
작성일 : 2021.01.03
작성자 : 이정관 (leejk526@gmail.com)
참고 영상
오픈도메인 챗봇 ‘루다’ 육아일기: 탄생부터 클로즈베타까지의 기록
💡 본 문서에 나오는 슬라이드는 위 영상에서 캡쳐한 것이므로, 저작권은 스캐터랩(scatterlab)에 있음을 명시합니다.요약
- 오픈도메인 챗봇의 어려운 점 (One-to-many, 무한한 컨택스트) 에 대해 언급을 하였고, 스캐터랩의 경우, 100억 카카오 메세지를 보유하고 있어, 한국어 실제 대화 데이터셋에서 확실히 강점을 가지고 있다.
- 루다 알파 모델의 경우 XiaoIce 프레임워크를 따르고 있으며 NLU, Retriever, Ranker로 구성되어 있으며, 모델이 꽤나 복잡한 편이다. 평가는 SSA(Sensibleness & Specificity Average; Google Meena)로 평가한다.
- 루다 알파에서 루다 베타로 넘어가면서, 1. 프레임워크 단순화, 2. DialogBERT (for NLU, Response Selection) 부분 개선, 3. 응답 후보(또는 DB) 퀄리티 개선, 4. SSA 평가 기반의 데이터 레이블을 24,000 개 만들어 Response Selection 성능을 개선하였다.
- 핵심 교훈으로서, 신뢰할만한 벤치마크의 중요성, 엄밀한 실험의 중요성, 모델 단순화의 중요성, 린하게 제품을 만드는 것의 중요성에 대해 언급한다.
- 향후 개선 계획을 소개하고 있다. (Persona, 말을 잘 거는 루다, 초대형화, 기억과 개인화, 경량화)
목차
1. 오픈도메인 챗봇이란?
1.1 챗봇의 두 영역
- 목적 지향형 챗봇 (Goal-oriented chatbot)
- 특정 주제, 편의성, 비서 역할
- 오픈도메인 챗봇 (Open-domain chatbot)
- 자유 주제, 소셜 니즈, 친구 역할
1.2 오픈도메인 대화가 특히 어려운 이유
1. One-to-many 문제
-
하나의 컨텍스트에서 서로 다르지만 좋은 답변들이 다수 존재

-
마찬가지로, 다양한 유형의 오답도 존재

-
머신러닝 관점에서 학습이 어렵다
2. 무한한 컨텍스트

3. 부족한 대화 데이터
- 대부분의 언어 데이터셋은 문어체
- 화자, 턴 등의 대화만의 특수성을 반영한 데이터셋을 대량으로 구하기 어려움

4. 스캐터랩은 데이터셋에서 독점적인 우위 보유?
- 한국어 100억 카카오톡 메세지
- 100억 == 10,000,000,000 == 30B turns?
- 일본어 10억 라인 메세지
- 10억 == 3B turns?

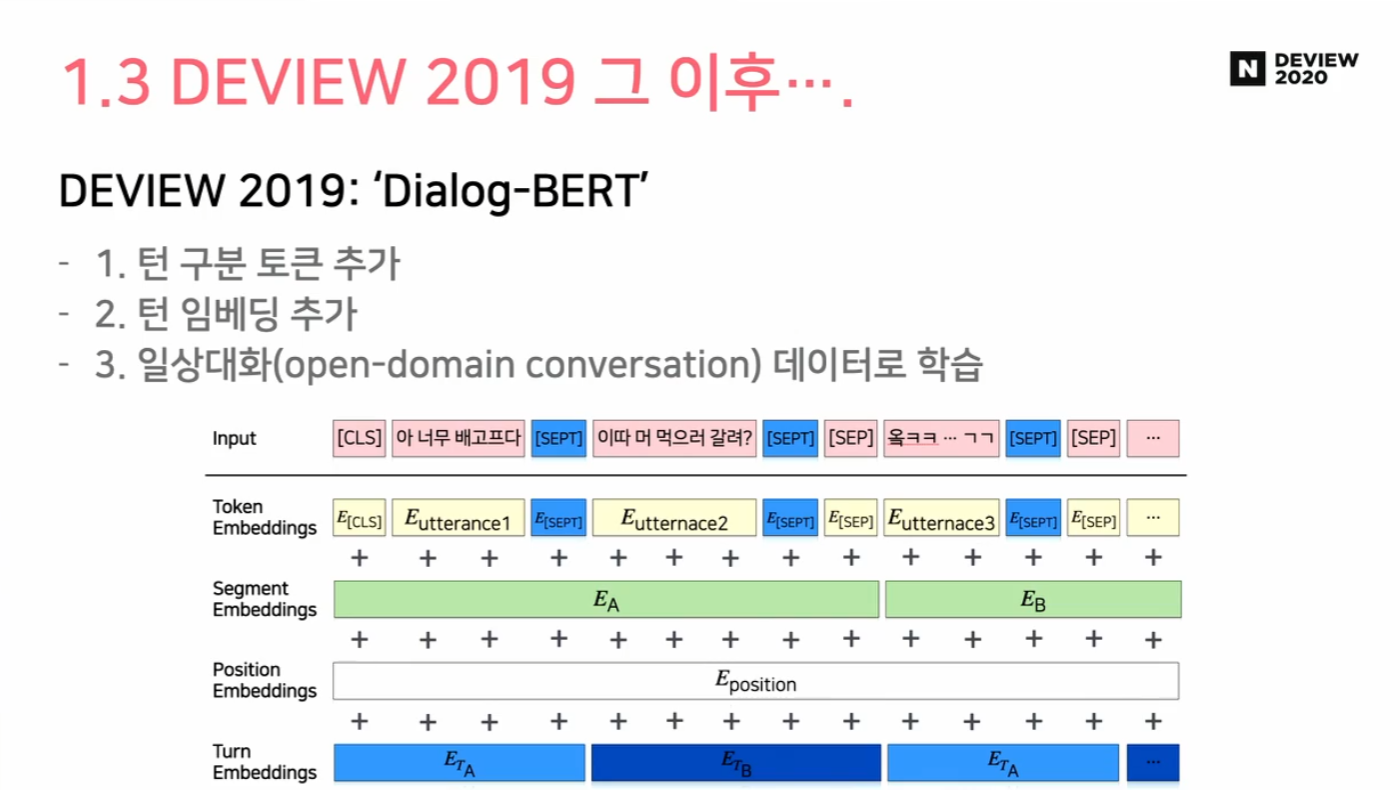
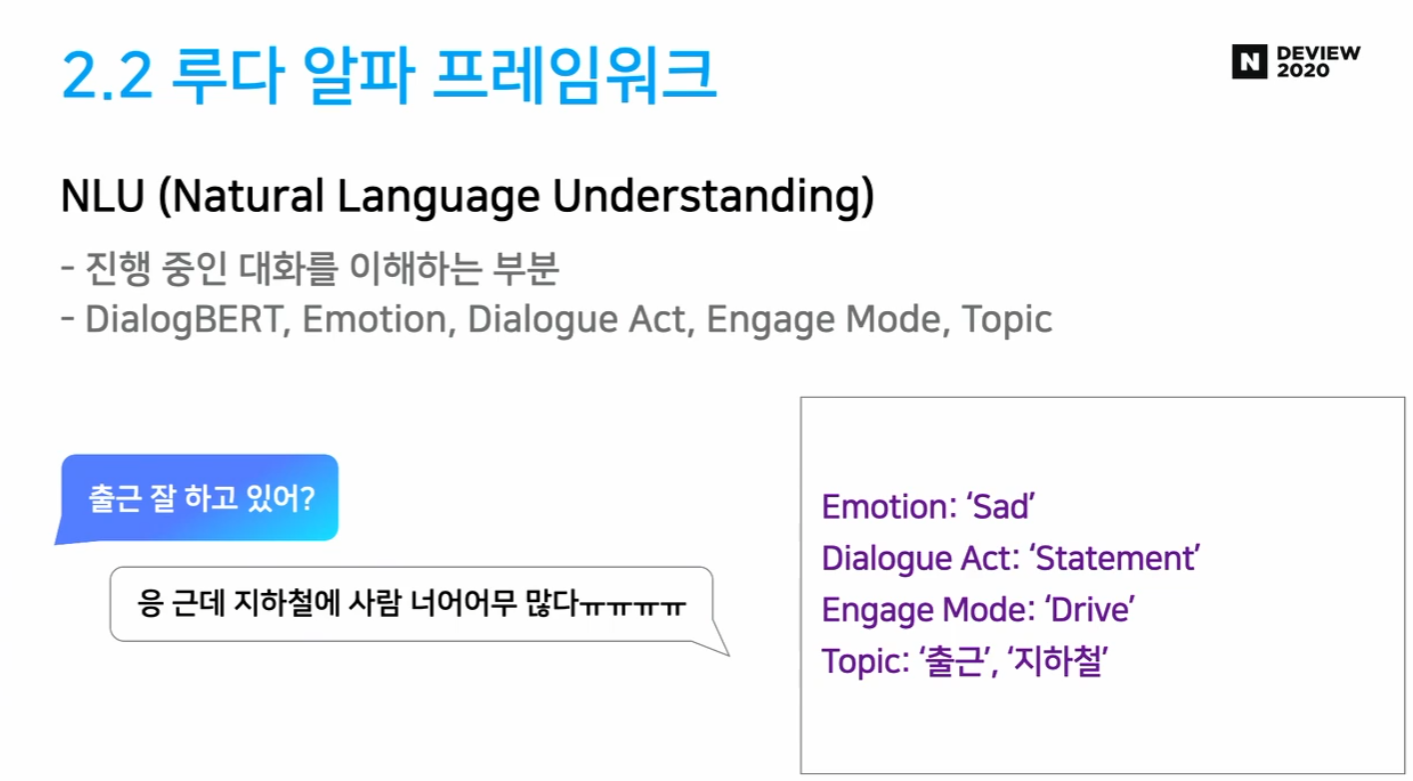
1.3 DEVIEW 2019: “Dialog-BERT”
- 턴 구분 토큰 추가
- 턴 임베딩 추가
- 일상대화 (open-domain conversation) 데이터로 학습
2. 루다 알파: XiaoIce 기반 프레임워크
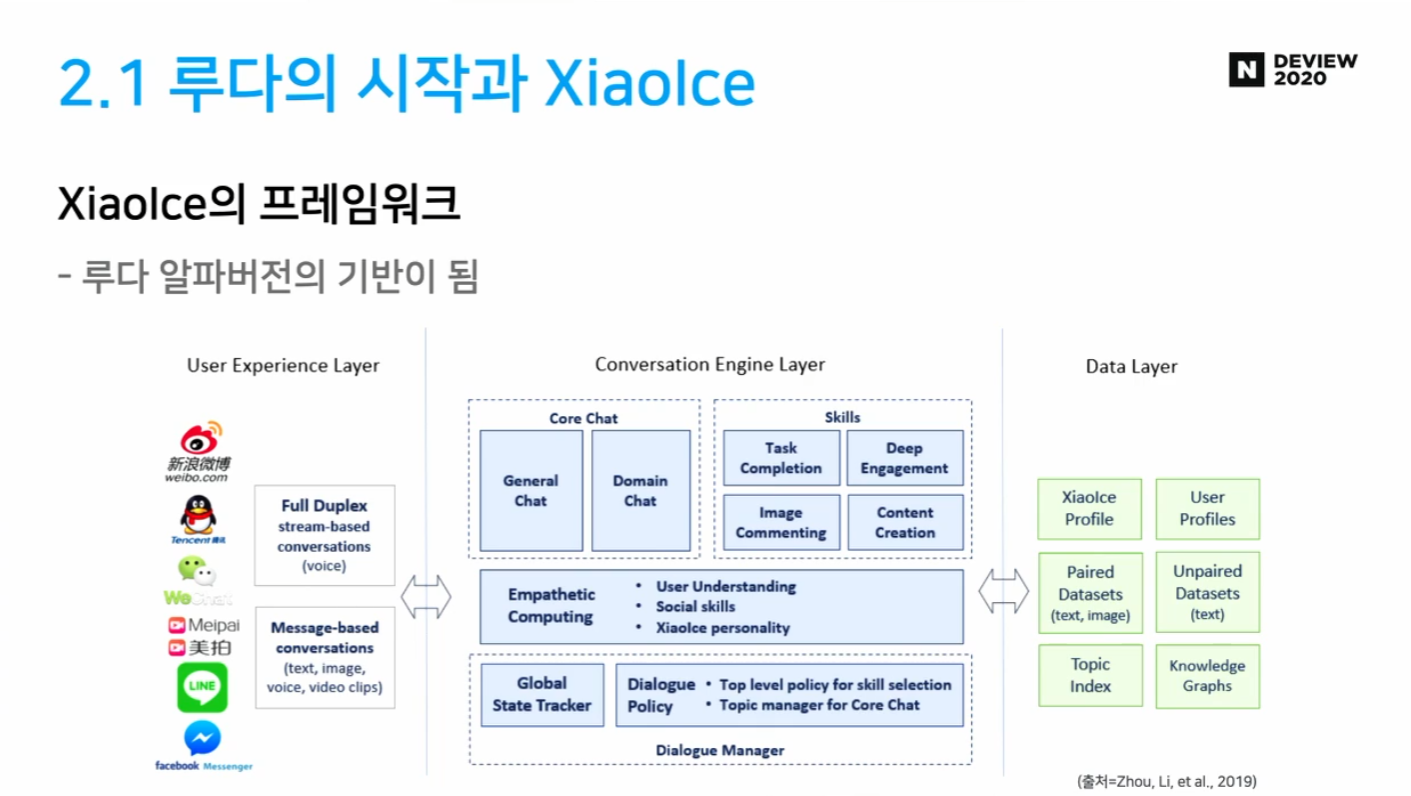
2.1 루다의 시작과 XiaoIce
- 목표
- 엄청 많은 사람들과 (100만명 이상)
- 엄청 많은 대화를 (하루 평균 20턴 이상)
- 엄청 오랜 기간 동안 (3년 이상)
- 나누는 오픈도메인 챗봇을 만들자!
- XiaoIce: Microsoft가 만든 소셜 챗봇
- Microsoft가 만든 소셜 챗봇
- 중국(2014), 일본(린나, 2015), 인도네시아(린나, 2017) 서비스
- 6억 6천만명 친구

