비지도 학습
-
비지도 학습은 정답 없이 데이터에서 패턴이나 구조를 찾는 머신러닝 기법을 의미
-
활용 영역
- 데이터의 군집화
- 차원 축소
- 이상치 탐지
지도 학습과의 비교
1. 지도 학습
- 입력 데이터에 대한 정답을 알고 있는 상태에서 모델을 학습하여, 새로운 데이터가 들어왔을 때
레이블을 예측. ex)이미지 분류, 스팸 메일 분류
- 비지도 학습
- 별도의 레이블이 없고, 오직 입력 데이터만으로부터 구조를 파악. ex)고객 그룹화, 문서 토픽
분류
군집 분석의 개념
군집 분석
- 비슷한 특성을 가진 데이터들을 묶어서 각 그룹 내 데이터들끼리의 유사도를 최대화하고, 다른
그룹과의 차이는 최대화하는 기법
목적
1. 데이터의 구조 파악 : 정답 없이 데이터의 자연스러운 분포를 확인
2. 세분화 : 마케팅에서는 고객 세분화를, 제조업에서는 센서 데이터로 기계 작동 패턴 분류 등을
수행
군집 분석의 절차
1. 데이터 수집 및 전처리 : 이상치 제거, 결측치 처리, 스케일링/정규화
-
군집 수 또는 파라미터 설정 : K-Means의 경우 k 설정, DBSCAN은 거리, 최소 데이터 수 등
-
군집화 알고리즘 적용 : 설정에 따라 알고리즘 수행
-
결과 해석 및 평가 : 실루엣 계수 등 군집 평가 지표 활용
-
사후 활용 : 마케팅 전략, 제품 개선, 이상치 탐지 등
K-Means
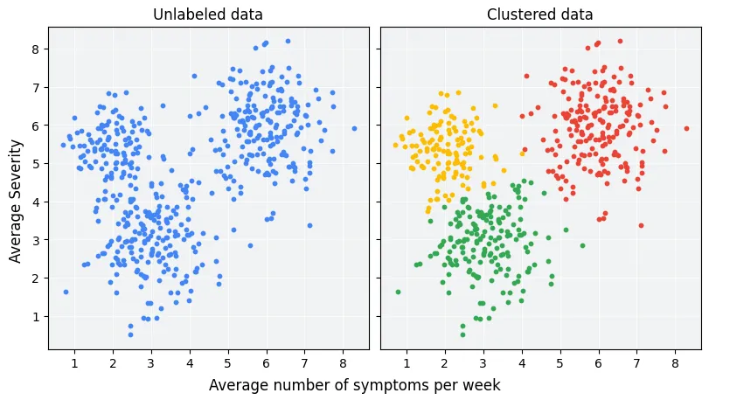
알고리즘
- 미리 군집 수 k를 설정
- 무작위로 k개의 중심을 선택 후, 각 데이터 포인트를 가장 가까운 중심에 할당
- 각 군집의 중심을 다시 계산하고 재할당하는 과정을 반복
- 군집 내 데이터와 중심 간 거리의 제곱합을 최소화
장점
- 계산 속도가 빠르고 구현이 간단
- 대용량 데이터에도 비교적 잘 잘동
단점
- 군집 수 k를 미리 알아야 함
- 이상치에 취약
- 구형 구조가 아닌 복잡한 형태의 분포를 파악하기 어려움
DBSCAN
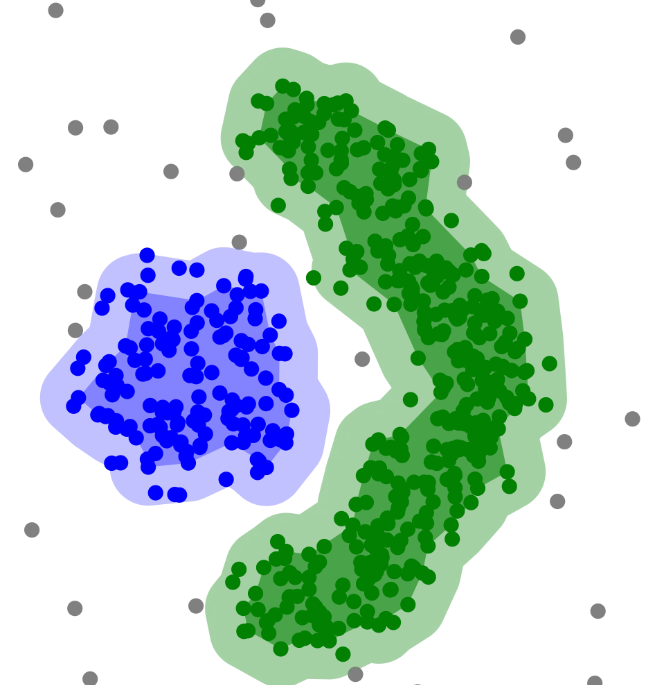
알고리즘
- 밀도 기반 군집화 기법. 일정 거리 내 데이터가 많으면 그 영역을 ‘밀도가 높다’고 판단해 하나
의 군집으로 결정 - k를 미리 설정하지 않아도 되며, 노이즈 포인트(어느 군집에도 속하지 않는 점)을 구분할 수 있
음
장점
- 군집 수를 사전에 알 필요가 없음
- 노이즈와 이상치를 자연스럽게 처리
- 구형이 아닌 복잡한 형태의 군집도 잘 찾아냄
단점
- 파라미터 ε와 minPts에 민감
- 데이터 밀도가 균일하지 않으면 성능이 떨어질 수 있음
예시
- 지리정보(GIS) 분석에서 지역별로 가게가 얼마나 밀집되어 있는지 분석할 때 사용
- 특정 지점에 가게가 몰려 있으면 하나의 군집, 중간에 뜨문뜨문 있는 가게는 노이즈(Cluster에 속하지 않는 포인트)로 분류
