시작하기 앞서...
먼저 TCP를 알아보기 앞서 알아야 되는 개념이 있습니다.
- Process
- Socket
해당 내용은 TCP를 설명하면서 반복해서 나오는 용어이기 때문에 알아두고 진행해야 된다고 판단했습니다.
이 내용은 아래 링크에서 다루었으니 모르신다면 참고하고나서 읽으시면 이해가 더욱 원할하게 될 것입니다.
참고: Process와 Socket
먼저 TCP를 다뤄보기 전에 TCP 소켓 객체에 대해서 다루고 넘어가겠습니다.
TCP 소켓 프로그래밍
❗ TCP는 연결지향 프로토콜로 클라이언트와 서버가 서로에게 데이터를 보내기 전에 TCP연결을 설정(handshake and establish)할 필요가 있음을 의미합니다.
먼저 TCP 소켓의 생성 과정을 살펴보겠습니다.
TCP 연결의 한쪽은 클라이언트 소켓에 연결하고 다른 쪽은 서버 소켓에 연결합니다. (주소 연결)
TCP 연결이 설정 된 후, 소켓을 통해 데이터를 TCP 연결로 보내면 됩니다. UDP와 달리 TCP의 경우 소켓을 연결한 후 패킷에 목적지 주소를 붙이지 않습니다.
서버가 클라이언트의 초기 접속에 응대할 수 있도록 준비하고 있어야 하는데, 여기에는 두 가지 의미가 있습니다.
- TCP 서버는 클라이언트가 접속하기 전에 프로세스를 먼저 수행하고 있어야 한다.
- 서버 프로그램은 클라이언트로부터의 초기 접속을 처리하는 특별한 출입문(즉, 특별한 소켓)을 가져야 합니다.
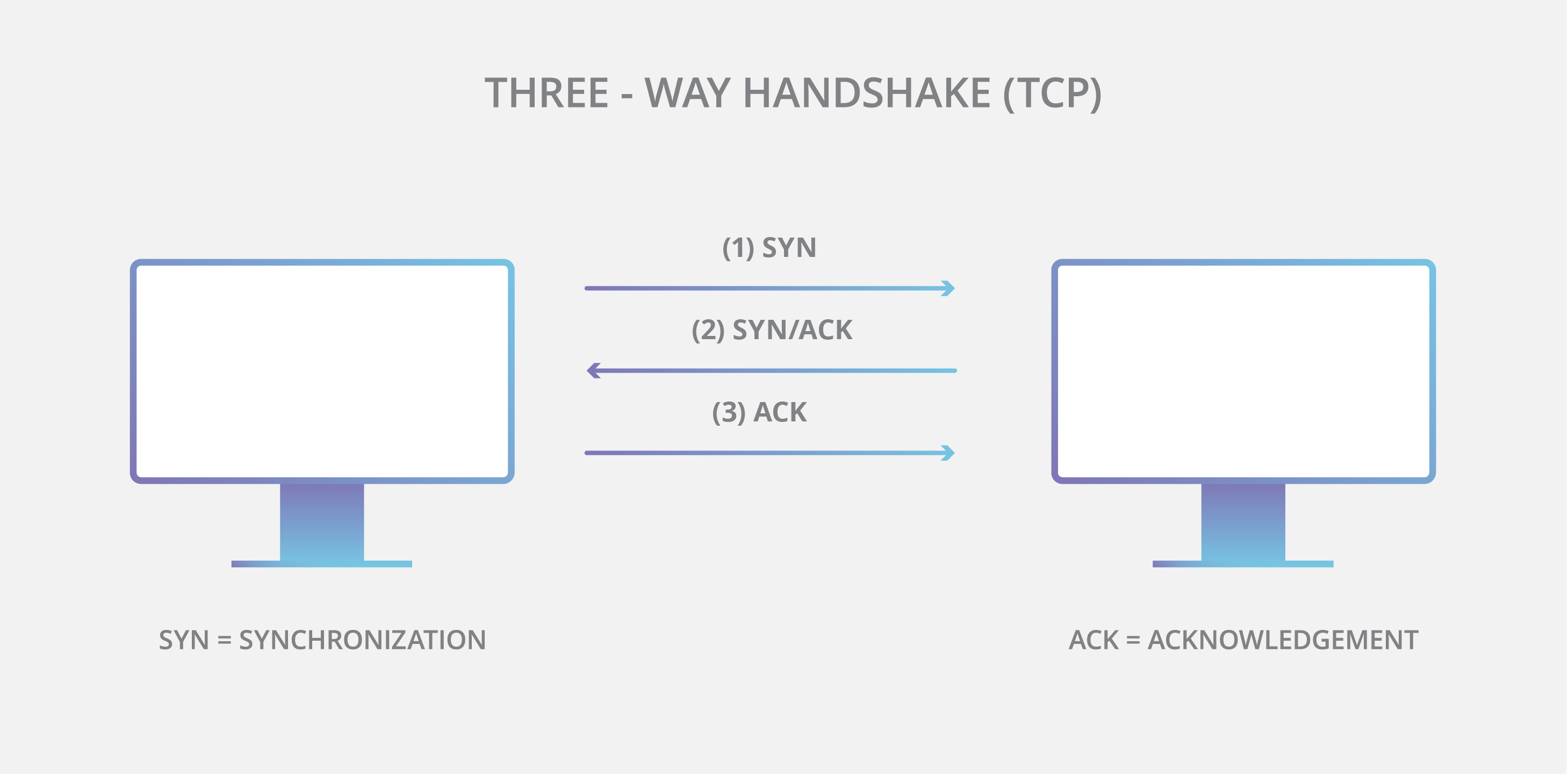
