Deep Clustering
- 특징
1) end-to-end learning of convnets that works with any standard clustering algorithm, like k-means, and requires minimal additional steps
: 아래 그림과 같이 k-means 클러스터링 기법과 end-to-end 방식의 convnet을 사용했고 최소한의 단계들을 더했다.
2) unsupervised learning에서 사용된 방식들 중 최고 성능 달성
3) 이전의 SOTA 모델들보다 더 성능이 좋다.
1. Introduction
문제점: ImageNet으로 Pre-train한 CNN이나 convnet모델들은 특정한 class가 균등하게 주어진 데이터셋으로만 학습을 했기 때문에 큰 규모의 데이터셋이나 다양한 이미지 클래스 불균형이 있는 데이터에는 취약하다는 것이다.
bag of features
- k-means로 convnet을 학습시키면 feature들이 zero화되고 cluster들은 sinlge entity에 부딪히게 되는 문제가 있었다.
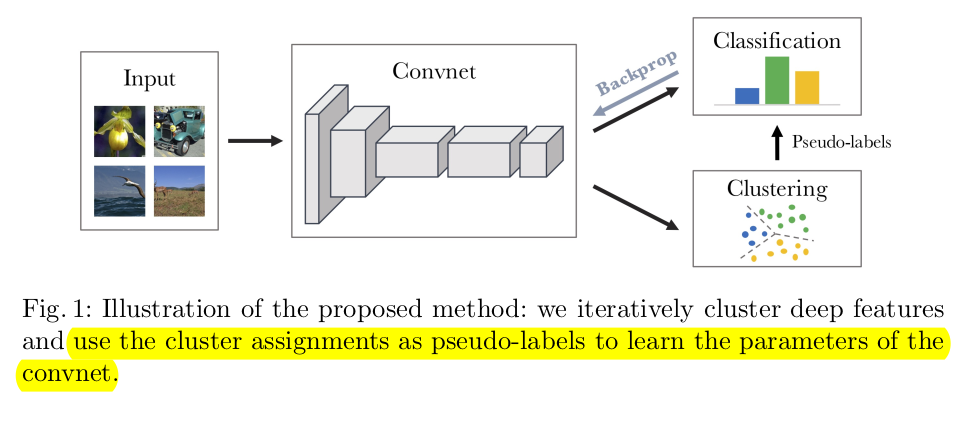
Deep Clustering의 방식은 위의 사진과 같이 이미지 descriptor들의 clustering과 cluster assignments를 예측해 convnet의 가중치를 update시키는 것으로 구성된다.
전체적인 파이프라인은 supervised로 학습한 convnet을 재사용한다.
Self-supervised learning고 달리 clustering은 작은 도메인 지식만 필요하고 input이미지로부터 특정한 signal이 없다. 기본적인 모델로는 AlexNet과 VGG를 사용하고 random한 이미지로도 학습하기 위해 YFCC100M이라는 이미지 데이터셋도 사용할 것이다.
2. Related Work
Unsupervised learning of features
- Coates and Ng가 작성한 pre-train된 convnet에 k-means방법을 bottom-up 방식으로 각각 층에서 학습했다.
- 이 외에도 다양한 방법들이 있지만 SVM과 같은 방식으로 이미지들을 구분하는것이지만 Deep Clustering은 단순히 clustering만 사용한다.
Self-supervised learning
- raw input data에서 계산된 "pseudo-labels(가짜 labels)"로 라벨을 바꾸는 pretext 작업을 사용한다.
- Doersch et al[25]은 pretext task로서 이미지 patch들의 상대적인 position을 예측해 분류하는 일을 했다.
- Noroozi and Favaro[26]는 섞은 pathch들을 재배열해서 신경망을 학습시킨다.
- Pathak et al[38]이 쓴 논문에서 주변 배경을 기반으로 없는 pixel들을 예측하는 것이다.
- Paulin et al[39]은 이미지 retrieval setting을 사용해 CNN patch level을 학습한다.
- [41] 연속한 frame들 사이로 camera transformation을 예측하는 것
- [29] track된 patch들의 coherence를 찾는 방식
- [27] 움직임에 기반에 비디오를 분리하는 방식
- 공간과 시간의 coherence와 달리, image colorization [28][42], cross-channel prediction [43], sound[44], instance counting[45]
- 최근에는 다양한 cue들을 결합시키는 방법도 나왔다.[46][47]
- Deep Clustering과 달리, 이런 접근들은 domain지식이 필요하고 feature들을 바꾸기 위한 pretext task 작업들이 필요하다.
Generative models
- 최근 unsupervised learning은 이미지 생성에 많은 발전이 있었다. 주로, parametrized mapping은 이미 정의된 random한 noise와 이미지들 사이에서 autoencoder, GAN, reconstruction loss로 학습된다.
- GAN의 discriminator는 시각적인 feature들을 만들지만 결과는 상당히 disappointing하다. Donahue et al과 Dumoulin et al은 GAN에 encoder를 더하는 것은 competitive한 visual feature들을 만드는 것이라고 보았다.
이미지의 feature들을 clustering을 한 후에 라벨이 없는 이미지를 학습시킨 후 가중치를 convnet 모델에 back-propagation을 시킨다.
