시작하기 앞서...
먼저 UDP를 알아보기 앞서 알아야 되는 개념이 있습니다.
- Process
- Socket
해당 내용은 UDP를 설명하면서 반복해서 나오는 용어이기 때문에 알아두고 진행해야 된다고 판단했습니다.
이 내용은 아래 링크에서 다루었으니 모르신다면 참고하고나서 읽으시면 이해가 더욱 원할하게 될 것입니다.
참고: Process와 Socket
먼저 UDP를 다뤄보기 전에 UDP 소켓 객체에 대해서 다루고 넘어가겠습니다.
UDP 소켓 프로그래밍
송신 프로세스가 데이터의 패킷을 소켓 문밖으로 밀어내기 전에, UDP를 사용할 때 먼저 패킷에 목적지 주소를 붙여 넣어야 한다.
여기서, 목적지 호스트에서 하나 혹은 그 이상의 소켓을 갖는 많은 네트워크 애플리케이션을 수행하고 있을 수 있기 때문에 IP주소만이 아니라 소켓이 생성될 때 포트 번호(port number)라고 하는 식별자도 보내줘야 한다.
기본적인 동작 방식을 보자면 다음과 같습니다.
- 클라이언트는 키보드로부터 한 줄의 문자(데이터)를 읽고 그 데이터를 서버로 보낸다.
- 서버는 그 데이터를 수신하고 문자를 대문자로 변환한다.
- 서버는 수정된 데이터를 클라이언트에게 보낸다.
- 클라이언트는 수정된 데이터를 수신하고 그 줄을 화면에 나타낸다.
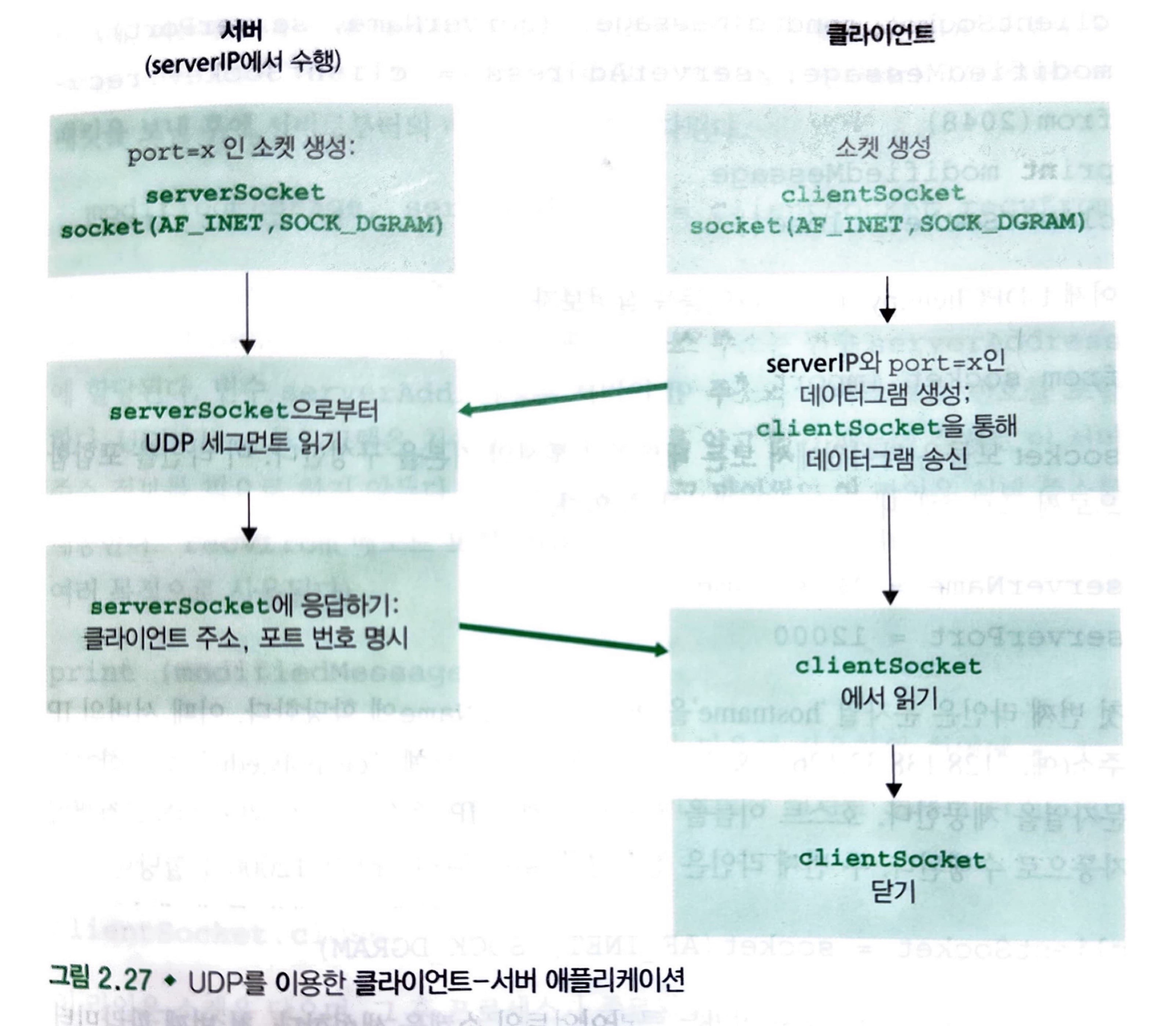
여기서의 코드는 최소한의 코드만으로 제공되는 것을 인지하고 확인하면 됩니다.
먼저, 애플리케이션 클라이언트 쪽은 다음과 같신습니다.
from socket import *
serverName = 'hostname'
serverPort = 12000
clientSocket = socket(socket.AF_INEF, socket.SOCK_DGRAM)
message = raw_input('Input lowercase sentence:')
clientSocket.sendto(message.encode(), (serverName, serverPort))
modifiedMessage, serverAddress = clientSocket.recv-from(2048)
