신뢰성 있는 데이터 전송의 원리
먼저 해당 그림을 봐봅시다.

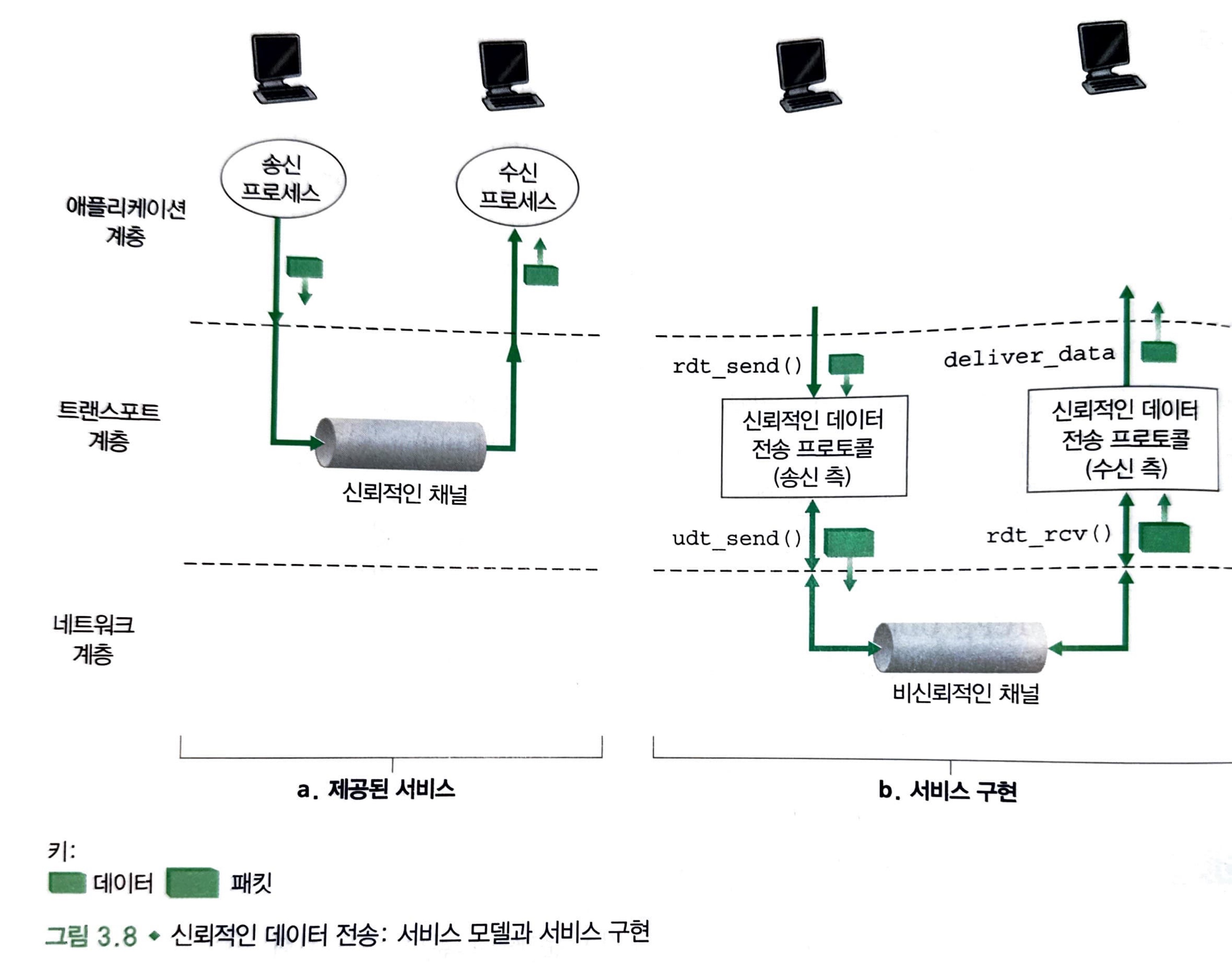
해당 그림은 신뢰적인 데이터 전송 연구에 대한 프레임워크를 보여줍니다.
상위 계층 개체에게 제공되는 서비스 추상화는 데이터가 전송될수 있는 신뢰적인 채널의 추상화입니다.
여기서 말하는 신뢰적인 채널은 데이터 손상과 손실이 없는 것을 의미합니다.
이러한 서비스 추상화를 구현하는 것은 신뢰적인 데이터 전송 프로토콜(reliable data transfer protocol)의 의무입니다.
여기서 다뤄볼 것은 크게 3가지 입니다.
- 데이터 손실과 오류가 나지 않는 경우
- 데이터 오류만 나는 경우
- 데이터 손실과 오류가 전부 나오는 경우
점차적으로 복잡해지는 하위 채널 모델을 고려하는 신뢰적인 데이터 전송 프로토콜을 점진적으로 개발해 나갈 것입니다.
여기서 일단 전제로 깔고 가는 것은 하부 채널은 패킷의 순서를 바꾸지 않는다는 것입니다.
즉, 손실이 될 수는 있지만, 순서가 바뀌는 일은 없다는 것입니다.
그리고 아래 두 용어를 구분 짓고 넘어가겠습니다.
- 패킷: 프로토콜 데이터 단위
- 세그먼트: 트랜스 포트 계층에서의 데이터 단위
데이터는 기본적으로 단방향 데이터 전송(unidirectional data transfer)의 경우만 고려하고 양방향(전이중)데이터 전송은 설명이 복잡하므로 일단 배제하고 가겠습니다.
완벽하게 신뢰적인 채널 상에서의 신뢰적인 데이터 전송: rdt1.0
먼저 하위 채널이 완전히 신뢰적인 경우 즉, 오류도 나오지 않고, 모든 패킷을 수신한다는 것으로 가정하고 가겠습니다.
선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.
여기서 유한상태 머신(finite-state machine, FSM)라는 용어가 나옵니다.
FSM은 송신자의 동작을 정의하고, 수신자의 동작을 정의합니다. 송신자에 대해서 그리고 수신자에 대해서 분리된 FSM이 있다는 것을 유의하고 가면 되겠습니다.
아래 그림을 봅시다.
해당 그림에 동작 순서를 적어 놓았습니다.
설명을 하자면, 점선으로 된 부분부터 시작을 합니다.
상위 계층으로 부터 데이터를 전달 받아서, 해당 데이터를 세그먼트로 나눠주고 헤더를 붙입니다.
네트워크 계층으로 해당 세그먼트를 내려주고 거기서 IP 헤더를 붙이고 캡슐화를 해서 데이터그램으로 만들어 줍니다.
이후 패킷으로 생성까지 완료가 된 후 채널로 송신하고 수신 측에서 받고 데이터를 추출해서 상위 계층으로 전달해주는 방식입니다.
해당 경우는 완전히 신뢰적인 채널을 가정해 놓았기 때문에 별도의 피드백이 필요하지 않습니다.
비트 오류가 있는 채널 상에서의 신뢰적 데이터 전송: rdt2.0
하위 채널의 더 실질적인 모델은 패킷 안의 비트들이 하위 채널에서 손상되는 모델입니다.
보통 오류는 패킷을 전송 또는 전파되거나 버퍼링될 때 발생합니다.
이러한 경우에 어떻게 처리해야 할까요?
만약 사람의 경우 말할 때 상대방이 못 알아 들었으면 상대방은 "What?" 하고 물어볼 수 있고, 알아 들었으면 "OK"라고 답변할 것입니다.
이것을 컴퓨터 네트워크에선 메시지 받아쓰기 프로토콜이 해주는데 2가지가 있습니다.
- 긍정 확인응답(positive acknowlegment, ACK)
- 부정 확인응답(negative acknowlegmetn, NAK)
일단 수신측으로 패킷을 보낼 때든가, 송신측으로 ACK나 NAK을 보낼 때든가 서로가 서로의 상황을 모르기 때문에 알려줘야 합니다.
즉 이러한 재전송을 기반으로 하는 신뢰적인 데이터 전송 프로토콜은 자동 재전송 요구(Automatic Repeat reQuest, ARQ) 프로토콜로 알려져 있습니다.
이 프로토콜은 3가지를 요구합니다.