3. Method
3.1 Preliminaries(서두)
- convnet은 raw한 이미지들을 고정된 dimensionality의 벡터 공간에 mapping하는 것이다.
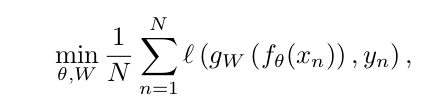


-
convnet 이후에 나온 값을 이미지 feature나 representation이라고 한다.
-
gw인 classifier를 사용해 top layer에서 분류를 한다. negative log-softmax인 multinomial logistic loss를 사용하고 cost function은 mini-batch로 최적의 기울기를 찾는 STD(Stochastic Gradient Descent)와 gradient를 계산하는 backpropagation을 찾는다는 내용이다.
3.2 Unsupervised learning by clustering
- Deep Clusteing에서 꼽은 문제점은 pre-trained하는 모델들이 input의 영향력이 중간에 위치한 네트워크보다 영향력이 강하다는 것이다.
- clustering을 한 값은 위에 방정식 1을 사용해 optimize해 pseudo-label을 형성하는 원리이다. 값들을 비교하는 것 없이 k-means 알고리즘을 사용한다. convnet에 의해 형성된 feature들을 사용해 k개 group으로 clustering을 진행한다. 이미지들을 좌표에 찍어 서로 가까이 있는 점들끼리 grouping을 하는 원리다.
즉, n개의 이미지에서 yn개의 cluster assignments가 만들어지고 d x k 인 C행렬로 clustering을 한다.
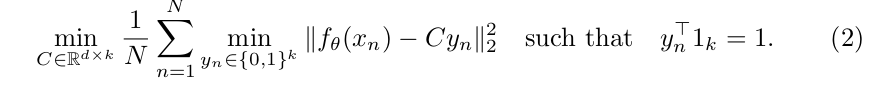
2번 방정식을 활용해 pseudo-label들을 만드는 feature를 클러스터링하고 1번 방정식으로 pseudo-label을 예측함으로 convnet 파라미터를 update한다. 그래서 저자는 중간 신경망을 강하게 만들기 위해 마지막 4096 크기로 출력되는 hidden feature(이미지 n장 x 4096 데이터셋)들을 clustering으로 해결하고자 한 것이다. clustering을 k가 10000일 때 가장 성능이 좋게 나왔다. 그렇게 clustering한 값을 pseudo label(= clustering index)라고 한다. 이 값들을 256차원으로 줄여 fine-tuning을 진행한다. 이 sampling된 값은 균등하다고 생각한다.3.3 Avoiding trivial solutions
Empty clusters
Discriminative model(결정경계를 학습하는 모델)은 모든 inputs을 하나의 cluster에 넣는다.
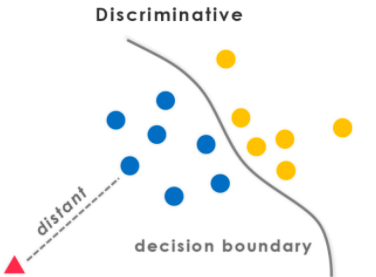
이 문제는 비어있는 cluster들을 막는 알고리즘이 없고 convnet같은 linear model에 발생한다. 흔히 사용하는 방법은 자동적으로 k-means 최적화하는 동안 비어있는 cluster들을 reassign하는 것이다. 그래서 이 논문에서는 비어있지 않은 cluster에 속하는 점들을 두개로 나눠 clustering을 했다.
Trivial parametrization
만약 대량의 이미지를 작게 cluster한다면 parameter들은 과하게 구별할 것이다. 즉, input과 관계없이 같은 output이 나올 것이다. 이 문제는 심하게 불균형인 image supervised learning에서도 발생한다. cluster 크기가 커야 방정식1번인 loss function에서 input의 기여도가 커진다.
3.4 Implementation details
Convnet architectures
- AlexNet 구조를 사용한다. 5conv인 96, 256, 384, 384, 256 filter들을 사용하고 3 fc layer로 구성된다. 우리는 Local Response Normalization layer를 제거하고 batch normalization을 사용한다.
- 또한, batch normalization을 사용한 VGG-16모델도 사용한다.
- Sobel 필터를 사용해 색상을 없애고 local contrast를 증가시키는 방식을 사용했다.

이 그림처럼 edge 부분만 학습시키는 것이다.
Training data
: 1000개의 클래스가 있는 1.3만개 이미지들을 가진 ImageNet 데이터셋으로 학습시킨다.
Optimization
중앙을 자른 이미지로 feature를 클러스터링하고 data augmentation(random horizontal flips, crop of random sizes, aspect ratios)를 한다. dropout, constant step size, 가중치의 L2 penalization, momentum 0.9를 사용한다. 256개의 image인 mini-batch로 구성한다.
- 클러스터링을 할 때, 256 차원으로 축소한 후 whitened, l2-nomalized를 한다. clustering 기법으로는 k-means를 사용한다. k-means를 사용하면 모든 데이터셋을 forward pass하는데 필요한 시간의 1/3으로 줄일 수 있다.
- 500 epochs로 학습해 AlexNet은 Pascal P100 GPU로 12일 정도가 걸린다.
