신뢰적인 데이터 전달을 위한 프로토콜 선정
앞서 인터넷의 네트워크 계층(IP 서비스)은 비신뢰적이라고 배웠습니다.
인터넷 프로토콜은 데이터그램 전달을 보장하지 않고, 데이터그램이 순서대로 전달되는 것을 보장하지도 않습니다. 또한, 데이터그램에 포함된 데이터의 무결성(integrity)을 보장하지도 않습니다.
TCP는 IP의 비신뢰적인 "최선형(best-effort)" 서비스에서 신뢰적인 데이터 전달 서비스(reliable data transfer service)를 제공합니다.
이 부분에선 TCP가 어떻게 신뢰적인 데이터 전송을 제공하는지 2개의 점진적인 단계들로 알아볼 것입니다.
- 소실 세그먼트를 복구하기 위해 타임아웃만을 사용하는 TCP 송신자의 매우 간소화된 설명을 보여줄 것입니다.
- 다음으로 타임아웃에 추가하여 중복 확인응답을 이용하는 좀 더 완전한 설명을 보여줄 것입니다.
현재까지 배웠던 내용을 정리하자면 다음과 같습니다.
- TCP는 데이터를 세그먼트로 만들어 주면서 세그먼트의 첫 번째 데이터 바이트의 바이트열 번호인 순서 번호를 매깁니다.
- IP datagram으로 만들어 주면서 데이터를 전달해 줍니다.
- 수신측에서 받고 ACK를 보내줍니다.
이 과정에서 타임 아웃이 발생하는 것까지 알아봤습니다.
몇 가지 시나리오를 보면서 위에서 언급한 중복 확인응답을 어떻게 활용하는지 보겠습니다.
먼저 첫번째 시나리오입니다.
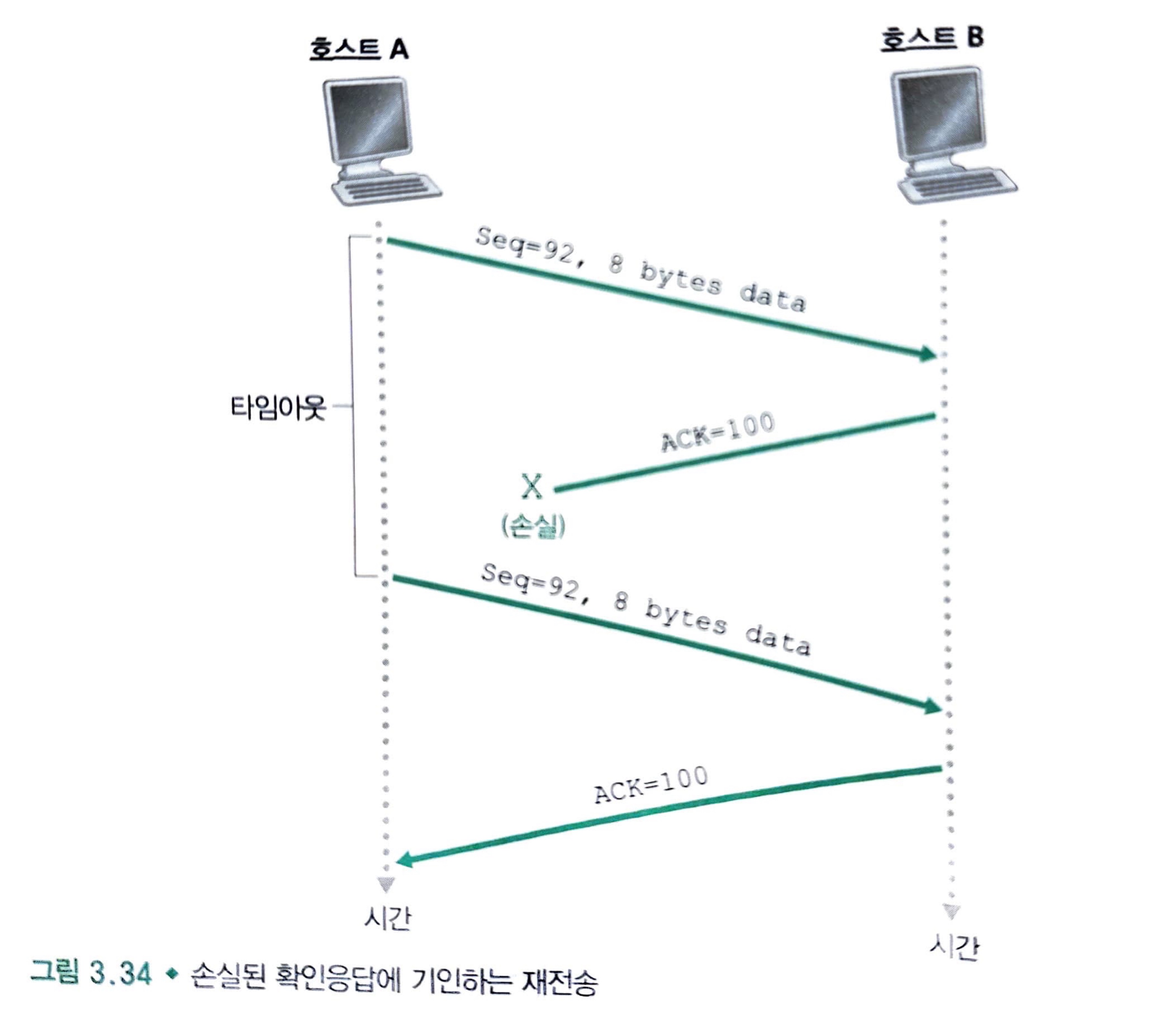
호스트 A가 호스트 B에게 세그먼트 순서번호가 92인 8바이트의 데이터를 보낸다고 가정해 봅시다.
호스트 A는 호스트 B로부터 긍정 확인응답 번호 100을 가진 세그먼트를 기다리지만 이것이 손실되어서 결국 타임 아웃이 발생하는 경우입니다.
두번째 시나리오입니다.
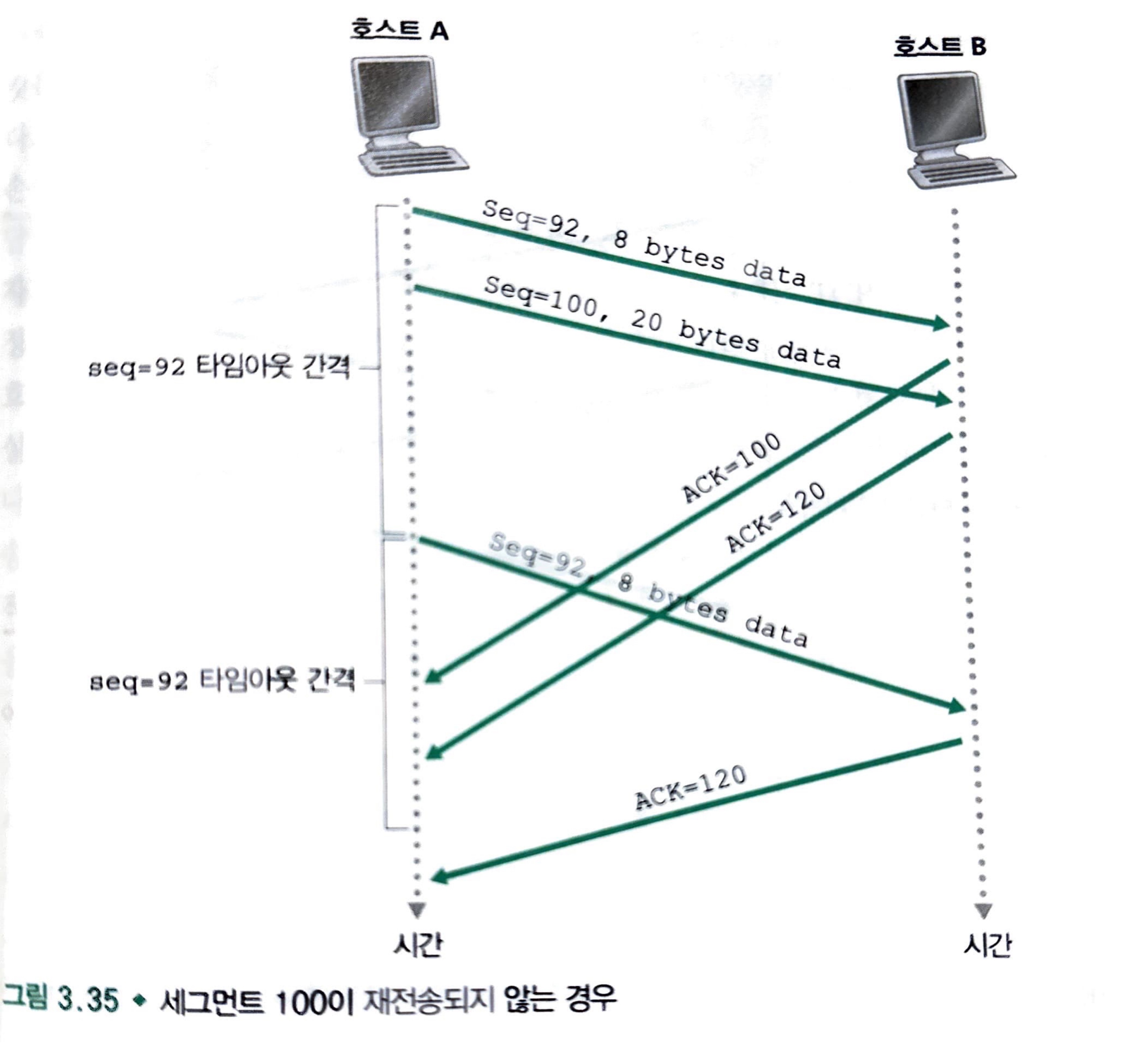
호스트 A가 연속해서 두 세그먼트를 전송합니다.
첫 번째 세그먼트는 순서번호 92와 8바이트의 데이터를 가지고 있고, 두 번째 세그먼트는 순서번호 100과 20바이트의 데이터를 가지고 있습니다.
