TCP/IP란?
❗ 인터넷 프로토콜 스위트(Internet Protocol Suite)는 인터넷에서 컴퓨터들이 서로 정보를 주고받는 데 쓰이는 통신규약 모음이다. 인터넷 프로토콜 슈트 중 TCP와 IP가 가장 많이 쓰이기 때문에 TCP/IP 프로토콜 슈트라고도 불린다.
TCP/IP는 패킷 통신 방식의 인터넷 프로토콜인 IP와 전송 조절 프로토콜인 TCP로 이루어져 있다. IP는 패킷 전달 여부를 보증하지 않고, 패킷을 보낸 순서와 받는 순서가 다를 수 있다. TCP는 IP 위에서 동작하는 프로토콜로, 데이터 전달을 보증하고 보낸 순서대로 받게 해준다. HTTP, FTP, SMTP 등 TCP 기반으로 한 많은 수의 애플리케이션 프로토콜들이 IP 위에서 동작하기 때문에, 묶어서 TCP/IP로 부르기도 합니다.
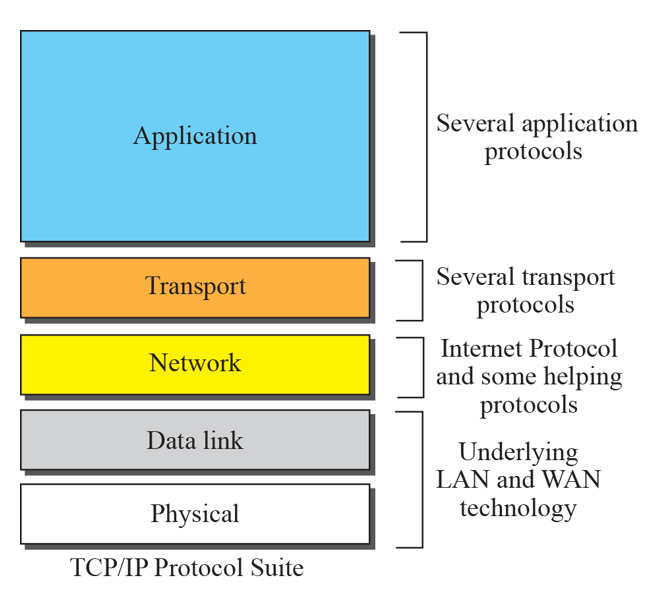
여기서는 원할한 설명을 위해서 OSI 7계층을 다루지 않고, TCP/IP 5계층으로 다룰 예정입니다.
❗ TCP/IP 5계층이란 네트워크의 기본 구조를 5계층으로 나누어 표준화한 것입니다.
네트워크를 이용한 통신은 서로 다른 역할을 가지는 5개의 계층을 통해서 일어난다고 생각하며 ㄴ됩니다.
이러한 5계층 중 3계층과 4계층을 강조해 TCP/IP 5계층이라고 합니다.
기본적인 동작 순서를 적어 나가면서 거기서 요구되는 기능들을 적고 설명할 예정입니다.
TCP/IP 5계층 역할 정리
먼저, 동작 순서를 이야기하기 전에 기본적인 동작 방식에 대해서 정리를 하고 진행하는 것이 좋을 것 같아서 먼저 정리하고 가겠습니다.
OSI 7계층에서 표현 계층과 세션 계층이 빠진 형태로 계층 구조는 동일합니다.
각 계층별 역할은 다음과 같습니다.
- 1 계층 - 물리 계층: 물리적인 연결과 전기 신호 변환/제어를 담당합니다.
- 2 계층 - 링크 계층: 네트워크 기기 간 데이터 전송 및 물리 주소를 결정합니다.
- 3 계층 - 네트워크 계층: 다른 네트워크와 통신하기 위한 경로를 설정하고 논리 주소를 결정합니다.
- 4 계층 - 전송 계층: 네트워크 계층에서 보내온 데이터 정렬, 오류 정정 등을 수행하고 신뢰할 수 있는 통신을 확보합니다.
