문법 요약
np.array()
array.ndim
array.shape
array.dtype
array.sum()
array.min()
array.max()
array.mean
array.std()
np.unique()
len()
np.arrange()
np.where()
pd.Series()
ser.sum()
ser.min()
ser.max()
ser.mean()
ser.std()
ser.skew()
ser.kurt()
ser.unique()
ser.idxmax()
ser.isin()
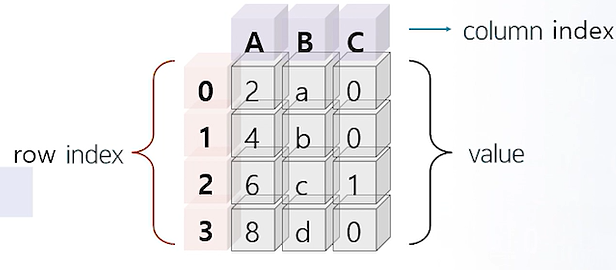
pd.DataFrame()
df.iloc[]
df.loc[]
pd.crosstab()
df.groupby()
기본문법
기본문법
코드의 작성
자료형
연산자
리스트
튜플
딕셔너리
제어문
조건문
반복문
사용자정의함수
라이브러리
numpy
Numpy
- 메모리 효율적인 벡터 산술연산 기능 제공
- 반복문 없이 전체 데이터 배열 일괄 연산 기능 제공
- 선형대수, 난수 발생, 푸리에 변환 등 다양한 연산 기능 제공
pandas
Pandas
- Numpy 기반 라이브러리
- 행과 열로 이루어진 객체를 다루기 용이(DataFrame)
- 시계열과 비시계열 데이터를 같이 다룰 수 있는 데이터 구조 제공
EDA : 수치형, 범주형 기술통계
Numpy 객체
np.array
교육과정에서는 array만 알면 된다.
import numpy as np
#create
np.array([1,2,3]) # 1*3 행렬
np.array([[1,2],[3,4]]) # 2*2행렬
np.array([1,2,3,4]).reshape((2,2)) # 2*2행렬
#retrieve
array=np.array([[1,2,3],[4,5,6]])
array[1][1] #5
array[1,1] #5
array[0,:2] # array[1,2]
array=np.array([[1,2,3],[4,5,6]])
#method, attribute
array.ndim # 2 , 차원
array.shape #(2,3) 각 차원 길이
array.dtype # dtype('int64') 데이터 타입
array.sum() # 21 합계
array.min() # 1 최소
array.max() # 6 최대
array.mean() # 3.5 평균값
array.std() # 1.7078.. 표준편차
nums = np.array([1,2,2,4])
set(nums) # {1,2,4} SET 반환
np.unique(nums) # array([1,2,4) 중복제
len(nums) # 4
np.arange(start = 3,stop = 8,step = 2) # array([3,5,7]) 3부터 시작해서 8까지, 2씩 증가하는 수열 배열 반환
np.where(nums == 2,1,0) # array([0,1,1,0]) : T/F
np.where(nums == 2, "ok!", "no!") # no ok ok no
Pandas 객체
- 시리즈(Series) : Pandas 객체의 1차원 객체, value와 index로 구성, Series()함수와 대괄호를 사용하여 생성
import pandas as pd
#Create
ser = pd.Series([1,2,3,3,4])
ser = pd.Series([1,2,3],index=["a","b","c"])
ser = pd.Series([1,2,3,3,4])
ser.sum() #13
ser.min() #1
ser.max() #4
ser.mean() #2.6
ser.std() # 1.1401..
ser.skew() # -0.4048.. , 왜도
ser.kurt() # -0.1775.. , 첨도
ser.unique() # [1,2,3,4] , 중복제거(고유값)
ser.idxmax() # 4 , 최대값 위치
ser.isin([1,2]) # TTFFF , 포함 여부 검사
ser.isin([6,7]).sum() #2- DataFrame : pandas 2차원 객체, value와 row index, column index로 구성되어 있음.