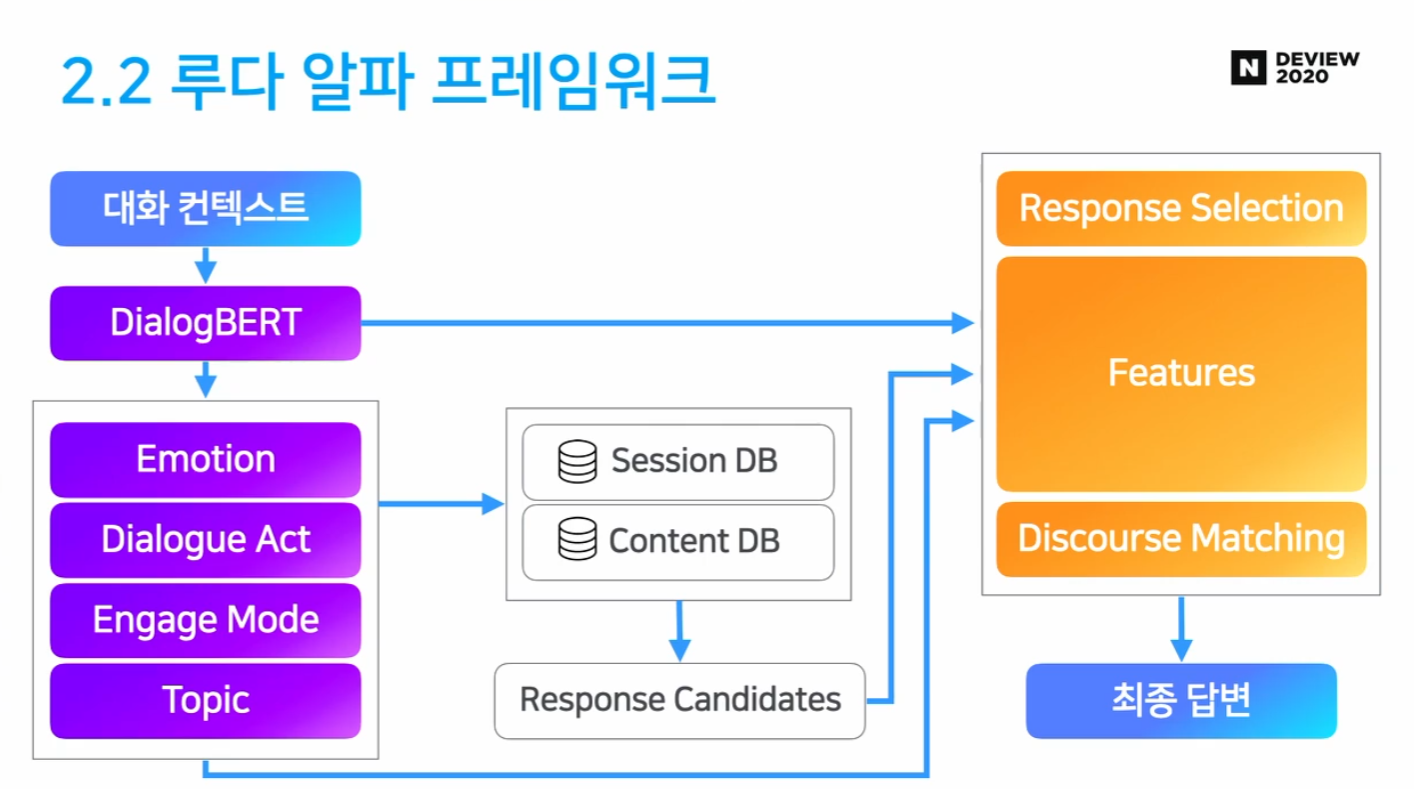
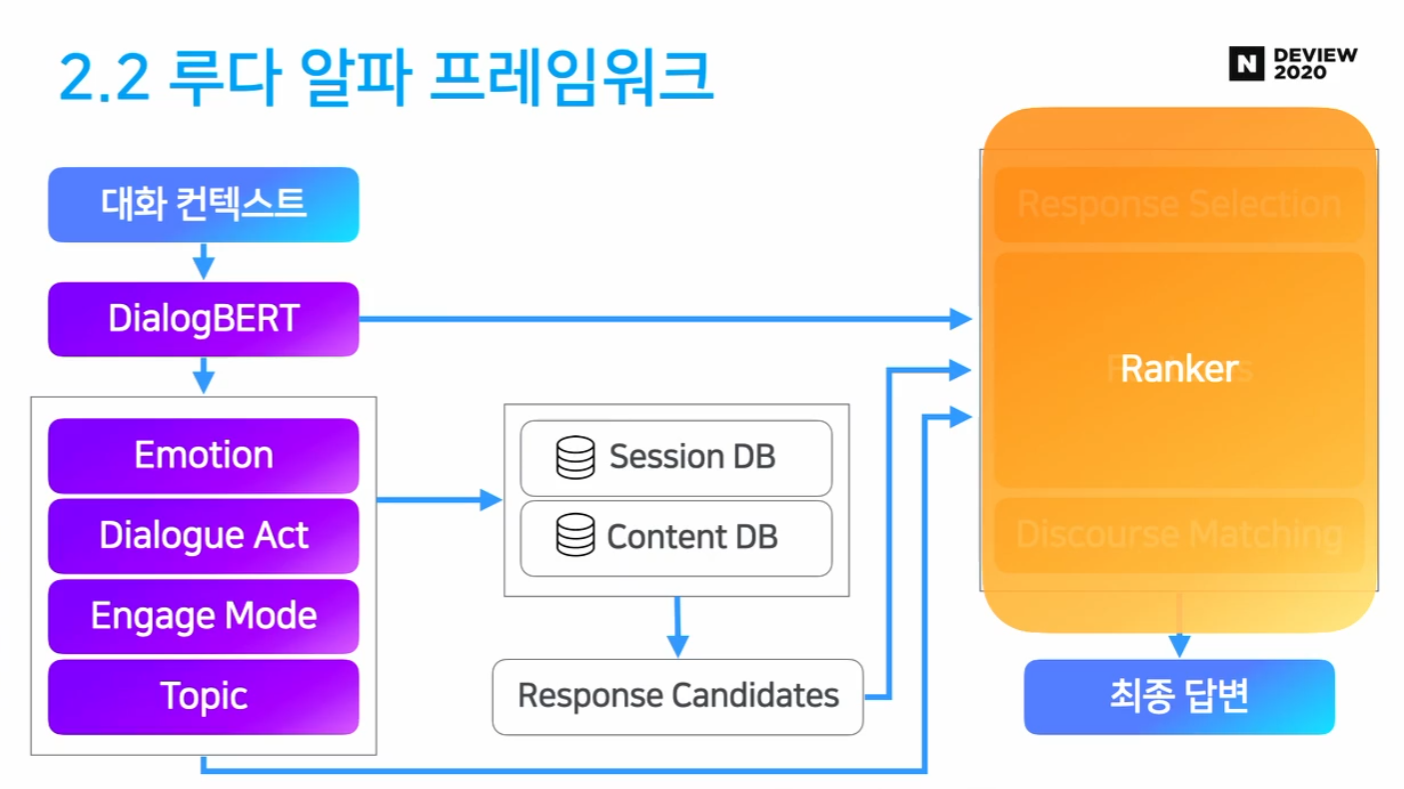
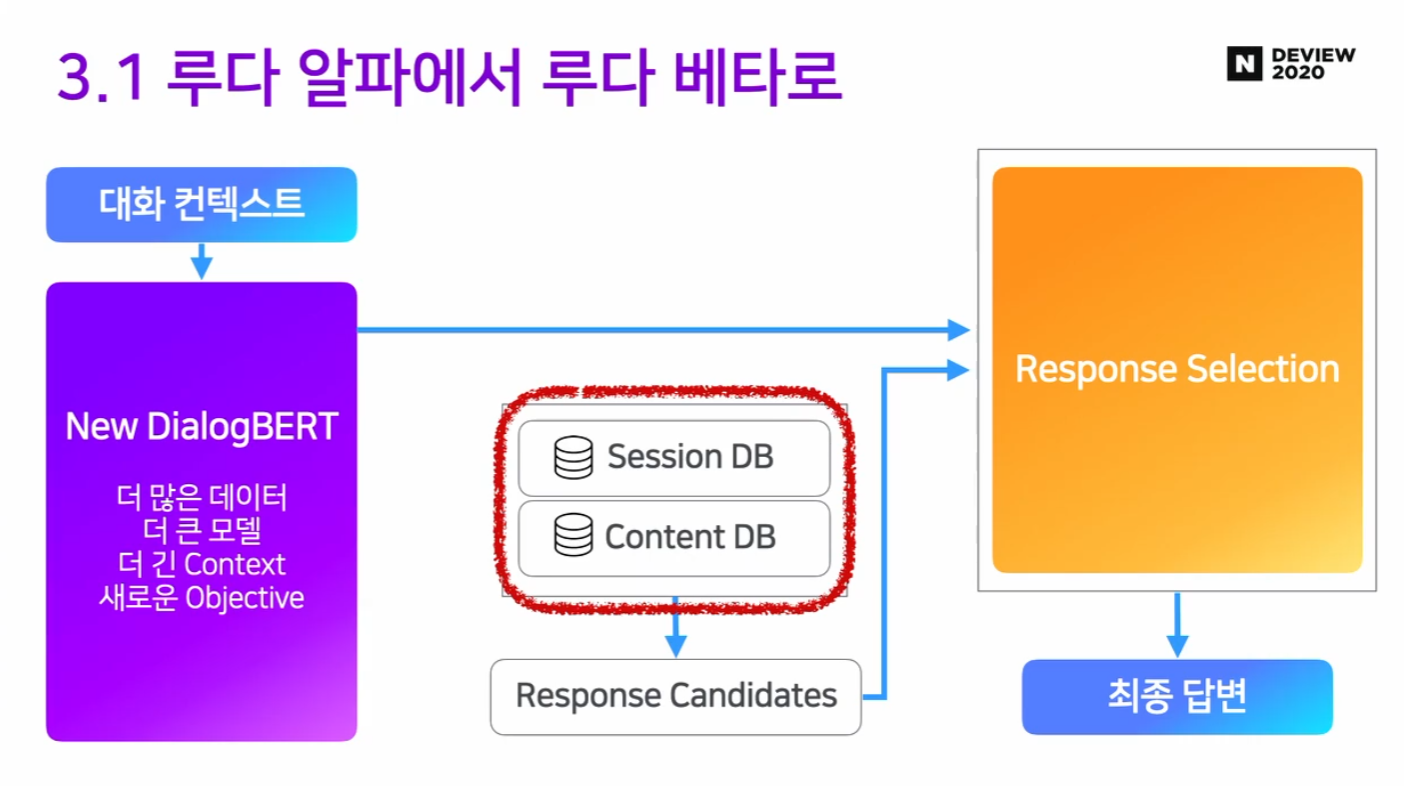
2.2 루다 알파 프레임워크
- 루다 알파 전체
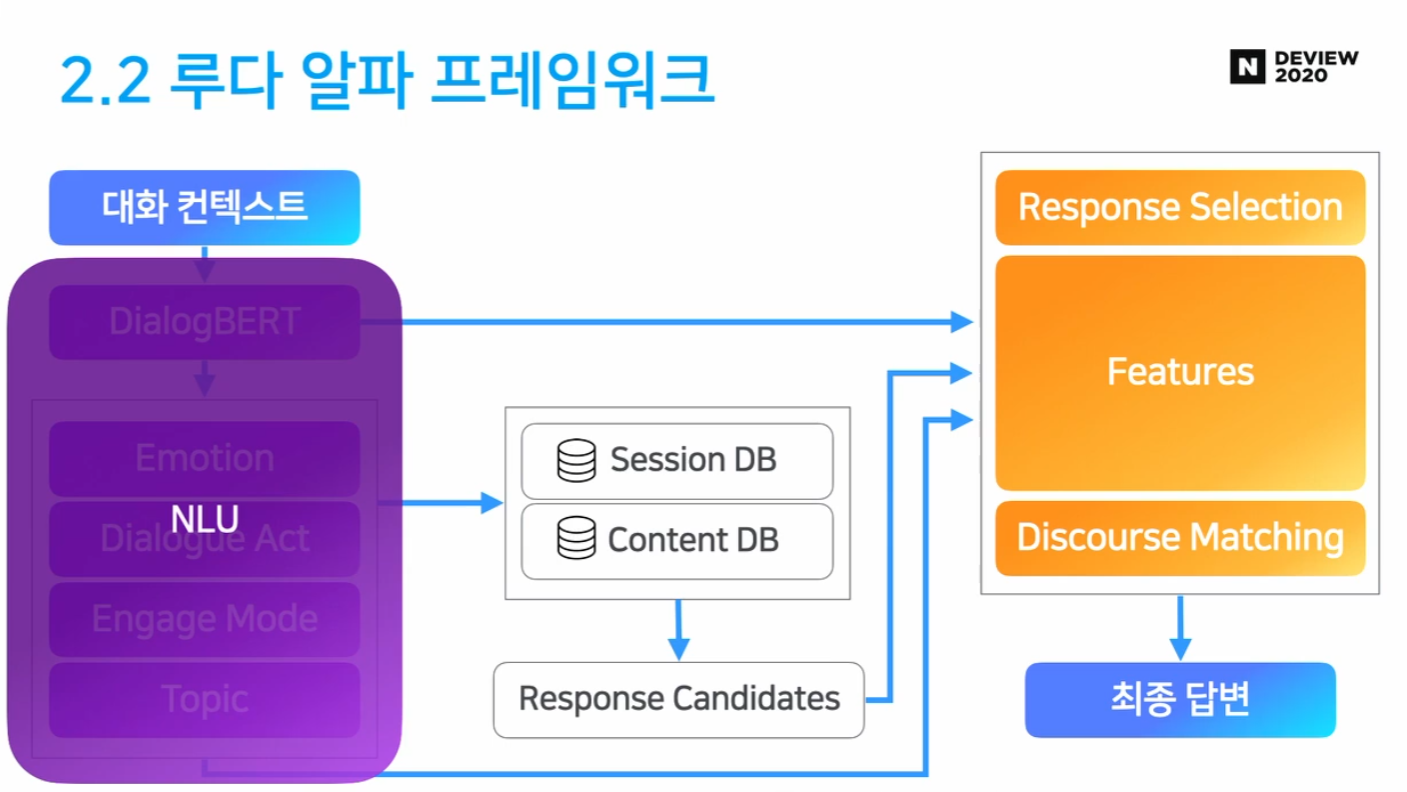