두 세그먼트 모두 무사히 호스트 B에게 도착을 한다고 가정을 하고, B는 2개의 개별적인 긍정 확인응답을 전달합니다. 이러한 긍정 확인응답 중 첫 번째는 긍정 확인응답 번호 100을 가집니다.
반면, 두 번째 확인응답은 응답번호 120을 가집니다. 호스트 A에서 첫 번쨰 세그먼트의 타임아웃 이전에 긍정 확인응답을 받지 못하는 상황입니다.
호스트 A는 순서번호 92로 첫 번째 세그먼트를 재전송하고 타이머를 다시 시작합니다.
새로운 타임아웃 이전에 두 번째 세그먼트에 대한 ACK가 도착하면 두 번째 세그먼트는 재전송을 하지 않을 것입니다.
세번째 시나리오입니다.
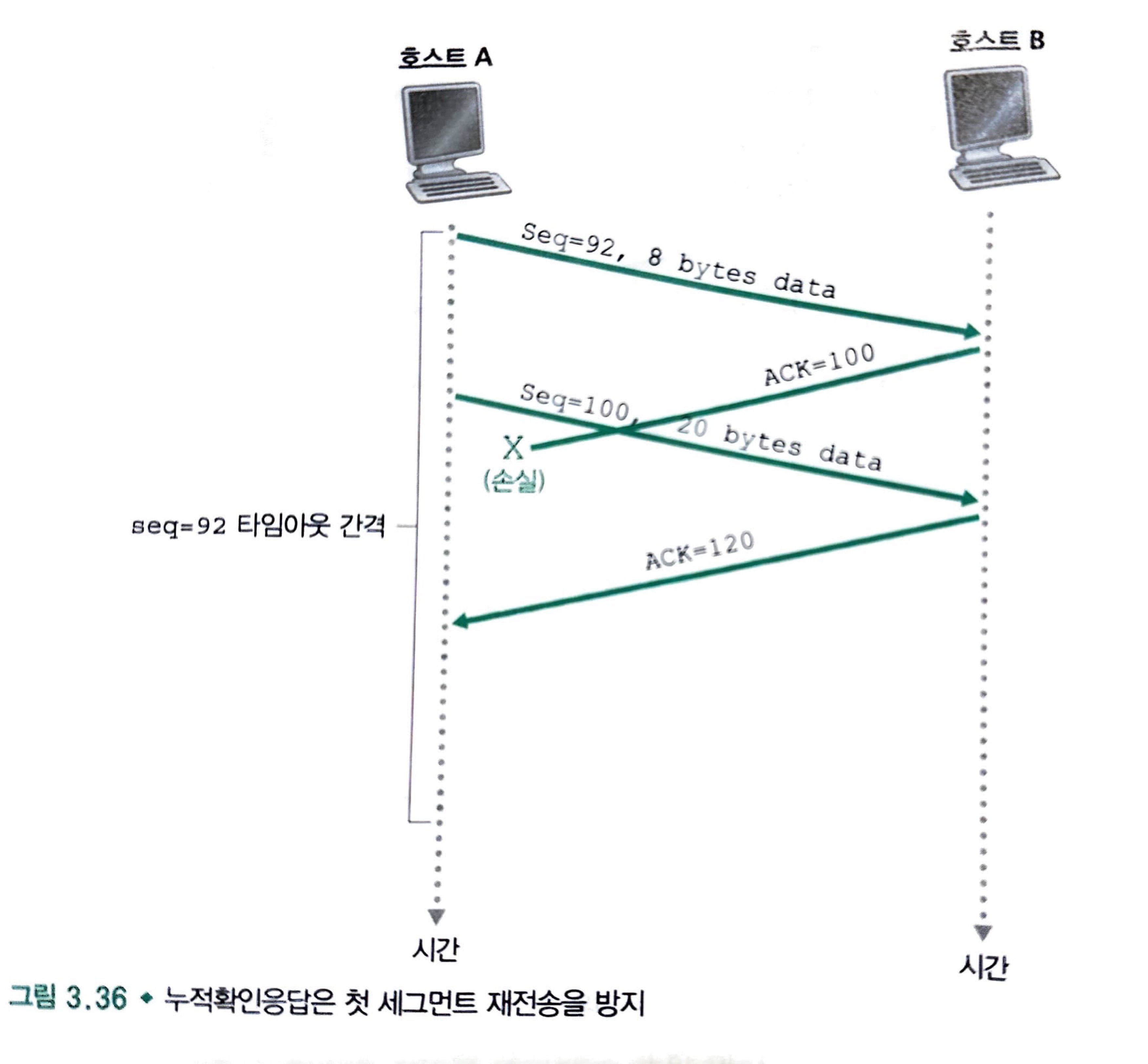
마지막 시나리오는 두 번째 예처럼 호스트 A가 2개의 세그먼트를 전송한다고 가정하는 것입니다.