- 오류 검출: 오류 검출 기능(ex. UDP checksum), 추가적인 비트들을 요구합니다.
- 수신자 피드백: 서로가 오류가 난 것을 알기 위해선 피드백이 필요하다. (1비트 요구)
- 재전송: 오류 패킷 재전송
송신측에서 패킷들을 보내고 이것에 대한 응답을 기다리는 동안, 즉 ACK와 NAK을 기다리는 동안에는 송신측에선 상위 계층으로부터 더 이상의 데이터를 받을 수 없습니다.
이러한 특징으로 인해서 rdt2.0과 같은 프로토콜은 전송-후-대기(stop-and-wait) 프로토콜로 알려져 있습니다.
여기서 확장되는 문제는 송신측에서 보내는 데이터가 오류가 나오는 것보다 수신측에서 보내는 응답이 오류가 나오는 경우입니다.선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.
만약 ACK 또는 NAK가 손상된다면, 송신자는 수신자가 전송된 데이터의 마지막 부분을 올바르게 수신했는지 알 방법이 없습니다.
이것을 처리하기 위해 3가지 가능성을 고려해 볼 것입니다.
- 오류가 검출되서 수신측에서 판단이 불가능한 경우 다시 물어보는 방식
- 응답 패킷에도 체크섬 비트들을 추가
- 왜곡된 ACK 또는 NAK 패킷을 받을 경우 현재 데이터 패킷을 단순히 다시 전송 즉, 중복 패킷(duplicate packet) 전송
여기서 사실 3가지 다 문제가 있다.
먼저 첫번째의 경우 다시 물어봤는데 그 또한 오류가 나온다면?
또 물어보게 될 것이고, 최악의 상황을 보면 같은 상황이 무한 반복할 수 있다.
두번째의 경우 체크섬 비트가 추가된다는 점이 문제다.
세번째의 경우 일단 효율성도 매우 떨어질 뿐더러, 송신자의 경우 수신자가 보낸 응답을 모른 채로 단순히 재전송을 하는 것이기 때문에 다음과 같은 상황이 벌어질 수 있습니다.
만약, 수신자 측에서 ACK를 보냈는데, 그것이 오류가 나와서 다시 같은 패킷들을 보내면 이 패킷들이 수신자 측에선 이전 패킷들과 전부 비교해보기 전에는 중복된 패킷인지 새로운 패킷인지 알 수가 없습니다.
위의 방식들은 죄다 효율이 떨어지는 것 같습니다. 사실 간단한 해결책이 존재하긴 합니다.
데이터 패킷에 새로운 필드를 추가하고 이 필드 안에 순서번호(sequence number)를 삽입하는 방식입니다.
현재 상황에서는 데이터의 손실을 배제해놓고 있으므로, 신경 쓸 필요가 없다.
수신자는 수신된 패킷의 순서 번호를 보고 가장 최근에 수신된 패킷과 비교하면서 동일하다면 다시 전송한 것이고, 순서번호가 변했다면 새로운 패킷을 보냈다고 판단할 수 있습니다.
송신측에서 응답을 할 때는
이것으로 송신자는 수신된 ACK와 NAK 패킷이 가장 최근에 전송된 데이터 패킷에 대한 응답으로 발생 된 것을 알 수 있습니다.
아래 그림을 봐봅시다.