- NLU
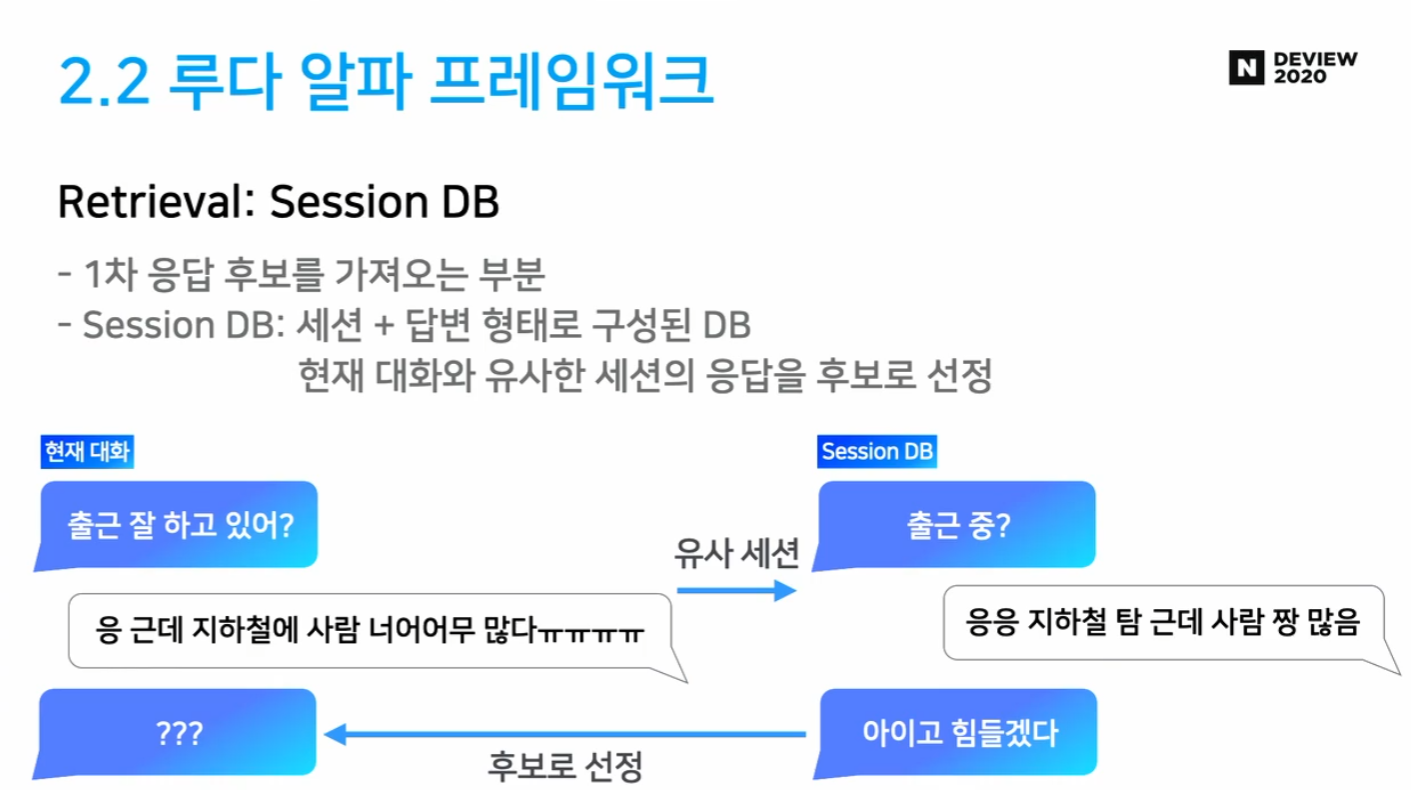
- Retrieval
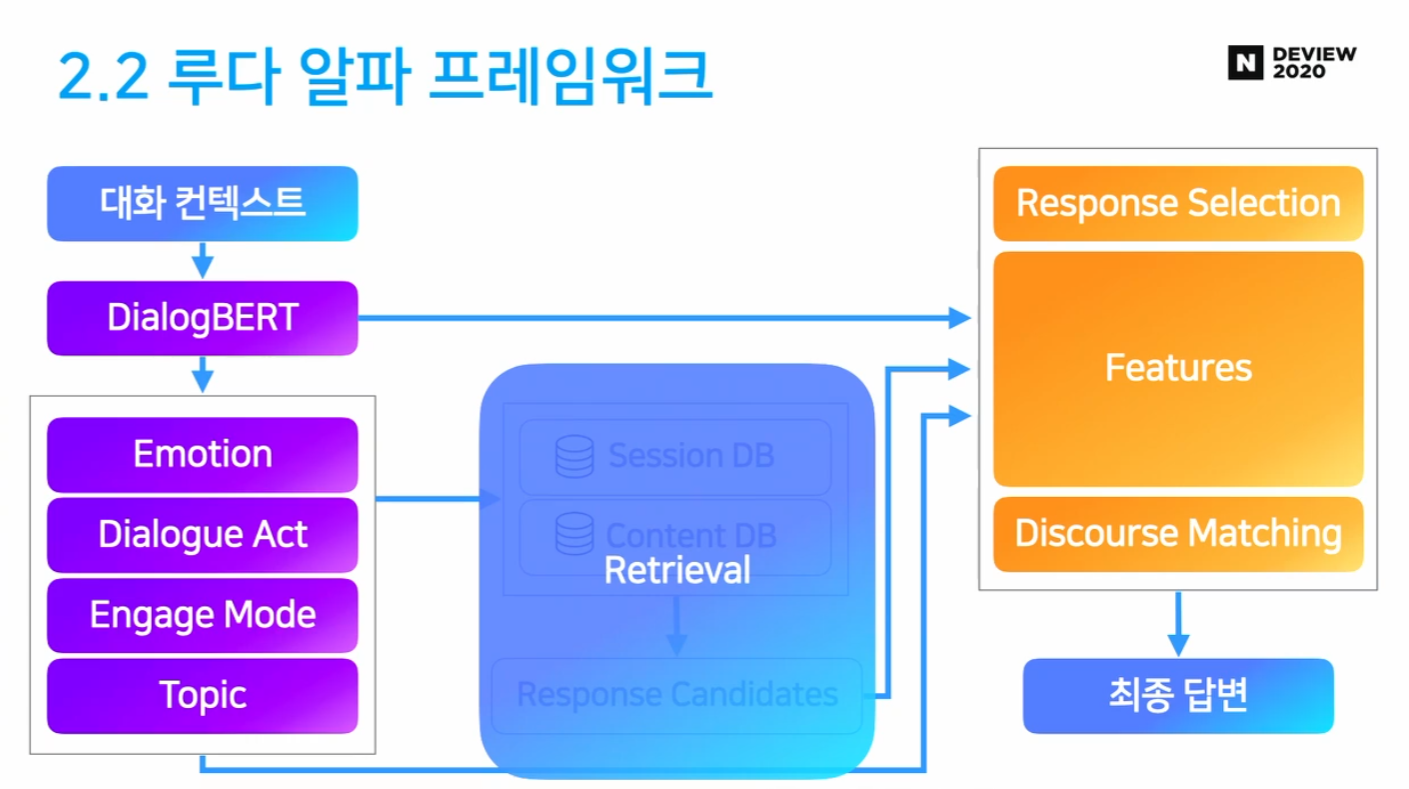
- Ranker
NLU: Dialog BERT
Retrieval: Session DB
Retrieval: Content DB

