AI 공부를 시작 한 지 꽤 됐다. 하지만 제대로 된 AI 공부의 기틀을 잡지 못해서 이것 저것 여러가지 하다가 방향을 정해야 하겠다는 생각에 책으로 공부를 계속 하려고 한다.
Sequential Post들은 다음의 책을 기반으로 한다.

이 책의 3장인 SVM부터 시작할 예정이다.
1. 지도학습
지도학습은 정답(label)을 컴퓨터에 미리 알려주고 데이터를 학습시키는 방법이다.
지도학습의 종류에는 분류와 회귀가 있다. 분류는 주어진 데이터를 정해진 범주에 따라 분류하고 회귀는 데이터들의 특성을 기준으로 연속된 값을 그래프로 표현하여 패턴이나 트렌드를 예측할 때 사용한다.
| 구분 | 분류 | 회귀 |
|---|---|---|
| 데이터 유형 | 이산형 데이터 | 연속형 데이터 |
| 결과 | 훈련 데이터의 레이블 중 하나를 예측 | 연속된 값을 예측 |
| 예시 | 학습 데이터를 A,B,C그룹 중 하나로 매핑 | 결과값이 어떤 값이든 나올 수 있음 (주가 예측) |
1.1 K-nearest neighbor(K-최근접 이웃)
왜 사용할까? : 주어진 데이터에 대한 분류
언제 사용하면 좋을까? : 훈련데이터를 충분히 확보할 수 있는 환경
K-nearest neighbor은 새로운 입력(학습에 사용하지 않은 새로운 데이터)을 받았을 때 기존 클러스터에서 모든 데이터와 인스턴스(instance*, 자세하게는 아래에서 따로 설명) 기반 거리르 측정 후에 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘임. 즉, 과거 데이터를 통해 미리 분류 알고리즘을 만들어 두는 것이 아닌, 새로운 데이터가 들어오면 과거의 데이터와 비교를 통해 분류를 수행.
(*instance : 여기서 instance는 새로운 데이터가 들어왔을 떄 데이터와 데이터 사이의 거리를 측정한 관측치(혹은 데이터 값)을 의미한다.)
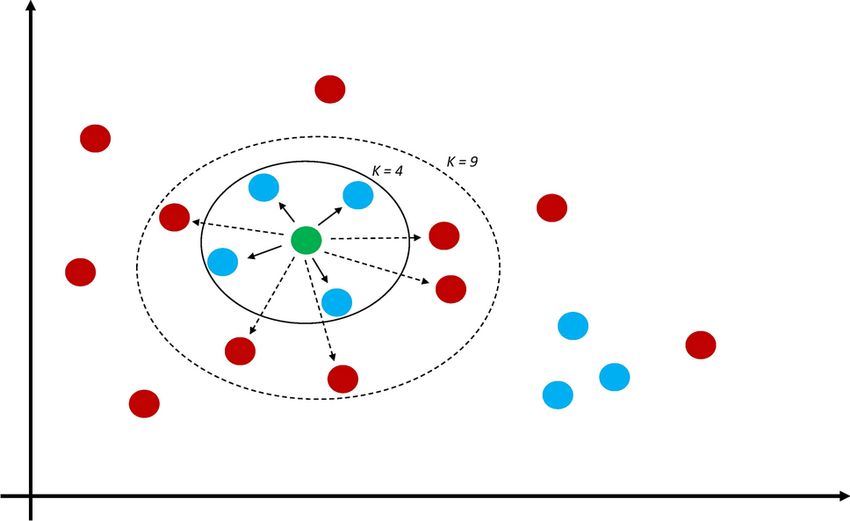
위의 그림에서 K값이 달라질 때마다 분류가 달라진다. 위의 그림에서는 K = 4일때(가장 가까운 것들이 4개) 파란색으로 분류되지만, K = 9가 되면 빨간색으로 분류된다. 이러한 K값은 임의 지정한다.
예제를 통해 알아보자
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import metrics #모델 성능 평가
from google.colab import drive
drive.mount('/content/Mydrive/')
%cd /content/Mydrive/MyDrive/pytorch_textbook/chap03/ #각자의 경로를 생성해주면됨
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv('./data/iris.data', names = names)
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,4].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler
s = StandardScaler()
X_train = s.fit_transform(X_train)
X_test = s.fit_transform(X_test)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors= 50) #K = 50인 K-nearest neighbor모델 생성
knn.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
y_pred = knn.predict(X_test)
print(accuracy_score(y_test, y_pred))
실행 환경은 colab으로 하였다.
코드를 조금 설명하자면 맨 위 코드는 구글 드라이브를 이용하였기 때문에 그냥 마운트만 한 것이고, X(data)를 train data로 설정하고, y를 label로 설정하였다.
X와 y가 무엇을 의미하는지 잠깐 살펴보자
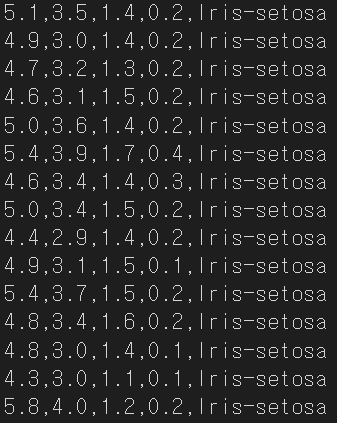
실제로 col 1~4는 각 요소에 대한 특성을 수치화된 data로 가지고 있고, col 5는 어떤 종류인지 string으로 나와있다.
그 후 모듈을 이용해서 split해주고(test data를 0.2(20%)로 설정) StandardSacler로 정규화 해주었다.
이후 K-nearest neighbor 모델을 생성해 준 다음 fit을 이용해 학습시켰다.
K = 50인 경우 정확도는 0.9333이었다.
K값을 조절해 가면서 최대치가 언제인지를 찾아보자.
k = 10
acc_array = np.zeros(k)
for k in np.arange(1, k+1, 1):
classifier = KNeighborsClassifier(n_neighbors = k).fit(X_train, y_train)
y_pred = classifier.predict(X_test)
acc = metrics.accuracy_score(y_test, y_pred)
acc_array[k-1] = acc
max_acc = np.amax(acc_array)
acc_list = list(acc_array)
k = acc_list.index(max_acc)
print("정확도", max_acc, '으로 최적의 k는', k+1,'입니다.')정확도 0.9666666666666667 으로 최적의 k는 1 입니다.