- 5 계층 - 응용 계층: 다른 종단 시스템에서 실행되는 애플리케이션의 프로세스가 서로 메시지를 보내는 방법을 정의합니다.
각 계층별로 수행하는 기본적인 역할은 이정도이고, 구체적인 부분에 대해선 아래에서 다루겠습니다. 그리고 모든 계층에서 공통적으로 수행되는 동작 방식이 있습니다.
- <캡슐화/역캡슐화>
서로 다른 계층 간 데이터를 주고받는 과정에서 캡슐화와 역캡슐화가 발생하게 됩니다.
송신자 측에서 메시지를 보낼 때 응용 계층부터 물리 계층까지 각 계층에서 수행해야 하는 과정을 거친 뒤 아래 계층에 전달을 합니다.
응용 계층에서 역할을 수행 후 프로세스가 데이터를 전송 계층에게 전달해주는데 전송 계층은 다중화 작업을 통해서 데이터를 잘게 나누는 작업을 수행하는데 이때 잘게 나누어진 데이터를 세그먼트라고 합니다.
세그먼트에 헤더를 붙이고 이것을 네트워크 계층에게 건네줍니다. 네트워크 계층은 이 데이터를 페이로드에 담고 그 앞에 IP 헤더를 붙입니다. 링크 계층에서도 또한 비슷한 동작을 수행합니다.
이러한 작업을 캡슐화라고 합니다.
반대로 수신자 측에선 헤더와 페이로드(데이터)를 나누는 작업을 수행하는데 이 작업을 역캡슐화라고 할 수 있습니다.
즉, 캡슐화는 헤더를 붙이는 작업이고, 역캡슐화는 헤더를 제거하는 작업이라고 생각하면 됩니다.
이제 본격적으로 동작 순서를 이야기해 가면서 개념을 정리해 봅시다.
동작 순서
전체적인 동작 순서를 설명해 나가겠습니다.
일단 현재 제가 공부한 내용을 토대로 순서를 정리해 나갈 것이고 현재 링크 계층을 공부하지 않았기 때문에 그 전까지 정리할 예정입니다.
기본적인 상황은 종단간 메시지 전송을 기본으로 하고 여기서 TCP Connection조차 맺어져 있지 않은 상황부터 시작해 나갈 것입니다. 가능한 모든 상황을 생각해 보고 정리할 예정입니다.
한 호스트가 홈페이지에 접속을 하여 HTTP를 이용해서 홈페이지 텍스트 파일을 가정해 봅시다.
클라이언트는 홈페이지에 접속하기 위해서 Domain Name으로 되어있는 서버 이름을 URL 입력칸에 입력하면서 상황은 시작됩니다. 우리는 여기서부터 시작을 할 것입니다.
호스트 네임을 가지고 DNS를 통해 IP 주소를 받아올 것입니다.
Connection
이제 클라이언트 측은 IP 주소를 알고 있으니 이것을 이용해서 TCP Connection을 준비할 것입니다.
먼저 TCP Connection을 맺기 위해서 필요한 것이 4가지가 있습니다.
- 송신자 IP 주소
- 송신자 Port 번호
- 수신자 IP 주소
- 수신자 Port 번호
이 4개를 이용해서 클라이언트는 이미 bind()를 통해서 커널에 등록되어 있는 서버 소켓과의 연결을 요청합니다.
이 과정에서 three handshake 과정이 발생합니다.
좀 더 추가적으로 설명하자면 커널에 등록되어 있는 서버 소켓은 listen()을 통해서 클라이언트 접속 요청을 기다리고 있다가 accept()를 통해서 접속을 허락합니다. 이후 커널이 자동으로 소켓을 생성하고 이 소켓에 필요한 작업을 취하고 클라이언트에게 반환해줍니다. 이때 소켓을 클라이언트 소켓이라고 합니다.
이 부분에 대해선 해당 페이지를 참고바랍니다. (정말 자세히 설명을 해놔주셨습니다...!!)
이 과정을 통해서 TCP 연결이 완료되었고,이제 데이터를 보낼 준비가 완료되었습니다.