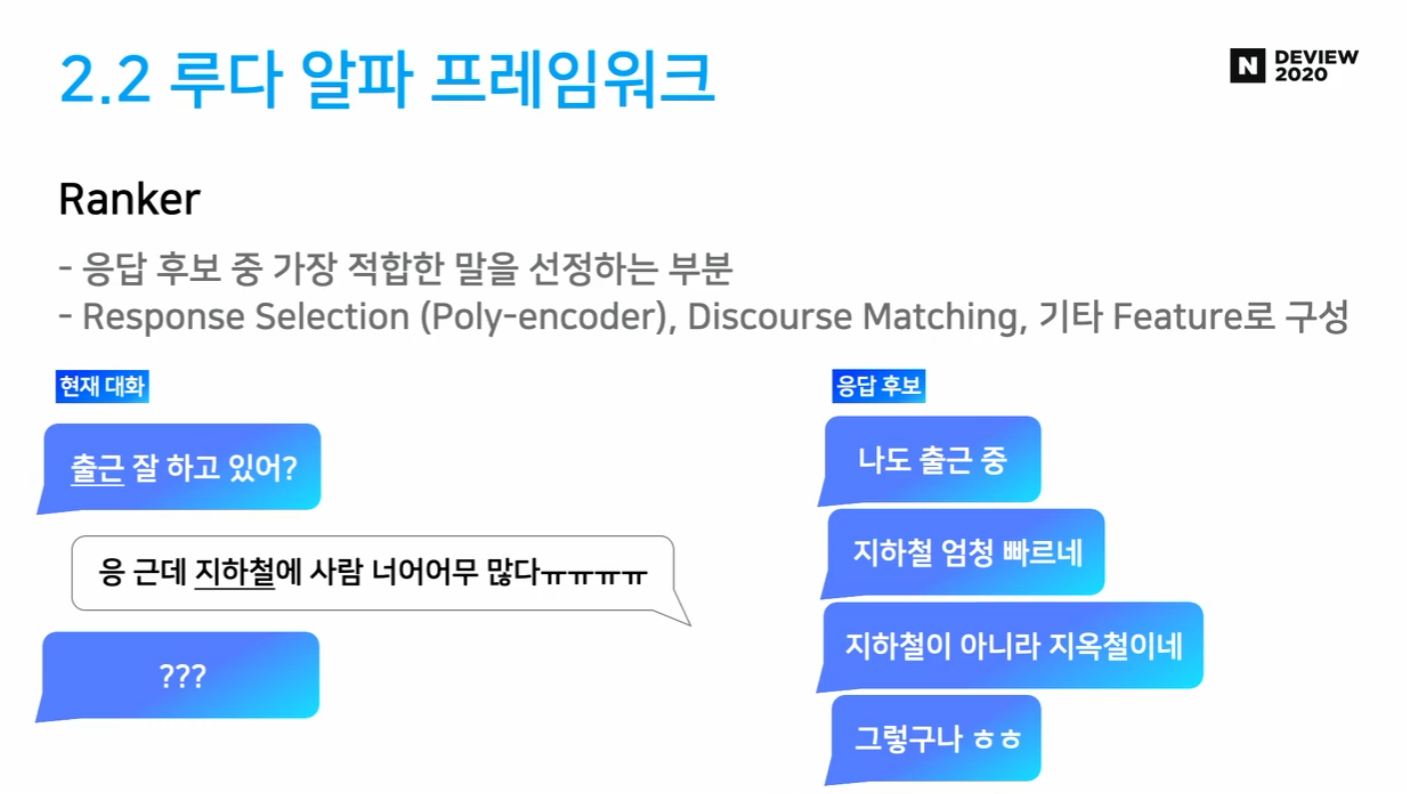
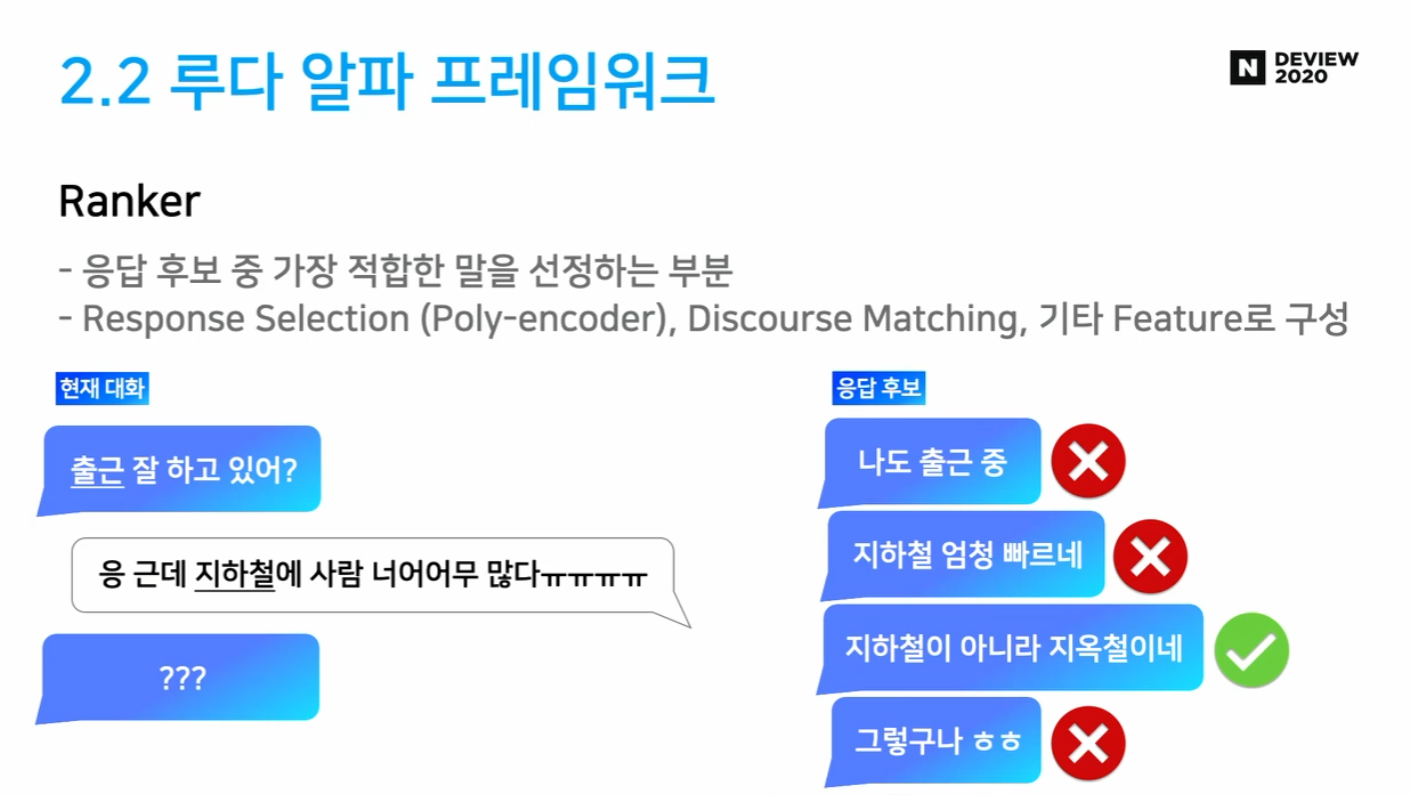
Ranker
- 응답 후보들 중 가장 좋은 응답 선정
- Response Selection (Poly-encoder)
- Discourse Matching
- 대화 흐름 상 가장 적절한 응답 설정
2.3 루다 알파 성능 평가
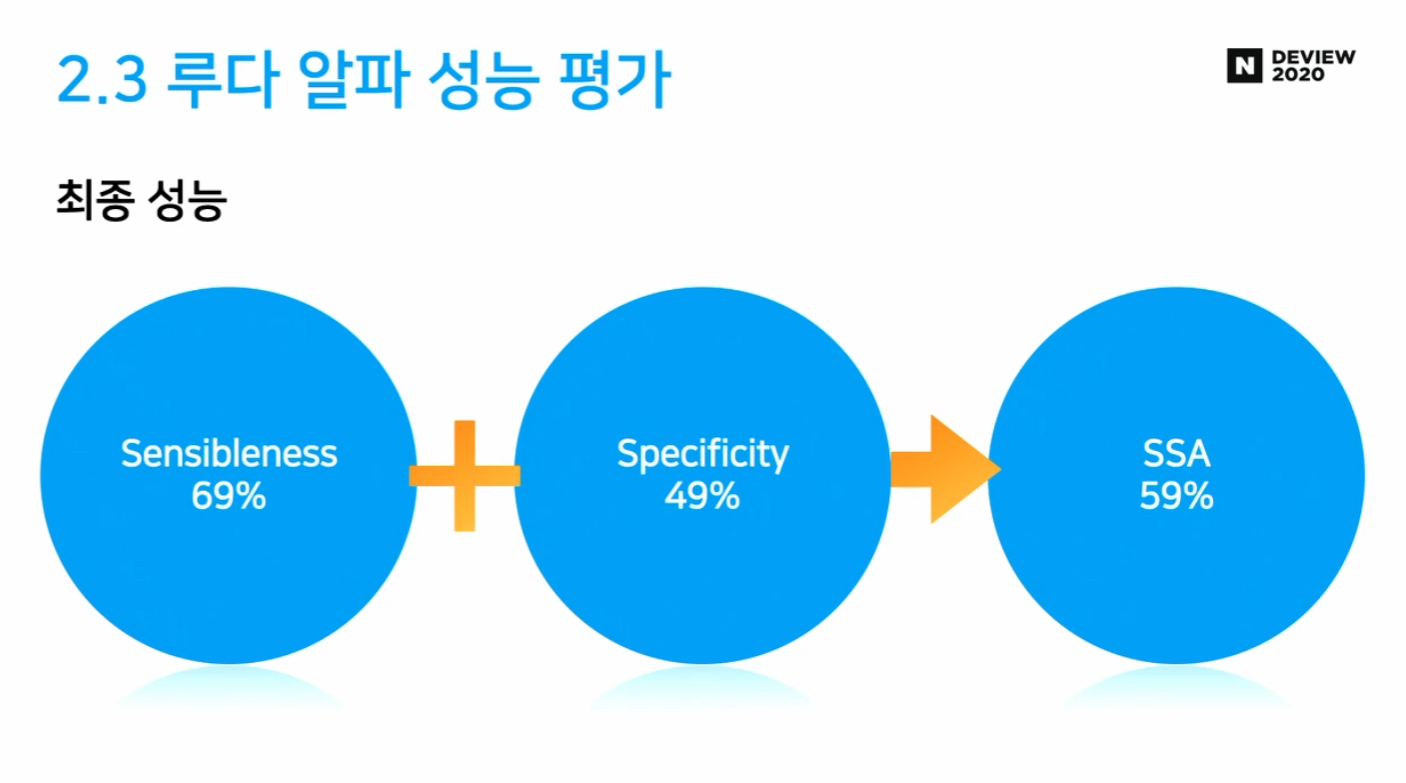
- SSA (Sensibleness & Specificity Average)
- 기본적으로 오픈도메인 chitchat은 다양한 도메인 때문에 평가하기 까다로움
- 어떤 기준?? ⇒ 학계에서도 아직 정립된 것이 없음
- SSA는 Meena에서 측정한 성능 지표
- Sensibleness : 응답이 말이 되는지?
- Specificity : 응답이 구체적인지?