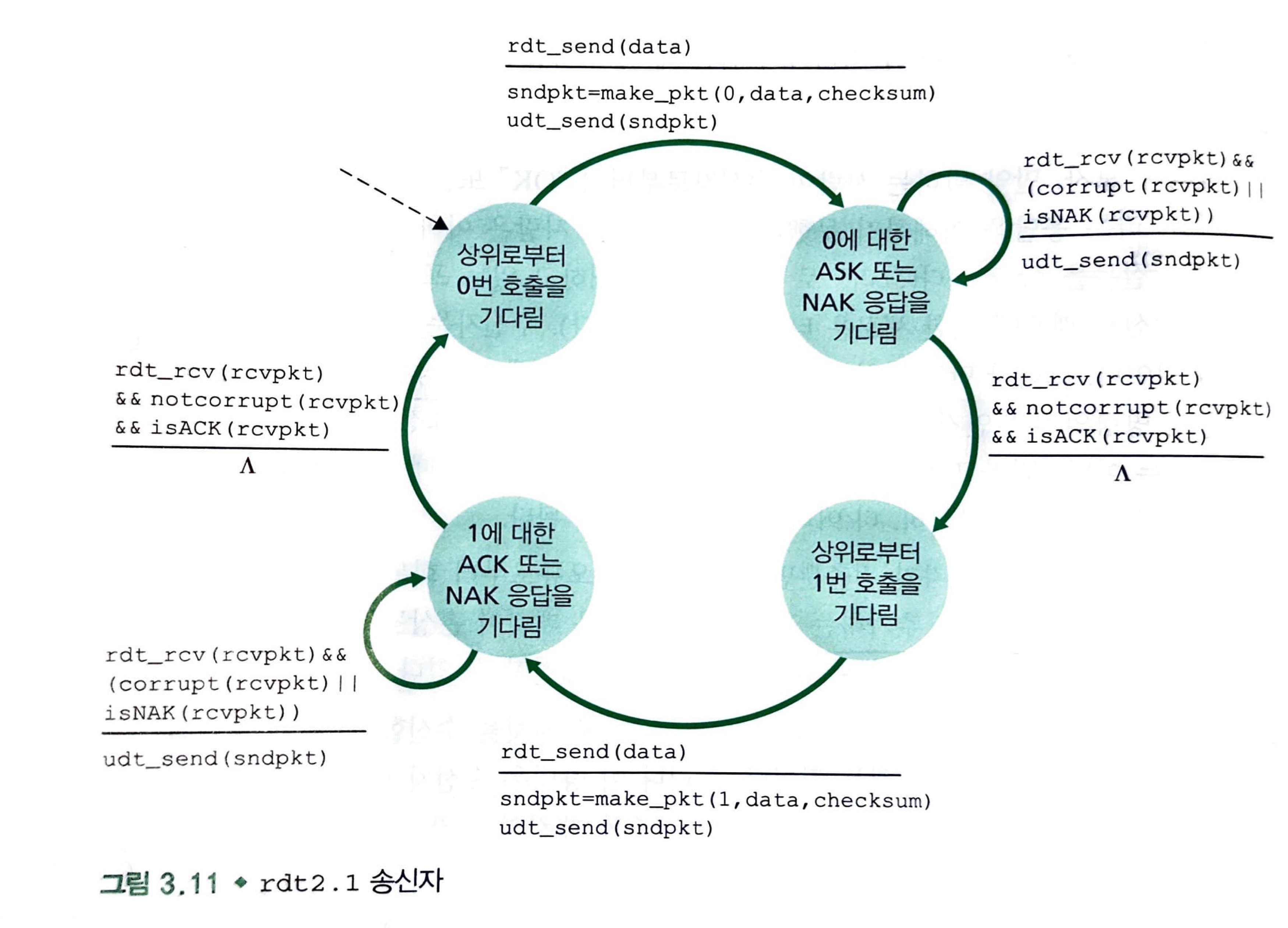
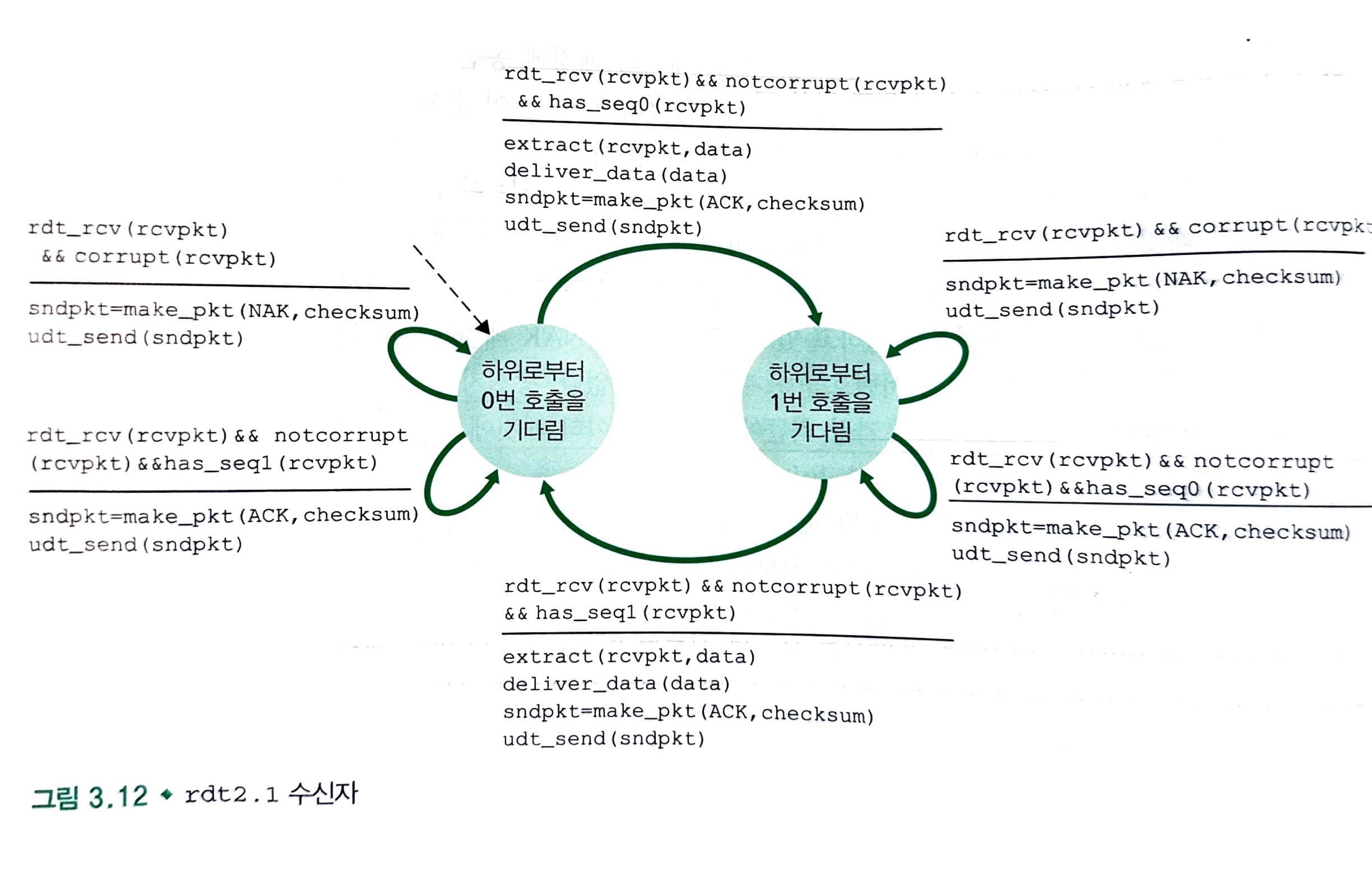
이것은 rdt2.0의 수정된 버전인 rdt2.1에 대한 FSM을 나타내고 있습니다.
현재 송신자와 수신자 FSM 각각은 전보다 두 배 많은 상태를 가지고 있습니다.
여기서 0과 1은 순서번호를 의미하는 것으로, 순서 번호 0번 패킷이 전송되고 있으면 순서 번호 1번 패킷이 기다리고 있는 것이고, 그 반대의 경우도 나타냅니다.
이제 수신자는 송신자에게 패킷을 받고나서 ACK와 NAK으로 보내는 대신 가장 최근에 받았던 패킷의 순서 번호를 보냄으로써 같은 효과를 볼 수 있습니다.
만약 중복된 같은 패킷에 대해서 2개의 ACK(같은 순서번호)를 받았다면 이것은 중복(duplicate) ACK를 수신한겁니다.
당연히, 송신자는 수신자가 보내는 패킷의 순서번호를 반드시 검사해야 합니다.
비트 오류와 손실 있는 채널 상에서의 신뢰적 데이터 전송: rdt3.0
이 경우에는 두 가지를 추가적으로 신경 써야 합니다.
- 어떻게 패킷 손실을 검출할 것인가?
- 패킷 손실이 발생했을 때 어떤 행동을 할 것인가?
2번의 경우 체크섬, 순서번호, ACK 패킷, 재전송의 사용이 가능하게 해줍니다.
송신자에게 손실된 패킷의 검출과 회복 책임을 부여할 것인데, 여기서 만약 송신자가 패킷을 전송하고 패킷 또는 수신자의 패킷에 대한 ACK를 손실했다고 가정해 봅시다.
어느 경우에나 송신자에게는 어떠한 응답이 돌아오지 않습니다.
송신자가 충분한 시간을 기다릴 수 있다면 이것은 크게 문제가 되지 않습니다.
그런데 얼마나 기다려야 할까요?
많은 네트워크들에서는, 이 최악의 최대 지연 시간은 예측하기조차 매우 어렵습니다.
그리고 무엇보다도 프로토콜이 패킷 손실을 가능한 빨리 복구해주는 것이 이상적입니다.
그렇다면, 손실이 되었든 아니든 적절한 시간을 설정한 후 재전송하는 방식을 채택하는 것이 가능해 보입니다.
하지만, 이것으로 인해 중복 데이터 패킷(duplicate data packet)의 가능성을 포함합니다.
물론, 이전까지 순서번호를 다루지 않았을 때는 패킷을 까보고 확인해야 되는 번거로움이 방해되었지만 지금은 충분한 기능을 가지고 있습니다.
적절한 시간을 설정해주기 위한 카운트다운 타이머(countdown timer)이 필요해 보이네요.
- 매 패킷(첫 번째 또는 재전송 패킷)이 송신된 시간에 타이머를 시작함.
- 타이머 인터럽트에 반응함(적당한 행동을 취함)
- 타이머를 멈춤
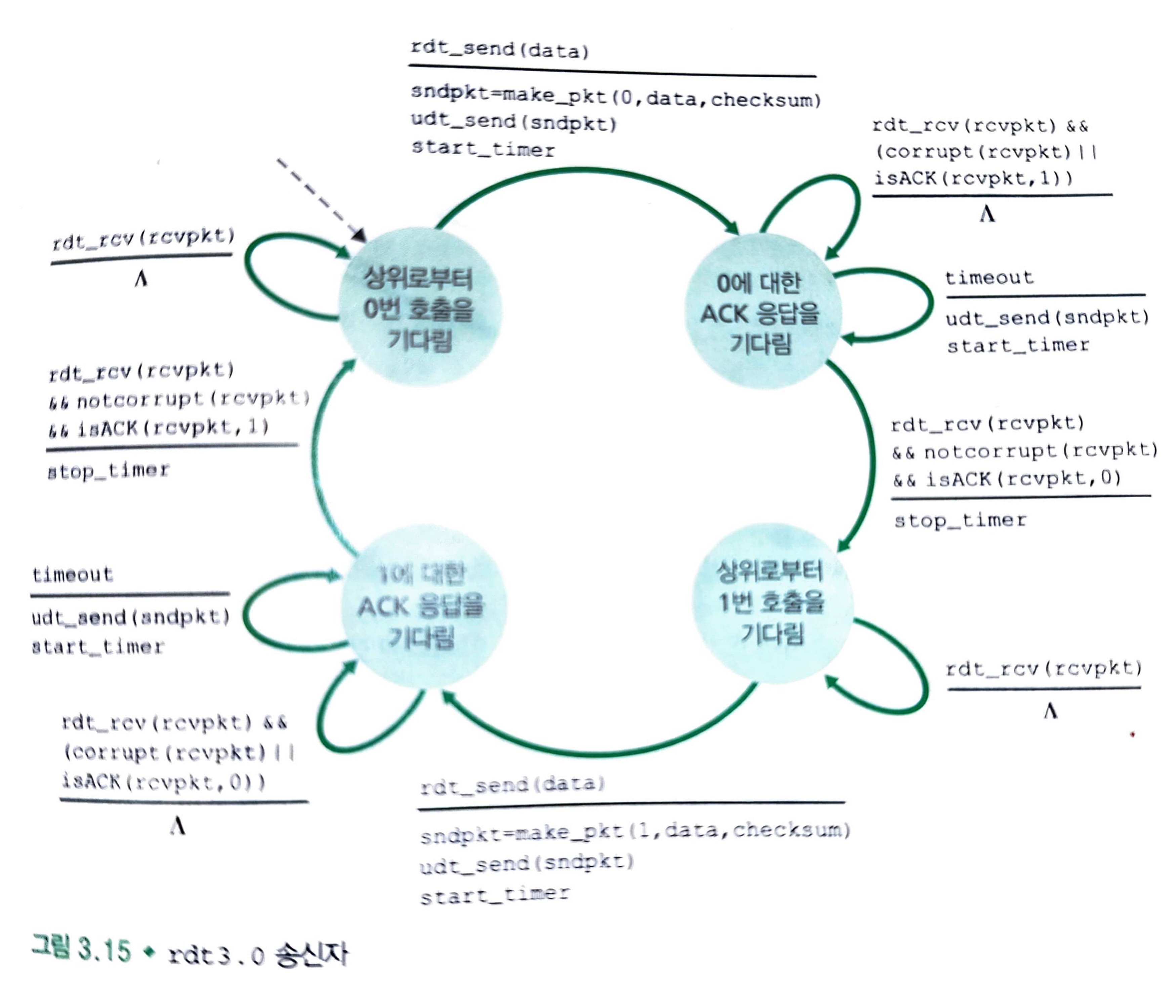
현재 그림은 패킷이 손상되거나 손실될 수 있는 채널에서 데이터를 신뢰적으로 전송하는 프로토콜인 rdt3.0 송신자 FSM을 보여줍니다.