이제 연결하는 부분이 끝났습니다. 이젠 데이터를 전송하기 위한 준비 작업이 필요합니다.
그 부분에 대해서 정리하기 전에 현재 소켓 프로그래밍에 대해서 다루고 있는 김에 UDP/IP에 대해서도 적고 넘어가겠습니다.
만약, UDP를 기반으로한 실시간 스트리밍 방송에 접속을 한다고 생각해 봅시다.
들어가는 동시에 영상을 시청할 수 있게 됩니다. 어떻게 이렇게 빨리 영상이 나오는 것일까요?
먼저 UDP의 경우 Connection이라고 부를만한 작업이 이루어지지 않습니다. 그렇다면 우리는 어떻게 패킷을 전송받는 것일까요?
UDP/IP는 일방적으로 패킷을 전송하는 방식을 사용합니다. 그냥 보냅니다. 상대방 시스템이 켜져 있는지 조차 모릅니다. 그러니 재대로 전달이 될지 보장이 안되는 것입니다. 하지만 빠를 수 밖에 없습니다.
소켓을 생성하고 커널에 등록하면 클라이언트로부터 데이터를 수신할 수 있는 상태가 됩니다. 클라이언트가 데이터 요청을 보내면서 서버는 송신 측 주소 정보를 받아오고 이 주소를 이용해서 자료를 전송합니다.
TCP와 UDP의 차이
여기에서 보이듯이 TCP와 UDP는 신뢰성, 네트워크 제어, 연결 지향성 등 외에도 다양한 차이를 보여줍니다. 동작 방식에서 조차 큰 차이가 존재하죠. 특히, 동작 방식에서의 차이는 전공서적에서도 크게 다루지 않아서 해당 블로드들을 참고했으니 링크를 달아놓도록 하겠습니다.
참고:
추가적인 설명
TCP의 경우 종단간의 호스트끼리만 3방향 핸드 셰이크를 맺는 것일까?
종단 호스트들 사이 네트워크 상에서는 수 많은 라우터 혹은 중개 서버들이 존재합니다. 과연 이것들과도 전부 연결 작업이 진행 되는 것일까요?
이부분에 대해선 제 생각을 정리해서 올려 놓겠습니다. (혹시 의견이 있다면 댓글 부탁드리겠습니다 ^^)
처음에는 중간에 거쳐가는 모든 것들과 TCP Connection을 맺을 것이라고 생각을 했습니다. 하지만 일단 라우터는 기본적으로 포워딩과 라우팅 기능을 수행하는 것에 특화되어 있으므로 Connection을 맺을 수 없을 뿐더러 맺을 필요성조차 있어 보이지 않습니다. 또한, 현재까지 배운 내용대로라면 Connection작업을 맺기 위해선 소켓이 필요해 보입니다. 라우터에서 소켓이 있다고 생각되지 않습니다.
그렇다면 중간에 있는 서버 즉, 중개 서버는 어떨까요? 예를 들자면 클라이언트와 클라이언트측 프록시 서버, 서버측 프록시 서버와 서버 과연 어떻게 커넥션이 맺어질까요?
결론부터 말씀드리자면, 일단 커넥션은 전부 맺어진다고 생각합니다. 하지만, 이것이 전부 완벽한 TCP 커넥션일 것이라고는 현재 저의 지식으로써는 확실히 답을 못하겠습니다. 실제로 HTTP 커넥션도 TCP 커넥션의 기반으로 이루어지기는 하지만, TCP 커넥션이 모두 HTTP 커넥션인 것은 아닙니다. Connection 헤더에는 Proxy-Connection이라는 것도 존재합니다. 이러한 것을 보면, 커넥션 자체는 맺어진다고 보는 것이 맞다고 생각합니다. 하지만, 이렇게 모든 중개 서버와 Connection이 맺어진다고 생각하면 많은 지연이 발생할 것이고 이것을 위해서 병렬 커넥션과 지속 커넥션, 파이프라인 커넥션, 다중 커넥션과 같은 기능들이 존재합니다.