print (modifiedMessage.decode())
clientSocket.close()이제 동작들을 하나씩 살펴봅시다.
from socket import *socket 모듈은 파이썬에서 모든 네트워크 통신의 기본을 구성합니다. 이 라인을 포함함으로써 프로그램 내에 소켓을 생성할 수 있습니다.
serverName = 'hostname'
serverPort = 12000서버의 주소 혹은 서버의 호스트 이름을 포함한 문자열과 포트 번호를 정수 12000으로 할당했습니다.
이때 호스트 이름을 사용하는 경우 IP 주소를 얻기 위해 DNS 검색이 자동을 수행됩니다.
clientSocket = socket(socket.AF_INEF, socket.SOCK_DREAM)이 라인은 clientSocket이라는 클라이언트의 소켓을 생성합니다.
첫번째 파라미터는 주소군(family)을 나타냅니다. 특히, AF_INET는 하부 네트워크가 IPv4를 사용하고 있음을 나타냅니다.
두번째 파라미터는 소켓이 UDP소켓임을 의미하는 SOCK_DREAM 타입을 나타냅니다. 소켓을 생성할 때 클라이언트 소켓의 포트 번호를 명시하지 않아도 되며, 운영체제가 이 작업을 대신 수행합니다.
message = raw_input('Input lowercase sentence:')
clientSocket.sendto(message.encode(), (serverName, serverPort))사용자가 필요한 메세지를 입력하고 보내기 위해 바이트 형태로 바꿔줘야 합니다.
encode()메서드를 사용해서 문자열 타입의 메시지를 바이트 형태로 변환해주고, 목적지의 주소를 메시지에 붙여서 그 패킷을 소켓인 clientSocket으로 보냅니다. (소스 주소도 패킷에 붙이는데 이것은 자동으로 수행됩니다.)
modifiedMessage, serverAddress = clientSocket.recv-from(2048)패킷이 클라이언트의 소켓에 인터넷으로부터 도착하면 패킷 데이터는 modifiedMessage에 할당되고 패킷의 소스 주소는 변수 serverAddress에 할당 됩니다. 2048은 버퍼의 크기를 의미합니다.