서버 프로세스가 수행이 된 후, 클라이언트 프로그램에서 서버에 있는 환영(welcome) 소켓의 주소(IP 주소와 소켓의 포트 번호)를 명시한 후 세 방향(three-way) 핸드셰이크를 하고 서버와 TCP 연결을 설정합니다.
전송 계층에서 일어나는 세 방향 핸드셰이크를 클라이언트와 서버 프로그램은 전혀 인식하지 못합니다.
세 방향 핸드셰이크 동안 클라이언트 프로세스는 서버 프로세스를 노크(knoking)하고 서버가 이것을 "들으면" 해당 클라이언트에게 지정되는 새로운 소켓을 생성합니다.
이것이 바로 TCP 소켓입니다.
환영 소켓 != TCP 소켓
애플리케이션 관점에서 볼 때 클라이언트의 소켓과 서버의 연결 소켓은 파이프(pipe)에 의해 직접 연결 됩니다. 서로의 소켓은 전송과 수신 둘 다 가능합니다.
TCP가 전송하는 바이트의 순서를 보장해 주면서 클라이언트와 서버 프로세스 간에 **신뢰적(reliable) 서비스를 제공합니다.
아래의 그림은 TCP 전송 서비스를 통해 통신하는 클라이언트와 서버의 주요 소켓 관련 동작을 보여줍니다.
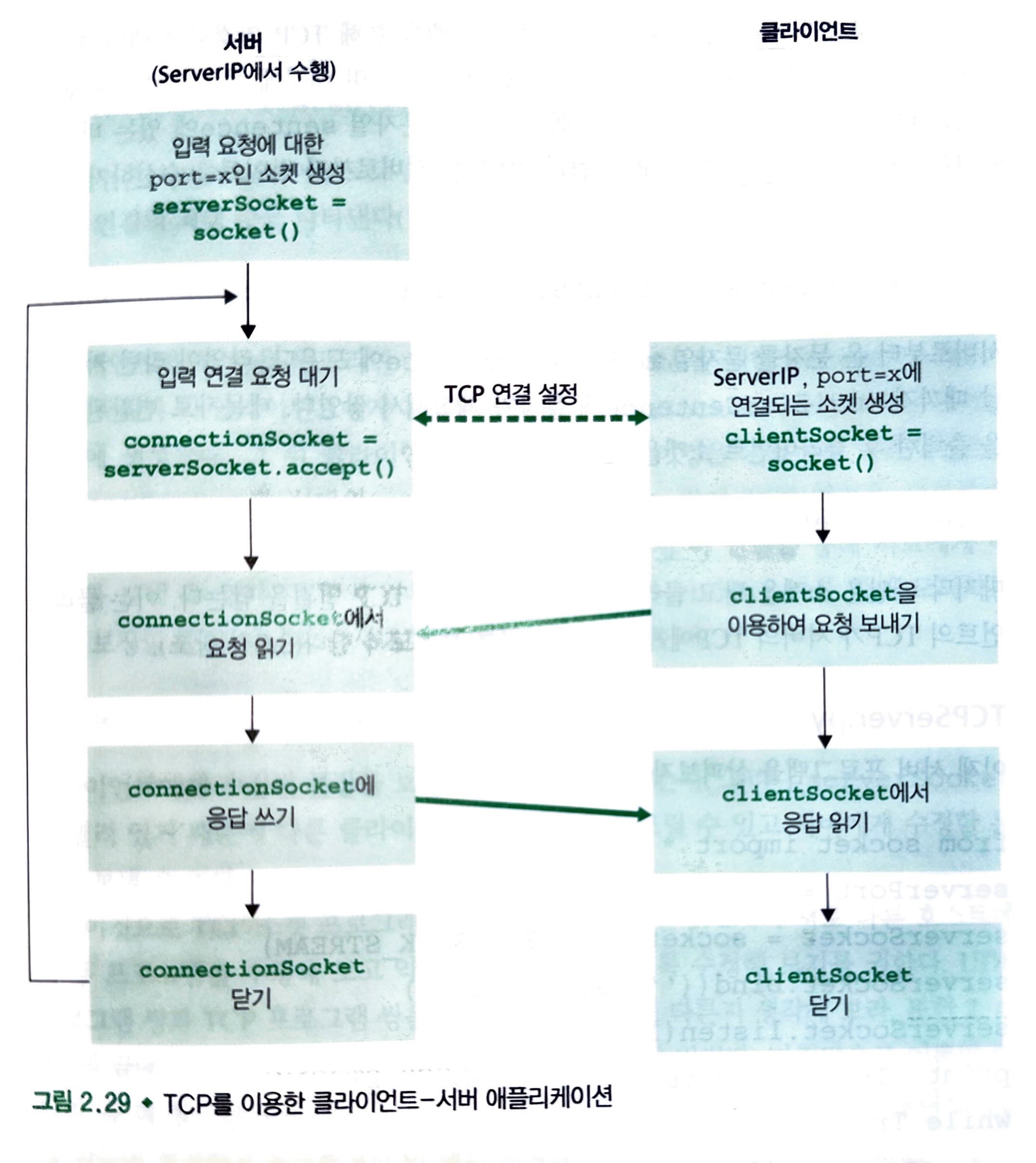
여기서의 코드는 최소한의 코드만으로 제공되는 것을 인지하고 확인하면 됩니다.
애플리케이션의 클라이언트 쪽의 코드를 살펴 봅시다.
from socket import *
serverName = 'serverName'
serverPort = 12000
clientSocket = socket(AF_INEF, SOCK_STREAM)
clientSocket.connect((serverName, serverPort))