첫 번째 세그먼트의 긍정 확인응답이 네트워크에서 분실되었지만, 첫 번째 세그먼트의 타임아웃 전에 호스트 A가 긍정 응답 번호 120의 긍정 확인응답을 수신하면, 호스트 A는 호스트 B가 119바이트까지 모든 데이터를 수신했다는 것을 알게 됩니다.
타임아웃 주기의 두 배로 설정
여기서 타임 아웃이 발생하고 TCP가 재전송 때마다 마지막 EstimateRTT와 DevRTT로부터 타임아웃값을 가져오는 것이 아니라 타임아웃 주기를 이전 값의 두 배로 설정하는 것에 주목해야 합니다.
이러한 방식으로 진행되다가, 정상적으로 ACK를 받으면 두 가지 다른 사건들(즉, 상위의 애플리케이션으로부터 데이터 수신과 ACK 수신) 이후 타이머가 시작될 때에는 TimeoutInterval은 EstimateRTT와 DevRTT의 가장 최근값에서 가져옵니다.
이 방식으로 해결이 되는 것일까요?
타임아웃을 두 배로 늘린다는 것은 결국, 송신측에서 무책임하게 TimeoutInterval을 늘림으로써 "좀 늦게 도착해도 되니깐 일단 갔다 와바 그리고 수정할게"라는 것과 크게 다를바가 없어 보입니다.