변수별로 문자,숫자 등 다른 속성 지정 가능. 기본적으로 dictionary를 활용하여 생성
#pd.DataFrame([1,2,2],[3,3,4])
#pd.DataFrame([[1,2],[3,4],[5,6]], columns = ["xx","yy"])
#pd.DataFrame(np.arange(4).reshape(2,2), columns = ["a","b"])
df = pd.DataFrame({"aa":[1,2,3],"bb":[2,3,4]})
df.aa
df["aa"]
df["aa"][:2]
df.iloc[1,1] # iloc : 정수 기반 인덱
df.iloc[:,0]
df.loc[:,"aa"]
df.iloc[:2,:]
df.iloc[:,0]
df.loc[:,"aa"]
데이터 요약
crosstab
- 두 변수를 조합하여 살펴볼 때 사용하는 Pandas 함수
- normalize 인자에 True, 1, 0값을 할당하여 값을 정규화 할 수 있음
df = pd.DataFrame({"aa":[1,2,3],"bb":[2,3,4]})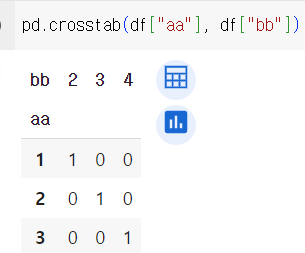
groupby
- 특정 변수 기준으로 요약 연산을 할 때 활용하는 데이터프레임 메서드
- 두 개 이상 변수를 기준으로 연산할 경우 변수명을 리스트로 묶음


표본 추출
키워드
임의추출
층화추출
계통추출
군집추출
pandas
sample
groupby
sklearn
model_selection
train_test_split
표본 추출 개요
표본 추출의 종류
- 단순 임의 추출(Simple Random Sampling)
: 별도의 규칙이 존재하지 않은 보통의 임의 추출- 층화 표본 추출(Stratified Random Sampling)
: 군집별로 지정한 비율 만큼의 데이터를 임의 추출- 계통 추출(Systematic Sampling)
: 첫 표본을 무작위로 추출하고 표집 간격 k만큼 떨어진 곳의 데이터 추출- 군집 추출(Cluster Sampling)
: 소수의 군집으로 분할하고 일정 수의 소집단을 임의 표본 추출실습 정리 : 데이터/주요 함수 및 메서드
csv file pandas read
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv(file)
df.head(2)unique, nunique
df["season"].unique()
print(len(df["season"].unique()))
print(df["season"].nunique())sample()
n:표본개수
random_state:seed
frac:percentage
df.sample(n = 3, random_state = 34)
#df.groupby("season").sample(n=2, random_state=34) # 각 그룹(season)별로 sample2개씩 뽑힘.
df.sample(frac=0.005, random_state=34)
len(df.sample(frac=0.005, random_state=34))
df.sample(frac=0.005, random_state=34).shape
df.sample(frac=0.005, random_state=34).shape[0]
train, test set split
df_train, df_test = train_test_split(df, train_size = 0.7, random_state=123)
df_train.head(2)실습문제
#주어진 데이터의 1.23% 추출 시 몇 개의 행이 추출되는가
df.sample(frac=0.0123).shape[0] # frac: percentage
#season 기준 5%씩 추출 시 추출되는 총 행의 개수는
df.groupby("season").sample(frac=0.05).shape[0]
#학습과 평가용 데이터 세트로 8:2 분리 시 평가 데이터 최고기온(seed=123으로 설정)
df_train,df_test = train_test_split(df,train_size=0.8, random_state=123)
df_test["temp"].max()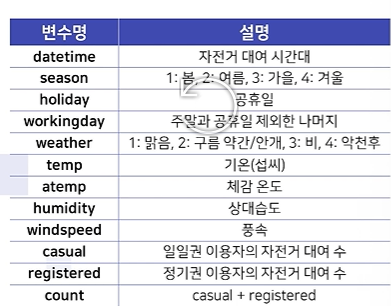
데이터 전처리 : 결측치 이상치
키워드
결측치
이상치
isna
isnull
notna
notnull
fillna
dropna
quantile
이상치
- 이상치 : 중심 경향성에서 멀리 떨어진 값
- 이상치의 처리 방법
- 이상치 처리에 절대적인 기준은 없음
- 대표적으로 Carling, Tukey 방법이 있음.