sentence = raw_input('Input lowercase sentence:')
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print('From Server:', modifiedSentence.decode())
clientSocket.close()주요 동작들을 살펴보겠습니다.
clientSocket = socket(AF_INEF, SOCK_STREAM)먼저, clientSocket이라고 하는 클라이언트의 소켓을 생성합니다.
첫번째 파라미터는 하위 네트워크가 IPv4를 사용함을 의미하고, 두번째 파라미터는 소켓이 SOCK_STREAM(UDP 소켓이 아닌 TCP 소켓임을 의미) 타입임을 나타냅니다.
클라이언트의 소켓을 생성할 때 해당 소켓의 포트 번호를 명시하지는 않습니다.
대신에 운영체제가 하도록 내버려 둡니다.
clientSocket.connect((serverName, serverPort))이 부분은 클라이언트와 서버간에 데이터를 보내기전에 TCP연결을 시작하는 부분입니다.
파라미터에는 연결 서버의 주소가 담겨있습니다.
sentence = raw_input('Input lowercase sentence:')문자열 sentence는 사용자가 리턴(return) 키를 입력하여 문장을 마칠 때까지 문자를 계속해서 모읍니다.
clientSocket.send(sentence.encode())이 부분을 보면 TCP의 경우 단순히 문자열 sentence에 있는 바이트를 TCP연결에게 제공하고 있는 것을 확인할 수 있습니다.