이후 메시지를 문자열로 바꾼 후 출력을 하고 소켓을 닫으며, 그 후 프로세스가 종료됩니다.
이제 애플리케이션 서버 쪽을 봅시다.
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
serverSocket.bind(('', serverPort))
print("The server is ready to receive")
while True:
message, clientAddress = serverSocket.recvfrom(2048)
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)시작은 유사합니다.
serverSocket.bind(('', serverPort))위 라인은 포트 번호 12000을 서버의 소켓에 할당하는 것입니다. 즉, UDPServer의 코드는 명시적으로 포트 번호를 소켓에 할당합니다. 이렇게 서버 IP 주소의 12000 포트로 패킷을 보내면 해당 소켓으로 패킷이 전달되는 것입니다.
그 뒤 UDPSever는 클라이언트로부터 계속해서 패킷을 수신하고 처리할 수 있도록 while 루프로 들어갑니다. while 루프에서 UDPSever는 패킷이 도착하기를 기다립니다.
message, clientAddress = serverSocket.recvfrom(2048)패킷이 서버에 도달하면 위와 동일하게 메시지와 패킷의 소스 주소가 각각 할당됩니다.
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)그 후 대문자로 바꿔주고 변환된 메시지를 붙이고, 그 결과로 만들어진 패킷을 서버의 소켓으로 보냅니다.
그 뒤 인터넷은 패킷을 클라이언트 주소에 보냅니다.
패킷을 보낸후 서버는 while 루프에서 머무르며 다른 UDP패킷이 도착하기를 기다립니다.
UDP(User Datagram Protocol)
일단 UDP가 어떻게 동작하는지 확인해 봅시다.
[RFC 786]에서 정의된 UDP는 트랜스포트 께층 프로코로이 할 수 있는 최소 기능으로 동작합니다.
⚡ RFC ⚡
RFC(Request for Comments) 문서는 비평을 기다리는 문서라는 의미로, 컴퓨터 네트워크 공학 등에서 인터넷 기술에 적용 가능한 새로운 연구, 혁신, 깁버등을 아우르는 메모를 나타냅니다.
UDP는 다중화/역다중화 기능과 간단한 오류 검사 기능을 제외하고 IP에 아무것도 추가하지 않습니다.
즉, UDP를 이용한 애플리케이션은 거의 IP와 직접 통신하는 셈이죠.
UDP는 프로세스로부터 메시지를 가져와서 다중화/역다중화 서비스에 대한 출발지, 목적지 포트 번호 필드를 첨부하고 다른 두 필드들을 추가한 후 최종 세그먼트를 네트워크 계층으로 넘겨줍니다.
네트워크 계층은 트랜스포트 계층 세그먼트를 IP 데이터그램으로 캡슐화하고, 세그먼트를 수신 호스트에게 "최선형" 전달 서비스로 전달합니다.
⚡ 최선형 전달 서비스 ⚡
IP 계층이 데이타그램의 전송을 위하여 최대의 노력을 하지만, 확실한 전송을 보장하지 않습니다.
즉, 데이터의 흐름이 많거나 적거나 간에 시간지연이 없도록 하는 등의 신뢰성을 보장하지 않습니다.
수신 호스트에 도착한다면, UDP는 세그먼트의 데이터를 해당하는 애플리케이션 프로세스로 전달하기 위해서 목적지 포트 번호를 사용합니다.
순서를 정리하자면 다음과 같습니다.
- UDP가 수신측 프로세스로부터 Message Receive
- src port + dest port + 2개 필드 추가
- 네트워크 계층 전달 후 IP datagram으로 캡슐화
- "최선형" 전달 서비스로 전달
- 수신 호스트의 UDP가 역 다중화
DNS는 일반적으로 UDP를 사용하는 애플리케이션 계층 프로토콜의 예입니다.
