🌎 pro2. 조이스틱
문제 설명
조이스틱으로 알파벳 이름을 완성하세요. 맨 처음엔 A로만 이루어져 있습니다.
ex) 완성해야 하는 이름이 세 글자면 AAA, 네 글자면 AAAA
조이스틱을 각 방향으로 움직이면 아래와 같습니다.
▲ - 다음 알파벳
▼ - 이전 알파벳 (A에서 아래쪽으로 이동하면 Z로)
◀ - 커서를 왼쪽으로 이동 (첫 번째 위치에서 왼쪽으로 이동하면 마지막 문자에 커서)
▶ - 커서를 오른쪽으로 이동 (마지막 위치에서 오른쪽으로 이동하면 첫 번째 문자에 커서)
예를 들어 아래의 방법으로 "JAZ"를 만들 수 있습니다.
- 첫 번째 위치에서 조이스틱을 위로 9번 조작하여 J를 완성합니다.
- 조이스틱을 왼쪽으로 1번 조작하여 커서를 마지막 문자 위치로 이동시킵니다.
- 마지막 위치에서 조이스틱을 아래로 1번 조작하여 Z를 완성합니다.
따라서 11번 이동시켜 "JAZ"를 만들 수 있고, 이때가 최소 이동입니다.
만들고자 하는 이름 name이 매개변수로 주어질 때, 이름에 대해 조이스틱 조작 횟수의 최솟값을 return 하도록 solution 함수를 만드세요.
제한 사항
name은 알파벳 대문자로만 이루어져 있습니다.
name의 길이는 1 이상 20 이하입니다.
입출력 예
name return
"JEROEN" 56
"JAN" 23
코드
def solution(name):
# 조이스틱 조작 횟수
answer = 0
# 기본 최소 좌우이동 횟수는 길이 - 1
min_move = len(name) - 1
for i, char in enumerate(name):
# 해당 알파벳 변경 최솟값 추가
# ord 문자 순서 위치 값
answer += min(ord(char) - ord('A'), ord('Z') - ord(char) + 1)
# 해당 알파벳 다음부터 연속된 A 문자열 찾기
next = i + 1
while next < len(name) and name[next] == 'A':
next += 1
# 기존, 연속된 A의 왼쪽시작 방식, 연속된 A의 오른쪽시작 방식 비교 및 갱신
min_move = min([min_move, 2 * i + len(name) - next, i + 2 * (len(name) - next)])
# 알파벳 변경(상하이동) 횟수에 좌우이동 횟수 추가
answer += min_move
return answer🌎 17503. 맥주 축제
문제
내일부터 N일 동안 대구광역시에서 맥주 축제가 열립니다!
이 축제에서는 무려 K종류의 맥주를 무료로 제공합니다.
축제 주최자는 축제에서 더 많은 참가자들이 다양한 종류의 맥주를 즐겼으면 합니다. 그래서 축제에서 참가자들은 하루에 맥주 1병만 받을 수 있고, 이전에 받았던 종류의 맥주는 다시 받을 수 없습니다.
맥주를 정말로 사랑하는 대학생 전씨는 무료 맥주 소식에 신이 났습니다. 전씨는 이 맥주 축제에 참가해 총 N일 동안 맥주 N병을 마시려 합니다.
하지만 전씨에게는 큰 고민이 있었습니다. 전씨는 맥주를 사랑하지만, 도수가 높은 맥주를 마시면 기절하는 맥주병이 있습니다. 전씨는 맥주를 마시다 기절하면 늦잠을 자 다음 날 1교시 수업에 결석해 F를 받게 될 수도 있습니다.
전씨는 고민을 해결하기 위해 천재석사 현씨과 천재박사 승씨에게 자신의 간을 강력하게 만들어달라고 부탁했습니다. 하지만 간을 강력하게 만드는 비용이 너무 비싸서, 전씨는 간을 가능한 한 조금만 강화할 계획을 세웠습니다.
