

Model Compression 관련 논문 중 첫 번째로 리뷰할 논문은 Training with Quantization noise for Extreme Model Compression이라는 논문이다.
이 논문은 Facebook AI에서 Arxiv에 2020.04.17일에 최종본으로 등록이 된 논문이다.
해당 논문은 새로운 방법을 제시하기보다는 기존의 방법의 문제점을 보완하는 방향으로 작성된 논문이다.
Quantization, pruning, knowledge-distillation, compressed architecture 등 다양한 model compression 기법들이 존재하는데, 이 논문은 Quantization을 통한 model compression을 제시한다.
Contributions
- In NLP SOTA 달성 : MNLI(The Multi-Genre Natural Language Inference) dataset을 사용하여 RoBERTa 모델을 14MB로 줄이면서 82.5%의 accuracy 달성
- In CV SOTA 달성 : ImageNet dataset을 사용하여 EfficientNet-B3 모델을 3.3MB로 줄이면서 80.0%의 accuracy 달성
본문에서 제시하는 Quant-Noise방법 중 Product Quantization과 int8 Quantization을 혼합한 방법을 사용하여 Neural Network를 training 함으로써 ImageNet에서 79.8%의 top-1 accuracy, Wikitext-103에서 21.1 perplexity 달성과 동시에 fixed-precision computation을 얻음
Introduction
Introduction에서는 다양한 Model compression 방법들에 대해서 설명한다. 첫 번째로는, network의 weights의 파라미터 수를 줄임으로써 compressed 된 모델을 얻는 방법 중 하나인 pruning과 distillation이 있다. 두 번째로는, 이 논문에서 가장 많이 언급되는 Quantization이다. Quantization은 network의 각 weight들의 bit 수를 줄임으로써 모델을 압축시키면서 성능은 유지되게 하는 방법이다.
Quantization의 세 가지 종류 중 하나인 scalar-quantization을 간략하게 설명하면, floating-point weight들을 lower-precision으로 바꿔준다. 이는 압축률이 높으면서 inference를 가속화해주는 장점이 있다. 하지만, lower-precision으로 표현됨으로써 error들이 많이 쌓이게 되고, 이는 성능의 저하를 가져오는 경향이 있다. 에러가 쌓이는 것을 방지하기 위해서 일반적으로 training을 하면서 quantization을 진행하게 된다. 그러나, 이 방법도 1. gradinet가 null이 발생 2. train에서 적용된 함수와 test에서 적용된 함수의 차이가 발생하는 문제가 존재한다. 이를 해결하기 위해 QAT(Quantization Aware Training)이 제시되었고, 이는 gradient를 계산할 때 STE(Straight Through Estimator)을 이용하는 방법이다.
QAT, STE?
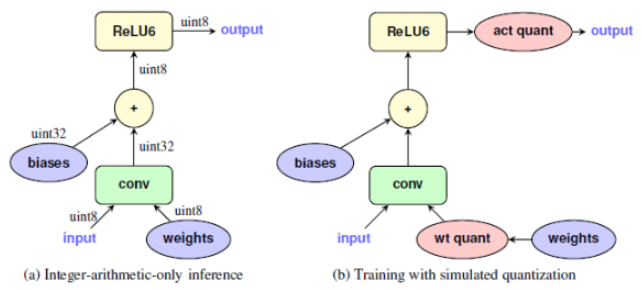
그림 a)는 일반적인 Quantization방법이고, 그림 b)는 QAT이다.
일반적인 Quantization은 모델이 training이 다 끝난 후에 Quantization을 진행하게 된다. 반면에, QAT는 일반적인 모델 설계단계와 동일하게 weight을 initialize 해주고, 이 weight에 대해 quantization을 진행하게 된다. 그 후 model을 거쳐서 나온 output에 대해서도 quantization을 진행하여 최종적인 output을 계산하게 되는 것이다. 즉, 일반적인 quantization은 training이 다 끝난 후 quantization을 적용하는 것이고, QAT는 training과정 중에 지속적으로 quantization을 적용하는 것이다.
그럼 QAT과정 중에 weight, biases들은 어떻게 update 하는 것일까?
여기서 필요한 개념이 STE이다. 이는 gradient가 흐를 수 있게 하는 것으로, quantization 전의 gradient와 후의 gradient를 항등 함수로 처리하겠다는 것이다. 즉, Relu를 거쳐 나온 output을 u, u에 대해 quantization을 적용 한 값을 v라고 하면, 로 계산하여, gradient가 null이 되는 상황을 막아준다.
