다. 모든 방법은 backbone을 ResNet-50로 사용한다. 2-layer MLP, 128-dimensional representations를 사용한 방법의 결과이다.
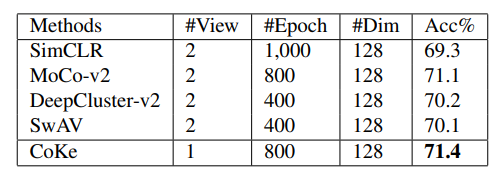
baseline 방법들은 individual instance를 각각의 iteration에서 두개의 augmentations를 한 이미지로 representation을 학습한다. 대조적으로, CoKe는 online optimization을 사용한다. 800 epoch에서 71.4%를 달성했고 MoCo-v2보다 더 좋은 결과이다. 하지만 half number of view에 대한 결과치이다.
이것은 instance들간의 관계를 활용한느 것은 instance discrimination보다 informative patterns를 더 잘 학습한다는 것을 보여준다.
clustering 기반 방법들과 비교할 때 같은 숫자의 view들을 학습시킬 때, CoKe는 SwAV와 DeepClustering보다 1% 더 성과가 좋았다.

마지막으로, 학습시간도 CoKe에서 데이터의 one epoch 학습 시간을 볼 때, 가장 짧았다.
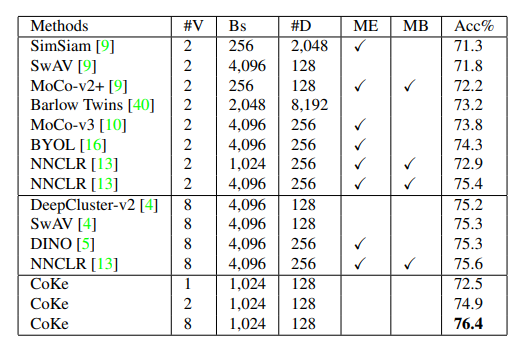
NNCLR모델은 large memory bank로 nearest neighbors를 얻고 batch size도 큰 편이지만 CoKe는 굉장히 간단한 online clustering방식임에도 불구하고 비슷한 성능이 나왔다. 심지어 8개 gpu를 사용한 결과 가장 성능이 좋았다.
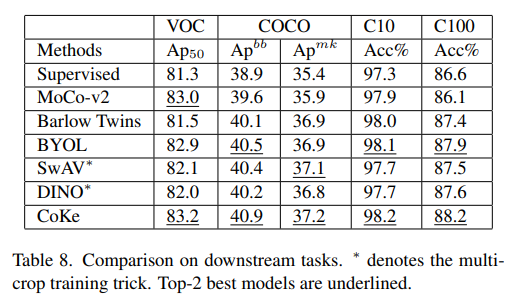
Comparison on Downstream Tasks
fair comparison을 위해 MoCo에서 사용한 codebase로 baseline parameter를 사용했다. multi-crop을 사용했을 때 가장 좋은 성능이 나왔다.
Conclusion
CoKe는 less computational cost임에도 불구하고 가장 효과적인 representation을 보였다.

글 잘 읽었습니다. CoKe에 대한 설명이 매우 자세하고 이해하기 쉬웠습니다. 특히 clustering과 discrimination을 분리하는 방식과 online Constrained K-means 알고리즘에 대한 설명이 매우 흥미로웠습니다. 이 글을 통해 새로운 인사이트를 얻었습니다. 감사합니다.