타임아웃은 주로 네트워크에서의 혼잡에 의해 발생을 합니다.
"혼잡"하기에 Timeout이 발생한 것인데, 재전송을 계속하면 상황은 악화될 것입니다.
또한, 생각해보면 재전송이 일어나는 것 자체가 성능을 떨구는 것도 있습니다.
되도록이면 재전송이 일어나는 것은 피하는 것이 좋습니다.
빠른 재전송
타임 아웃이 유발하는 재전송의 문제점은 결국 타임아웃 주기가 너무 길어질 수 있다는 점입니다.
세그먼트를 잃었을 때, 긴 타임아웃 주기는 잃어버린 패킷을 다시 보내기 전에 송신자를 오랫동안 기다리게 해서 종단간의 지연을 증가시킵니다.
다행히도, 송신자는 타임아웃이 일어나기 전에 중복 ACK에 의한 패킷 손실을 발견합니다.
여기서 말하는 중복 ACK는 송신자가 이미 이전에 받은 확인응답에 대한 재확인응답 세그먼트 ACK를 말합니다.
앞서 송신자는 데이터 스트림의 제일 앞 번호를 순서 번호로 보내면서 확인 응답번호로 다음 보낼 것에 대한 순서 번호를 담아서 보낸다고 했습니다.
데이터의 손실이 일어났을 경우 그 다음 세그먼트가 보내는 확인 응답번호는 해당 세그먼트가 가지고 있던 확인 응답 번호를 보내는 것이 아닌 수신자가 손실 패킷 바로 이전 패킷인 세그먼트의 확인 응답번호를 보냅니다.
아래 사진을 보면 이해가 될 것입니다.
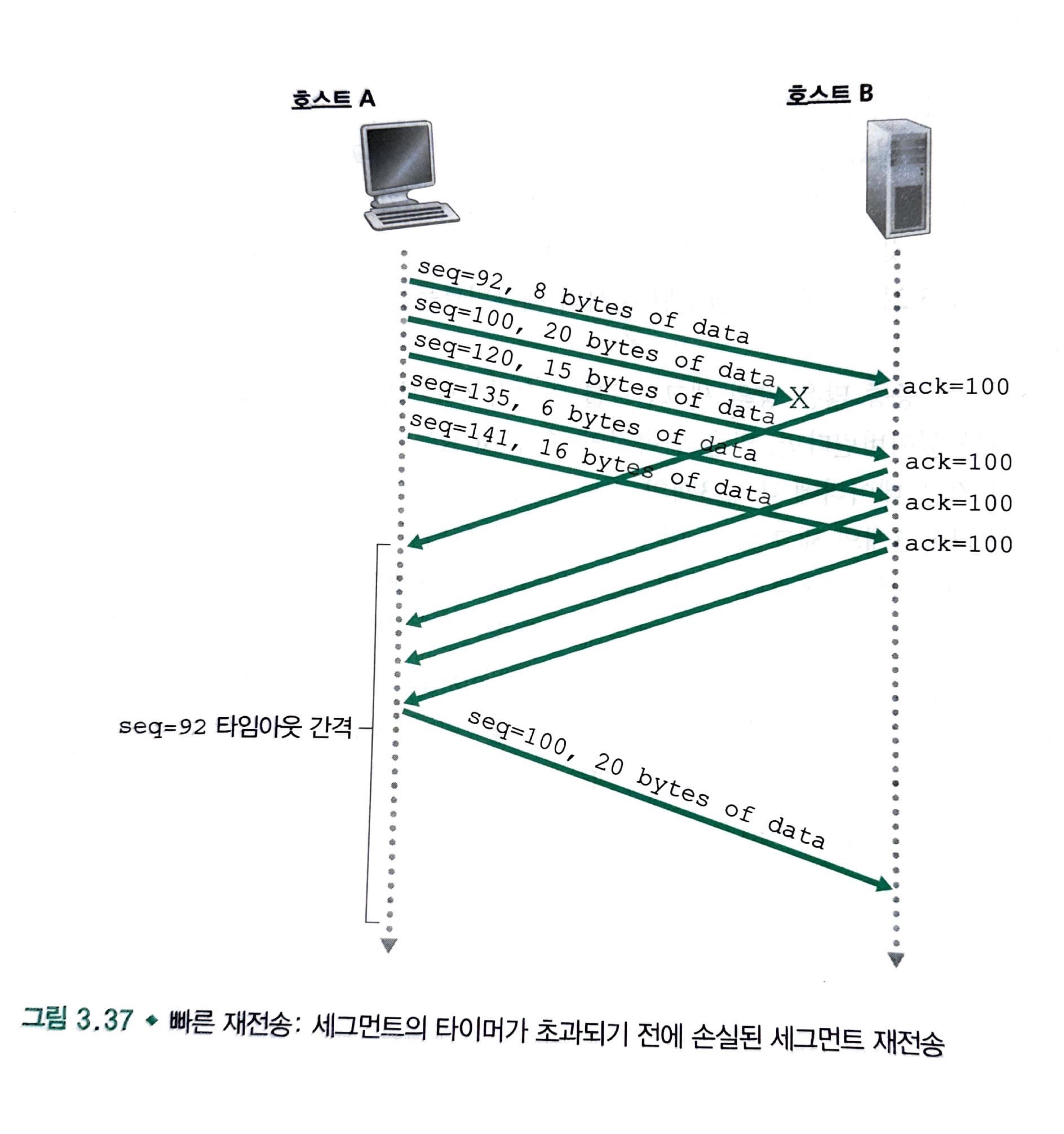
이와 같이 타임 아웃이 일어나기 전에 송신측에선 중복된 ACK를 받을 수 있습니다.
일정 양의 중복된 ACK를 받았을 때 해당 세그먼트는 네트워크 내에서 분실되었다고 가정하고 손실 세그먼트를 재전송하는 기법이 존재합니다.
이것을 빠른 재전송(fast retransmit)라고 합니다.
이것의 대표적인 방법이 Three duplicate ACK입니다.