Quantization
Quantization에는 총 세 가지가 존재한다. 위에서 잠시 예를 들었던 Scalar Quantization과 Vector Quantization 그리고 Product Quantization이 있다.
Scalar Quantization
Scalar quantization은 위의 설명대로 lower-precision으로 표현하는 방식이고, int4, int8 등이 있으며 뒤의 숫자는 bit 수를 나타낸 것이다.
예를 들어, W=[[-1.54, 0.22],[-0.26,0.65]]의 weight을 int4로 표현한다고 하자. 가장 먼저 해야 할 일은 minimum, maximum을 정하는 것이다. 이번 예에서는 min=-2, max=2로 가정하자. 그다음 [min, max]의 범위를 16등분 해준다. 여기서 왜 16등분을 해주냐면, 4-bit로 표현할 수 있는 숫자의 범위는 -8부터 8까지이기 때문이다. 그리고 quantization 할 weight(=W)의 각각의 값들을 16등분으로 나누어진 범위 중 가장 가까운 값들로 mapping 해준다. 마지막으로, min=-2, max=2이기 때문에 scale(4-bit는 -8부터 8까지)를 맞춰주기 위해 mapping 된 값에 를 해준다.
이것이 scalar quantization이다.
Vector Quantization
Vector Quantization은 각각의 weights들은 block 단위로 나눠서 quantization 해주는 방식이다. 즉, 하나의 weight값이 p*q matrix의 형태일 때, 이 matrix를 column을 기준으로 나눈다. 그렇게 되면, 총 p개의 vector가 생성이 되고, 각각의 vector을 quantization 해주는 방식이다.
Product Quantization
Product Quantization은 Vector Quantization에서 한단계 더 추가된 quantization방식이다. 위의 vector quantization에서 이어서 설명해보자면, p개의 vector로 나뉜 상황에서 각각의 vector을 subvector로 나누게 된다. 즉, p개의 vector 중 첫 번째 vector를 v_1이라고 할 때, v_1 벡터는 q차원을 갖는 벡터이다. 이 벡터를 다시 한번 4개의 subvector로 나누게 된다. 즉, subvector의 차원은 q/4가 되는 것이다. 이렇게 나뉜 subvector의 단위로 quantization을 진행하게 된다. 이러한 방식으로 quantization을 진행하는 것을 Traditional product quantization이라고 한다. 이 방법 외에 Iterative product quantization이라는 방식이 있는데, 이는 "Pierre Stock, Armand Joulin, Rémi Gribonval, Benjamin Graham, and Hervé Jégou. And the bit goes down: Revisiting the quantization of neural networks. CoRR, abs/1907.05686, 2019."을 참조하면 좋을 것 같다.
Method
이런 다양한 quantization 방식들을 training 과정에서 STE를 적용하여 진행하게 되면(QAT) bias가 발생하게 된다. 따라서 저자들은 이 부분을 해결하기 위하여 Quant-Noise라는 방법을 제시했다. 이는 weight의 일부분만 랜덤 하게 quantization을 진행함으로써 unbiased 된 gradient를 unquantized weight들을 통하여 흐르게 하는 기법이다. 이는 매우 다음과 같은 그림으로 이해할 수 있다.
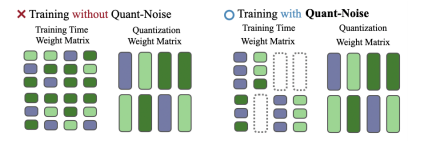
그림의 왼쪽은 Quant-Noise를 진행하지 않았을 때의 weight들이고, 오른쪽 그림은 Quant-Noise를 적용하였을 때의 weight들을 표현한 것이다. 오른쪽 그림의 Training Time Weight Matrix 그림에서 왼쪽 위의 3개의 subvector들을 보면 모두 동일한 색으로 표현되어 있음을 볼 수 있다. 이는 quantization이 진행되어 동일한 값을 가지는 것을 볼 수 있고, 왼쪽에서 두 번째 3개의 subvector들 중 첫 번째 subvector은 quantization후에도 동일한 색을 가지는 것을 보아 quantization이 진행되지 않았음을 알 수 있다. 또한, quantization뿐만 아니라, 점선으로 표시된 부분은 dropout을 적용한 것을 확인할 수 있다. 이처럼 모든 weight 값들에 대하여 quantization을 진행하기보다는 랜덤 하게 일부만 적용된 것을 볼 수 있다.