선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.
해당 그림은 시간은 다이어그램의 위로부터 아래로 움직인다.

즉, 패킷에 대한 수신 시간은 전송 지연과 전파 지연 때문에 패킷 전송 시간보다 더 늦습니다.
위 사진에서 보시다싶히, 패킷의 순서번호가 0과 1이 번갈아 일어납니다.
이러한 특징 때문에 프로토콜 rdt 3.0은 때때로 얼터네이팅 비트 프로토콜(alternate-bit protocol)이라고 부릅니다.
파이프라인된 신뢰적 데이터 전송 프로토콜
위에서 봤던 프로토콜 rdt3.0은 이제 기능적으로 정확한 프로토콜로 보입니다. 하지만, 핵심적인 성능 문제가 있습니다. 바로 전송-후-대기(stop-and-wait) 프로코콜이라는 것입니다.
예를 들어, 하나의 호스트는 미국 서부에 위치하고, 다른 하나는 동부에 위치한 두 종단 호스트가 데이터를 주고 받는다고 해봅시다.
이 두 종단 시스템 사이의 광속 왕복 전파 지연(RTT)은 대략 30ms이고 이것들이 1Gbps(초당 ) 전송률(R)을 가진 채널에 의해서 연결되어 있다고 가정해봅시다.
패킷당 1,000바이트의패킷 크기(L)를 전송한다고 했을 경우 필요한 시간은 다음과 같습니다.
결국 패킷을 전부 밖으로 내보내는데 걸리는 시간은 0.008ms입니다.
패킷이 대륙을 횡단하는 시간은 15ms이므로 패킷이 송신자부터 수신자까지 도달하는데 걸리는 시간 t는 다음과 같습니다.
수신자가 받고나서 ACK 패킷을 보내는 것까지 생각을 하면 다음과 같습니다.
여기서 이 아닌 이유는 ACK 패킷은 데이터 패킷에 비하면 크기가 매우 작기 때문에 고려할 대상이 되지 않기 때문입니다.
선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.
송신자가 채널을 통해 실제적으로 분주하게 비트를 전송하는데만 걸린 시간을 송신자의 이용률(utilization) 수식으로 정의한다면 다음과 같습니다.
송신자는 30.008ms 동안 1000바이트를 송신할 수 있지만, 비록 초당 1Gbps의 링크가 가용하다 하더라도 267 kbps의 유효 처리량(effective throughput)을 가집니다.
이러한 특별한 성능 문제를 해결하기 위해서 파이프라이닝(pipelining) 기술이 도입됩니다.
❗ 파이프라이닝(pipelining): 확인응답을 기다리지 않고 여러 패킷을 허용하는 것입니다.
이 기능은 다음과 같은 중요성을 가지고 있습니다.
- 순서의 범위가 커져야 합니다.
- 유일한 순서번호를 가져야 하며, 확인 응답이 안 된 패킷이 여러 개일 수 있기 때문입니다.
- 프로토콜의 송신 측과 수신 측은 한 패킷 이상을 버퍼링 해야 합니다.
- 최소한 송신자는 전송되었으나 확인응답 되지 않은 패킷을 버퍼링해야 합니다. (수신자에게도 필요)
- 필요한 순서번호의 범위와 버퍼링 조건은 응선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.답하는 방법에 의존합니다.
파이프라인 오류 회복은 두 가지 접근방법이 있습니다.
- N부터 반복(Go-Back-N, GBN)
- 선택적 반복(Selective Repeat, SR)
N부터 반복(Go-Back-N, GBN)
❗ GBN 프로토콜에서 송신자는 확인응답을 기다리지 않고 여러 패킷을 전송(가능할 때)할 수 있어야 합니다.
그림을 통해 살펴봅시다.
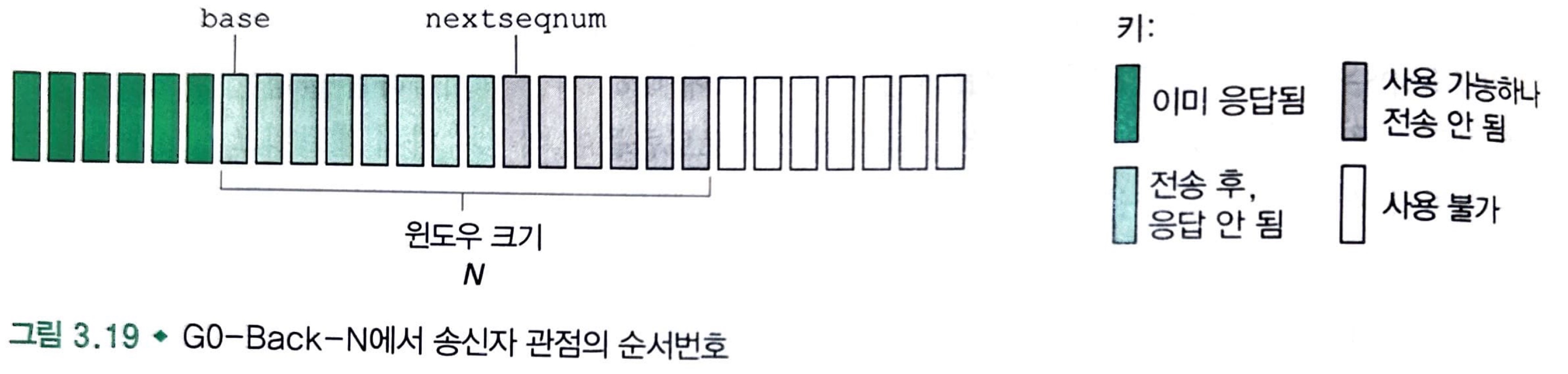
확인 응답이 안 된 가장 오래된 패킷의 순서번호를 base로 정의하고 사용되지 않은 가장 작은 순서번호를 nextseqnum(전송될 다음 패킷의 순서번호)으로 정의한다면, 순서 번호의 범위에서 4개의 간격을 식별할 수 있습니다. 간격 [0, base - 1]에서 순서번호는 이미 전송되고 확인응답이 된 패킷에 대응합니다. 간격 [base, nextseqnum - 1]은 송신은 되었지만 아직 확인응답 되지 않은 패킷에 대응됩니다. 간격 [nextseqnum, base + N - 1]은 상위 계층으로부터 데이터가 도착하면 바로 전송될 수 있는 패킷을 위하여 사용될 수 있습니다. 마지막으로, base + N이상의 순서번호는 파이프라인에서 확인응답 안 된 패킷(여기서는 순서번호 base를 가진 패킷으로 가정)의 확인응답이 도착할 때 까지 사용될 수 없습니다.
⚡ 윈도우 ⚡
전송되었지만 아직 확인응답 안 된 패킷을 위해 허용할 수 있는 순서번호의 범위를 의미합니다. 여기서는 크기가 N입니다.