하지만 이러한 방식으로 작동할 경우 멍청한 프록시에서 발생하는 문제에서 납득이 가지 않는 요소가 있습니다. 멍청한 프록시는 keep-alive 옵션을 이해하지 못하고 그대로 호스트 서버에게 전달하는 것에서 발생하는 문제인데, 만약 프록시와 클라이언트간에 세 방향 핸드셰이크를 할경우, 프록시에서 클라이언트에게 응답을 주는 과정은 어떻게 설명이 되는 것인가? 애초부터 이 문제가 발생하는 전제 조건이 이미 커넥션이 맺어져 있는 상태에서 상태 유지를 위해 keep-alive 옵션을 주는 것인가? 맺어져 있는 커넥션에 보내는 것이 맞을 것입니다. keep-alive의 경우 기존의 커넥션을 재사용하기 위함이기 때문에 기존의 커넥션이라는 뜻은 이미 활용하고 있는 커넥션이라는 뜻으로 봐도 무방하다고 생각해서 입니다.
이 부분에 대해선 따로 정리를 하겠습니다.
참고: [TCP/IP] 너무나도 비효율적인 HTTP Connection
데이터 전송을 위한 준비 단계
여기서는 데이터를 전송하기 위해서 TCP가 동작하는 방식에 대해서 서술할 것입니다.
먼저, 간단하게 정리하자면 다음과 같습니다.
통신 계층은 상위 계층의 프로세스로부터 버퍼에 공간이 있을 때 데이터 스트림을 받습니다.
데이터를 받은 후 다중화 작업과 캡슐화 작업을 통해서 세그먼트로 만든 후 네트워크 계층에게 넘겨줍니다. 네트워크 계층에서도 캡슐화 작업을 통해서 링크 계층에게 건내주고 링크 계층 또한 캡슐화를 수행합니다.
크게 보자면 이렇게 작동합니다.
이 과정에서 발생하는 것은 여기까지만 보는 것이 맞다고 봅니다.
데이터 전송을 하기 전에 확인해야 할 것은 이것뿐만이 아닙니다.
앞으로 확인해야 할 것은 다음과 같습니다.
- 어떻게 보낼것인가?(신뢰성 보장하기 위해서) => **통신 계층
- 얼마나 보낼것인가? => 통신 계층
- 어떤 경로로 보낼 것인가? => 네트워크 계층
이러한 것들의 확인이 이루어져야 합니다.
이 부분을 우리는 통신 계층과 네트워크 계층의 역할을 나눠서 살펴볼 것입니다.
통신 계층(Transport Layer)
TCP는 신뢰성 있는 데이터를 전송해줘야 합니다. 어떻게 이것을 처리할 수 있을까요?
신뢰성 있는 데이터를 전송하기 위해서 데이터가 올바르게 도착을 했는지 응답해주는 응답 메시지(ACK, NACK)를 이용할 수 있습니다. 하지만, 이것은 오류 검출 방식, 추가적인 Bit를 요구하는 등 여러가지 문제점을 안고 있습니다. 그래서 패킷에 순서 번호(Sequence Number)를 담아서 보내는 것으로 데이터가 올바르게 도착했는지 확인합니다.
수신측에 올바르게 도착을 했다면 이것을 송신측에 알려줘야 하겠죠?
이때 사용하는 방법이 GBN(Go-Back-N)방식과 SR(Selective-Repeat)방식입니다.
현재 사용하고 있는 방식은 GBN의 Cumulative ACK과 SR에서 중복된 ACK가 온 세그먼트 혹은 손실이 일어나 세그먼트 하나만을 전송하는 방식을 둘 다 사용하고, 효율성을 위해서 파이프라이닝(pipelining) 기법을 같이 사용합니다.
이제 어떻게 보낼지도 결정했습니다.
이번에는 수신측에서 받을 수 있는 공간 확보가 되어 있는지 확인해야 하겠죠.
이것을 수행하는 것이 흐름 제어(Flow Control)입니다. 수신측의 rwnd(Recieve Window)를 확인하고 보낼 수 있는지 확인하는 작업이 이루어 집니다.