3개의 중복된 ACK가 도착했을 경우 세그먼트의 손실로 간주하고 해당 세그먼트를 보내는 것을 의미합니다.
GBN인가 SR인가?
결국 TCP는 GBN 프로토콜인가, 아니면 SR 프로토콜인가?
결론적으로, TCP 송신자는 송신되고 확인응답 안된 바이트의 가장 작은 순서번호(SendBase)와 전송될 다음 바이트의 순서번호(NextSeqnum)을 유지해야 합니다.
여기서, TCP는 GBN 형태의 프로토콜과 많이 비슷해 보입니다.
그러나 많은 TCP의 구현은 올바르게 수신되었지만 순서가 바뀐 세그먼트들을 버퍼링합니다.
선택적 확인응답(selective acknowledgment)[RFC 2018]이라고 하는 TCP에 제안된 수정은 TCP 수신자가 마지막으로 올바로 수신된 "순서가 맞는"세그먼트에 대해 누적 확인응답을 하기보다는 "순서가 틀린" 세그먼트에 대해서 선택으로 확인응답을 하게 합니다.
이 방식의 오류 복구 매커니즘은 GBN과 SR 프로토콜의 혼합으로 분류하는 것이 적당합니다.
여기서 필자는 왜 GBN과 SR의 혼합이라고 하는지 헷갈렸는데 그 이유는 아래와 같습니다.
먼저 TCP가 GBN과 비슷한 점은 TCP는 Cumulative ACK를 사용한다는 점입니다. 여기서 Cumulative ACK란 해당 세그먼트의 순서 번호를 그대로 보내는 것이 아닌, 마지막에 받았던 확인 응답번호를 보내는 방식을 의미합니다. SR의 경우 손실이 일어난 것과 상관 없이 해당 세그먼트의 순서 번호를 보내기 때문에 타임 아웃이 일어나는 경우가 아니면 손실된 세그먼트를 알 수 있는 방법이 없습니다.
그리고 TCP는 중복된 ACK가 온 세그먼트 혹은 손실이 일어난 세그먼트 하나만을 전송하는 방식은 SR과 유사합니다.
Reference