우선, K종류의 맥주에 각각 '선호도'와 '도수 레벨'을 매겼습니다. 선호도는 전씨가 해당 맥주를 얼마나 좋아하는지를 나타내는 수치이고, 도수 레벨은 해당 맥주의 도수가 얼마나 강한지를 나타내는 수치입니다. 편의상 전씨는 선호도와 도수 레벨을 정수로 매겼습니다.
만약, 마시는 맥주의 도수 레벨이 전씨의 간 레벨보다 높으면 맥주병이 발병해 기절해버리고 맙니다.
또한, 전씨는 맥주병에 걸리지 않으면서도 자신이 좋아하는 맥주를 많이 마시고 싶어합니다. 따라서, 마시는 맥주 N개의 선호도 합이 M이상이 되게 하려 합니다.
거창한 계획을 세운 전, 현, 승 세 사람은 서로 머리를 맞대고 고민하다가, 스트레스를 받아 연구를 집어치고 맥주를 마시러 떠나버렸습니다.
이를 본 여러분은 세 사람을 대신해 조건을 만족하는 간 레벨의 최솟값을 출력하는 프로그램을 만들어 주려고 합니다.
세 사람을 도와주세요!
입력
첫 번째 줄에 축제가 열리는 기간 N (1 ≤ N ≤ 200,000) 과, 채워야 하는 선호도의 합 M (1 ≤ M < 231) 과, 마실 수 있는 맥주 종류의 수 K (N ≤ K ≤ 200,000) 가 주어집니다.
다음 K개의 줄에는 1번부터 K번 맥주의 선호도 vi (0 ≤ vi ≤ 10,000) 와 도수 레벨 ci (1 ≤ ci < 231) (vi, ci는 정수) 이 공백을 사이에 두고 주어집니다.
1번부터 K번 맥주의 종류는 모두 다릅니다.
출력
첫 번째 줄에 주어진 선호도의 합 M을 채우면서 N개의 맥주를 모두 마실 수 있는 간 레벨의 최솟값을 출력합니다.
만약 아무리 레벨을 올려도 조건을 만족시킬 수 없으면 첫 번째 줄에 "-1" 하나만 출력하고 더 이상 아무것도 출력하지 않아야 합니다.
예제 입력 1
3 9 5
2 5
4 6
3 3
4 3
1 4
예제 출력 1
5
예제 입력 2
1 100 2
99 10
99 10
예제 출력 2
-1
알고리즘 분류
- 자료 구조
- 그리디 알고리즘
- 정렬
- 이분 탐색
- 우선순위 큐
코드
import sys
import heapq
# 입력 받기
n, m, k = map(int, sys.stdin.readline().split())
# 선호도 순서로 정렬하여 입력
beers = [list(map(int, input().split())) for _ in range(k)]
beers = sorted(beers, key=lambda x: (x[1], x[0]))
preference = 0
pq = [] # 우선순위 큐를 사용할 리스트
# 낮은 도수부터 먹어보면서 N을 만족하는지 확인
# 만족하지 않으면 -1 출력하고 종료
for i in beers:
preference += i[0] # 현재 맥주의 선호도를 더함
heapq.heappush(pq, i[0]) # 현재 맥주의 선호도를 우선순위 큐에 추가
if len(pq) == n: # 현재까지의 맥주가 n개가 되었을 때
if preference >= m: # 만족도가 m 이상이면
answer = i[1] # 현재까지의 맥주 중 가장 높은 도수의 맥주를 선택
break
else:
preference -= heapq.heappop(pq) # 만족도를 만족하지 못하면 가장 낮은 선호도를 갖는 맥주를 제거
# for-else 구문: for문이 break 없이 정상적으로 종료되면 else 블록이 실행됨
else:
print(-1)
exit()
print(answer)🌎 1105. 팔
문제
L과 R이 주어진다. 이때, L보다 크거나 같고, R보다 작거나 같은 자연수 중에 8이 가장 적게 들어있는 수에 들어있는 8의 개수를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 L과 R이 주어진다. L은 2,000,000,000보다 작거나 같은 자연수이고, R은 L보다 크거나 같고, 2,000,000,000보다 작거나 같은 자연수이다.
출력
첫째 줄에 L보다 크거나 같고, R보다 작거나 같은 자연수 중에 8이 가장 적게 들어있는 수에 들어있는 8의 개수를 구하는 프로그램을 작성하시오.