2.4 루다 알파 클로즈베타

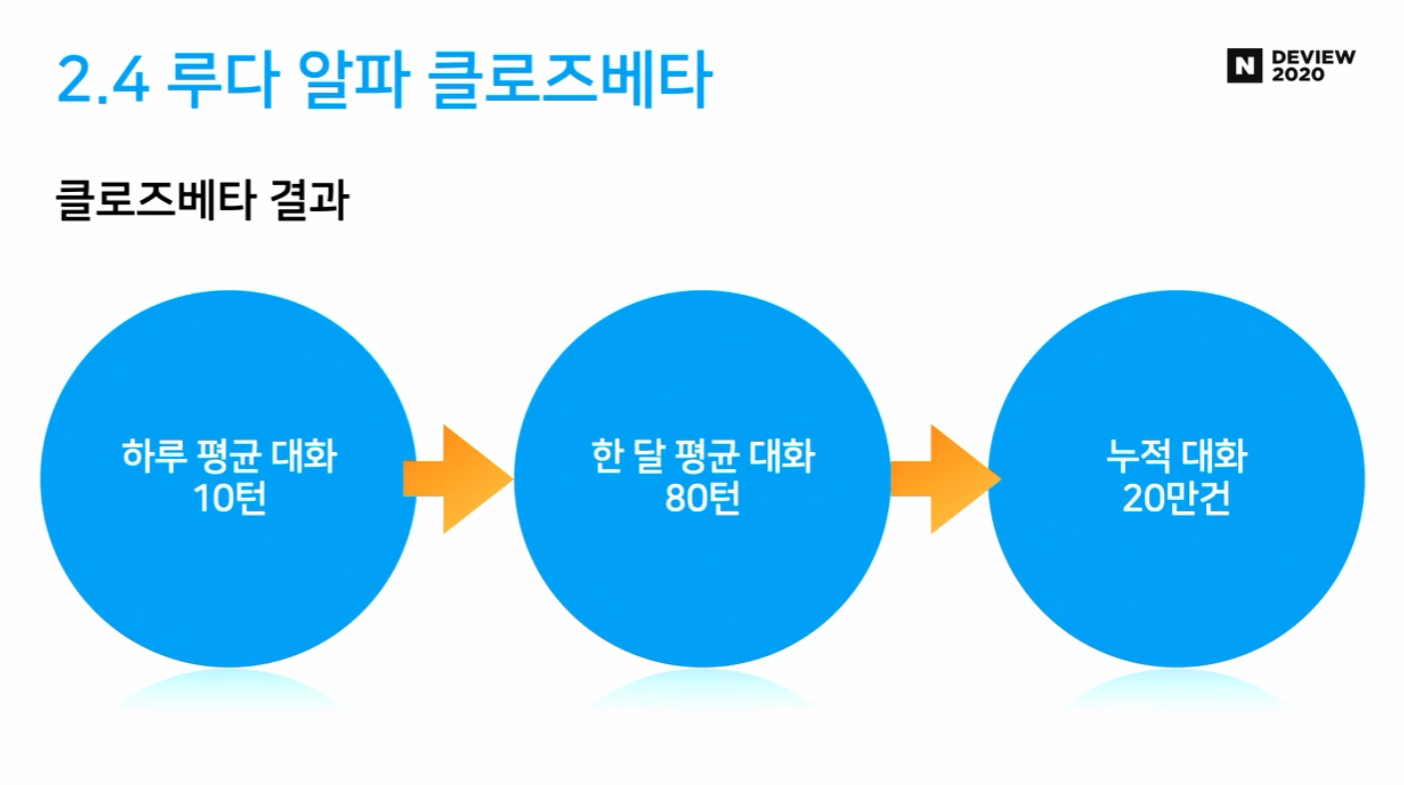




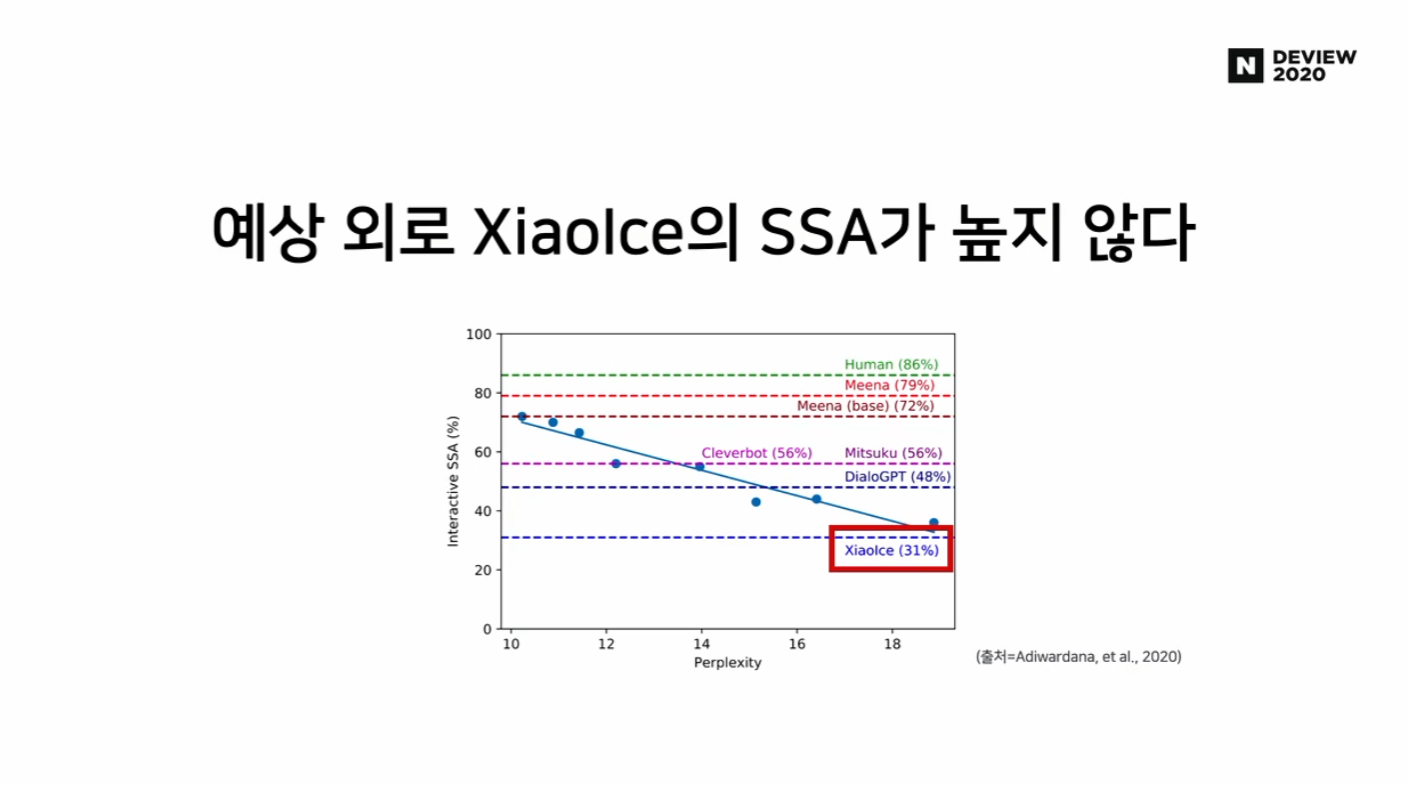
- 루다 알파 버전의 모방 모델인 XiaoIce의 SSA가 높지 않다
- 루다 알파 버전의 문제점
-
복잡한 구조
-
응답 DB의 낮은 퀄리티
-
Response Selection 성능
-
나이브한 Retrieval
-
첫 DialogBERT의 구조적 한계

-
3. 루다 베타: Retrieve & Rank
- Retrieve 와 Rank가 핵심이여서 다음과 같이 이름을 지음.