- 분포 기반으로 처리도 가능. (정규분포기준 상위,하위 n%제거 등)
결측치
- 결측치 : 값이 기록되지 않고 비어 있음
- 결측치의 처리 방법
- 결측치 처리에 절대적인 기준은 없음
- 단순 제거와 특정 값으로 대체하는 방식이 있음 (선형보간등..)
- 분석 데이터에서 결측치가 차지하는 비중이 낮은 경우 단순 제거하는 경우가 많음
실습 정리 : 데이터/주요 함수 및 메서드



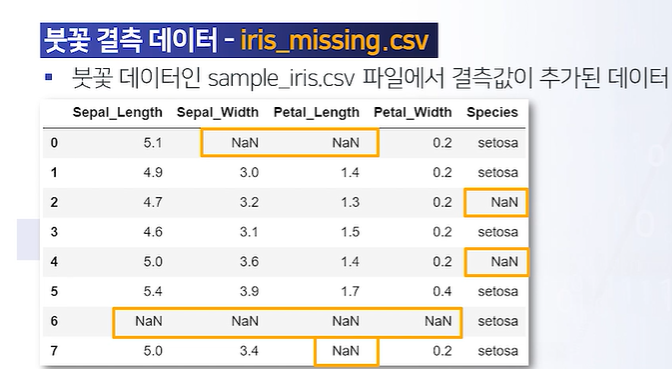
isna() / notna()
df.head(7)
df_na=df.head(7)
df_na["Sepal_Length"].isna()
#df_na["Sepal_Length"].notna()
#True+True+False#2
df_na["Sepal_Length"].isna().sum()
df_na.isna().sum() #column별 결측치 개수 ★
df_na.isna().sum(axis = 1) # 각 row별 결측치 개수 ★fillna()
df_na.fillna(value = {"Sepal_Length" : 999,
"Sepal_Width" : 999,
}) # column 지정해 결측치 값 채우기
df_na.fillna(value = 999)# column 구분 없이 결측치 값 채우기
sepal_width_mean = df_na["Sepal_Width"].mean()
df_na.fillna(value = {"Sepal_Width" : sepal_width_mean })
#주의 : 결측치 처리 반환을 원본에 덮어써야 갱신됨
# ->
df_na = df_na.fillna(value = {"Sepal_Width" : sepal_width_mean }) dropna()
df_na2 = df.head(7)
df_na2
df_na2.dropna() # 결측치가 있는 데이터(row) 제거
df_na2.iloc[:,:-1]# 마지막 column 제외 ★
df_na2.iloc[:,:-1].dropna(how="all") # 특정 row가 모든 변수 결측치일경우 날림.(default : any, 1개라도 있으면 제거)quantile()
print(df["Sepal_Length"].max())
print(df["Sepal_Length"].min())
print(df["Sepal_Length"].mean())
print(df["Sepal_Length"].median())#중위수
print(df["Sepal_Length"].quantile())
print("\n")
print(df["Sepal_Length"].quantile(q=0.25)) # 제 1 사분위수
print(df["Sepal_Length"].quantile(q=0.50)) # 제 2 사분위수
print(df["Sepal_Length"].quantile(q=0.75)) # 제 3 사분위수 실습문제
#수치형변수 결측치 개수 총합
df.iloc[:,:-1].isna().sum().sum()
#sepal width변수 결측치 평균으로 대치한 값의 분산
df=df.fillna(value={"Sepal_Width" : df["Sepal_Width"].mean()})
df["Sepal_Width"].var()
#평균 기준으로 1.5 표준편차 넘어서는값 이상치 간주 시, Sepal Length 변수 기준 이상치인 row개수
file = path+"iris.csv"
df = pd.read_csv(file)
sl_mean=df["Sepal.Length"].mean()
sl_std = df["Sepal.Length"].std()
cond_1 = df["Sepal.Length"] < (sl_mean - 1.5*sl_std)
cond_2 = df["Sepal.Length"] > (sl_mean + 1.5*sl_std)
df_out = df.loc[(cond_1) | (cond_2)]
len(df_out)데이터 전처리 : 파생변수 생성
키워드
numpy
where
pandas
rename
apply
astype
to_datetime
dt
weekday
get_dummies
파생변수 개요
- 파생변수 : 기존 변수를 조합하여 만들어내는 새로운 변수
- 예시
- 기온,습도,풍속 조합 체감온도 변수
- 물건주문건수&환불건수 조합 환불 비율 변수
- 기존 방문 매장 정보 활용 주 방문 매장 변수
실습 정리 : 데이터/주요 함수 및 메서드
apply, lambda 함수 잘 섞어쓰는 것이 중급 수준에서는 중요하다


where
df["is_setosa"] = np.where(df["Species"] == "setosa", 1, 0)
df.tail()
pd.crosstab(df["Species"], df["is_setosa"])#검증