예제 입력 1
1 10
예제 출력 1
0
예제 입력 2
88 88
예제 출력 2
2
예제 입력 3
800 899
예제 출력 3
1
예제 입력 4
8808 8880
예제 출력 4
2
코드
# 입력으로 두 개의 문자열 A와 B를 공백을 기준으로 받음
A, B = map(str, input().split(' '))
# 매치된 숫자의 개수를 세기 위한 변수 초기화
ret = 0
# 두 문자열의 길이가 다르면 매치할 수 없으므로 0을 출력하고 종료
if len(A) != len(B):
print(0)
else:
# 두 문자열의 길이가 같으면 각 위치의 문자를 비교하면서 매치된 '8'의 개수를 센다
for i in range(len(A)):
if A[i] == B[i]:
if A[i] == '8':
ret += 1
else:
# 문자가 다르면 더 이상 매치할 필요가 없으므로 반복문 종료
break
# 매치된 '8'의 개수 출력
print(ret)🌎 pro2. 디스크 컨트롤러
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청
- 1ms 시점에 9ms가 소요되는 B작업 요청
- 2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
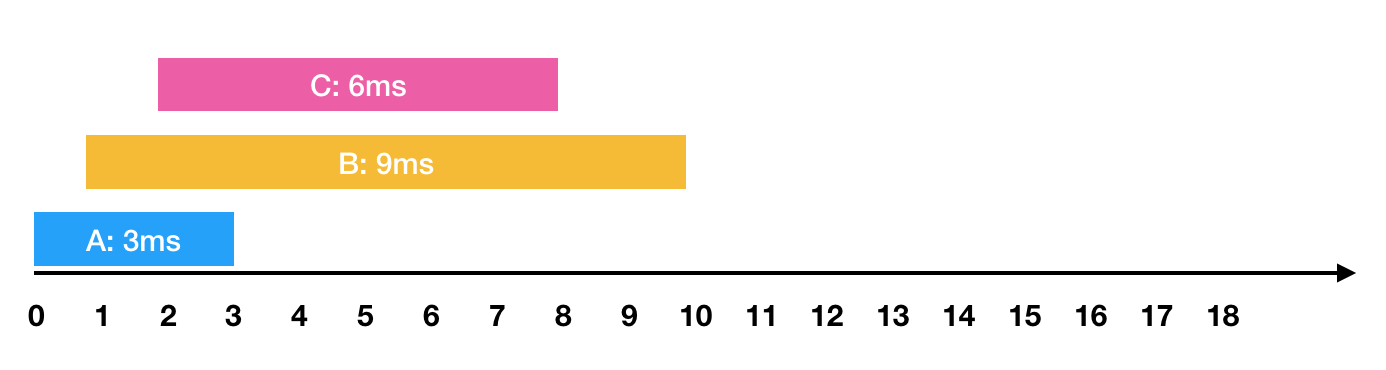
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
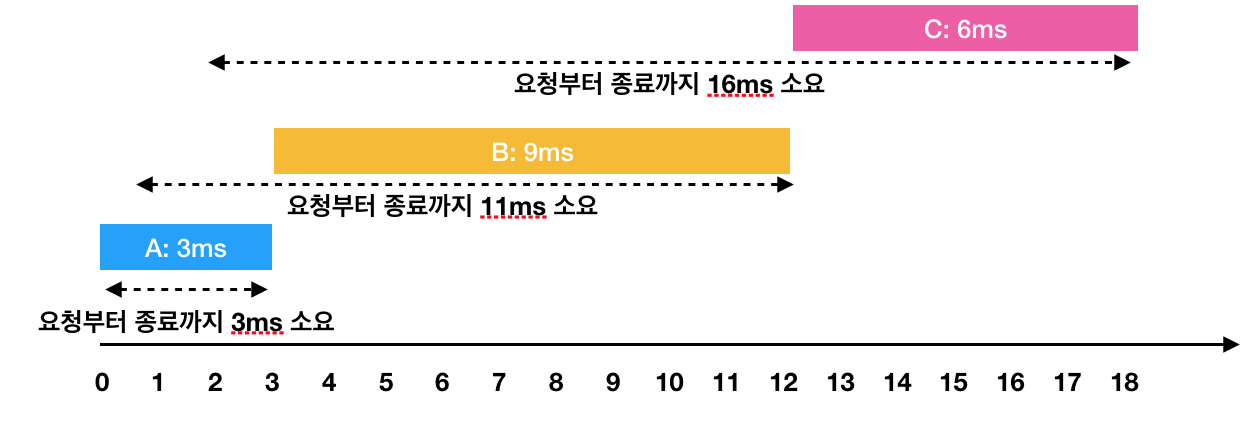
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면