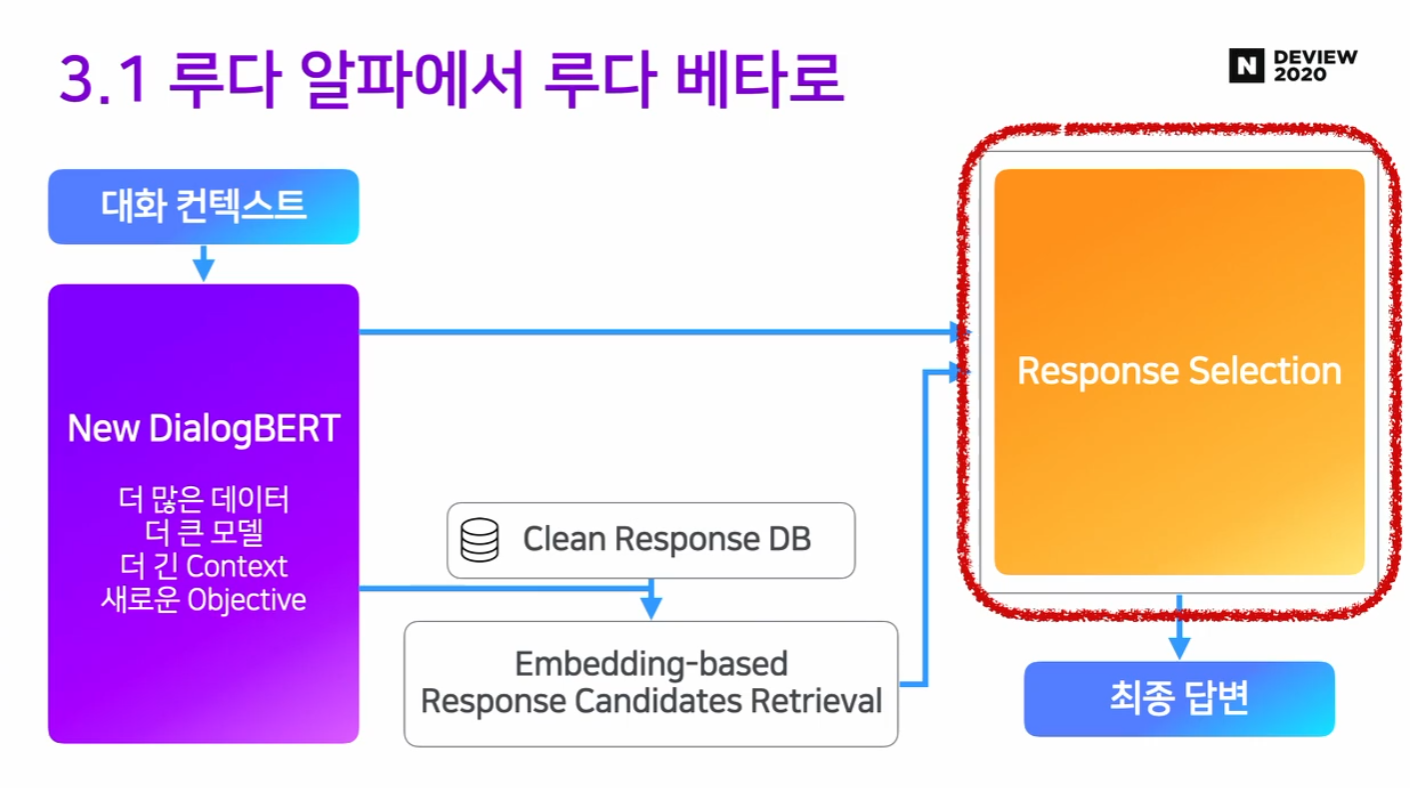
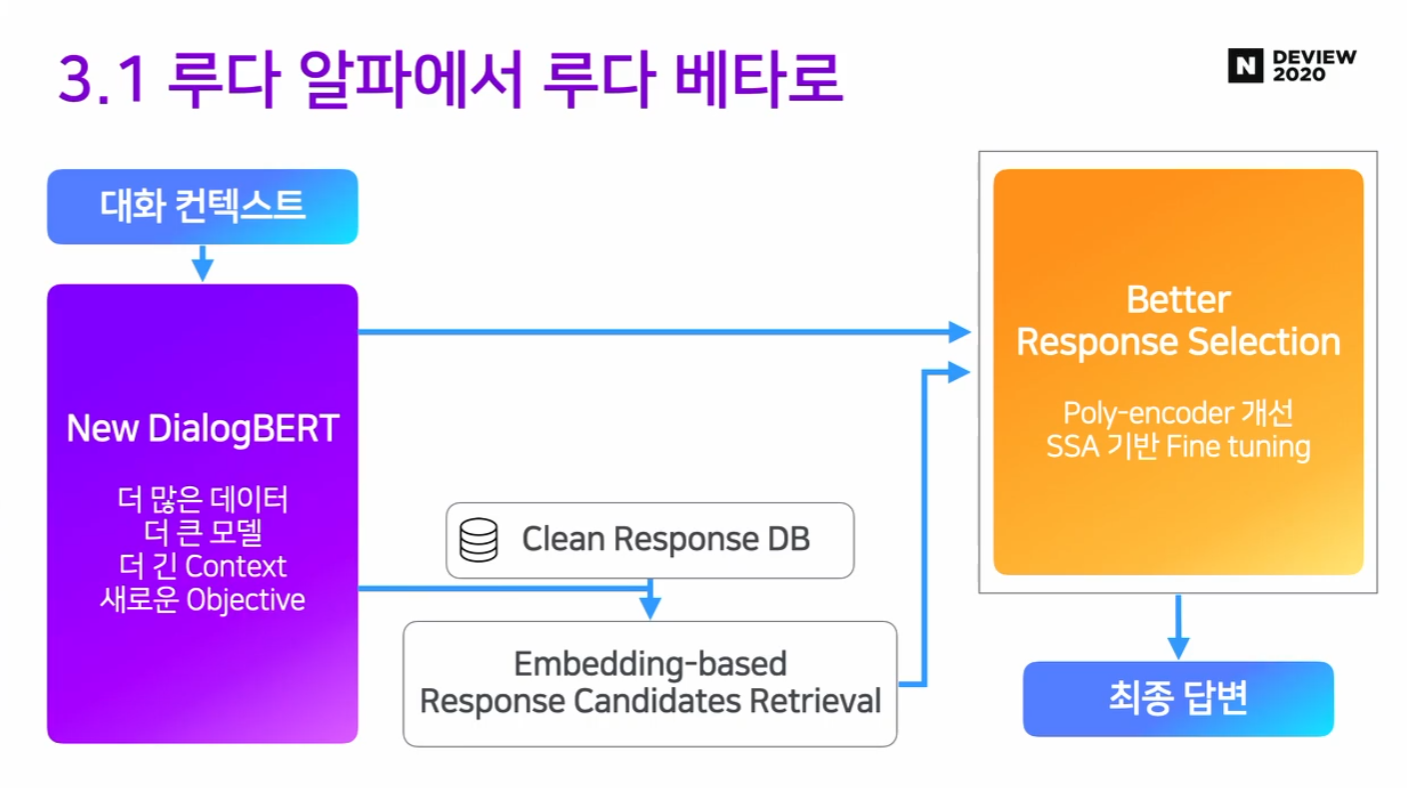
3.1 루다 알파에서 루다 베타로
업데이트 1. 프레임워크의 복잡도를 줄이자
-
즉, 단순화
-
성능 개선의 이점 보다 복잡도 증가로 인한 computing power 이슈가 더 크다
-
좋은 트레이드 오프 (단순화 > 복잡성)