Results
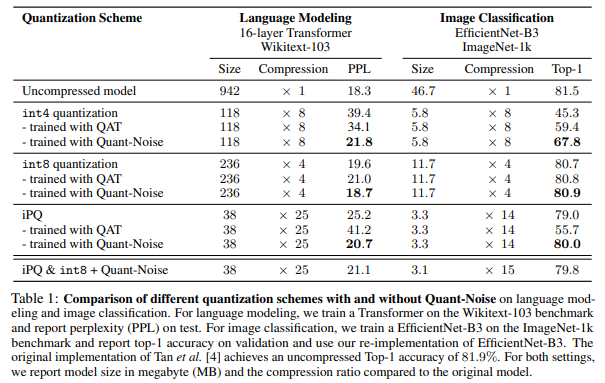
위의 표는 각기 다른 quantization방식(int4, int8, iPQ, iPQ+int8)을 적용하였을 때의 NLP에서의 ppl, Image Classiffication accuracy이다. 각각의 quantization에서 Quant-Noise를 적용했을 때의 결과가 가장 좋은 것을 볼 수 있으며, 다른 quantization방식보다 iPQ quantization방식을 이용하여 Quant-Noise로 training을 했을 때 결과가 가장 좋은 것을 볼 수 있다.

또한, model compression의 한 종류인 양자화를 적용함에 따라 performance 대비 model size를 나타내는 표도 제시되었다. 표를 확인해보면, 각각의 task에서 SOTA 대비 performance는 많이 하락하지 않으면서 model size가 상당히 감소한 것을 볼 수 있다.
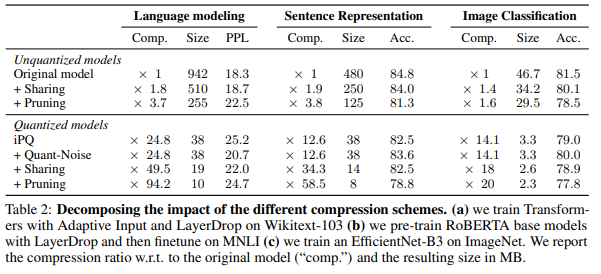
Introduction에서 설명한 것과 같이 다양한 model compression 기법들(weight sharing, pruning, etc)과의 비교도 진행하였다. 표에서 보는 것처럼, Quant-Noise를 적용했을 때 performance가 어느정도 보존되면서 model이 압축되는 것을 볼 수 있다.
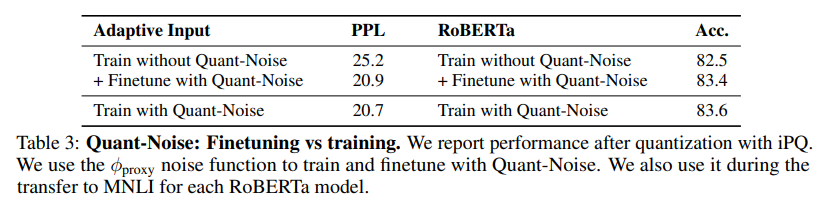
마지막으로, training과정에서 Quant-Noise를 적용하는 것과 finetuning과정에서 Quant-Noise를 적용하여 비교하는 실험을 진행하였다. 두 경우의 결과가 많이 차이나지 않는 것을 보아, finetuning과정에서 Quant-Noise를 적용해도 충분히 좋은 결과를 얻을 수 있다는 결과를 보여주었다.
Conclusion
Training with quantization noise for extreme model compression 논문을 정리하자면, 저자들이 제시한 Quant-Noise방식은 다양한 application에 모두 적용될 수 있는 quantization방식이며 성능을 어느 정도 보존하면서 상당한 compression을 보여주었다. 또한, integer quantization, vector quantization, product quantization, int+product quantization 등 quantization 종류에 상관없이 사용할 수 있는 방법이다. 이렇게 Facebook AI에서 제시한 Quant-Noise방식은 상당히 흥미롭고, 매우 간단하지만 실험 결과를 보면 상당히 impact있는 방법이다. 해당 논문을 읽으면서 quantization에 관심을 갖게 되었고, 이를 바탕으로 quantization을 실제로 한번 적용해 봐야겠다.
배우는 과정이라 미흡한 부분이 있을 수도 있습니다. 포스트에 관련한 질문이나, 지적할 부분이 있으시다면 언제든지 말해주시면 감사하겠습니다 :)