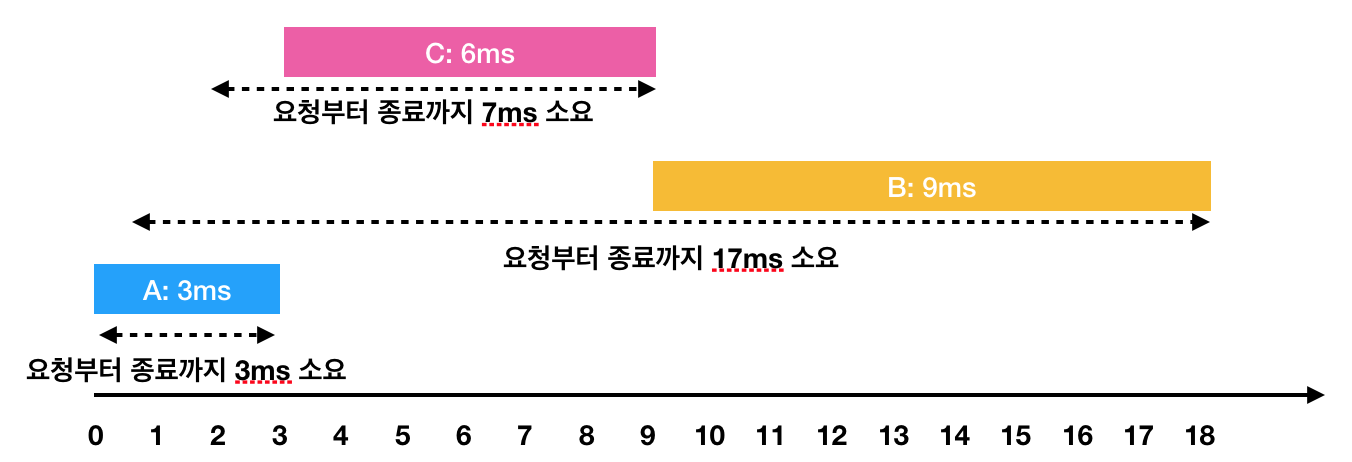
- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예
jobs return
[[0, 3], [1, 9], [2, 6]] 9
입출력 예 설명
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
코드
import heapq
def solution(jobs):
# 초기화
answer, now, i = 0, 0, 0
start = -1
heap = []
while i < len(jobs):
# 현재 시점에서 처리할 수 있는 작업을 heap에 저장
for j in jobs:
if start < j[0] <= now:
# 작업의 소요 시간과 요청 시간을 heap에 저장
heapq.heappush(heap, [j[1], j[0]])
if len(heap) > 0: # 처리할 작업이 있는 경우
cur = heapq.heappop(heap) # heap에서 가장 소요 시간이 작은 작업 선택
start = now
now += cur[0] # 현재 시간을 작업 종료 시간으로 업데이트
answer += now - cur[1] # 작업 요청 시간부터 종료 시간까지의 시간을 누적
i += 1
else: # 처리할 작업이 없는 경우 다음 시간을 넘어감
now += 1
return answer // len(jobs) # 평균 응답 시간을 계산하여 반환🌎 1430. 공격
문제
다솜이는 누구나 쉽게 게임을 만들 수 있도록 하기 위해 Microsoft에서 출시한 XNA Game Studio Express를 가지고 게임을 만들었다.