패킷이 도착할 때마다 윈도우는 오른쪽으로 이동(slide)합니다.
이러한 이유 때문에 N을 윈도우 크기(window size)라 부르며, GBN 프로토콜은 슬라이딩 윈도우 프로토콜(sliding-window protocol)이라고 부릅니다.
윈도우 크기를 설정하는 것은 흐름제어가 송신자에게 제한을 가하는 한 가지 이유입니다. 나중에 자세하게 다룰 예정입니다.
패킷의 순서번호는 패킷 헤더 안의 고정된 길이 필드에 포함됩니다. 만약 k가 패킷 순서번호 필드의 비트 수라면, 순서번호의 범위는 이 됩니다.
TCP 순서번호는 패킷 단위보다는 바이트 스트림에서 바이트를 세는 수입니다.
마지막으로 볼 확장된 FSM을 살펴보겠습니다.
이 FSM은 ACK 기반의 NAK 없는 GBN 프로토콜입니다.
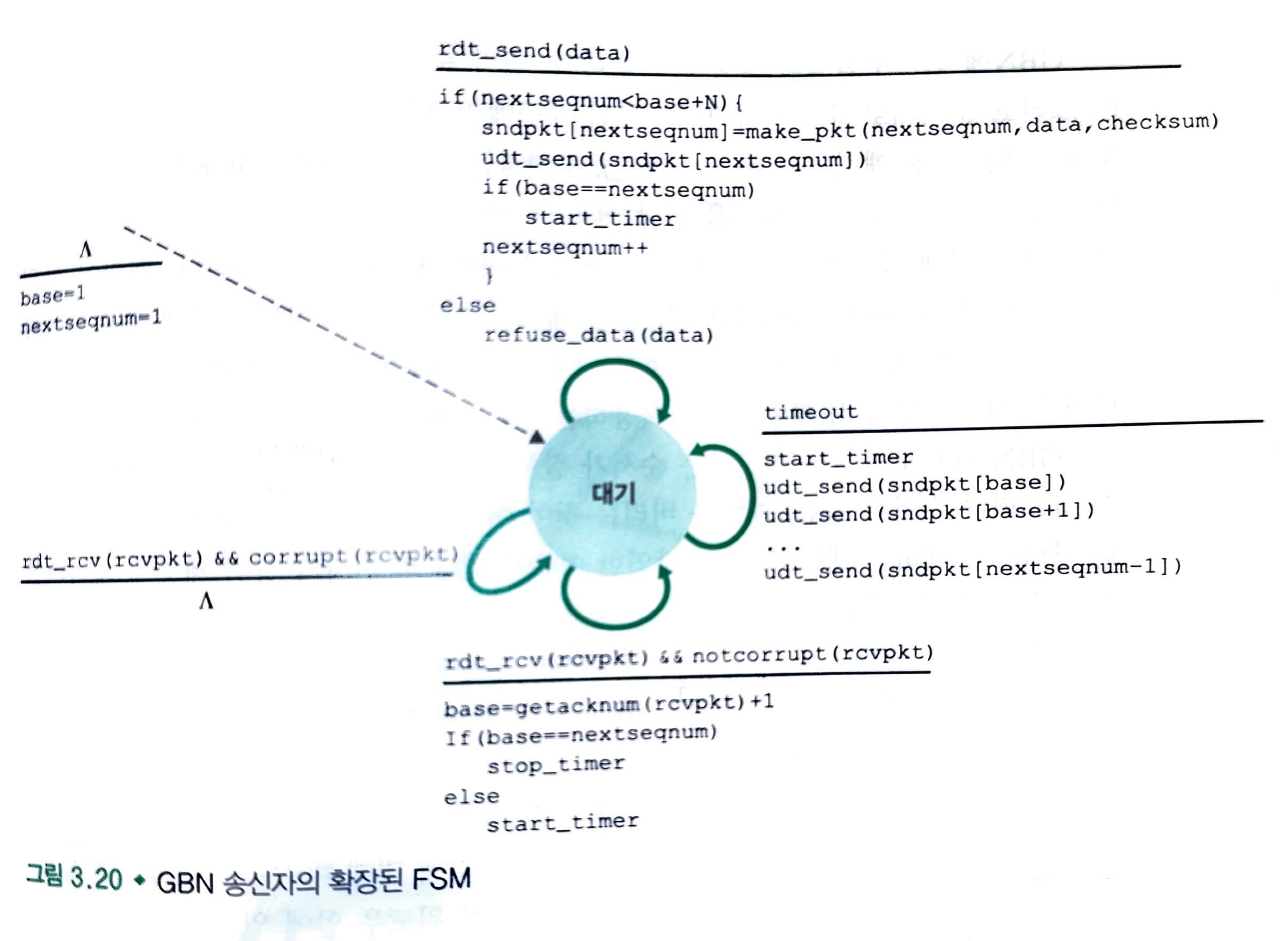
GBN 송신자는 다음과 같은 세 가지 타입의 이벤트에 반응해야 합니다.
- 상위로부터의 호출: rdt_send()가 위로부터 호출되면, 송신자는 윈도우가 가득 찼는지, 즉 N개의 아직 확인응답 되지 않은 패킷이 있는지를 확인합니다.
- 공간이 있다면: 패킷 생성, 송신
- 공간이 없다면: 데이터 반환
- ACK의 수신: GBN 프로콜에서 순서번호 n을 가진 패킷에 대한 확인응답은 누적 확인응답(cumulative acknowledgment)으로 인식됩니다.
- 타임아웃 이벤트: 타이머는 손실된 데이터 또는 손실된 확인응답 패킷으로부터 회복하는데 사용됩니다.
- 만약 타임아웃이 발생한다면, 송신자는 이전에 전송되었지만 아직 확인응답 되지 않은 모든 패킷을 다시 전송합니다.
해당 구조에서의 프로시저(procedure)들은 이벤트-기반 프로그래밍(event-based programming)에서의 프로시저라고 볼 수 있습니다.
다양한 프로시저들은 프로토콜 스택에서 다른 프로시저에 의해서 야기되거나 인터럽트의 결과로 요청될 것입니다.
간단하게 정리해보자.
수신자측
- 순서 번호 N까지 순서대로 수신
- 패킷 n에 대한 ACK를 송신
- 상위 계층에 패킷의 데이터 부분을 전달.
- 손실이 발생하여, 순서 번호 K까지 순서대로 수신
- K까지 재대로 전달되었다는 ACK를 송신
- K까지의 패킷들을 상위 계층에 전달
기껏 받은 패킷들을 하나의 패킷 손실 때문에 버리는 상황이 발생할 수 있는 것입니다. 낭비가 굉장히 심합니다. 또한, 이것의 기본 방식은 순서대로 패킷이 전달되어야 되는 것인데 뒤에서 나올 것이지만, 여러 개의 둘 이상의 연결을 요구하는 "채널"이 네트워크 일 경우, 패킷 순서가 바뀔 수 있으므로 문제가 또 발생한다.
예를 들어, 패킷 n + 1이 먼저 도착했으면, 패킷 n + 1을 저장하고 나중에 패킷 n이 수신되면 상위 계층에 전달될텐데 여기서 패킷 n이 손실된다면 패킷 n과 n + 1을 전부 재전송할 것입니다.
물론, 이러한 방식은 수신자의 버퍼링이 간단하다는 이점이 있습니다.
수신자는 단지 다음 순서 패킷의 순서번호만 유지하면 됩니다.