공간 확보가 되었다고 가정해 봅시다. 이대로 이제 보내면 될까요? 아닙니다.
만약, 나혼자 네트워크를 이용하고 데이터를 서버에 보낸다고 한다면 괜찮습니다. 하지만, 네트워크 상에서 수 많은 호스트가 같은 네트워크를 공유하고 있습니다. 이것을 고려해야 합니다.
그래서 존재하는 것이 혼잡 제어(Congestion Control)입니다. 혼잡 제어에서는 현재 보낼라고 하는 네트워크 상의 트래픽을 확인합니다. (물론, 이 설명에는 살짝 애매한 부분이 있습니다. 혼잡 제어는 데이터를 전송하기 시작하고나서 사용되는 기능이기 때문이죠. 하지만 설명을 위해서 이렇게 설명을 하겠습니다.)
혼잡 제어에서는 cwnd(Congestion Window)를 이용하여 데이터를 보낼 수 있는 상황인지 확인을 합니다.
만약 트래픽이 너무 몰려서 라우터의 버퍼가 가득찬 경우 데이터는 손실이 일어날 것입니다. 이것으로 인해서 3-duplicated Ack의 발생 혹은 Timeout Event가 발생할 것입니다. 이러한 상황이 발생하면 데이터 전송 속도에 크게 영향을 주기 때문에 되도록이면 피하는 것이 좋습니다.
그래서, TCP 혼잡제어 알고리즘에서 사용되는 세가지 구성요소를 이용합니다.
- 슬로 스타트(Slow Start)
- 혼잡 회피(Congestion Avoidance)
- 빠른 회복(Fast Recovery)
이러한 기능들을 이용하여 최종적으로 Min(rwnd, cwnd)로 보내는 양을 조절합니다.
이제 진짜 보낼 준비가 되었습니다.
현재 이루어진 작업으로는 데이터를 보내기 위해서 다중화와 캡슐화를 했고, 얼만큼 보낼지를 결정했습니다.
이제 어디를 통해서 보낼지 결정하면 됩니다. 여기서부터는 네트워크 계층의 역할이 수행됩니다.
네트워크 계층(Network Layer)
데이터에 관련된 작업은 마쳤습니다.
빠른 전송을 위해서는 적절한 경로 선택이 필수적입니다.
네트워크 계층에서는 이러한 경로 선택을 위해서 포워딩과 라우팅 기능을 제공합니다.
우선적으로 생각해봐야 할 것은 전체적인 라우팅을 어디서 수행되는지의 문제입니다.
라우팅(Routing)
이 방식과 관련되서 두 가지 방식으로 나뉩니다.
- 분산된 라우팅 방식
- 중앙 집중형 방식
분산된 집중형 방식이라고 함은 각각의 라우터가 최저 비용 경로를 계산하여 이를 다른 라우터들과 공유하면서 진행하는 방식을 의미합니다.
중앙 집중형 방식은 SDN(Software Defined Network)라고 불리고 컨트롤러-에이전트 구조로 되어있습니다.
SDN에서는 기존의 분산된 라우팅 알고리즘 대신에 중앙 집중식 컨트롤러가 네트워크 라우팅 정보를 관리하고 제어합니다. 이때, 컨트롤러와 에이전트 간에 정보를 교환하는 OpenFlow 프로토콜을 사용합니다.
OpenFlow에서 컨트롤러는 네트워크 토폴로지와 트래픽 패턴을 분석하여 플로우 테이블을 재계산합니다. 이를 통해 네트워크 토폴로지를 모니터링하고, 트래픽 패턴을 분석하여 스위치들의 플로우 테이블을 수정합니다.
에이전트는 컨트롤러에게 변화가 일어난 정보와 함께 해당 스위치의 플로우 테이블 전체를 전달합니다. 이와 같은 작업을 수행함으로써 네트워크 전체적인 상태를 파악할 수 있도록 도와주는 역할을 합니다.