UDP의 경우 프로그램이 패킷을 명시적으로 생성하지 않으며 패킷에 목적지 주소를 붙이지 않습니다.
modifiedSentence = clientSocket.recv(1024)서버로부터 온 문자를 라인이 리턴키로 끝날 때까지 문자열 modifiedSentence에 문자가 계속해서 쌓입니다. 대문자로 변환된 문장을 출력한 후 클라이언트 소켓을 닫습니다.
clientSocket.close()마지막 라인은 소켓을 닫고 클라이언트와 서버 간의 TCP 연결을 닫습니다. 이는 클라이언트의 TCP가 서버의 TCP에게 TCP 메시지를 보내도록 합니다. (연결을 끊겠다고 말해주는 것)
서버 프로그램도 한번 살펴보겠습니다.
from socket import*
serverPort = 12000
serverSocket = socekt(AF_INET, SOCK_STREAM)
serverSocket.bind(('', serverPort))
serverSocket.listen(1)
print('The serrver is ready to receive')
while True:
connectionSocket, addr = serverSocekt.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
connectionSocket.close()마찬가지로 동작을 확인해 보겠습니다.
serverSocket = socekt(AF_INET, SOCK_STREAM)서버가 TCP 소켓을 만들었습니다.
serverSocket.bind(('', serverPort))첫 번째 파라미터가 비어있는 것이 보입니까? 출입문을 설정한 후 임의의 클라이언트가 문을 두드리기를 기다리고 있는 것입니다. 즉, serverSocket은 대기하는 소켓입니다.
serverSocket.listen(1)이 라인은 서버가 클라이언트로부터의 TCP 연결 요청을 듣도록 하는 것입니다. 파라미터는 큐되는 연결의 최대 수를 나타냅니다.(적어도 1)
connectionSocket, addr = serverSocekt.accept()클라이언트가 이 문을 두드리면 프로그램은 serverSocket을 위한 accept() 메소드를 시작해서 이 클라이언트에게 지정된 connectionSocket이라는 새로운 소켓을 서버에 생성합니다.
그 뒤 클라이언트와 서버는 핸드셰이킹을 완료해서 서로의 connectionsocket간에 TCP 연결을 생성합니다.
이제 이 연결을 통해 서로에게 바이트를 보낼 수 있습니다.
connectionSocket.close()클라이언트에게 수정된 문장을 보낸 후 연결 소켓을 닫습니다.
그러나 serverSocket이 열려 있기 때문에 다른 클라이언트가 출입문을 두드릴 수 있고 서버에게 수정할 문장을보낼 수 있습니다.
이렇게 TCP 소켓 프로그래밍이 완료됩니다.
TCP
여기서부턴 굉장히 다룰 내용이 많습니다.
대부분의 내용은 다른 페이지에서 다룰 예정이고, 여기서는 링크를 달아둘 것입니다.
최종적으로 마지막엔 핵심적인 내용만 해당 페이지에 정리하는 방향으로 진행하겠습니다.
신뢰성 있는 데이터 전송의 원리
먼저 TCP를 이해하기 위해 우리는 신뢰성 있는 데이터 전송의 원리를 알고 갈 필요가 있습니다.
해당 링크를 참고하고 오시기 바랍니다.
연결지향형 트랜스포트: TCP
TCP는 데이터를 보내기 전에 서로 "핸드셰이크"를 먼저 해야 하므로 연결지향형(connection-oriented)이다.
즉, 데이터 전송을 보장하는 파라미터들을 각자 설정하기 위한 사전 세그먼트들을 보내야 합니다.
TCP 프로토콜은 오직 종단 시스템에서만 동작하고 중간의 네트워크 요소(라우터와 브리지)에서는 동작하지 않으므로, 중간의 네트워크 요소들은 TCP 연결 상태를 유지하지 못합니다. 사실, 중간 라우터들은 TCP 연결을 인지하지도 못합니다.
TCP 연결은 전이중(full-duplex) 서비스를 제공하는데, 이것은 연결만 되어 있다면 서로에게 데이터를 보낼 수 있다는 것을 의미합니다.
또한, TCP 연결은 항상 단일 송신자와 단일 수신자 사이의 점대점(point-to-point)입니다. "멀티캐스팅"은 TCP로는 불가능하다는 소리입니다.
TCP 연결을 할때는 "세 방향" 핸드셰이크(three-way handshake)를 사용하는데, 이 방식은 총 3개의 세그먼트가 오고 갑니다.
첫 번째 세그먼트는 클라이언트가 먼저 특별한 TCP 세그먼트를 보냅니다.
두 번째 세그먼트는 서버가 특별한 TCP 세그먼트로 응답합니다.