#df["is_setosa_2"] = (df["Species"] == "setosa") + 0 #이런식으로도 가능
#df["is_setosa_3"] = (df["Species"] == "setosa") * 1rename : 컬럼(변수)명 변경
df = df.rename(columns ={"Sepal.Length" : "SL"}) #반환값 원본에 저장해야함.apply
# DF 간략화(bike to bike_sub)
bike.columns #컬럼조회
bike_sub = bike.iloc[:4,9:11] # bike, registered 변수만 뽑아내기 #row 4개
print(len(bike_sub))
#bike_sub = bike.loc[:4, ["casual", "registered"]]
bike_sub = bike.loc[:4, "casual":"registered"] #row 5개
print(len(bike_sub))
#iloc는 4-1해서(인덱스:4) 0,1,2,3 인덱스가 나오고 loc는 4 까지 참조이기때문에(값:4) 0,1,2,3,4가 나옴.주의
#apply
bike_sub.sum()
bike_sub.sum(axis=1)
bike_sub.apply(func = sum)
bike_sub.apply(func = sum, axis = 1)
#bike_sub.apply(func = mean) #-> 기본함수로 mean 없으므로 에러
#bike_sub.apply(func = pd.Series.mean) # 나옴
bike_sub.apply(func = lambda x: round(x.mean())) #람다함수활용datetime
bike_sub["casual"].astype("str") + "대" # 스트링 더하기
bike["datetime"][:3].str.slice(0,4) #연도 뽑기
bike["datetime"][:3].str.slice(5,7) #월 뽑기
bike_time = pd.to_datetime(bike["datetime"][:3])
bike_time
print(bike_time.dt.year)
print(bike_time.dt.month)
print(bike_time.dt.hour)
print(bike_time.dt.weekday)get_dummies
#bike_dum = pd.get_dummies(data = bike, columns = ["season"]) #가변수 대상이 되는 변수를 없애버린다.(columns)
bike_dum = pd.get_dummies(data = bike, columns = ["season"], drop_first=True) #drop_first : season_1 날림(), 모든 가변수 분석 모델에 넣으면 완전 공산성 등 문제 생길 수 있어.. 나중에 필요. 실습문제
#temp 변수와 atemp변수 차이 절대값 평균 - 소수점 셋째자리까지
bike["diff"] = abs(bike["temp"]-bike["atemp"])
round(bike["diff"].mean(),3) #.abs().mean() method chaining
#casual 값의 최대값이 25가 넘은 날은 총 며칠인가
bike["datetime"] = pd.to_datetime(bike["datetime"])
bike["date"] = bike["datetime"].dt.date
bike_agg = bike.groupby("date")["casual"].max()
bike_agg.head() #Series
bike_agg_up25 = bike_agg[bike_agg > 25]
#bike_agg를 series가 아닌 dataFrame으로 handling하고싶은 경우
bike_agg = bike.groupby("date")["casual"].max().reset_index() #groupby시
#bike.info()
#시간대별 registered 평균을 산출했을 때 가장 큰 시간
bike["hour"] = bike["datetime"].dt.hour
bike_hour = bike.groupby("hour")["registered"].mean().reset_index()
bike_hour.loc[bike_hour["registered"] == bike_hour["registered"].max(),]
bike_hour.loc[bike_hour["registered"].idxmax(), ]데이터 전처리 : 데이터 병합
키워드
Binding
Join
pandas
reset_index
set_index
concat
merge
데이터 병합 개요
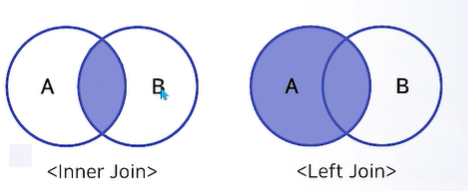
- 병합의 종류
- 데이터를 이어 붙이는 Binding은 행 또는 열 방향으로 연산 가능
- 특정 변수 기준으로 두 데이터 엮는 Join연산 많이 사용.