왜 DNS는 UDP를 사용하는 것일까요?
애초부터 애플리케이션 개발자는 TCP 방식보다 UDP를 선호하는 경우가 많습니다.
이러한 이유가 무엇일까요?
UDP의 특징
여기서는 TCP와 비교해서 UDP의 특징을 살펴볼 것입니다. 먼저, 장점을 살펴보고 그 이후 단점을 살펴볼 예정입니다.
장점
❗ 무슨 데이터를 언제 보낼지에 대해 애플리케이션 레벨에서 더 정교한 제어
UDP의 경우 데이터를 전달 받자마자 UDP 세그먼트로 만들고, 즉시 그 세그먼트를 네트워크 계층으로 전달합니다.
이에 반해서, TCP는 혼잡제어 메커니즘을 가지고 있습니다.
이 혼잡제어 메커니즘은 TCP를 다루는 부분에서 자세히 다루겠지만, 간단하게 말하자면 과도하게 트래픽이 쌓이면, 트랜스포트 계층 TCP 송신자를 조절하는 방법을 말합니다.
또한 TCP는 신뢰적인 전달이 얼마나 오래 걸릴지에 대해 관계없이 목적지가 세그먼트의 수신 여부를 확인응답 할 때 까지 데이터 세그먼트 재전송을 계속 할 것입니다.
요즘 같이, 실시간 애플리케이션을 많이 사용하는 시대에서 이러한 지연은 바라지 않습니다.
실시간 애플리케이션은 종종 최소 전송률을 요구하고, 지나치게 지연되는 세그먼트 전송을 원하지 않으며, 조금의 데이터 손실은 허용할 수도 있으므로, TCP의 서비스 모델과 맞지 않는 것입니다.
❗ 연결 설정이 없다.
TCP는 세 방향 핸드셰이크를 사용합니다. 하지만, UDP는 형식적인 예비 동작이 없습니다.
즉, UDP는 연결을 설정하기 위한 어떤 지연도 없는 것입니다.
실제로 이 연결 설정 지연은 HTTP에서 웹 문서의 다운로드 지연에 심각한 공헌자라고 합니다.
❗ 작은 패킷 헤더 오버헤드
UDP는 기능이 많이 추가되지 않은 만큼 TCP보다 더 작은 헤더의 크기가 추가됩니다.
TCP가 세그먼트마다 20바이트의 헤더 오버헤드를 갖는 반면에 UDP는 단지 8바이트의 오버헤드를 가집니다.
이러한 UDP의 특징에 부합되는 애플리케이션이 많기 때문에 TCP보다 UDP를 선호되는 애플리케이션이 있는 것입니다.
실제로 네트워크 관리 애플리케이션의 경우 네트워크가 혼잡한 상태에서 오히려 더 잘 동작되어야 하므로 UDP를 사용합니다. (과도한 상태에서 신뢰적이거나 혼잡제어 된 데이터 전송 수행은 어렵다.)
UDP가 사용되는 예시로는 스트리밍 멀티미디어, 인터넷 폰, 네트워크 관리, 이름 변환, 원격 파일 서버, 등등 여러 분야에서 사용되고 있습니다.
하지만, 이러한 특징으로 인해 UDP가 TCP보다 좋다? 이것은 아닙니다. UDP의 단점을 살펴보겠습니다.
단점
먼저, TCP를 사용하는 예시를 먼저 살펴보고 UDP의 단점을 확인해 보겠습니다.
TCP를 사용하는 예시로는 전자메일, 원격 터미널 접속, 웹, 파일 전송, 스트리밍 멀티미디어, 인터넷 폰, 등등 입니다.
이러한 것들은 왜 TCP가 선호될까요?
바로 "신뢰성"이 애플리케이션에서 요구되기 때문입니다.
단점을 살펴보면 TCP를 사용하는 이유를 알 수 있습니다.
❗ UDP는 혼잡제어를 하지 않는다.