세 번재 세그먼트는 마지막으로 클라이언트가 특별한 세그먼트로 다시 응답합니다.
처음 2개의 세그먼트는 "페이로드", 즉 에플리케이션 계층 데이터가 없습니다.
세 번째 세그먼트는 페이로드를 포함할 수 있습니다.
일단 TCP 연결이 설정되면, 데이터를 송신할 수 있고 앞서 봤다싶히 소켓을 통해서 데이터의 스트림을 전달 했습니다. 초기에 TCP는 세 방향 핸드셰이크 동안 준비된 버퍼의 하나인 연결의 송신 버퍼(send buffer)로 데이터를 보냅니다. (이때, 송신 버퍼에서 데이터 묶음을 "만들어서" 네트워크로 보냅니다.)
세그먼트의 크기는 최대 세그먼트 크기(maximum segment size, MSS)로 제한됩니다.
MSS는 일반적으로 로컬 송신 호스트에 의해 전송될 수 있는 가장 큰 링크 계층 프레임의 길이[최대 전송 단위(maximum transmission unit, MTU)]에 의해 일단 결정되고, 그런 후에 TCP 세그먼트(IP 데이터그램 안에 캡슐화 되었을 때)와 TCP/IP 헤더 길이(통상 40바이트)가 단일 링크 계층 프레임에 딱 맞도록 하여 정해집니다.
즉, MTU값에 근거해서 MSS가 결정된다고 생각하면 됩니다.
TCP 세그먼트 구조
TCP 세그먼트는 헤더 필드와 데이터 필드로 구성되어 있습니다.
참고로 많은 대화식 애플리케이션은 MSS보다 작은 데이터 덩어리를 전송합니다. 예를 들면, 텔넷과 같은 원격 로그인에서는 종종 TCP 세그먼트 안의 데이터 필드는 오직 1바이트를 가집니다.
아래 사진은 TCP 세그먼트 구조인데 해당 사진을 보면서 하나하나씩 기능들을 살펴보겠습니다.
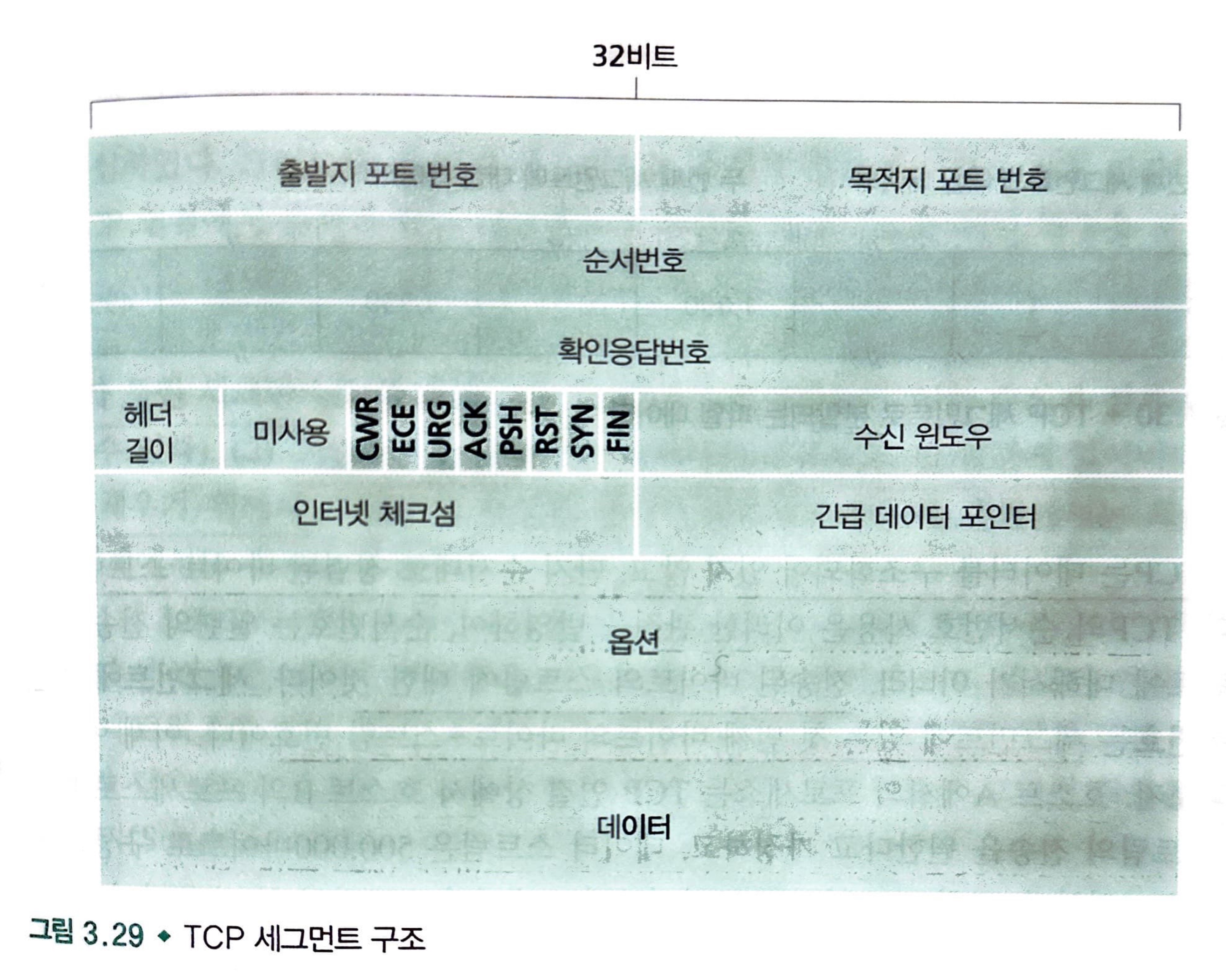
- src port, dest port: 다중화와 역다중화를 하는데 사용되는 포트 번호
- 체크섬(checksum): UDP처럼 헤더는 TCP 헤더 또한 체크섬 필드 포함
- 32비트 순서번호 필드(sequence number field), 32비트 확인응답번호 필드(acknowledgement number field): 신뢰적인 데이터 전송 서비스 구현에서 TCP 송신자와 수신자에 의해서 사용