다솜이의 게임은 적의 공격에 대비해서 도시를 방어하는 게임이다. 도시에는 탑이 N개가 있다. 각각의 탑은 X-Y좌표 평면위에 존재한다. 또, 탑은 맨 처음에 D의 에너지를 가지고 있고, 탑의 사정거리는 R이다.
탑 주변에 적이 나타나면, 탑은 적을 다음과 같은 방법으로 공격할 수 있다.
일단, 탑은 자신의 에너지를 재분배할 수 있다. 만약 서로 다른 두 탑의 거리가 R보다 작거나 같다면, 둘 중에 한 탑은 다른 탑에게 에너지를 자기가 가지고 있는 한도내에서 자유롭게 전송할 수 있다. 하지만, 에너지를 전송할 때는, 절반을 잃는다. (탑 1이 탑 2에게 에너지를 10 전송하면, 탑 1은 에너지를 10을 잃고, 탑 2는 에너지를 5 얻는다.)
탑이 적을 공격할 때는, 적과 탑의 거리가 R보다 작거나 같아야한다. 탑에서 적을 공격할 때는, 자신의 모든 에너지를 적을 공격하는데 쓴다. 이때 적이 받는 데미지는 에너지의 양과 같다.
적이 받을 수 있는 에너지의 최댓값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 탑의 개수 N, 사정 거리 R, 초기 에너지 D, 적의 X좌표 X, 적의 Y좌표 Y가 주어진다. 둘째 줄부터는 탑의 위치가 한 줄에 하나씩 X좌표 Y좌표 순으로 주어진다. N은 50보다 작거나 같은 자연수이고, R은 500보다 작거나 같은 자연수, D는 100보다 작거나 같은 자연수이다. 모든 X좌표와 Y좌표는 1,000보다 작거나 같은 음이 아닌 정수이다. 탑의 위치가 같은 경우는 없고, 적과 탑의 위치가 같은 경우도 입력으로 주어지지 않는다.
출력
첫째 줄에 적이 받는 데미지의 최댓값을 출력한다. 절대/상대 오차는 10-2까지 허용한다.
예제 입력 1
4 2 10 0 0
2 0
4 0
6 0
8 0
예제 출력 1
18.75
예제 입력 2
7 3 100 3 0
5 1
6 3
5 5
3 6
1 5
0 3
1 1
예제 출력 2
362.5
예제 입력 3
9 1 4 0 2
1 2
2 2
3 2
4 2
5 2
3 0
3 1
3 3
3 4
예제 출력 3
9.25
예제 입력 4
3 7 17 0 0
0 5
10 10
5 0
예제 출력 4
34.0
예제 입력 5
4 1 100 10 10
10 12
12 10
10 8
8 10
예제 출력 5
0.0
코드
from collections import deque
# 입력 받기: 탑의 수(n), 영향 반경(r), 기본 값(e), 시작 지점 좌표(ex, ey)
n, r, e, ex, ey = map(int, input().split())
# 탑들의 좌표를 저장하는 집합 생성
tops = {tuple(map(int, input().split())) for _ in range(n)}
# 결과값 초기화
answer = 0
# 너비 우선 탐색(BFS) 함수 정의
def bfs(x, y):
global answer, tops
# 시작 지점을 큐에 추가 (x, y, 현재 깊이(depth))
q = deque([(x, y, 0)])
# BFS 수행
while q:
x, y, depth = q.popleft()
# 깊이가 0보다 크면 기본 값(e)에 2의 (depth-1) 승을 나눈 값을 결과에 더함
if depth:
answer += e / (2 ** (depth - 1))
# 거리 내에 있는 탑 찾기
candidate = []
for top in tops:
if (x - top[0]) ** 2 + (y - top[1]) ** 2 <= r ** 2:
candidate.append(top)
# 찾은 탑들을 큐에 추가하고, 이미 방문한 탑은 tops에서 제거
for top in candidate:
q.append((top[0], top[1], depth + 1))
tops -= set(candidate)
# BFS 시작
bfs(ex, ey)
# 결과값 출력: 소수점 둘째 자리까지 반올림하여 출력
print(round(answer, 2)) if int(answer) != answer else print(f'{answer}.0')