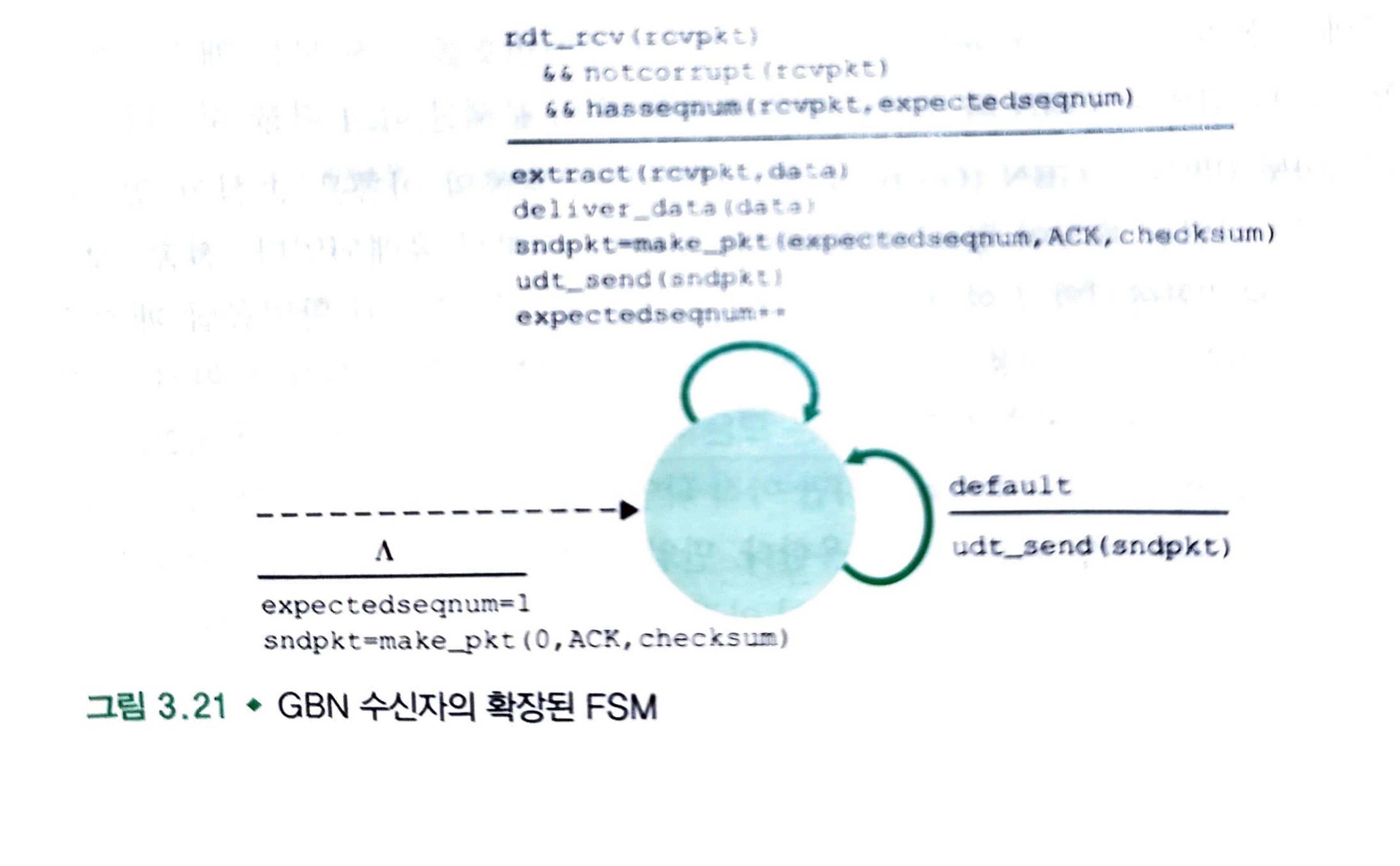
수신자측의 FSM이 확실히 간단한 것으로 확인이 됩니다.
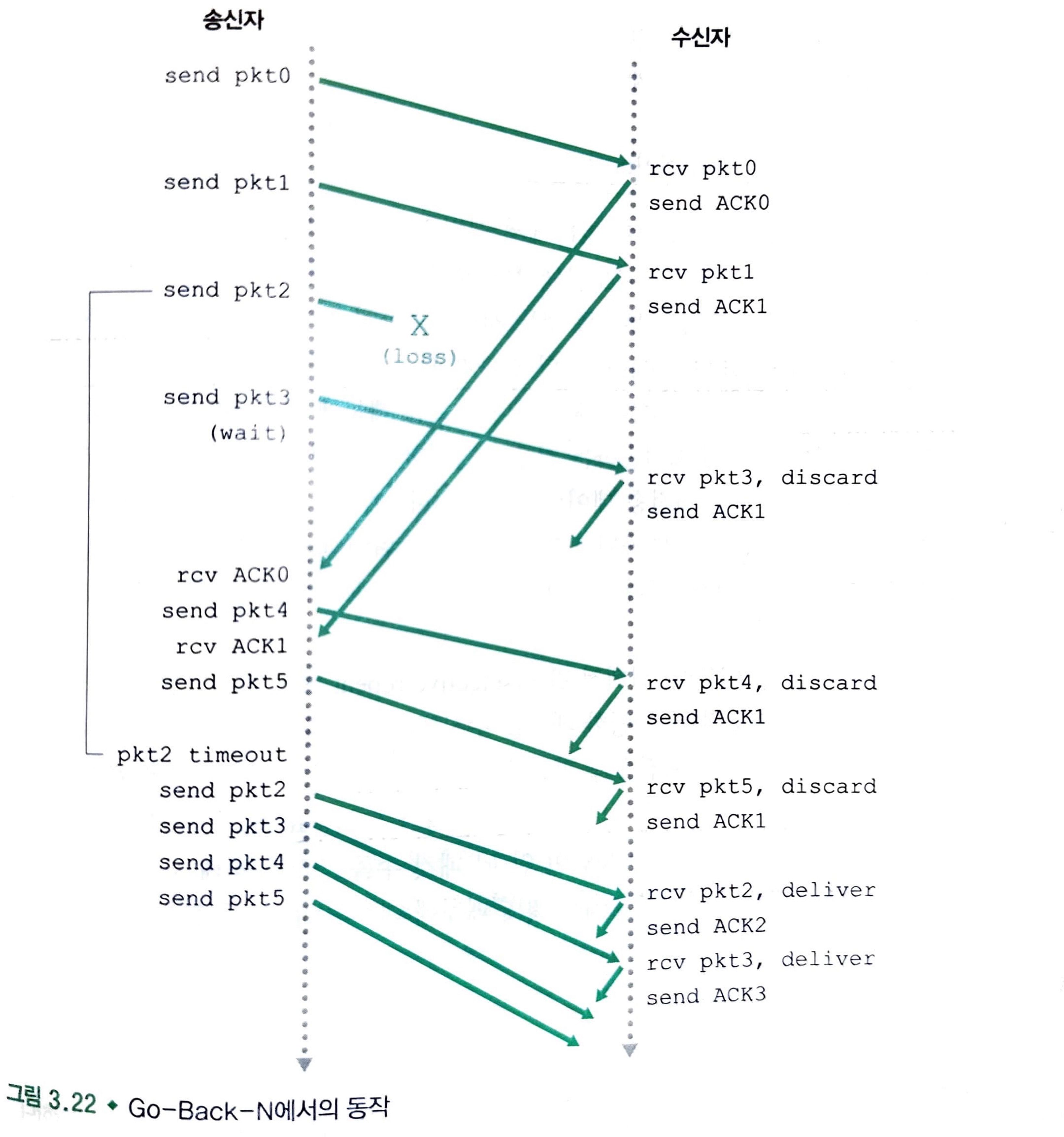
다음은 윈도우의 크기가 4인 경우에 대한 GBN 프로토콜의 동작을 보여줍니다.
윈도우의 크기 제한 때문에 송신자는 패킷 0 부터 3까지 송신합니다.
하지만 패킷 2가 손실이 일어난 상황입니다.
그래서 패킷 3, 4, 5는 전부 버리는 상황입니다.
선택적 반복(Selective Repeat, SR)
사실 이전에 봤던, 전송-후-대기 프로토콜에서의 채널 이용률 문제를 피하도록 GBN 프로토콜은 파이프라인을 채우는 것으로 문제를 해결했습니다.
하지만, 여전히 문제가 있습니다.
특히 윈도우 크기와 "밴드폭-지연(bandwidth-delay)" 곱의 결과가 모두 클 때, 많은 패킷들이 파이프라인에 있을 수 있습니다.
이러한 상황에서 만약 패킷의 손실이 발생했다고 생각해보아라. 파이프라인안에 있는 패킷들은 전부 버려질 것이다.
이러한 문제를 해결해주는 선택적 반복 프로토콜을 살펴봅시다.
