왜 사용할까? : 주어진 데이터에 대한 분류
언제 사용하면 좋을까? : 서보트 벡서 머신은 커널만 적절히 선택한다면 정확도가 상당히 좋다. 때문에 정확도를 요구하는 분류문제를 다룰 떄 사용하면 좋다. 텍스트를 분류 할 때에도 많이 사용한다.
SVM은 분류를 위한 기준선을 정의하는 모델이다. 분류되지 않은 새로운 데이터가 나타나면 경계선을 기준으로 어느 경계에 속하는지를 분류할 수 있다.
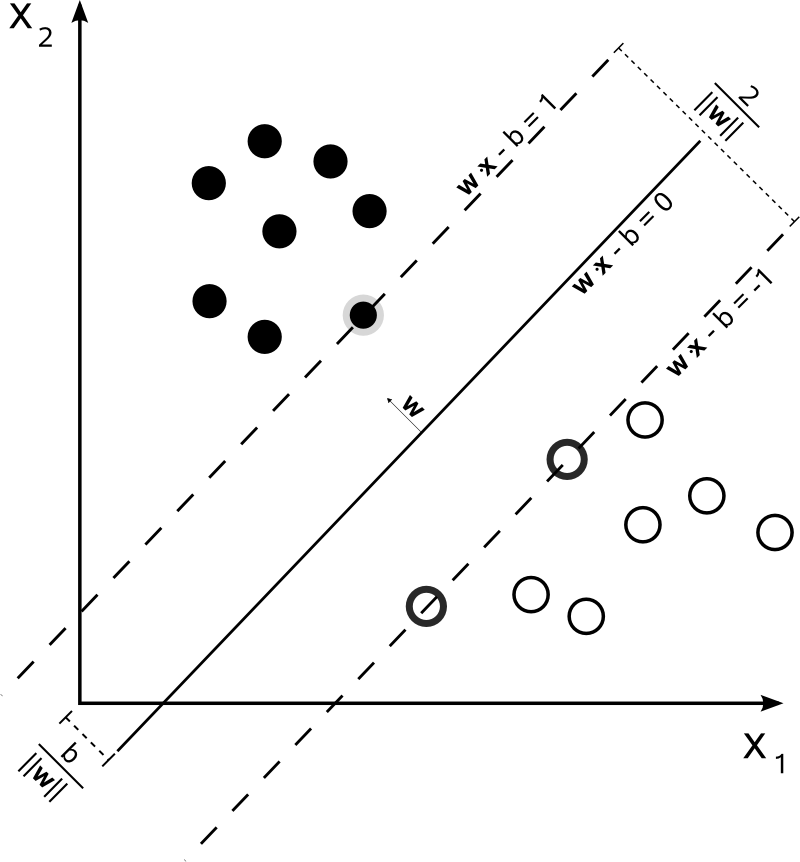
경계선을 결정경계라고 하는데, 이 결정 경계가 클래스를 분류한다. SVM에는 마진(margin)이라는 것이 있는데, 이는 결정 경계와 서포트 벡터(Support Vector)사이의 거리를 의미한다. SV란 결정 경계와 가장 가까이 있는 데이터(들)을 의미한다. 이 데이터(들)이 경계를 결정하는 중요한 역할을 한다. 즉, 최적의 결정 경계는 margin이 최대가 되어야 한다.
margin의 종류에는 soft margin과 hard margin 두 가지가 있다.
soft margin은 margin안 (결정 경계를 넘을수도 있음)에 이상치가 있어도 되는 경우
hard margin은 절대로 없는 경우를 의미한다.
from sklearn import svm
from sklearn import metrics
from sklearn import datasets
from sklearn import model_selection
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = model_selection.train_test_split(
iris.data, iris.target, test_size = 0.6, random_state = 42)
svm = svm.SVC(kernel='linear', C=1.0, gamma=0.5)
svm.fit(X_train, y_train)
predictions = svm.predict(X_test)
score = metrics.accuracy_score(y_test, predictions)
print('정확도 : {0:f}'.format(score))정확도 : 0.988889
코드를 설명해보면, 데이터셋을 불러와 훈련과 테스트 데이터셋으로 분리한다.
먼서 sklearn으로 svm모델을 생셩 및 훈련 후 테스트 데이터셋을 이용한 예측을 수행한 후 정확도를 출력한다.
SVM 모델은 선형 분류와 비선형 분류를 지원한다. 비선형에 대한 커널은 선형으로 분류될 수 없는 데이터들 때문에 발생했다.
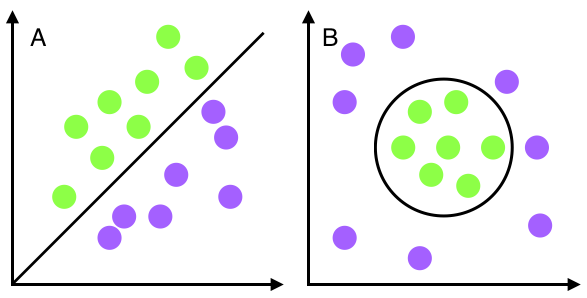
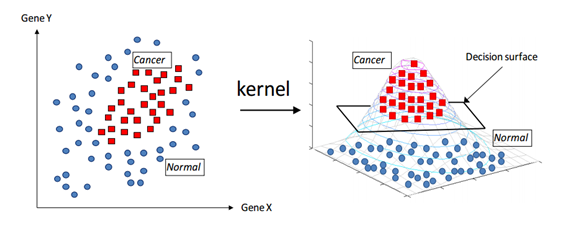
이러한 선형으로 분류할 수 없는 데이터들을 비선형 분류를 통해서 해결할 수 있다. 비선형 문제를 해결하는 가장 기본적인 방법은 저차원 데이터를 고치원으로 보내는 것인데, 이는 많은 수학적 계산이 필요하기 때문에 성능에 문제를 줄 수 있다.
이러한 문제를 해결하고자 도입한 것이 바로 '커널 트릭(kernel trick)'이다. 선형 모델을 위한 커널에는 선형(linear) 커널이 있고, 비선형을 위한 커널에는 가우시안 RBF 커널과 다항식 커널(poly)가 있다.