- Join연산 중 Inner Join과 Left Join 많이 사용
- Join 상세
- Inner Join : 두 데이터 세트의 기준이 되는 변수인 Key 변수가 공통인 행을 반환
- Left Join : A세트의 모든 행을 유지하고 B세트는 Key 변수 기준으로 A세트와 공통인 행을 반환
실습 정리 : 데이터/주요 함수 및 메서드



reset_index
bike_sub = bike.sample(n=4,random_state=123)
bike_sub
bike_sub.reset_index()
bike_sub = bike_sub.reset_index(drop=True) #원본에 입력
bike_sub = bike_sub.set_index("datetime")
bike_sub.reset_index()concat
#concat
bike_1 = bike.iloc[:3,:4]
bike_2 = bike.iloc[5:8, :4]
#print(len(bike_1))
#print(len(bike_2))
pd.concat([bike_1,bike_2]) #row
#pd.concat([bike_1,bike_2],axis=1) #column , 인덱스가 안맞는 상태. (6row)
pd.concat([bike_1,bike_2.reset_index(drop=True)],axis=1) #column, 인덱스가 0,1,2 , 0,1,2로 bike_1, bike_2가 같은 row로 통합됨.(3eow)
merge
file1 = path+"join_data_group_members.csv"
file2 = path+"join_data_member_room.csv"
df_A = pd.read_csv(file1)
df_B = pd.read_csv(file2)
#merge
pd.merge(left = df_A, right = df_B,
left_on = "member" , right_on = "name",
how="left")
#how="inner")
실습 문제
#A를 B에 LeftJoin 했을 때 생성되는 결측 행의 개수는?
df_join = pd.merge(left = df_A, right = df_B,
left_on = "member" , right_on = "name",
how="left")
df_join.isna().sum()
#여름과 겨울의 시간대별 registered 평균을 비교할 때 가장 차이가 많이 나는 시각은?
bike["datetime"] = pd.to_datetime(bike["datetime"])
bike["hour"]=bike["datetime"].dt.hour
bike_summer = bike.loc[bike["season"]==2,]
bike_winter = bike.loc[bike["season"]==4,]
#print(bike_summer["season"].unique())#2
#print(bike_winter["season"].unique())#4
bike_summer_agg = bike_summer.groupby("hour")["registered"].mean().reset_index()
bike_winter_agg = bike_winter.groupby("hour")["registered"].mean().reset_index()
bike_agg_bind = pd.concat([bike_summer_agg, bike_winter_agg], axis = 1)
bike_agg_bind = bike_agg_bind.iloc[:,[0,1,3]]
bike_agg_bind.columns = ["hour","reg_s","reg_w"]
bike_agg_bind["diff"] = abs(bike_agg_bind["reg_w"]-bike_agg_bind["reg_s"])
bike_agg_bind["diff"].max()
#비가 온 날에 30도가 넘는 시각의 count 평균은 얼마인가
bike["datetime"] = pd.to_datetime(bike["datetime"])
bike["date"] = bike["datetime"].dt.date
bike_h100 = bike.groupby(["date"])["humidity"].max().reset_index()
bike_h100 = bike_h100.loc[bike_h100["humidity"]==100,]
bike_join = pd.merge(left = bike, right = bike_h100,
left_on="date", right_on = "date",
how = "inner")
bike_join
bike_join_temp_up30 = bike_join.loc[bike_join["temp"] > 30, ]