-
모델 복잡성 해소
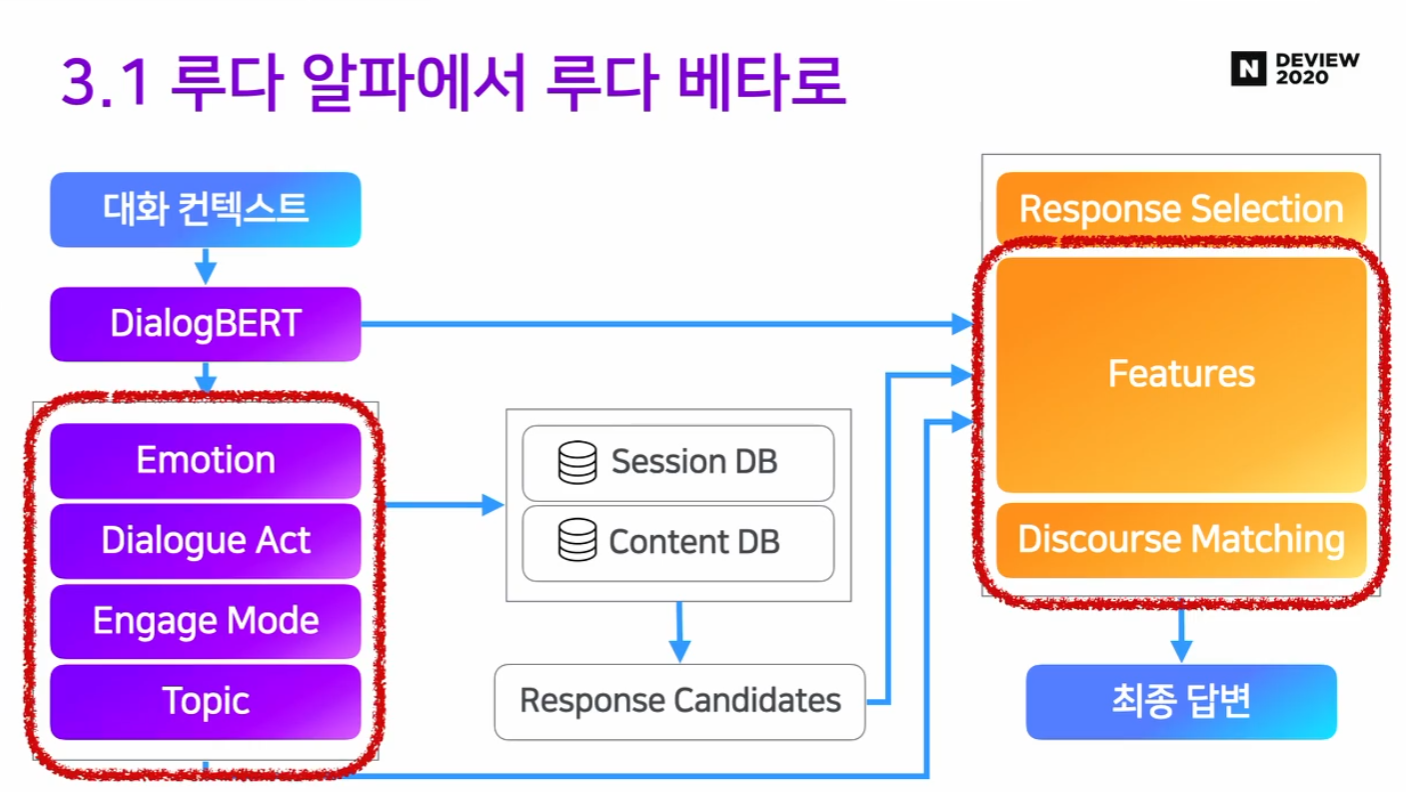
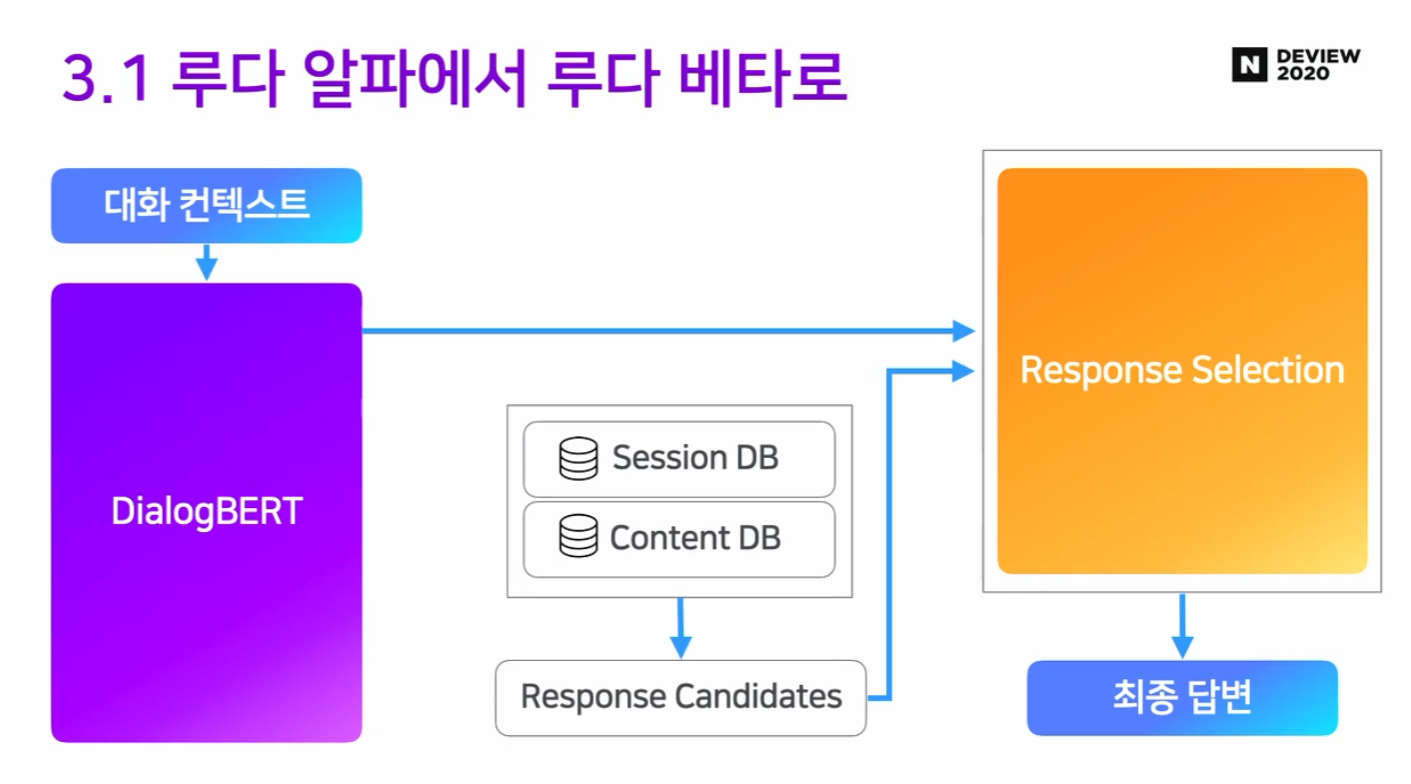
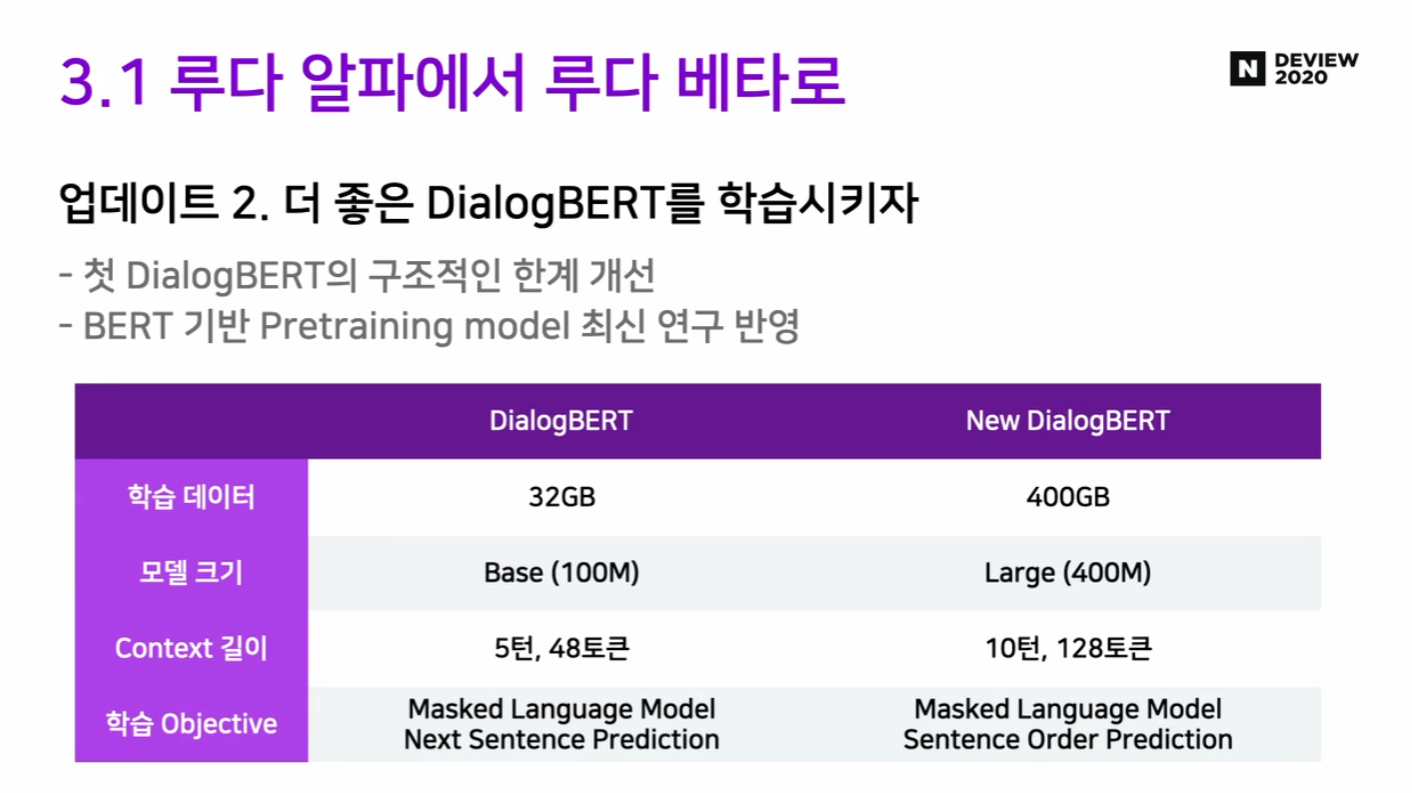
업데이트 2. 새로운 DialogBERT 제안!
- DialogBERT는 NLU 파트에서도 쓰이지만 Response Selection에서도 쓰이고 있어, 매우 중요한 파트.
- 의문점) DialogBERT 디자인은 어떻게?
-
Scale up! (모델 크기)
-
Context 길이
- 5 turns, 48 tokens ⇒ 10 turns, 128 tokens
-
학습 Objective
- MLM, Sentence Order Prediction
-
- DB 파트 개선
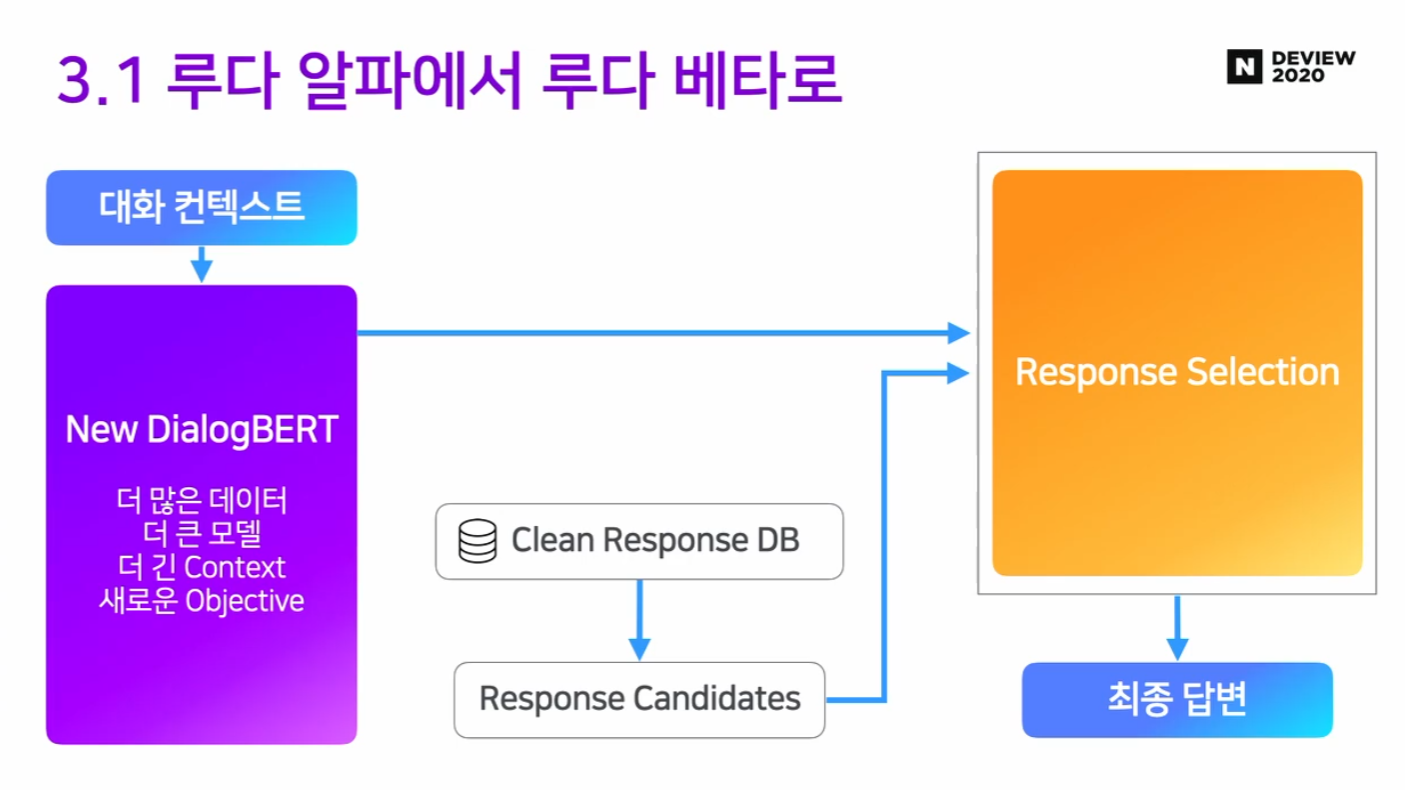
업데이트 3. 응답 DB 퀄리티를 높이자
-
단일 응답 DB로 변경!
-
DB 퀄리티 개선: 중복 문장, 퀄리티 낮은 문장, 페르소나에 맞지 않는 응답 제거
- 사람과 사람의 대화이기 때문에, 불완전한 문장이나 끊기는 문장이 있을 수 있음
- 끊기는 문장의 경우, 의미를 알 수가 없는 경우도 있음
- 페르소나에 안 맞는 문장의 경우 제거
-
20대 여대생이 페르소나인데, 1. 군대를 다녀왔다던지, 2. 아는 형(호칭)이 잘못된 경우, 3. 과장님(직책이 안 맞음) 이야기가 나오는 경우

-
-
개정안 : Clean Response DB
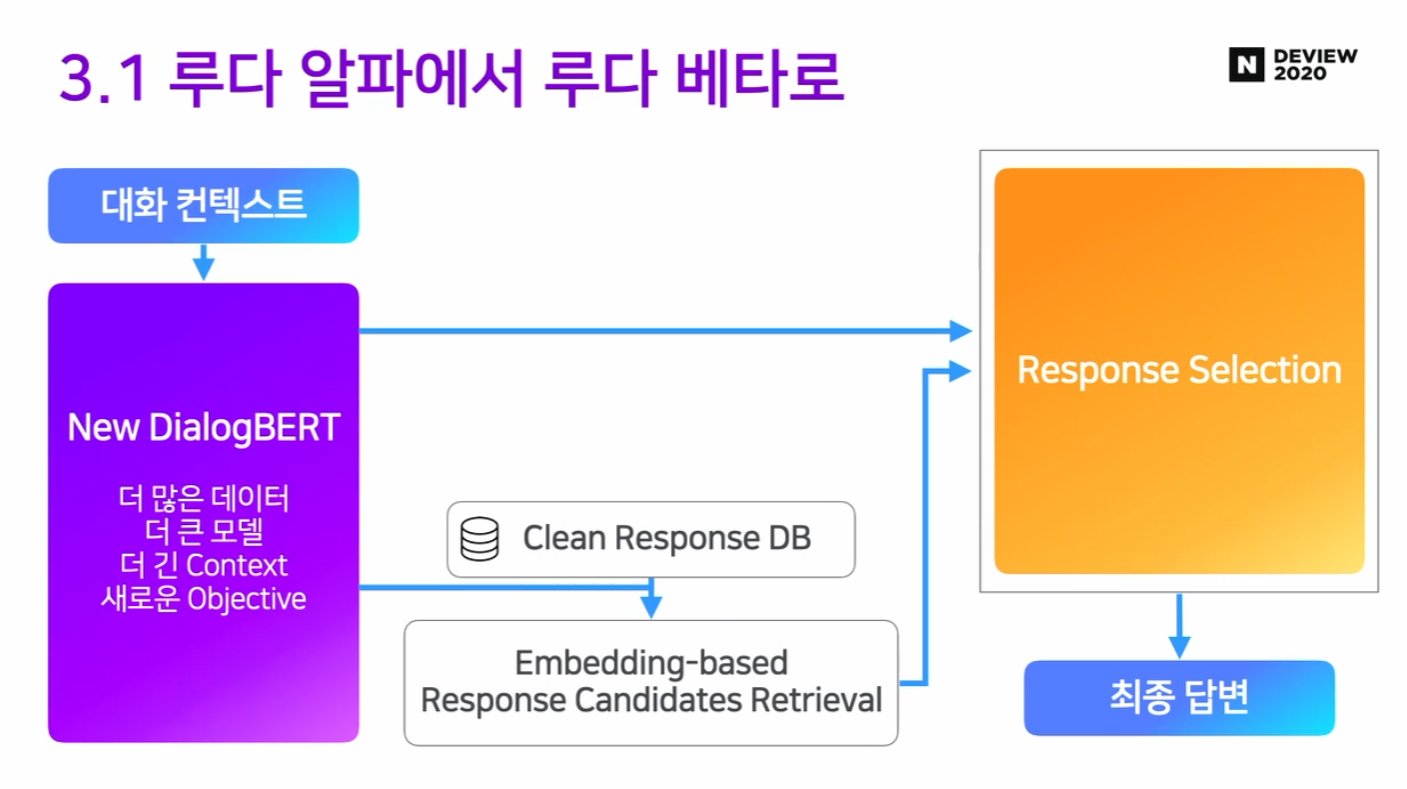
업데이트 4. 응답 후보를 의미 기반 (Semantic based) 으로 뽑자
- 기존 : TF-IDF류의 lexical 요소를 기반으로 응답 후보를 선정
- 단어가 겹친다거나, 토큰이 겹칠 때 응답후보로 선정
- 대화 임베딩과 응답 후보 임베딩의 cosine similarity로 응답 후보 선정
- 즉, Bi-encoder 로 응답 후보 선정
- 응답 후보에 대해서는 미리 임베딩 계산
- 차원 축소를 통해 1억개 이상의 응답 후보 에서도 서빙 가능하도록 구현
- [JG] FAISS 같은 것으로 할 수 있을 듯?
- ⇒ 1차 응답 후보를 추리는 과정임