위에서 장점에서 혼잡제어를 하지 않기 때문에 오히려 빠른 전송이 가능하다고 했습니다.
하지만, 모두가 혼잡제어를 사용하지 않고 높은 비트의 비디오 스트리밍을 시작한다고 가정해 보겠습니다.
라우터에서 많은 패킷 오버플로가 발생할 것이고, 이는 소수의 UDP 패킷만이 출발지-목적지 간의 경로를 무사히 통과하게 만들 것입니다.
사실 여기서 중요한 점은 이로 인해서 야기되는 효과입니다.
제어되지 않은 UDP 송신자에 의해서 발생된 높은 손실률은 그 손실률을 감소시키기 위해 TCP 송신자들이 속도를 줄이도록 합니다.
❗ 이러한 특징으로 인해 UDP는 DDos 공격에 사용되기도 합니다. ❗
UDP에는 핸드셰이크가 필요하지 않으므로 공격자는 먼저 해당 서버의 통신 시작 권한을 얻지 않고도 대상 서버에 UDP 트래픽을 '폭주 시킬'수 있습니다.
UDP 세그먼트 구조
UDP 세그먼트 구조는 RFC 768에 정의되어 있습니다.
UDP 헤더는 2바이트씩 구성된 4개의 필드를 가집니다.
포트 번호로는 출발지와 목적 포트 번호가 필요로 하고, 길이 필드는 헤더를 포함하는 UDP 세그먼트의 길이를 나타냅니다. 체크섬이란 오류 검출 기능이 들어가 있습니다.
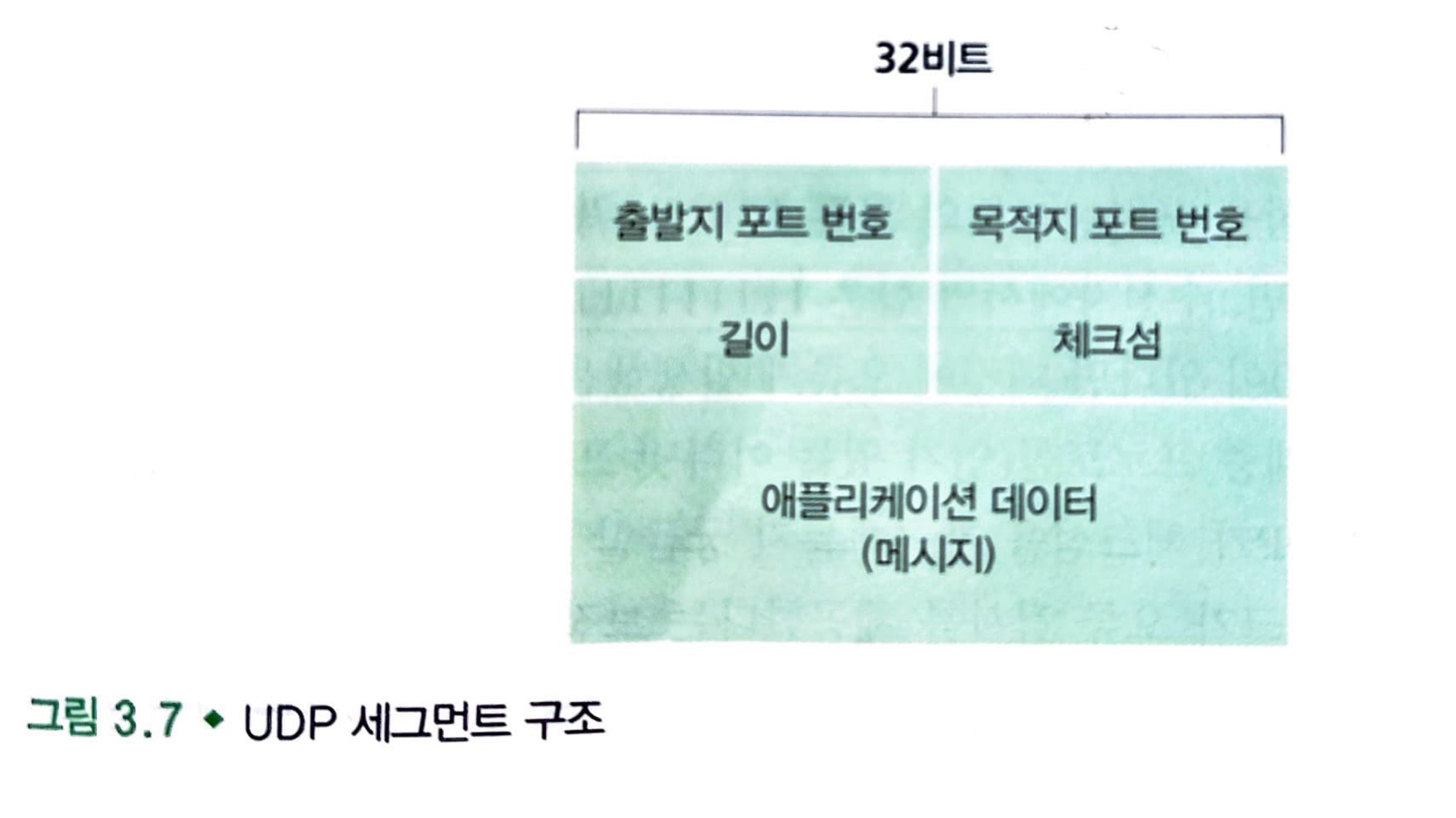
체크섬(checksum)은 세그먼트에 오류가 발생했는지를 검사하기 위해 수신 호스트에 의해서 사용됩니다.
UDP 체크섬
UDP 체크섬은 오류 검출 기능을 제공합니다.
즉, 체크섬은 세그먼트가 출발지로부터 목적지로 이동했을 때, UDP 세그먼트 안의 비트에 대한 변경사항이 있는지 검사하는 것입니다.
기본적인 방식은 다음과 같습니다.
