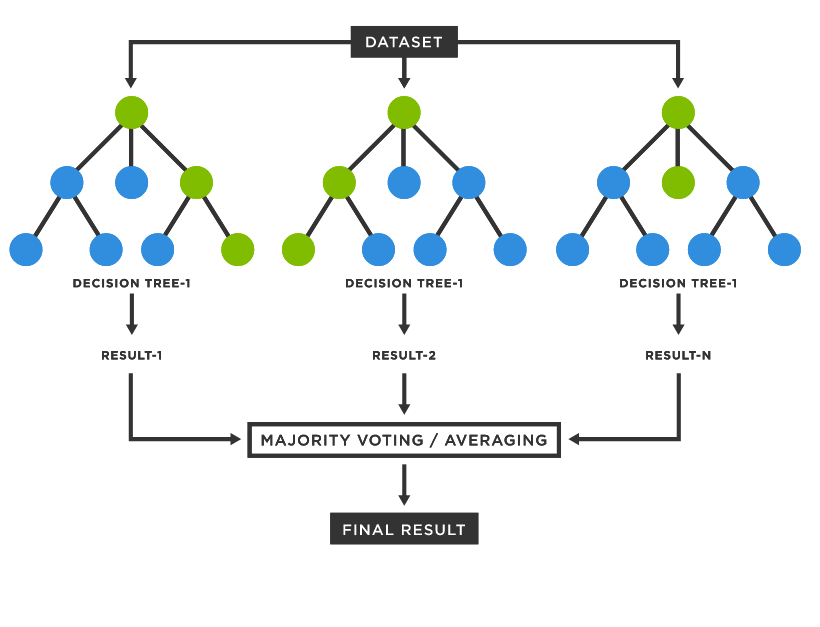
"여러 개의 트리 모델"에서 "서로 다른 데이터"를 투입하여 나온 결과를 종합하여 가장 많은 투표를 얻은 결과를 최종 결과로 선택하는 방식으로 작동
랜덤 포레스트는 대표적인 "배깅" 방식 알고리즘
배깅(Bagging) : 앙상블의 한 방식, 같은 알고리즘의 여러 개의 개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적인 예측을 수행한 결과를 보팅을 통해 최종 예측 결과로 선정하는 방식
랜덤 포레스트의 기반 알고리즘은 "결정 트리"
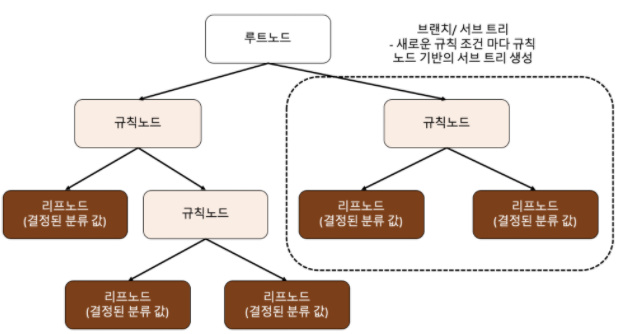
결정 트리(Decision Tree) : 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만들어 내는 것
PROBLEM : 트리의 깊이가 깊어질수록 과적합으로 이어져 결정 트리의 예측 성능이 저하될 가능성이 높음
SOLUTION : 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 함 -> 깊이가 덜 깊어짐
=> 최대한 균일한 데이터 세트 만들기!
높은 정보 이득(낮은 엔트로피), 낮은 지니계수(불평등 지수)
<결정 트리 생성 과정>
1. 모든 독립 변수, 기준값(threshold)에 대해 "정보 획득량"을 구해 정보 획득량이 큰 독립 변수와 기준값을 선택 (높은 정보 이득, 낮은 지니계수)
2. 전체 학습 데이터 집합을 해당 독립 변수의 값보다 작은 데이터 그룹(자식노드1)과 해당 독립 변수의 값보다 큰 데이터 그룹(자식노드2)로 나눔
3. 각각의 자식 노드에 대해 1~2단계를 반복하여 하위의 자식 노드 만듦, 데이터가 모두 특정 분류에 속하면 반복 중지