- 16비트 수신 윈도우(receive window): 흐름제어에 사용됩니다.
- 4비트 헤더 길이(header length) 필드: 32비트 워드 단위 TCP 헤더 길이를 나타낸다.
- 옵션(option) 필드: 선택적이고 가변적인 길이를 가졌으며, 송신자와 수신자가 최대 세그먼트 크기(MSS)와 협상하거나 고속 네트워크에서 사용하기 위한 윈도우 확장 요소로 이용됩니다.
- 플래그(flag): 6비트를 포함
- ACK: 확인응답 필드에 있는 값이 유용함을 가르키는 데 사용
- CWR, ECE: 명시적 혼합표시에서 사용
- PSH: 수신자가 데이터를 상위 계층에 즉시 전달해야 한다는 것을 가리킨다.
- URG: 송신 측 상위 계층 개체(entity)가 "긴급"으로 표시 하는 데이터임을 가리킨다.
- 이 긴급 데이터의 마지막 바이트의 위치는 16비트의 긴급 데이터 포인터 필드(urgent data pointer field)에 의해서 가리켜진다.
TCP 세그먼트 헤더에서 가장 중요한 필드는 순서번호 필드와 확인응답 번호 필드입니다.
TCP는 데이터를 구조화되어 있지 않고, 단지 순서대로 정렬된 바이트 스트림으로 봅니다.
이러한 관점에서 TCP의 순서번호는 일련의 전송된 세그먼트에 대해서가 아니라, 전송된 바이트 스트림에 대한 것입니다.
세그먼트에 대한 순서번호 = 세그먼트에 있는 첫 번째 바이트의 바이트-스트림 번호
확인응답 번호의 경우 순서번호와는 조금 다릅니다.
호스트 B로부터 도착한 각 세그먼트는 B로부터 A로 들어온 데이터에 대한 순서번호를 갖습니다.
호스트 A가 자신의 세그먼트에 삽입하는 확인응답 번호는 호스트 A가 호스트 B로부터 기대하는 다음 바이트 순서번호입니다.
이렇게만 보면 무슨 말인지 헷갈리니 이 부분은 예시를 적어 놓겠습니다.
호스트 A가 B로부터 0에서 535까지 번호가 붙은 모든 바이트를 수신했다고 가정해 봅시다. 그리고 호스트 B로 다음 세그먼트를 송신하려고 합니다. 호스트 A는 0 ~ 535 데이터 묶음을 보내고 536 ~ N 까지의 데이터 묶음을 보내는 상황인 것입니다.