❗ 선택적 반복(seletive repeat, SR) 프로토콜은 수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 송신자가 다시 전송하므로 불필요한 재전송을 피합니다.
필요에 따라 각각의 개별적인 재전송은 수신자가 올바르게 수신한 패킷에 대한 개별적인 확인응답을 요구할 것입니다.
여기서, 주목해야할 점은 당연히 의심되는 패킷을 어떻게 찾아내냐가 중요하겠네요.
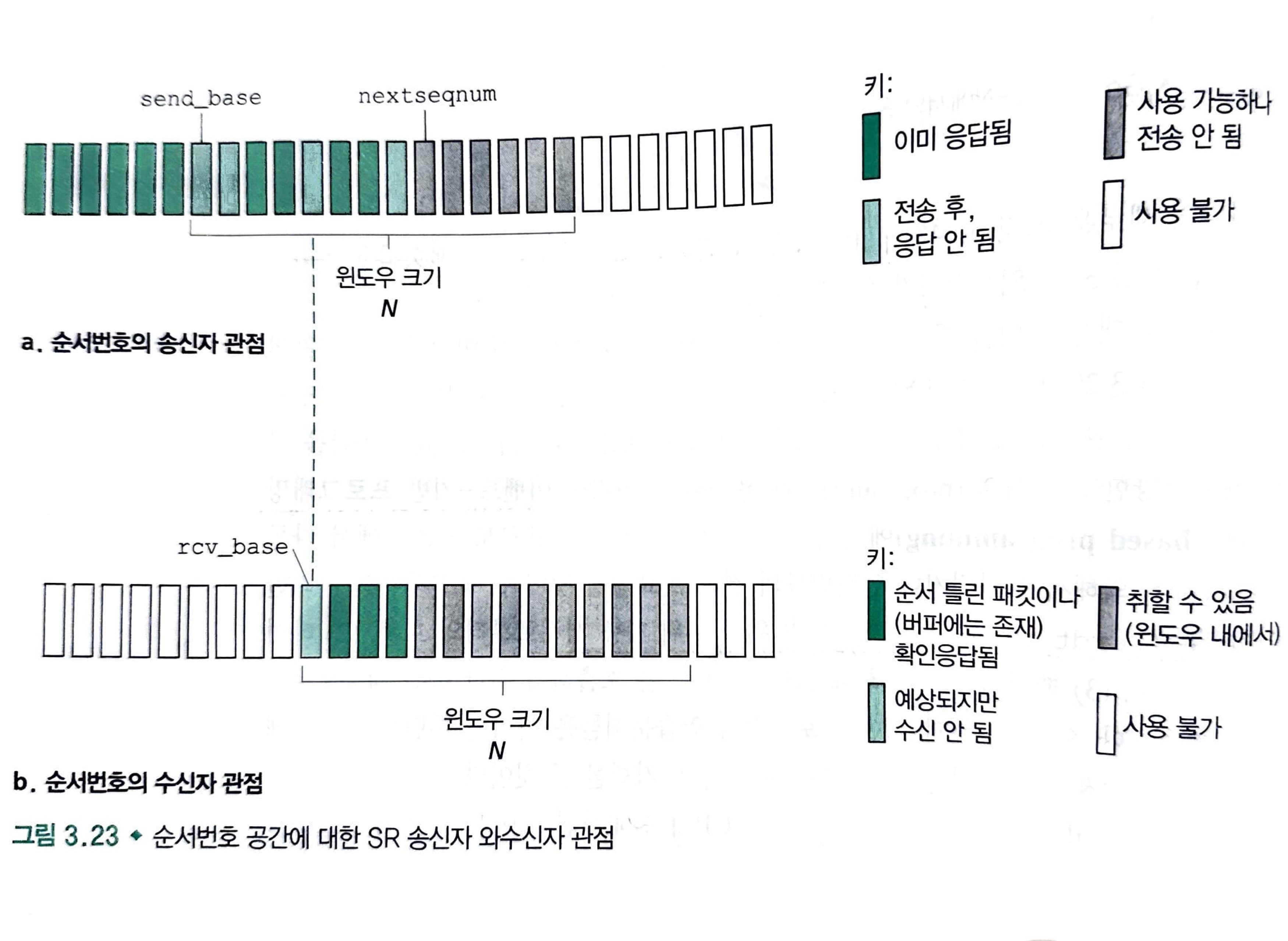
윈도우 크기 N은 파이프라인에서 아직 확인응답이 안 된 패킷 수를 제한하는 데 사용됩니다. 그러나 GBN과는 달리 송신자는 윈도우에서 몇몇 패킷에 대한 ACK를 이미 수신했을 것입니다.
그러나 GBN과는 달리 송신자는 윈도우에서 몇몇 패킷에 대한 ACK를 이미 수신했을 것입니다.
다음은 SR 송신자 이벤트와 행동을 정리한 것입니다.
- 상위로부터 데이터 받음: 상위에서 데이터가 수신될 때, SR 송신자는 패킷의 다음 순서번호를 검사합니다.
a. 순서번호가 송신자 윈도우 내에 있으면, 데이터는 패킷으로 송신
b. 그렇지 않으면 GBN처럼 버퍼에 저장 또는 나중에 전송하기 위해 상위 계층으로 되돌려짐 - 타임아웃: 타이머는 손실된 패킷을 보호하기 위해 다시 사용된다.
a. 오직 한 패킷만이 타임아웃에 전송되기 때문에, 각 패킷은 자신의 논리 타이머를 가진다. - ACK 수신: ACK가 수신되었을 때, SR 송신자는 그 ACK가 윈도우에 있다면 그 패킷을 수신된 것으로 표기한다.
a. 만약 패킷 순서번호가 send_base와 같다면, 윈도우 베이스는 가장 작은 순서번호를 가진 아직 확인응답 되지 않은 패킷으로 옮겨집니다.
b. 만약 윈도우가 이동하고 인도우 내의 순서번호를 가진 미 전송 패킷이 있다면, 이 패킷들은 전송됩니다.
이번엔 SR 수신자 이벤트와 행동을 살펴봅시다.
- [rcv_base, rcv_base + N -1] 내의 순서번호를 가진 패킷은 손상 없이 수신된다.
a. 이 경우는 수신된 패킷이 수신자의 윈도우에 속하며, 선택적인 ACK 패킷이 송신자에게 되돌려 집니다.
b. 만약 이 패킷이 이전에 수신되지 않았던 것이라면, 버퍼에 저장됩니다.
c. 만약 이 패킷 수신 윈도우의 base와 같은 순서번호를 가졌다면, 이 패킷과 이전에 버퍼에 저장되어 연속적으로 번호가 붙은(rcv_base로 시작하는) 패킷들은 상위 계층으로 전달됩니다. - [rcv_base - N, rcv_base - 1] 내의 순서번호를 가진 패킷이 수신된다. 이 경우에는 이 패킷이 수신자가 이전에 확인응답한 것이라, ACK가 생성되어야 합니다.
- 이외의 경우. 패킷을 무시한다.