bike_join_temp_up30["count"].mean()데이터 전처리 : 정렬 및 변환
키워드
정렬
오름차순
내림차순
pandas
crosstab
sort_values
melt
pivot
정렬 개요
- 정렬 방법
- 오름차순 : 값이 작은 것 부터 정렬
- 내림차순 : 값이 큰 것 부터 정렬
- 정렬의 활용
- 특정 변수의 최대값 또는 최소값을 확인할 때 사용
- ex) 시계열 데이터 분석에서 시간순서대로 데이터 정렬
실습 정리 : 데이터/주요 함수 및 메서드




crosstab
pd.crosstab(dia["cut"], dia["clarity"])
pd.crosstab(dia["cut"], dia["clarity"], normalize = True).round(2)
pd.crosstab(dia["cut"], dia["clarity"], normalize = 0 ) # row 연산 : Fair에서 I1은 13.04% SI2 28%
pd.crosstab(dia["cut"], dia["clarity"], normalize = 1 ) # column기준 연산 : I1 clairty Premium 비율은 27%
#pd.crosstab(dia["cut"], dia["clarity"], values = dia["price"], aggfunc = pd.Series.mean)
dia.groupby(["cut","clarity"])["price"].mean().reset_index()
sort_values
dia_agg = dia.groupby(["cut","clarity"])["price"].mean().reset_index()
dia_agg.sort_values("price").head()
dia_agg.sort_values("price", ascending = False).head()
dia_agg.sort_values(["cut","clarity"], ascending = [True,False]).head()melt
file = path+"elec_load_2017_7d.csv"
elec = pd.read_csv(file)
elec.head()
elec_melt = elec.melt(id_vars=["YEAR","MONTH","DAY"] )
elec_melt.head()
print(len(elec))
print(len(elec_melt))pivot
#pivot
#elec_melt.pivot_table()#wide form 바꾸면서 요약까지
elec_pivot = elec_melt.pivot(index = ["YEAR","MONTH","DAY"],
columns="variable",
values="value").reset_index() #돌리기만
elec_pivot
elec_melt실습 문제
file = path+"bike.csv"
bike = pd.read_csv(file)
#workingday가 아니면서 holiday가 아닌 날의 비율
pd.crosstab(bike["workingday"], bike["holiday"])
pd.crosstab(bike["workingday"], bike["holiday"], normalize=True)
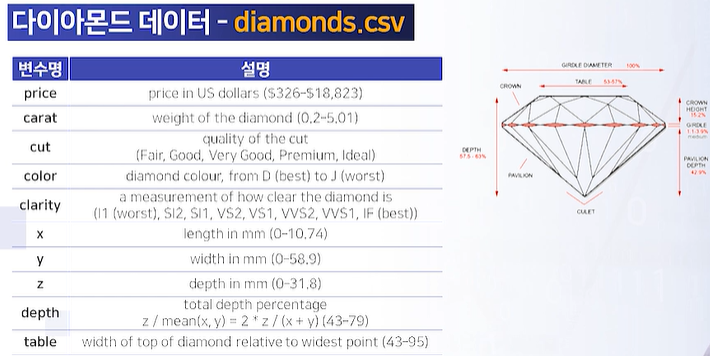
file = path+"diamonds.csv"
dia = pd.read_csv(file)
#가장 많은 데이터가 있는 세공 수준과 색상 조합을 순서대로 고르면
cross = pd.crosstab(dia["cut"], dia["color"])
cross_melt = cross.reset_index().melt(id_vars = "cut")
cross_melt.sort_values("value", ascending = False).head()
#세공수준별 색상별 가격과 케럿의 평균을 구하고 1캐럿당 가격이 가장 높은 세공수준과 색상 조합을 순서대로 고르면
dia_agg = dia.groupby(["cut","color"])[["price","carat"]].mean().reset_index()
dia_agg["ratio"] = dia_agg["price"] / dia_agg["carat"]
dia_agg = dia_agg.sort_values("ratio", ascending = False)
dia_agg.head()
데이터 전처리 : 사용자 정의 함수 활용
키워드
def
return
기본값
pow
normalization
minmax
standardization
사용자정의함수 개요
- 사용자 정의 함수 특징 및 사용
- 가용한 함수를 조합하여 만든 새로운 함수
- 라이브러리와 유사하게 사전 실행 및 등록 필요
def function(param): # 실행코드 return #반환값실습 정리 : 사용자 정의 함수 설정 및 주의점

정선용