- Response Selection 파트는 매우 중요함!
- 후보들 중 진짜 하나의 문장을 선정하는 과정이기 때문!
- 후보들 중 진짜 하나의 문장을 선정하는 과정이기 때문!
업데이트 5. Fine-tuning으로 Response Selection 성능을 개선하자
- Poly-encoder의 개량
- 직전 턴
- 마지막 말이 훨씬 중요하기 때문에 여기에 포커스를 할 수 있도록 함.
- 같은 화자의 턴 별도 학습
- 루다 모델이 앞에서 했던 말을 일관되게 할 수 있도록 같은 화자의 턴 별도 학습
- 직전 턴
- Fine-tuning
- SSA에 최적화된 SSA 레이블링 데이터를 추가하여 별도 학습.
- crowd sourcing을 통해 24,000세션 수집
- 응답 후보에 대해 레이블링 할 때 3명이 붙어 다수결로 결정

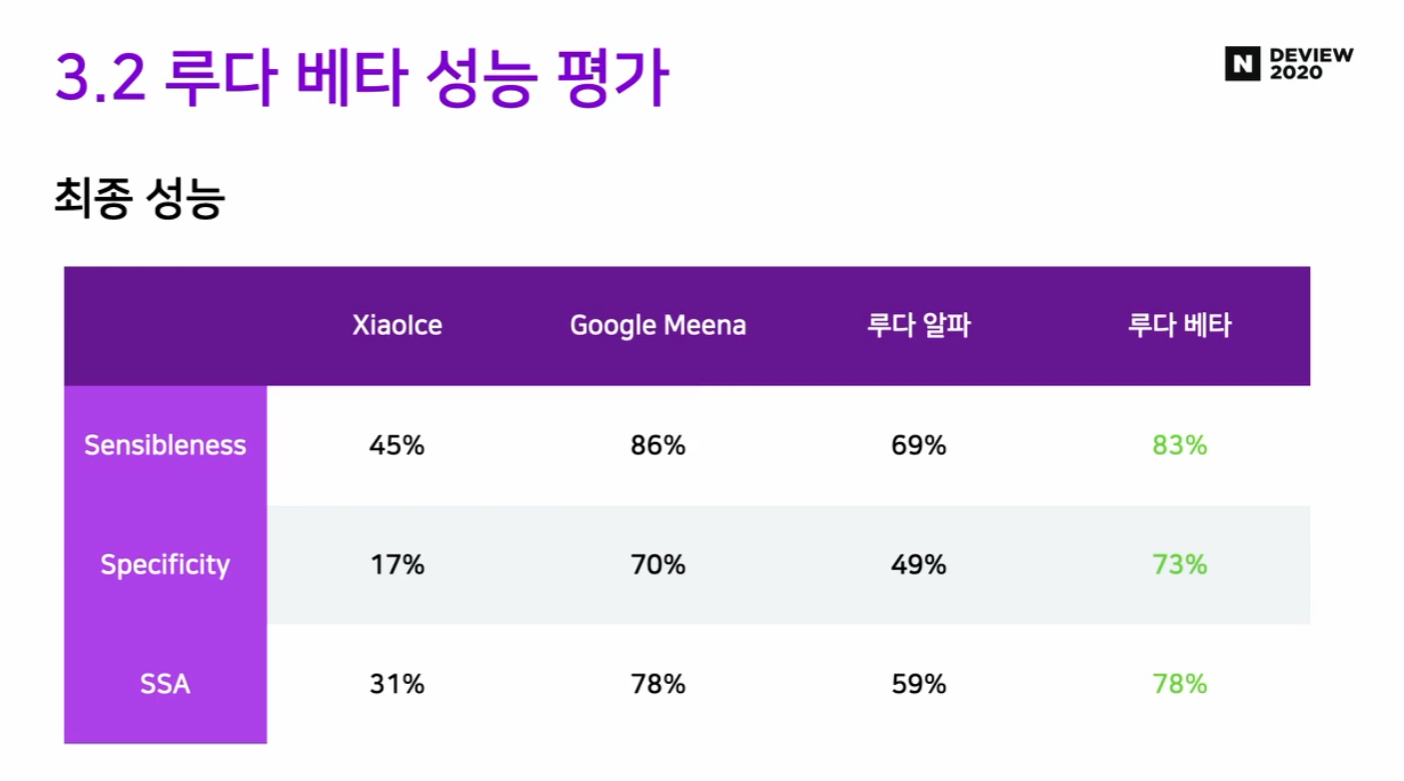
3.2 루다 베타 성능 평가
- 루다 알파보다 20% 성능 향상!

4. 핵심 교훈
- 이루다 팀이 겪은 시행착오를 덜 겪으시면 좋겠다
4.1 신뢰할만한 벤치마크를 만들자
- 좋은 벤치마크란 무엇?
- “Context는 몇 개여야 할까?”
- “Positive는 몇 개여야 할까”, “Negative는 어떤 종류로 몇 개여야 할까?”
- 좋은 벤치마크는 리서치의 등불이자 나침반
- Probing task의 중요성
-
Ribeiro et al., 2020 (https://aclanthology.org/2020.acl-main.442.pdf)
-
정량적인 결과와 함께 어떤 걸 잘 하고, 못하는지 톺아봐야 함

-
4.2 엄밀한 실험이 더 빠르다
- 제품을 목표로 하는 머신러닝 리서치의 딜레마
- 리서치의 엄밀함 vs. 제품 릴리즈를 위한 속도
- 엄밀한 진행이 오히려 시간을 아끼게 해준다
- 변인 통제, 실험의 기록, 실험 순서, 타 모델 및 데이터를 통한 검증 등

4.3 복잡도도 성능만큼 중요하다
- 복잡도 vs. 성능
- 프레임워크를 더 복잡하게 만들면서 성능을 올리는 논문이 다수
- 하지만 성능을 올리는 게 능사일까?
- 때로는 심플함을 위해 성능을 포기하는 게 나을 수 있음
- 성능을 포기하되 심플하게 했을 때의 이점
-
버그 발생 확률 줄어듬
-
디버깅이 편함
-
추후 모든 작업의 효율 향상

-
4.4 머신러닝 제품도 린하게 만들자
- 다시 처음으로 돌아간다면..?
-
챗봇이 작동할 수 있는 최소 제품(MVP)을 만들고, 거기서 개선을 하자

-
5. 앞으로의 과제
5.1 중단기 과제
- Persona
- 어떻게 루다에 페르소나에 맞는 말을 깊게 골라낼 것인가?
- 말을 잘 거는 루다
- 어떻게 말을 거느냐에 따라 사람들의 응답률이 다르더라
- [네이버 댓글] Q: 어떻게 답하고 싶은 타이밍에 답하고 싶은 내용으로 말을 걸 것인가? 구글처럼 사용자 분석알고리즘으로 나이나 관심있는 분야를 기록하면 되지 않을까요?, 그걸 이용해서 사용자의 하루 패턴 시간표를 만드는
- 어떻게 말을 거느냐에 따라 사람들의 응답률이 다르더라
- Continual Learning
- 어떻게 루다와 사용자의 대화를 통해 지속적인 개선을 이룰 것인가?
- 외부 데이터
- 어떻게 대화가 아닌 텍스트를 통해 지식과 콘텐츠를 녹여낼 것인가?
- 정관의 생각
- 외부 구글 검색 결과?
- GIF 첨부?
- 이모지?
- 어떻게 대화가 아닌 텍스트를 통해 지식과 콘텐츠를 녹여낼 것인가?
5.2 중단기 과제
- 초대형 생성 모델
- 어떻게 2B 파라미터 이상의 생성 모델을 잘 학습할 것인가?
- 기억과 개인화
- 어떻게 사용자의 정보와 과거 대화를 기반으로 개인화된 대화를 할 것인가?
- 경량화
-
어떻게 초대형 모델을 서빙할 것인가?

-
스캐터랩의 비전
- (실제 사람은 아니더라도) 대화상대로서 선호되는 Conversational ai 개발

Take-away / 소감
- 많은 시행착오를 이미 스캐터랩에서 거친 것을 느꼈다. 그들의 시행착오를 간접적으로라도 느끼고, 시간을 세이브 할 수 있으면 좋을 것 같다.
- DialogBERT를 보면서, 모델 스케일의 중요성을 느낀다.
- 응답 셋이 1억 개 쯤 된다는 것이 놀랍다.
- SSA 평가 지표를 잘 활용한 듯 하다. (또는 더 나은 메트릭이 있다면 찾아봐도 좋을 듯) 그들도 말하듯, 좋은 평가 지표는 등대이자 나침반!
- 린하게 하되,(모델 구성 단순화, end-to-end를 여러번 하기), 평가 및 계획은 엄밀하게! (어렵다 물론)
- 업데이트 5 처럼, 필요하다면 데이터 라벨링도 해야할 것 같다.
- 반대로 말하면, 데이터 수집할 때 로그가 중요하다는 생각이 든다.
- 중장기적인 관점에서, 어떤 타겟을 가지고 할 것인지 정하고 이에 맞는 데이터 수집이 필요하다.
- 위의 중단기 과제에서 가장 공감되는(또는 중요한 부분은), 챗봇이 언제, 어떻게 말을 걸어서 사람들로 하여금 재미를 느끼게 하는 것일 것 같다. [앱의 재사용률 관점?]
- 위 비전도 공감된다. 사람은 아니지만, 대화 상대로서 선호되는 챗봇을 만들어서 사용시간을 늘리는 챗봇을 만드는 것.
해당 내용에서 잘못된 부분이나, 의문인 부분에 대해 연락 주시는 것은 언제든 환영입니다!
Email : leejk526@gmail.com