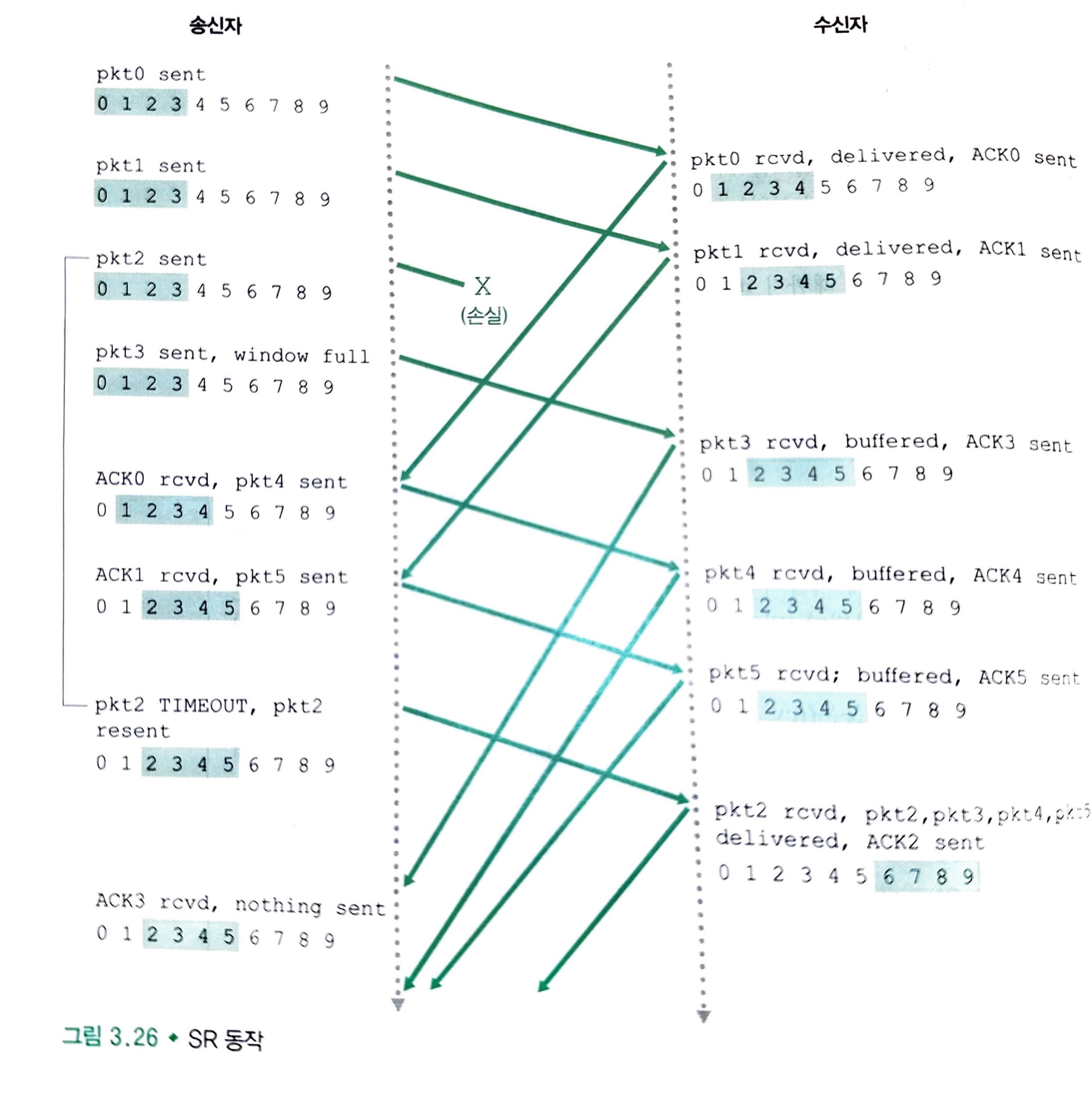
해당 그림은 손실된 패킷이 나타날 때까지의 SR 동작의 예를 보여줍니다.
여기서 패킷 2가 손실이 잃어 났기 때문에 패킷 3, 4, 5는 상위 계층으로 보내지지 않고, 버퍼에 저장됩니다.
여기서 중요한 것은, 수신자가 현재의 인도우 base보다 아래의 특정 순서번호를 가진 이미 수신된 패킷을 무시하지 않고 재확인하는 것이 중요합니다.
반드시 재확인이 필요합니다.
에를 들어 다음 상황을 확인해 봅시다.
송신자와 수신자의 순서 번호 공간이 주어지면, 수신자가 송신자에게 전파하는 send_base 패킷에 대한 ACK가 없다면, 수신자가 그 패킷을 이미 수신했음이 분명하더라도 결국 송신자는 send_base패킷을 재전송할 것입니다. 송신자의 윈도우는 이동하지 않습니다.
이는 SR 프로토콜에서 송신자와 수신자의 윈도우가 항상 같지 않다는 점을 의미합니다.
송신자와 수신자 윈도우 사이의 동기화 부족은 순서번호의 한정된 범위에 직면했을 때 중대한 결과를 가져옵니다.
다음 사진을 확인해 봅시다.

한정된 범위의 네 개의 패킷 순서번호 0, 1, 2, 3과 윈도우 크기 3에서 어떤 일이 일어날 수 있는가를 생각해 봅시다.
패킷 0부터 2까지 올바로 수신되고, 그때 수신자의 윈도우는 각각의 순서번호가 3, 0, 1인 4, 5, 6번째 패킷에 있습니다. 여기서 두 가지 시나리오을 고려해 볼 수 있습니다.
첫 번째 시나리오는 처음 3개의 패킷에 대한 ACK가 손실되고 송신자는 이 패킷을 재전송하는 경우입니다.
그 다음에 수신자는 순서번호가 0인 패킷(처음 보낸 패킷의 복사본)의 수신합니다.
두 번째 시나리오에서 처음 3개의 패킷에 대한 ACK가 모두 올바르게 전달되었습니다. 그러면 송신자는 자신의 윈도우를 앞으로 이동시켜 각각의 순서번호가 3, 0, 1인 4, 5, 6번째 패킷을 보냅니다. 순서번호 3을 가진 패킷이 손실되고, 순서번호 0을 가진 패킷(새로운 데이터를 포함한 패킷)은 도착합니다.
두 호스트 사이에는 상징적인 커튼이 있어서 서로 볼 수 없다고 생각하면 됩니다.
두 시나리오 다 근본적으로 문제는 같습니다.
다
수신자 측은 다섯 번째 패킷의 원래 전송과 첫 번째 패킷의 재전송을 구별할 수 있는 방법이 없습니다.
왜냐하면 앞에서 패킷 전송에 문제가 발생했을 때 비교하기 위해서 ACK, NAK나 오류 검출 비트 같은 방식 대신 순서번호만을 활용한다고 했습니다. 즉, 윈도우 크기가 위와 같이 되어 있는 시점에선 순서 번호가 같은 패킷의 경우 같은 패킷으로 간주해 버릴 수 밖에 없는 것입니다.
이런 문제가 야기되지 않기 위해서는 윈도우의 크기를 조절해야 합니다.
따라서, 윈도우 크기는 SR 프로토콜에 대한 순서번호 공간 크기의 절반 보다 작거나 같아야 합니다.
확장판
앞서 미리 언급하긴 했지만, 사실 둘을 연결하는 "채널"이 네트워크일 때, 패킷 순서 바뀜이 일어날 수 있습니다.
패킷의 순서 바뀜의 현상으로, 송신자와 수신자가 x를 포함하지 않고 있더라도, 순서번호 또는 확인응답번호 x를 가진 오래된 패킷의 복사본들이 생길 수 있습니다.
패킷 순서가 바뀌는 채널이라는 것은, 본질적으로 패킷들을 버퍼에 저장하고, 나중에 어느 때나 이 패킷들을 임의로 내보낸다고 간주할 수 있습니다.
순서번호가 재사용될 수 있으므로 그런 중복된 패킷들을 막을 수 있는 조치가 있어야 합니다. 실제 방식은 송신자와 순서번호 x를 가진 이전에 송신된 패킷들이 더이상 네트워크에 없다는 것을 어느 정도 "확신"할 때 까지 순서번호가 재사용되지 않음을 확실히 하는 것입니다.
이는 패킷이 어느 일정 시간 이상으로 네트워크에서 "존재"할 수 없다는 가정에 의해서 이루어집니다.
대략 3분의 최대 패킷 수명 시간이 고속 네트워크에 대한 TCP 확장에 가정되어 있습니다[RFC 1323].
다른 페이지에서 다룰 예정이지만, 사실 타임 아웃만을 이용하는 방법만 존재하는 것은 아닙니다. 이제까지의 방식을 살펴보면서, 손실이 발생했을 경우 우리가 확인하는 방법이 무엇이었는지 다시 한번 생각해 봅시다.
그렇습니다. 손실된 패킷의 순서 번호를 수신측에서 ACK에 담아서 보내주었습니다. 즉, 우리는 ACK에 담긴 손실된 패킷의 순서 번호를 받아서 손실이 난 것을 확인했습니다.
그렇다면, 중복된 순서 번호를 몇 번 이상 받았을 때 손실로 간주하고 처리할 수 있지 않을까?
이 방식은 Fast Retransmit을 해주는 Three duplicate ack라고 합니다.
다른 페이지에서 다룰 예정이니 여기까지하고 넘어가겠습니다.
Reference