송신 측에서 UDP는 세그먼트 안에 있는 모든 16 비트 워드 단위로 더하고 이에 대하여 1의 보수를 수행합니다. 덧셈 과정에서 발생하는 오버플로는 "윤회식 자리올림(wrap aruond)"를 합니다.
⚡ Wrap around ⚡
가령 unsigned 최대값 255에 계속 +1을 해나가면 값은 다시 0으로 돌아오고 1, 2, 3, 4, ...으로 이어집니다. 이와 같이 순환하는 것을 가르켜서 Wrap around라고 합니다.
signed 연산에서는 overflow가 발생시 양수가 음수로 되거나 음수가 양수로 Wrap around 됩니다.
마지막에 1의 보수를 수행했기 때문에 패킷이 아무 오류 없이 도착했다면, 수신지에서의 합은 1111,1111,1111,1111이 될것입니다. 만약 비트 중에서 하나라도 0이 있다면 패킷에 오류가 있음을 의미합니다.
사실 많은 링크 계층 프로토콜(인기 있는 이더넷 프로토콜을 포함)이 오류 검사를 하는데, 굳이 UDP가 체크섬을 할 필요가 있나 생각할 수 있습니다.
하지만, 출발지와 목적지 사이의 모든 링크가 오류 검사를 제공한다는 보장이 없기 때문입니다.
이것이 시스템 설계[Saltzer 1984]에서의 유명한 종단간의 원리(end-end principle)의 한 예입니다.
⚡ 종단간의 원리(end-end principle) ⚡
'어떤 기능은 종단 기반으로 구현되어야 하므로, 하위 레벨에 위치한 기능들은 상위 레벨에서 이 기능들을 제공하는 비용을 비교했을 때 중복되거나 거의 유용하지 않을 수 있다.'
즉, 하위 계층에서 오류 검출 서비를 제공할 수 있다고 해서 상위 계층이 이러한 서비스 제공을 포기해서는 안된다는 것입니다.
Reference