그래서, 0 ~ 535 데이터 묶음을 보내면서 확인응답 필드에 536을 삽입하고 그것을 삽입합니다.
여기서 다른 상황을 가정해봅시다.
만약, 송신측에서 0 ~ 535의 바이트를 포함하는 세그먼트와 900 ~1,000의 바이트를 포함하는 또 다른 세그먼트를 수신했다고 가정해봅시다.
이 상황에서 송신측은 536번째 바이트르 기다리고 있을 것입니다.
TCP는 스트림에서 첫 번째 잃어버린 바이트까지의 바이트들까지만 확인 응답하기 때문에, TCP는 누적 확인응답(cumulative acknowledgment)를 제공합니다.
사실 여기서 민감한 문제가 있습니다.
두 번째 세그먼트가 도착하기 전에 세번째 세그먼트가 먼저 도착을 한 상황입니다.
이때 호스트는 어떠한 행동을 하는가입니다.
기본적으로 두 가지 선택이 있습니다.
- 수신자가 순서가 틀린 세그먼트를 즉시 버린다. (수신자 설계 단순화)
- 수신자가 순서가 틀린 데이터를 보유하고, 빈 공간에 잃어버린 데이터를 채우기 위해서 기다린다.
후자가 네트워크 밴드폭 관점에서는 효율적이며, 실제에서도 취하는 방법입니다.
왕복시간(RTT) 예측과 타임아웃
이부분 또한 따로 다른 페이지에서 정리하도록 하겠습니다.
신뢰적인 데이터 전달
여기서는 결국 위에서 봤던 GBN과 SR 방식 중 무엇을 선택하는 것이 신뢰적인 데이터 전달을 하면서 효율적인 방식이 될 수 있을까에 대해서 알아보는 부분입니다.
이 부분도 TCP의 기본적인 내용은 아니기 때문에 링크를 달아서 따로 설명해 두도록 하겠습니다.
흐름 제어(Flow-Control)
TCP에는 송신자와 수신자의 처리 속도를 네트워크 환경에 맞게 맞추기 위해서 흐름 제어와 혼잡 제어라는 방식들을 사용합니다.
거기 중에서 송신자와 수신자의 관점에서만 보는 것이 흐름 제어라고 볼 수 있고, 혼잡 제어의 경우 종단 간의 네트워크 사이의 패킷 손실을 확인해서 처리하는 방식으로 여러 송신자들의 관점에서의 제어 방식이라고 생각할 수 있겠습니다.
흐름 제어부터 살펴보겠습니다.
혼잡 제어(Congestion-Control)
TCP에서 굉장히 중요하게 여겨지는 혼잡 제어에 대해서 알아보도록 하겠습니다.
다음 링크를 참고해주세요.
공평성
마지막으로 공평성에 대해서 다뤄보고 마무리 짓도록 하겠습니다.
TCP에서 말하는 공평성이 무엇일까?
여기선 상황을 가정해서 설명을 하도록 하겠습니다.
각각 다른 종단간의 경로를 갖지만, 모두 Rbps의 전송률인 병목 링크를 지나는 K개의 TCP 연결을 생각해 봅시다.
⚡ 병목 링크 ⚡
각 연결에 대해서 연결 경로상에 있는 모든 링크들은 혼잡하지 않고 병목 링크의 전송 능력과 비교해서 충분한 전송 능력을 가지고 있다는 것을 의미
병목 링크를 통해서 파일들을 전송하고, 병목 링크를 통과하는 UDP 트래픽이 없다고 가정해 봅시다.
각 연결의 평균 전송률이 R/K에 가깝다면 혼잡 제어 매커니즘이 공평하다고 합니다.
즉, 각 연결은 링크 대역폭을 동등하게 공유합니다.
좀 더 간단하게 말하자면, 윈도우 크기가 다른 호스트 끼리 같은 링크를 사용하고 있는데, 만약 해당 링크가 혼잡해서 Congestion Control을 해야하는 상황이라면 윈도우 크기가 큰 호스트만 처리할까?
결국 해당 링크와 TCP 연결을 한 모든 호스트의 cwnd를 조절하기 때문에 이것은 공평한 것이 아니라는 것입니다.
Reference