이렇게 봤을 때, SDN 방식이 분산된 라우팅 방식보다 좋아보입니다. 기본적으로 역할이 나눠져 있고, 문제가 발생할 경우 나눠져 있는 시점에서 해당 부분에 집중할 수 있죠. 하지만, 현재 사용되고 있는 방식은 일반적으로 분산된 라우팅 방식이라고 합니다. 대부분의 기업 및 조직에서는 분산된 라우팅 방식을 채택하여 네트워크를 운영하고 있습니다. 이는 기존의 네트워크 인프라를 대체하기 어려워서 그렇습니다.
라우팅이 어디서 이루어지는 확인했습니다.
이제 전체적인 라우팅 과정을 살펴봅시다.
네트워크 상에서는 수많은 라우터가 있고 이것을 각각 하나하나씩 관리하기에는 너무 많습니다.
그래서 AS(autonomous system)으로 조직화하여 이 문제를 해결합니다.
AS를 통해서 나누어졌기 때문에 우리는 이와 같이 생각할 수 있습니다.
- AS 외부에서의 라우팅
- AS 내부에서의 라우팅
먼저, AS 외부에서의 라우팅을 먼저 살펴보고, 그 다음 내부에서의 라우팅을 살펴보겠습니다.
AS 외부에서 라우팅은 AS 간의 라우팅으로 생각할 수 있습니다.
자율 시스템 간 라우팅 프로토콜(inter-autonomous system routing protocol)은 경계 게이트웨이 프로토콜(Border Gateway Protocol, BGP)라고 알려져 있습니다.
BGP의 동작 방식은 다음과 같습니다.
- 이웃 AS로부터 도달 가능한 서브넷 접두부 정보를 얻습니다.
- 서브넷 주소 접두로의 "가장 좋은" 경로를 결정합니다.
이것을 수행하기 위해서 경로 선택 알고리즘이 요구될 것입니다. 경로 선택 알고리즘은 다음의 우선순위를 지키면서 수행됩니다.
- 지역 선호도가 가장 높은 경로를 선택합니다.
- 최단 AS-PATH를 가진 경로를 선택합니다.
- 뜨거운 감자 라우팅을 수행합니다.
- BGP 식별자를 사용합니다.
이와 같은 방식으로 수행되고 자세한 내용에 대해서는 네트워크 계층: 제어평면에서 정리를 해두었습니다.
다음은 AS 내부에서 동작하는 방식을 알아보겠습니다.
AS 내부에서 사용하는 라우팅 프로토콜에는 두가지 방식이 있다고 볼 수 있습니다.
- OSPF(Open Shortest Path First)방식
- RIP(Routing Information Protocol)방식
OSPF는 기본적으로 다익스트라 알고리즘을 기반으로 최소 비용 계산이 이루어지고, 그것에 대한 정보를 AS 내부의 모든 라우터들에게 플러딩합니다.
RIP는 벨만-포드 알고리즘을 기반으로 최소 비용 계산이 이루어집니다.
현재 대부분의 네트워크에서는 OSPF와 같은 링크 상태 프로토콜을 사용합니다.
둘의 차이점을 간단하게만 정리하자면, OSPF는 링크 상태 알고리즘으로 전체적인 네트워크 토폴로지를 전부 알고 계산하는 방식을 사용합니다.
반면에, RIP는 거리 벡터 알고리즘으로 직접 연결된 이웃끼리 정보를 주고 받으면서, 모든 노드로 퍼져나가는 방식을 사용합니다.
이러한 방식으로 라우팅이 진행됩니다.
이제 포워딩에 대해서 알아봅시다.
포워딩 (Fowarding)
네트워크 상에서 데이터를 어떠한 경로로 보낼지 결정해 놓았습니다.
위에서 말한 방식들이 원할하게 작동이 되려면 라우터에서 결정되어 있는 경로에 맞는 길로 데이터를 안내해줄 필요가 있습니다.
그걸 위해서 사용하는 방식이 포워딩이고, 앞서 말했던 포워딩 테이블이 여기서 사용되는 것입니다.
이미 어느 경로를 통해서 가야할 지는 앞서 라우팅하는 부분에서 미리 결정된다고 말했습니다.
그렇다면, 포워딩 테이블에서는 이미 결정된 경로 즉, 계산된 포워딩 테이블을 이용하여 패킷을 올바른 길로 안내해 줄 수 있을 것입니다.
라우터는 물리 계층을 통해서 데이터를 다른 라우터로부터 받습니다.
캡슐화된 프레임을 수신하고, 링크 계층 헤더를 확인한 후 해당 프레임의 페이로드 부분을 포함한 전체 데이터그램을 추출합니다. 추출된 데이터그램에서는 네트워크 계층 헤더를 확인하고 필요한 라우터 작업을 수행합니다. 그리고 이후에는 다시 링크 계층 헤더를 붙여서 캡슐화된 프레임을 만들고, 다음 라우터나 수신자에게 전송합니다.
링크 계층에 대해서 본인이 아직 공부를 하지 않았기 때문에, 공부를 하고나서 설명을 붙이겠습니다.
라우터에서 사용하는 주소는 어떠한 형태로 되어 있을까요? 기존의 32비트 IP 주소의 형태로 플로우 테이블에 저장되어 있는 것일까요?
아닙니다. 플로우 테이블은 프리픽스와 링크 인터페이스를 사용하여 플로우 테이블의 엔트리를 갱신할 것입니다. 그리고 최장 프리픽스 매칭 규칙(longest prefix matching rule)을 활용하여 입력포트에서 올바른 출력 포트로 내보내 줄 수 있습니다.
라우터는 많은 입력 포트와 출력 포트로 이루어져 있고, 다른 입력 포트에서 같은 출력 포트로 내보내는 상황이 발생할 수 있습니다. 기본적으로 라우터의 입력 포트와 출력 포트 사이에는 일대일 매핑 관계가 있기 때문에 하나의 입력 포트에서 여러 출력 포트로 동시에 패킷을 내보내는 것은 불가능 하고, 여러 입력 포트에서 하나의 출력 포트로 동시에 패킷을 내보내는 것 또한 불가능합니다.
그렇다면, 어떻게 이러한 상황을 처리해야 될까요? 이때 이용하는 것이 패킷 스케줄링입니다.
모든 순간에 패킷 스케줄링이 사용되는 것이 아니고, 두개 이상의 입력 포트에서 같은 출력 포트로 내보내려고 하는 경우에 이 기법을 사용하는 것입니다.
패킷 스케줄링에는 다음과 같은 것들이 있습니다.
- FIFO(First-In-First-Out)
- 우선순위 큐잉(Priority Queuing)
- 라운드 로빈(Round robin)
- WFQ(Weighted Fair Queuing)
FIFO의 경우, 먼저 큐에 들어온 패킷 순서대로 내보내는 방식입니다.
우선순위 큐잉의 경우, 큐마다 클래스 우선순위를 매겨서 우선순위가 높은 클래스를 가진 큐를 먼저 내보내는 방식을 사용합니다.
라운드 로빈의 경우, 라운드 로빈은 우선순위 큐잉과 동일하게 클래스로 큐를 구분하지만, 엄격한 서비스 우선순위가 존재하지 않습니다. 클래스를 순환하는 방식으로 내보냅니다.
WFQ의 경우, 각 큐에 가중치를 부여하여 패킷을 처리하는 방식입니다.
해당 방식들을 자유롭게 사용중입니다. 이렇게 포워딩까지 알아봤습니다.
지금까지 데이터가 전달되는 과정을 알아봤습니다.
프로세스로부터 데이터를 받아서 데이터를 보내기 위해서 처리해야 되는 작업부터 시작해서 데이터를 어떠한 방식을 사용해서 보낼 것이고, 얼마나 보낼 것이고, 어떤 경로를 통해서 보낼 것이며, 어디를 통해서 보낼 것인가? 등등 알아봤습니다.
이 글은 본인이 데이터의 전체적인 흐름을 잡고 싶어서 정리한 내용이라 자세한 내용은 정리하지 않고 되도록이면 간단하게 정리했습니다.
자세한 내용을 참고하고 싶다면, 저의 블로그에 정리를 했으니 참고하면 될것같습니다. ^^
Reference
